VLingNav: Embodied Navigation with Adaptive Reasoning and Visual-Assisted Linguistic Memory
Abstract: VLA models have shown promising potential in embodied navigation by unifying perception and planning while inheriting the strong generalization abilities of large VLMs. However, most existing VLA models rely on reactive mappings directly from observations to actions, lacking the explicit reasoning capabilities and persistent memory required for complex, long-horizon navigation tasks. To address these challenges, we propose VLingNav, a VLA model for embodied navigation grounded in linguistic-driven cognition. First, inspired by the dual-process theory of human cognition, we introduce an adaptive chain-of-thought mechanism, which dynamically triggers explicit reasoning only when necessary, enabling the agent to fluidly switch between fast, intuitive execution and slow, deliberate planning. Second, to handle long-horizon spatial dependencies, we develop a visual-assisted linguistic memory module that constructs a persistent, cross-modal semantic memory, enabling the agent to recall past observations to prevent repetitive exploration and infer movement trends for dynamic environments. For the training recipe, we construct Nav-AdaCoT-2.9M, the largest embodied navigation dataset with reasoning annotations to date, enriched with adaptive CoT annotations that induce a reasoning paradigm capable of adjusting both when to think and what to think about. Moreover, we incorporate an online expert-guided reinforcement learning stage, enabling the model to surpass pure imitation learning and to acquire more robust, self-explored navigation behaviors. Extensive experiments demonstrate that VLingNav achieves state-of-the-art performance across a wide range of embodied navigation benchmarks. Notably, VLingNav transfers to real-world robotic platforms in a zero-shot manner, executing various navigation tasks and demonstrating strong cross-domain and cross-task generalization.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
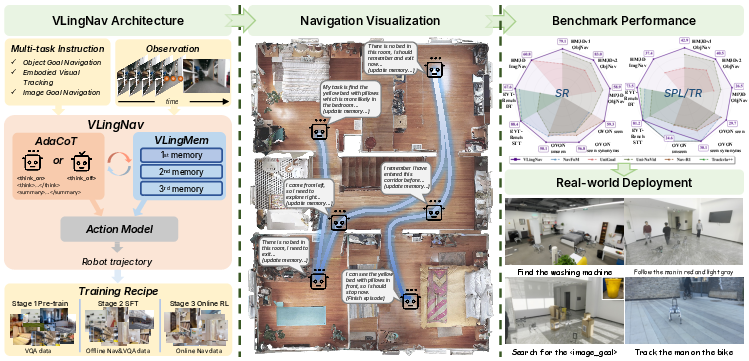
This paper introduces VLingNav, a smart robot “brain” that can see, read instructions, and move on its own. Its special trick is that it doesn’t just react—it knows when to stop and think, and it keeps a handy memory of what it has seen before. This helps it navigate new places, follow directions, find objects or images, and track moving people or things, even in long and tricky tasks.
What questions does the paper try to answer?
- How can a robot decide when it needs to “think hard” and when it can act quickly?
- How can a robot remember what it has already seen so it doesn’t get lost, repeat itself, or go in circles?
- How do we train such a robot so it can handle long, real-world tasks and still generalize to new places and instructions?
- Can we make a single model that works across different navigation tasks (find an object, follow a target, match an image) and even run on real robots without extra training?
How does VLingNav work? (In simple terms)
Think of the robot as having three big abilities: seeing, thinking, and moving.
1) Adaptive reasoning (when to think)
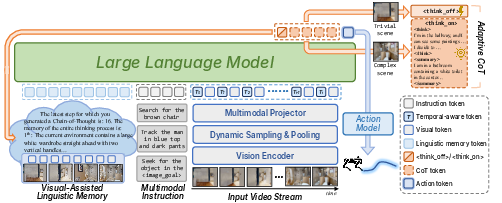
- People sometimes act fast and sometimes stop to plan. VLingNav does the same using “AdaCoT” (Adaptive Chain of Thought).
- Inside the model, it first decides whether to think or not (like flipping a “think on/think off” switch).
- If it chooses to think, it writes out short reasoning steps (like a mini plan) and also creates a simple summary of what it just saw.
- If it doesn’t need to think, it acts quickly to save time.
- Analogy: It’s like a student who usually answers easy questions quickly but thinks step-by-step for harder ones.
2) A memory that mixes words and visuals
- The robot keeps a running “diary” of the environment in language (the summaries), and it attaches key visual clues to it.
- This memory helps it remember what rooms or areas it has already checked, avoid going in circles, and guess where things are moving.
- Analogy: Imagine you’re exploring a building and jot down where you’ve been (language) alongside a few useful sketches (visual cues).
3) Smarter video processing
- Robots see lots of frames per second—many are similar. VLingNav keeps more frames from the recent past and fewer from the distant past (like skimming old footage and focusing on the latest events).
- It also compresses older visuals into a rough overview to save computation, and tags frames with timing information so it knows how old each image is.
- Analogy: You remember yesterday pretty well, last week a bit less, and last year only key moments.
4) Smooth, precise actions
- Instead of just choosing “turn left” or “go forward,” VLingNav predicts a short path with waypoints (position and direction), which is more precise and smoother for a moving robot.
- It uses a lightweight module (like a small neural net) to turn its internal thoughts into these motion plans.
How was it trained?
The team used a three-step training recipe and built a giant new dataset to teach these skills.
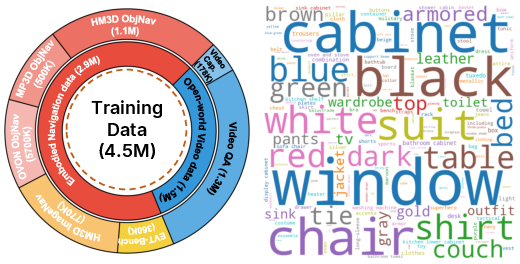
- A new dataset: Nav-AdaCoT-2.9M
- 2.9 million steps across different navigation tasks:
- ObjectNav: find a target object (e.g., “find the sofa”)
- ImageNav: go to the place shown in a picture
- Visual tracking (EVT): follow a described moving target in a crowd
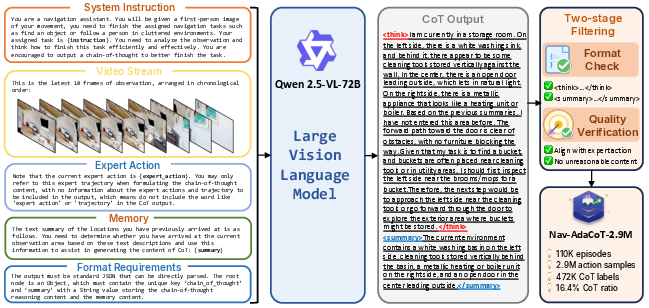
- Crucially, many examples include “adaptive thinking” labels that show not only what to do but also when and how to think.
- They created these “thinking” labels by prompting a strong vision-LLM to explain decisions step-by-step and then filtered the results for quality.
- Plus open-world videos
- They added 1.6 million video examples from public datasets to strengthen general visual understanding.
- Harder videos got extra reasoning labels so the model learns when reasoning helps.
- Training stages
- The robot practices in a simulator.
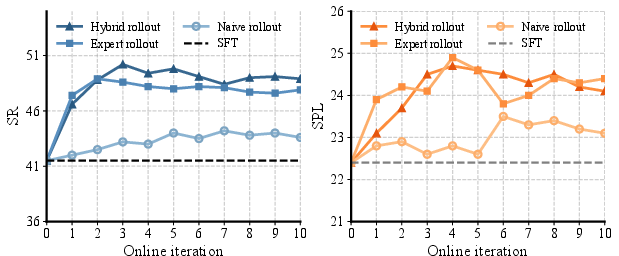
- If it gets stuck, an expert planner shows how to recover, and those examples are added to the training.
- This mix helps the robot go beyond just copying and learn to handle tricky, unexpected situations.
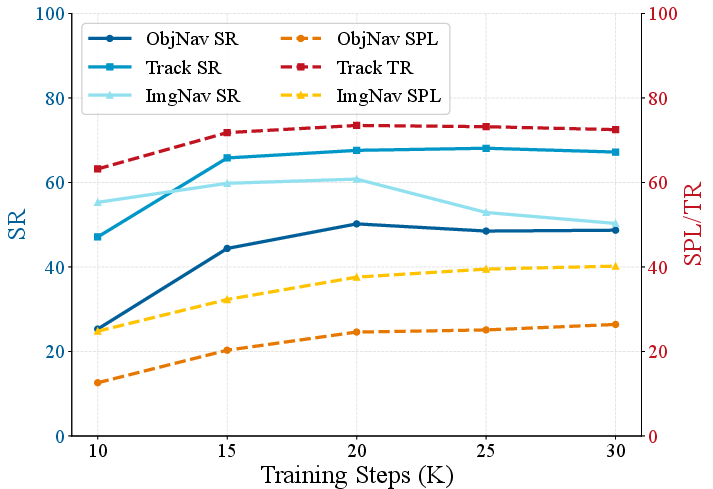
What did they find, and why is it important?
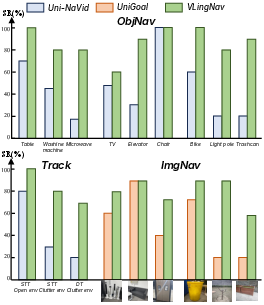
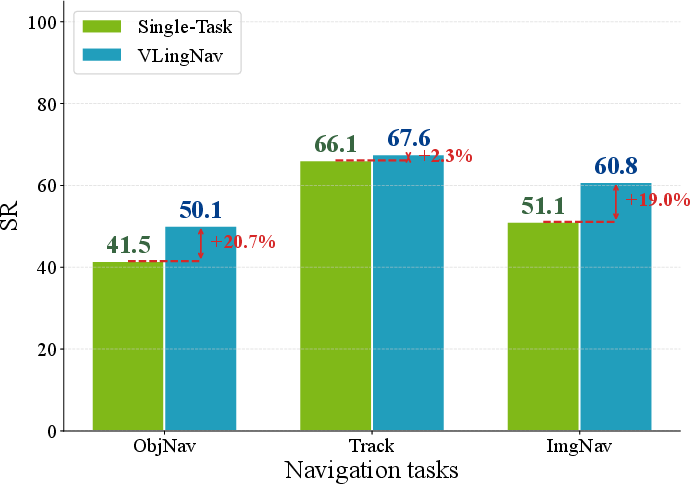
- Strong performance (state of the art): VLingNav beat other methods on several standard tests for navigation, including finding objects, image-based goals, and following a moving target.
- Better at long tasks: The adaptive thinking and memory reduced wandering and repeated mistakes, which is crucial for long routes in complex spaces.
- Works in the real world without extra training (zero-shot): The same model that worked in simulation also ran successfully on real robots for tasks it hadn’t seen before.
- Efficient and interpretable: Because it only reasons when needed, it stays fast. And when it does reason, it writes its thinking, which makes its decisions easier to understand.
Why does this matter?
- More reliable robots: Knowing when to think and having a good memory makes robots less likely to get lost or stuck—important for homes, offices, and factories.
- Fewer hand-crafted rules: Instead of building fragile pipelines with many separate parts, a single model learns to see, reason, and move together.
- Easier to generalize: Training with adaptive thinking and mixed data helps the model handle new rooms, tasks, and instructions without retraining.
- A foundation for future research: The large dataset with “when to think” labels and the memory design give other researchers tools to build smarter, more adaptable robot systems.
In short, VLingNav shows that giving robots the ability to decide when to think and to remember what they’ve seen—using language and visuals together—makes them far better at navigating the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed as actionable items for future research.
- AdaCoT gating policy: No analysis of how the <think_on>/<think_off> indicator is learned, calibrated, or regularized to avoid overthinking or underthinking; missing sensitivity studies on reasoning frequency vs. success/latency trade-offs and budget-aware control of reasoning.
- Reward design details: The RL stage lacks a clear specification of reward functions per task (ObjectNav, ImageNav, EVT), reward shaping, penalties (collisions, oscillations), and success criteria—making reproduction and principled tuning difficult.
- Loss weighting sensitivity: Hyperparameters (e.g., α=0.5 for SFT, λ=0.01 for RL) are fixed without ablation or robustness analysis across tasks and scenes; the impact of these weights on performance, stability, and generalization is unknown.
- Action-space inconsistency: The paper alternates between continuous control (trajectory waypoints a∈R3) and velocity commands (v, ω) without clarifying how these are reconciled across implementations, controllers, and platforms.
- Low-level control interface: How predicted waypoints are tracked by the robot (PID, MPC, pure pursuit), how non-holonomic and dynamic constraints are enforced, and how safety (e.g., collision avoidance) is guaranteed are not specified.
- Safety and failure handling: No systematic evaluation of collision rates, near-miss events, recovery behaviors, or safety-critical constraints during exploration, especially in crowded EVT scenarios.
- Memory management policy: VLingMem “UpdateMemory” is underspecified—no detail on capacity limits, pruning/forgetting strategies, summarization granularity, retrieval mechanisms, or safeguards against error propagation from incorrect memory.
- Memory correctness and utility: No quantitative metrics or diagnostics to assess memory fidelity, its effect on loop avoidance, or how memory improves efficiency (e.g., redundant exploration reduction) across long-horizon tasks.
- Map integration: The paper argues VLMs lack native map support, but does not explore or evaluate structured map/token representations, topological memory, or learned map encoders as alternatives to linguistic memory.
- Multi-sensor fusion: Only RGB inputs are used; the benefits and trade-offs of incorporating depth, LiDAR, IMU, or odometry (for robustness, metric localization, and dynamic obstacle handling) remain unexplored.
- Dynamic FPS sampling: The proposed sampling and grid pooling schedules lack empirical latency vs. accuracy trade-off analysis, stability under different robot speeds/frame rates, and sensitivity to time-embedding choices (RoPE settings).
- Generalization limits: Zero-shot transfer claims are qualitative; no standardized real-world metrics, task difficulty stratification, or failure case analysis to quantify sim-to-real robustness and domain shift tolerance.
- EVT identity robustness: In tracking with crowds, identity switches, occlusions, and re-identification errors are not analyzed; how VLingMem or AdaCoT mitigate identity drift is unclear.
- Dataset CoT coverage: Only ~472K of 2.9M samples have CoT; selection criteria, class/task balance, and potential biases introduced by filtering and “last 10 frames” truncation are not characterized.
- CoT quality assurance: Rule-based and trajectory consistency checks are mentioned but not detailed; no human evaluation or automatic metrics to quantify CoT factuality, coherence, and alignment with observations/instructions.
- Instruction realism: The dataset mixes planner-based trajectories with synthetic or templated instructions; how well the model handles free-form, ambiguous, multi-step, or conversational instructions is not evaluated.
- Multilingual and dialog: The approach is English-only; multilingual instruction following and interactive clarification (ask-then-act) remain untested.
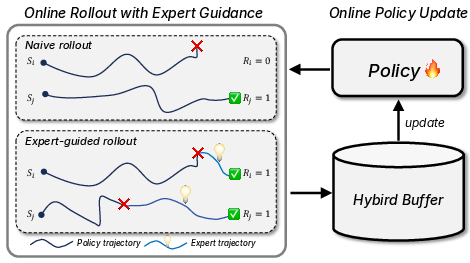
- Expert-guided rollout policy: The trigger for expert takeover (k=15 steps stuck) and oscillation detection are hand-picked; no ablation on k, no evaluation of how expert interventions bias exploration or impede learning novel strategies.
- RL stability and sample efficiency: PPO with REINFORCE++ advantages is used without reporting variance, learning curves, or failure rates; the method’s stability under sparse rewards and long horizons remains uncertain.
- Credit assignment across modalities: How advantages/gradients propagate through language tokens, vision features, and the action head (and whether RL degrades language reasoning) is not analyzed.
- Computational efficiency: Training uses 128 A100 GPUs; inference-time throughput on embedded hardware, end-to-end latency with/without CoT, and memory footprint are not reported.
- Comparative speed vs. action quality: The claim that MLP-based continuous actions are faster than diffusion/flow is not backed by head-to-head latency and precision benchmarks under matched conditions.
- Robustness to sensor/actuation noise: No tests with camera jitter, blur, lighting changes, calibration errors, actuation delays, or wheel slip; resilience under realistic robot imperfections is unquantified.
- Cross-embodiment transfer: While the model avoids task-specific tokens, it uses a robot-specific action head; transfer to differing kinematics, sizes, dynamics, and controller stacks remains an open question.
- Long-term memory saturation: The model operates over extended trajectories, but strategies for memory overflow, topic drift, and stale memory correction (e.g., memory verification or decay) are not provided.
- Adversarial and OOD robustness: Behavior under adversarial instructions, misleading visual cues, extreme clutter, or open-world outdoor scenarios is untested.
- Interpretability and debugging: Beyond textual summaries, tools or metrics to inspect internal reasoning, memory consistency, and decision traces are not provided for diagnosing failures in deployment.
- Ethical and privacy considerations: EVT with crowds raises privacy and social-navigation concerns; policies for de-identification, consent, and safety in human-populated spaces are not discussed.
- Reproducibility: Precise training recipes (optimizer settings, learning rates per module, curriculum schedules), environment seeds, and open-sourced code/checkpoints for the RL stage are not specified.
Practical Applications
Practical Applications Derived from the Paper
Below are actionable, sector-linked applications of VLingNav’s findings, methods, and innovations, grouped by deployment horizon. For each, we note potential tools/workflows and key assumptions/dependencies that affect feasibility.
Immediate Applications
Industry
- Warehouse and fulfillment AMRs (logistics)
- Use case: Zero-shot navigation in changing layouts; aisle reconfiguration; dynamic obstacle avoidance; pick-station routing; follow-me carts using EVT (person tracking).
- Why now: Continuous control head + AdaCoT keeps latency low while reasoning when needed; VLingMem prevents loops in large facilities.
- Tools/workflows: ROS2 node wrapping VLingNav; “AdaCoT Inference Engine” with dynamic FPS; “VLingMem Log” for route memory; hybrid RL fine-tuning in Isaac Sim/Habitat.
- Assumptions/dependencies: Egocentric camera(s) and IMU; safety layer for collision avoidance; on-edge GPU (e.g., Jetson Orin) or small form-factor GPU; floor safety certification.
- Facility inspection and maintenance (industrial/energy)
- Use case: Long-horizon patrol routes across multi-room plants; adaptive re-routing around blocked corridors; auditability via CoT logs.
- Tools/workflows: Patrol scheduler → VLingNav loop (Think indicator → CoT + summary → action → memory update) → inspection CRM.
- Assumptions/dependencies: Access constraints; lighting variability; regulatory audit requirements; integration with existing CMMS.
- Retail service robots (retail)
- Use case: Product-finding through ImageNav (user shows an item image); in-store shopper assistance; end-cap monitoring; inventory spot checks.
- Tools/workflows: POS/inventory API → “ImageGoal” prompt builder → VLingNav route → CoT/memory export to store analytics.
- Assumptions/dependencies: Privacy compliance in public spaces; on-device processing preferred; signage/text understanding may aid, but is not required.
- Hospital logistics and staff-assist carts (healthcare)
- Use case: Deliver supplies across unfamiliar wards; follow-staff EVT; explainable detours with CoT logs for incident review.
- Tools/workflows: HL7/FHIR task queue → navigation missions; explicit “when-to-think” thresholds for quiet/critical zones.
- Assumptions/dependencies: Clinical safety and infection control; elevator/door integration; fallback teleoperation.
- Security patrol robots (security)
- Use case: Patrol routes in offices/campuses; adaptive reasoning at choke points; interpretable incident traces via CoT + VLingMem.
- Tools/workflows: Patrol plan compiler → VLingNav policy; automated CoT log redaction pipeline for privacy.
- Assumptions/dependencies: Clear policies on retention/anonymization of CoT/memory logs; nighttime low-light sensors.
- Camera operator robots and social robots (media/events)
- Use case: EVT to follow a designated subject for filming; crowd navigation with trend inference.
- Tools/workflows: “Target designation” UI (text/image); latency-tuned AdaCoT thresholds for smooth motion.
- Assumptions/dependencies: Motion safety among pedestrians; consent for tracking; stabilization stack.
- Robotics platform SDKs and integrators (software/robotics)
- Use case: Package VLingNav as an SDK for mobile bases; drop-in action head for continuous control; adaptive video tokenization plugin.
- Tools/workflows: “VLingNav Edge SDK”; “Dynamic-FPS & Grid-Pooling” middleware; “Hybrid-RL Trainer” with expert-switch rollouts; CoT/memory timeline viewer.
- Assumptions/dependencies: Licensing/weights availability; compatibility with Nav2/ROS2 and hardware drivers.
Academia
- Benchmarks and datasets for embodied reasoning
- Use case: Train/evaluate adaptive CoT in navigation; study when-to-think and what-to-think policies; long-horizon memory ablations.
- Tools/workflows: Nav-AdaCoT-2.9M for SFT; open-world video CoT partitions for pre-training; Habitat-based evaluation scripts.
- Assumptions/dependencies: Access to GPUs for 7B-scale backbones; reproducible simulator seeds; dataset licensing.
- Methods research in memory and reasoning
- Use case: Compare linguistic vs map vs latent memory; study temporal tokenization (RoPE timestamping); continuous vs discrete action heads under RL.
- Tools/workflows: Modular swaps of VLingMem; PPO/REINFORCE++ baselines; advantage estimators; trajectory-level evaluations.
- Assumptions/dependencies: Ablation framework and logging; standardized metrics (SR, SPL, efficiency).
Policy and Governance
- Explainability and audit readiness for mobile robots
- Use case: Use CoT/memory logs as auditable decision traces for safety assessments, incident analysis, and certification dossiers.
- Tools/workflows: “CoT Compliance Exporter” (redaction, hashing, retention policies); sampling strategies for periodic audits.
- Assumptions/dependencies: Clear retention/privacy policies (GDPR/CCPA/HIPAA where relevant); operator training.
Daily Life
- Home service robots (consumer robotics)
- Use case: “Find this” via image goal; guided navigation to the kitchen/garage with verbal instructions; follow-me for carrying items.
- Tools/workflows: Mobile app → instruction/image goal → VLingNav loop; low-latency inference presets.
- Assumptions/dependencies: Cost/power constraints; robust obstacle avoidance around pets/kids; on-device inference to protect privacy.
Long-Term Applications
Industry
- General-purpose mobile manipulation with cognitive navigation (manufacturing, hospitality, healthcare)
- Use case: Combine AdaCoT navigation with manipulation policies for pick/place tasks across rooms; task decomposition via CoT.
- Potential products: “Cognitive GP-robot” stack that unifies nav + manipulation + memory.
- Dependencies: Reliable multi-sensor fusion; safety-certified arms/grippers; cross-task training data.
- Fleet-level shared linguistic memory (logistics, smart buildings)
- Use case: Robots share summarized VLingMem (e.g., “Shelf A relocated,” “Corridor blocked near Dock 3”) for faster adaptation.
- Products/workflows: “Mem-Server” with privacy-aware, building-level knowledge graph; conflict resolution and trust scoring.
- Dependencies: Robust comms; secure federated/edge sharing; governance over shared memory correctness.
- Construction/site robots and search-and-rescue (AEC, public safety)
- Use case: Navigate unstructured, evolving indoor sites; infer movement trends (crowds, debris shifts); CoT logs for mission debrief.
- Dependencies: Extreme sim-to-real; dust/lighting robustness; integration with safety supervisors and PPE detection.
- Autonomous wheelchairs and assistive mobility devices (healthcare)
- Use case: Natural-language route planning; dynamic adaptation in crowds; transparent decisions for caregiver trust.
- Dependencies: Medical-grade safety; certified redundancies; personalized preferences in memory.
Academia
- Standardized long-horizon memory benchmarks and metrics
- Use case: Evaluate persistent cross-modal memory durability, forgetting policies, and safety trade-offs over hours/days.
- Dependencies: Long-duration simulators; standardized privacy-preserving memory formats.
- RL for continuous action in embodied VLAs at scale
- Use case: Study sample efficiency of expert-guided rollouts; outcome-based rewards; curriculum learning for multi-task nav.
- Dependencies: Efficient simulators at scale; reliable reward shaping; reproducible pipelines.
- Cross-task generalization studies (nav → manipulation → social interaction)
- Use case: Transfer AdaCoT “when-to-think” policies across tasks; analyze emergent reasoning across domains.
- Dependencies: Unified datasets spanning tasks; multi-modal annotation standards.
Policy and Governance
- Standards for interpretable embodied AI and memory governance
- Use case: Codify requirements for CoT traceability, redaction, and retention; certification protocols for adaptive reasoning systems.
- Dependencies: Multi-stakeholder alignment (regulators, manufacturers, operators); test suites and reference scenarios.
- Privacy-by-design for embodied tracking (EVT) in public spaces
- Use case: Policies/tooling for on-device inference, ephemeral CoT, face blurring/pseudonymization of memory.
- Dependencies: Hardware capable of on-edge processing; legal clarity on logging and consent.
Daily Life
- Personalized home companions with persistent, privacy-preserving memory
- Use case: Household layout recall, habitual routes, user preferences; explainable route decisions for user trust.
- Dependencies: Local-only memory and compute; intuitive correction interfaces; cost and reliability for consumer markets.
Potential Tools, Products, and Workflows That Might Emerge
- VLingNav Edge SDK: ROS2-compatible package integrating AdaCoT, VLingMem, and continuous action head.
- AdaCoT Inference Engine: Runtime module that adaptively triggers reasoning to balance latency and accuracy; configurable policies per environment.
- VLingMem Store and Timeline Viewer: Audit and debugging tool to inspect summaries, trends, and their influence on actions.
- Dynamic-FPS & Grid-Pooling Plugin: Video preprocessing module for embedded GPUs to control token counts and compute cost.
- Hybrid-RL Trainer: Expert-guided rollout framework (shortest-path planner in sim) for safe, sample-efficient policy improvement.
- CoT Compliance Exporter: Redaction and retention management for reasoning/memory logs aligned with privacy regulations.
Key Assumptions and Dependencies (Cross-Cutting)
- Hardware: On-edge compute (e.g., Jetson Orin-class) to run a 7B VLM with video; adequate power/thermal management.
- Sensors: Egocentric RGB (plus depth/IMU preferred) and reliable odometry; safety sensors (lidar/ultrasonic) for redundancy.
- Safety stack: Independent collision avoidance and emergency stop layers; certified controllers where required.
- Data and training: Access to Nav-AdaCoT-2.9M and simulators with expert planners for RL; domain-specific fine-tuning to reduce sim-to-real gap.
- Privacy and compliance: Clear policies for CoT/memory logging, retention, and redaction—especially for EVT/person-following scenarios.
- Integration: ROS2/Nav2 compatibility; facility IT (maps/doors/elevators) where applicable; operator UX for instruction input (text/voice/image).
- Environment variability: Robustness to lighting, clutter, and crowds; procedures for out-of-distribution recovery (expert handoff, teleop).
Glossary
- Adaptive Chain-of-Thought (AdaCoT): A mechanism that selectively triggers explicit reasoning when needed to balance fast execution with deliberate planning. "we introduce an adaptive chain-of-thought (AdaCoT) mechanism, which dynamically triggers explicit reasoning only when necessary"
- Advantage: The baseline-adjusted return signal used in policy gradient methods to guide updates. "and we use REINFORCE++~\citep{hu2025reinforce++} to calculate the advantage ."
- Anchor-based diffusion policy: A diffusion-model policy that generates continuous motion trajectories using anchor points. "TrackVLA~\citep{wang2025trackvla} designs an anchor-based diffusion policy that directly outputs the robotâs motion trajectory"
- Autoregressive: A token-by-token generation paradigm where each output depends on previously generated tokens. "For text token prediction, the model follows a conventional autoregressive paradigm."
- Causal confusion: A training pathology where models learn spurious correlations that do not reflect true causal mechanisms. "mitigating issues such as covariate shift and causal confusion induced by imitation learning."
- Chain-of-Thought (CoT): Explicit intermediate reasoning steps generated before producing final actions or answers. "OctoNav~\citep{gao2025octonav} improves the model's performance in navigation tasks and enhances interpretability by executing CoT at fixed frequency."
- Covariate shift: A distribution mismatch between training and deployment data that leads to degraded performance. "mitigating issues such as covariate shift and causal confusion induced by imitation learning."
- Cross-Entropy (CE) loss: A classification loss used to supervise token generation in LLMs. "The training is supervised using a standard cross-entropy (CE) loss, applied at the token level."
- DeepSeek-R1: A large reasoning model demonstrating RL-driven improvements with outcome-based rewards. "Recent advances in large reasoning models (e, \mbox{DeepSeek-R1}~\citep{guo2025deepseek}) show that RL can drive remarkable progress even when relying solely on outcome-based rewards."
- Dual-process theory: A cognitive framework distinguishing fast intuitive and slow deliberative thinking. "inspired by the dual-process theory of human cognition"
- Ebbinghaus forgetting curve: A model of memory decay over time used to guide dynamic sampling of past frames. "Inspired by the Ebbinghaus forgetting curve~\citep{ebbinghaus2013image}, historical frames are sampled according to their time intervals relative to the current frame."
- Egocentric camera: A robot-mounted camera providing first-person visual observations. "captured by the egocentric camera mounted on the robot at each time step"
- Embodied Visual Tracking (EVT): A navigation subtask focused on tracking targets in dynamic scenes using language guidance. "and embodied visual tracking (EVT)~\citep{wang2025trackvla,zhong2024empowering,liu2025trackvla++}"
- Flow matching: A generative modeling technique that can be trained via RL when formulated as an MDP. "Recent advances ... addresses this by formulating flow matching as an MDP, enabling RL training via PPO~\citep{schulman2017proximal} or GRPO."
- GRPO: A reinforcement learning algorithm used to optimize reasoning and actions in VLA models. "OctoNav~\citep{gao2025octonav}, VLN-R1~\citep{qi2025vln}, and Nav-R1~\citep{liu2025nav} have convergently integrated GRPO~\citep{shao2024deepseekmath} into navigation VLA models"
- Grid pooling: A downsampling method for visual feature maps that summarizes historical observations efficiently. "we process past observations using a grid pooling strategy."
- HM3D: A large-scale 3D dataset of indoor environments used for navigation tasks. "HM3D OVON~\citep{yokoyama2024hm3d}: For this zero-shot, open-vocabulary task, we also collect shortest-path trajectories."
- ImageNav: Image-goal navigation where the target is specified by an image rather than text. "ImageNav is analogous to ObjectNav, with the key difference that the goal is specified by an image rather than text."
- Imitation learning: Training a policy to mimic expert demonstrations in supervised fashion. "most current VLA training paradigms rely on supervised fine-tuning (SFT) via imitation learning."
- KV cache: A transformer caching mechanism that accelerates inference by reusing key-value states. "and leverage KV cache to jointly improve both generalization and inference speed."
- LLaVA-Video-7B: A video-capable vision-LLM backbone used by VLingNav. "VLingNav extends a video-based VLM, specifically LLaVA-Video-7B~\citep{zhang2024video}"
- Long Short-Term Memory (LSTM): A recurrent neural network architecture used to propagate temporal representations. "compresses visionâlanguage representations into latent tokens and propagates them through a Long Short-Term Memory (LSTM) network."
- Mean Squared Error (MSE) loss: A regression loss used to supervise continuous action trajectories. "where $\mathcal{L}_{\text{MSE}$ is the Mean Squared Error loss that supervises the predicted action trajectory"
- Mem2Ego: A memory-augmented VLA approach that incorporates global maps to aid navigation. "Mem2Ego~\citep{zhang2025mem2ego} and MapNav~\citep{zhang-etal-2025-mapnav} incorporate global map information into VLA models as memory components."
- MDP (Markov Decision Process): A formalism for sequential decision-making under uncertainty. "formulating flow matching as an MDP, enabling RL training via PPO~\citep{schulman2017proximal} or GRPO."
- Multivariate Gaussian distribution: A probabilistic policy parameterization for continuous actions. "We parameterize the policy as a multivariate Gaussian distribution."
- Nav-AdaCoT-2.9M: A large dataset with adaptive reasoning annotations for embodied navigation. "we construct Nav-AdaCoT-2.9M, the largest embodied navigation dataset with reasoning annotations to date"
- ObjectNav: Object-goal navigation where the robot searches for an object category described by language. "ObjectNav requires the robot to explore unseen environments given a textual description of an object category"
- OctoNav: A CoT-enhanced navigation framework that reasons at a fixed frequency. "OctoNav~\citep{gao2025octonav} improves the model's performance in navigation tasks and enhances interpretability by executing CoT at fixed frequency."
- On-policy: Data collected using the current policy, reflecting its behavior for online updates. "we use the current policy to collect 128 episodes of on-policy data"
- Open-vocabulary ObjectNav (OVON): Object-goal navigation with categories beyond a fixed vocabulary. "HM3D OVON~\citep{yokoyama2024hm3d}: For this zero-shot, open-vocabulary task, we also collect shortest-path trajectories."
- PPO (Proximal Policy Optimization): A policy-gradient RL algorithm using clipped objectives for stable updates. "where $\mathcal{L}_{\text{RL}$ is a PPO-style policy-gradient objectiveï¼and we use REINFORCE++~\citep{hu2025reinforce++} to calculate the advantage ."
- Qwen2.5-VL-72B: A high-capacity vision-LLM used to generate CoT labels. "we designed a composite prompt for Qwen2.5-VL-72B~\citep{bai2025qwen2}"
- REINFORCE++: An advantage estimation and gradient method variant used within PPO-style objectives. "and we use REINFORCE++~\citep{hu2025reinforce++} to calculate the advantage ."
- RoPE (Rotary Position Embedding): A positional encoding method enabling time-aware token representations. "By encoding timestamp information using Rotary Position Embedding (RoPE)~\citep{su2024roformer}"
- ScanQA: A video/3D QA dataset incorporated to improve general visual reasoning. "Specifically, we utilize three datasets, LLaVA-Video-178K~\citep{zhang2024video}, Video-R1~\citep{feng2025video}, and ScanQA~\citep{azuma2022scanqa}, comprising a total of 1.6M samples"
- Shortest Path planner: An expert navigation policy that computes minimal-distance routes used for guidance. "implemented via a Shortest Path planner in simulator"
- SigLIP-400M: A pre-trained vision encoder used to compute visual features from frames. "we employ a pre-trained vision encoder (SigLIP-400M~\citep{zhai2023siglip})"
- SLAM (Simultaneous Localization and Mapping): A technique for building maps and estimating robot pose from sensor data. "leveraging mature techniques such as visual foundation models~\citep{ravi2024sam,liu2023grounding}, SLAM~\citep{qin2018vins,xu2022fast}, and path-planning algorithms~\citep{karaman2011anytime}"
- Supervised Fine-Tuning (SFT): Post-pretraining supervised training using labeled data and expert trajectories. "most current VLA training paradigms rely on supervised fine-tuning (SFT) via imitation learning."
- Temporal-aware indicator token: A special token that encodes time interval information for visual frames. "Specifically, a temporal-aware indicator token is introduced prior to each frame"
- TVI tokens: Specialized tokens allowing cross-embodiment inputs in navigation models. "NavFoM~\citep{zhang2025embodied} further extends the model by introducing TVI tokens, enabling inputs from cross-embodiment navigation data."
- VGGT: A model producing spatial features used to enhance 3D understanding in navigation. "by fusing spatial features produced by VGGT~\citep{wang2025vggt}"
- Vision-LLM (VLM): A multimodal model that processes visual and textual inputs for reasoning. "large Vision-LLMs (VLMs)."
- Vision-Language-Action (VLA) model: An agent that unifies visual-language understanding with action generation. "Vision-Language-Action (VLA) models have shown promising potential in embodied navigation"
- VLingMem: A visual-assisted linguistic memory module that stores persistent cross-modal semantics. "we develop a visual-assisted linguistic memory module (VLingMem)"
- VLingNav: The proposed VLA framework with adaptive reasoning and linguistic memory for navigation. "we propose VLingNav, a VLA model for embodied navigation grounded in linguistic-driven cognition."
- Vision-Language Navigation (VLN): A task where robots follow natural language to navigate in visual environments. "vision-language navigation (VLN)~\citep{zhang2024navid,zhang2024uni,wei2025streamvln,cheng2024navila,zeng2025janusvln}"
- Zero-shot: Deploying a model to new tasks or domains without additional fine-tuning. "VLingNav transfers to real-world robotic platforms in a zero-shot manner"
Collections
Sign up for free to add this paper to one or more collections.