- The paper introduces a hierarchical framework (CoINS) that combines skill-aware VLM reasoning with reinforcement learning to facilitate counterfactual interactive navigation.
- It employs counterfactual logic within the InterNav-VLM to assess object removal and uses an RL-based skill library for precise robot control.
- Experiments in both simulation and real-world settings demonstrate that CoINS outperforms traditional navigation methods in cluttered, dynamic environments.
Summary of "CoINS: Counterfactual Interactive Navigation via Skill-Aware VLM"
Introduction
The paper "CoINS: Counterfactual Interactive Navigation via Skill-Aware VLM" (2601.03956) introduces a hierarchical framework designed to enhance robotic navigation in cluttered environments by integrating skill-aware Vision-LLMs (VLMs) with reinforcement learning-based skill libraries. This framework, CoINS, aims to overcome limitations of passive obstacle avoidance by allowing robots to physically manipulate their surroundings, thereby creating traversable paths. Unlike conventional methods, CoINS employs a VLM, dubbed InterNav-VLM, that embodies skill-awareness and counterfactual reasoning capabilities to intelligently determine interaction necessity and target selection.
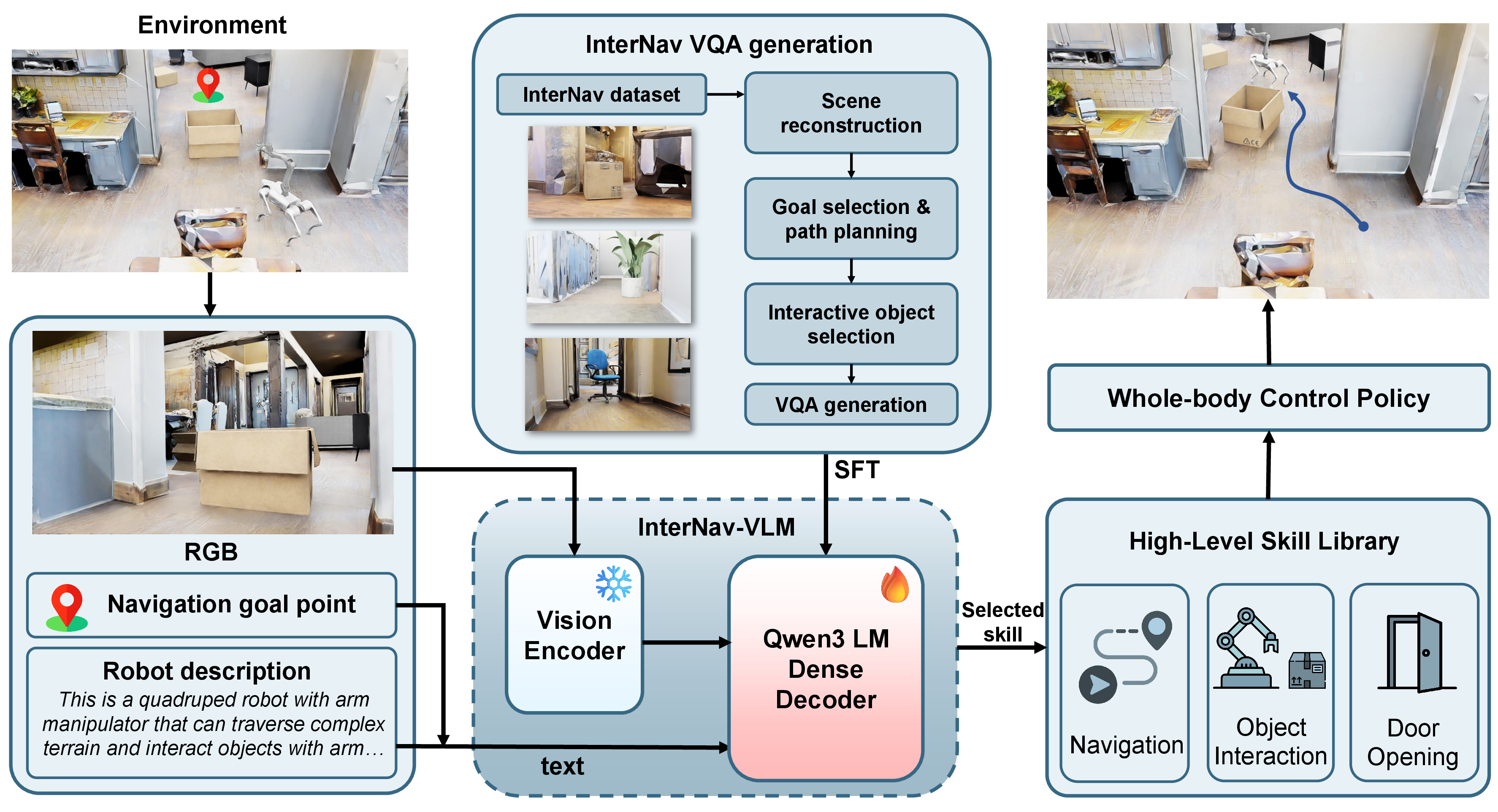
Figure 1: InterNav-VLM in CoINS framework. The VLM reasoning module takes the robot's egocentric RGB observations and embodiment constraints as input to produce high-level interaction and navigation decisions, which are then translated by the skill execution module into precise motion controls for diverse interaction primitives.
The CoINS framework addresses interactive navigation as a task and motion planning problem in environments populated with movable and static obstacles. It consists of two main components: a skill-aware reasoning policy (InterNav-VLM) for high-level decision-making and an RL-based skill library for low-level control execution. The goal of CoINS is to navigate the robot to its target efficiently by using onboard sensors to understand the environment and make decisions on whether interaction is necessary to clear obstructions.
InterNav-VLM for Navigation Reasoning
InterNav-VLM is fine-tuned to incorporate skill affordances and physical constraints into its reasoning context, facilitating physically grounded navigation decisions. The model uses counterfactual logic to evaluate the causal effects of object removal, thereby deciding when interaction is necessary to facilitate navigation.
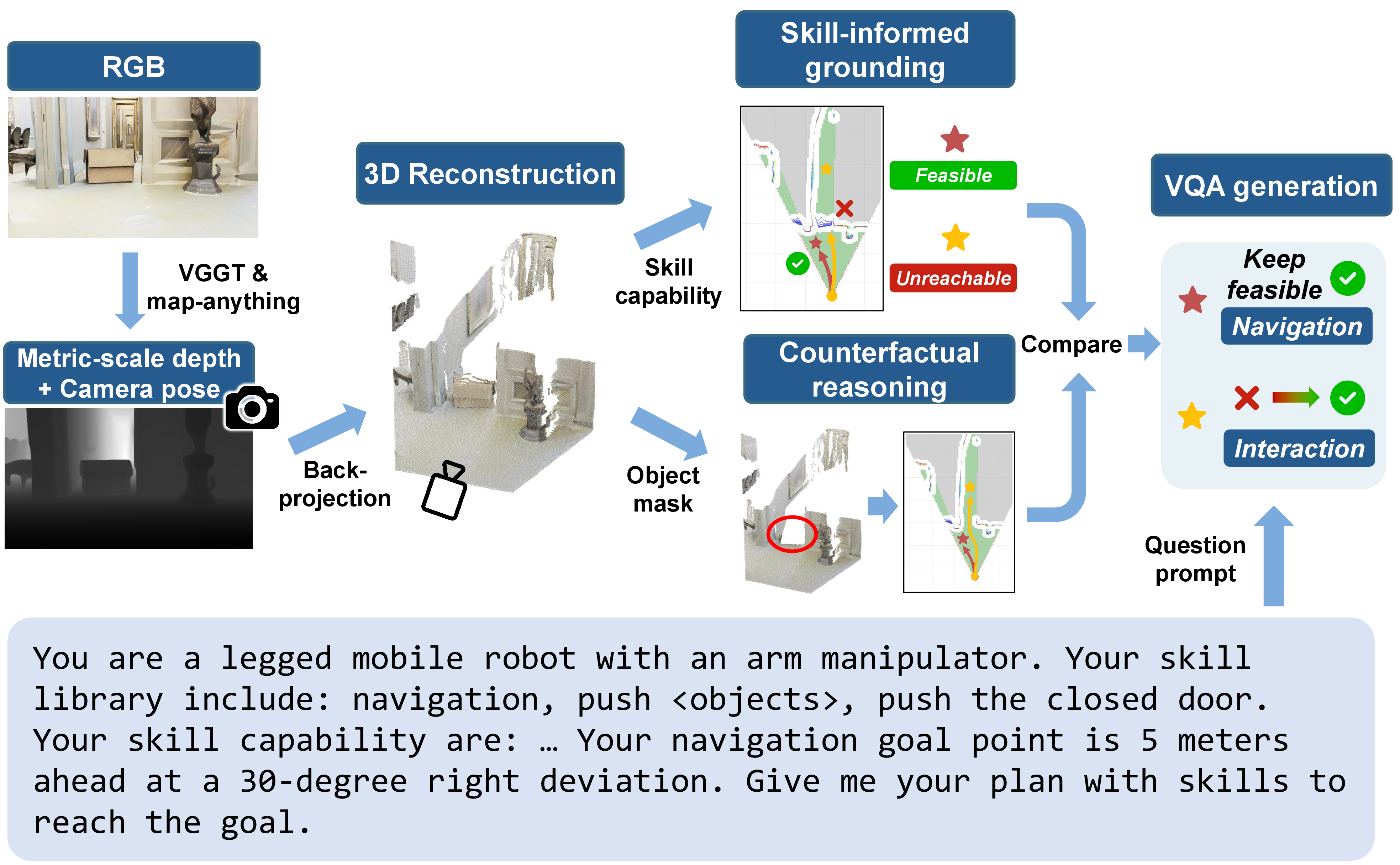
Figure 2: VQA generation process.
RL-Based Skill Library
CoINS employs a quadruped robot equipped with a manipulator for diverse loco-manipulation tasks. This robot utilizes a low-level whole-body controller trained via PPO to maintain stability while executing high-level navigation and interaction skills. The high-level skills include traversability-oriented manipulation, which focuses on efficient path clearance, and door opening, among others.
Interactive Navigation Dataset
The InterNav dataset was created using Isaac Sim to support training and evaluation of navigation frameworks in environments where interaction is required. It contains diverse scenes with realistic obstacles and varying complexity levels to challenge the robotic models in both simulated and real-world experiments.
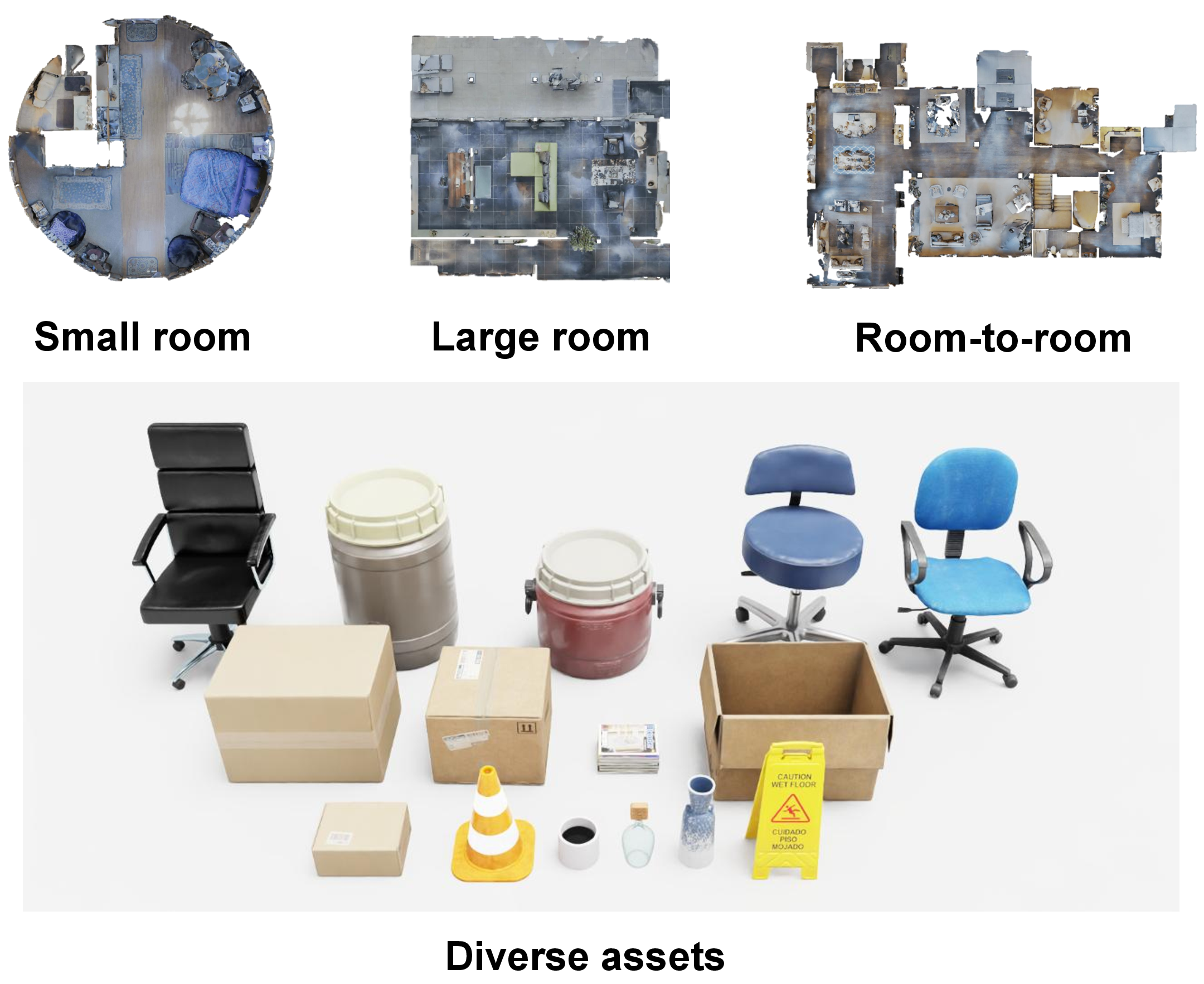
Figure 3: Diverse scenes and objects in the dataset.
Simulation and Real-World Evaluation
In simulation tests, CoINS significantly outperformed traditional navigation methods and contemporary interactive systems like IN-Sight and IN-ArmPush. Additionally, successful real-world deployment in cluttered environments demonstrated its practical applicability. The robot utilized its learned skills effectively, showcased by its ability to interact with various objects and clear paths efficiently.
Conclusion
CoINS presents a significant advancement in interactive robotic navigation, combining vision-language reasoning with skill execution capabilities. Future work may focus on enhancing the model's 3D spatial reasoning and exploring deployment across diverse robot platforms, including humanoids. This framework potentially paves the way for more adaptive and intelligent robotic systems capable of operating autonomously in complex real-world environments.

Figure 4: Real-world experimental setup, including the robot platform and the two test environments.