Learnable Multipliers: Freeing the Scale of Language Model Matrix Layers
Published 8 Jan 2026 in cs.LG | (2601.04890v1)
Abstract: Applying weight decay (WD) to matrix layers is standard practice in large-language-model pretraining. Prior work suggests that stochastic gradient noise induces a Brownian-like expansion of the weight matrices W, whose growth is counteracted by WD, leading to a WD-noise equilibrium with a certain weight norm ||W||. In this work, we view the equilibrium norm as a harmful artifact of the training procedure, and address it by introducing learnable multipliers to learn the optimal scale. First, we attach a learnable scalar multiplier to W and confirm that the WD-noise equilibrium norm is suboptimal: the learned scale adapts to data and improves performance. We then argue that individual row and column norms are similarly constrained, and free their scale by introducing learnable per-row and per-column multipliers. Our method can be viewed as a learnable, more expressive generalization of muP multipliers. It outperforms a well-tuned muP baseline, reduces the computational overhead of multiplier tuning, and surfaces practical questions such as forward-pass symmetries and the width-scaling of the learned multipliers. Finally, we validate learnable multipliers with both Adam and Muon optimizers, where it shows improvement in downstream evaluations matching the improvement of the switching from Adam to Muon.
The paper demonstrates that introducing learnable multipliers mitigates constraints imposed by noise and weight decay, enhancing language model expressivity.
The study employs scalar and vector multipliers to adaptively scale outputs at layer, row, or column levels, with empirical validation across benchmarks.
Experimental results show improved performance and feature diversity while reducing hyperparameter tuning and maintaining no inference overhead.
Learnable Multipliers: Freeing the Scale of LLM Matrix Layers
Introduction
This work addresses a fundamental optimization artifact encountered in large-scale LLM training: the equilibrium norm imposed by stochastic gradient noise and weight decay (WD) when applied to matrix layers. Specifically, the equilibrium causes model weights to adopt norms determined by optimizer hyperparameters—learning rate and weight decay—rather than data-driven requirements. This induces suboptimal scale constraints on internal representations and restricts the model's expressivity. The authors propose attaching learnable multipliers (LRMs) to matrix weights, allowing both scalar and vector scales to adaptively modulate layer outputs and circumvent the limitations of noise-WD equilibrium, thereby enhancing downstream performance across major LM benchmark suites.
Weight Decay–Noise Equilibrium and Its Limitations
Weight decay is omnipresent in LLM training with optimizers such as AdamW or Muon, stabilizing the uncontrolled growth of matrix weights under gradient noise. Empirical and theoretical analysis shows the weight norm follows ∥W(η,λ)∥∝λη. This norm is dictated by optimizer parameters rather than dataset-specific needs, pinning the model’s expressivity. The effect is not exclusive to Adam variants, as Muon exhibits similar dynamics.
The central critique is that these equilibrium-induced norms "trap" feature representations, potentially misaligning the learned scale from what would be optimal for loss minimization and generalization.
Learnable Multipliers: Formulation and Placement
The authors introduce two forms of LRMs:
Scalar multipliers: W→sW, where s∈R is a learnable parameter.
Vector multipliers: Wij→riWijcj, with ri∈Rdout, cj∈Rdin.
Multipliers can be incorporated at the layer, row, or column level to maximize expressive freedom in scaling, subject to architectural symmetries. The gradient flow for LRMs is significantly less noisy compared to matrix weights, enabling effective learning of the scale parameter without being suppressed by WD.
Multipliers are merged into effective weights during inference, incurring no runtime cost.
Experimental Validation: Escaping Noise-WD Norms
Rigorous experiments in both final projection (LM head) and residual MLP blocks demonstrate the limitations of WD-noise equilibrium and the efficacy of LRMs in escaping these traps.
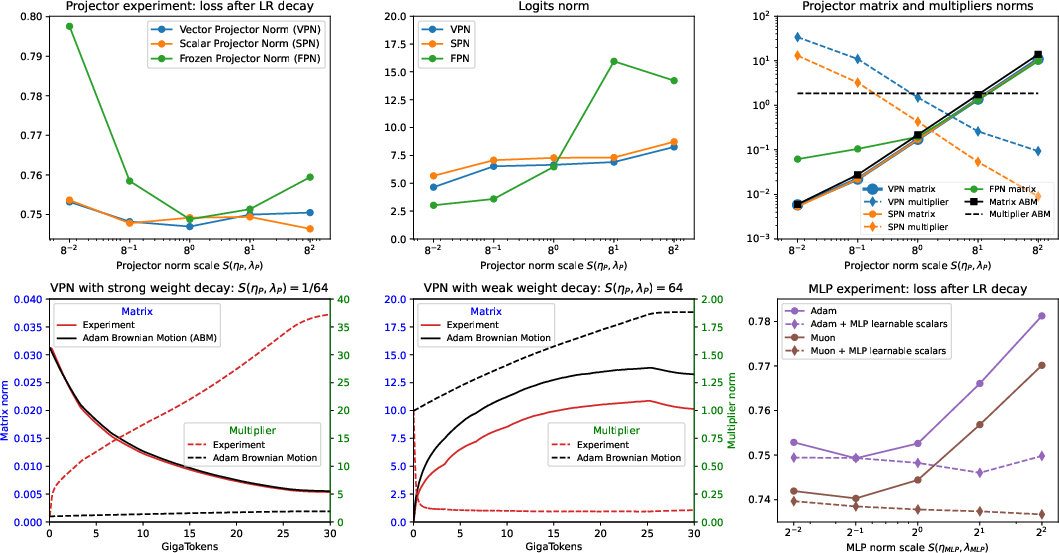
In projector layers, freezing multipliers and varying WD/learning rate causes marked degradation in final loss for extreme norm values, but introducing scalar or vector LRMs maintains stable, optimal logit scales regardless of WD-induced norms.
Figure 1: Projector and MLP scale λη sweep illustrates degradation for fixed norm and robust compensation with learnable multipliers.
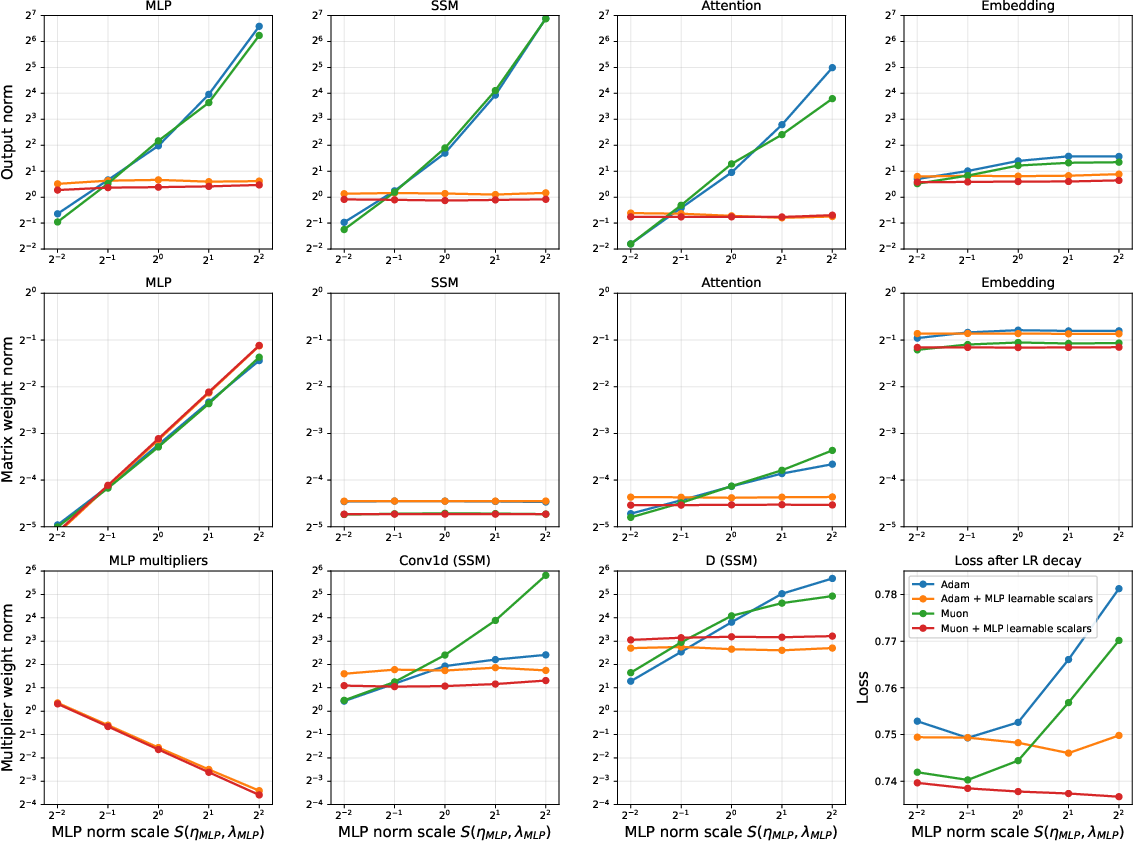
In MLP blocks, restricting RMSNorm adaptation and sweeping matrix norms results in notable loss increases, attributed to output scale mismatches between blocks. The addition of LRMs restores optimal performance by enabling inter-block scale compensation (see also Figure 2 for comprehensive norm behavior across subcomponents).
Figure 2: Behaviour of MLP, attention, and SSM block norms as MLP matrix scale is varied, showing compensation by LRMs for suboptimal WD/learning rate setups.
Both Adam and Muon optimizers exhibit identical architecture traps and benefits from multiplier inclusion, reinforcing the universality of the phenomenon.
Scale Diversity and Feature Expressivity
LRMs not only escape equilibrium constraints but expand the diversity of internal feature norms—both depth-wise across layers and width-wise within blocks.
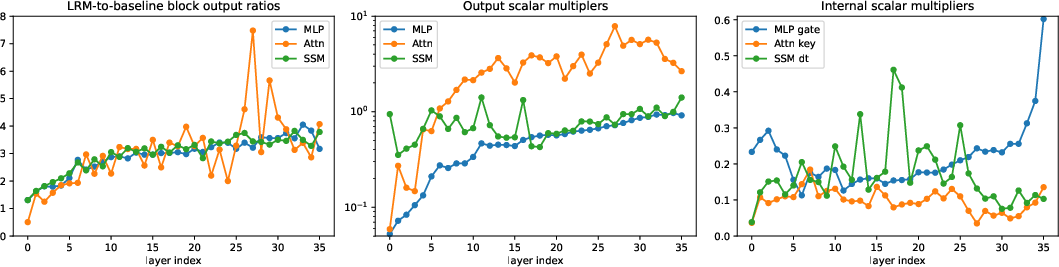
Depthwise analysis reveals that later layers leverage higher outputs and exhibit broader inter-block scale variations with LRMs, suggesting improved routing of representational capacity toward loss minimization.
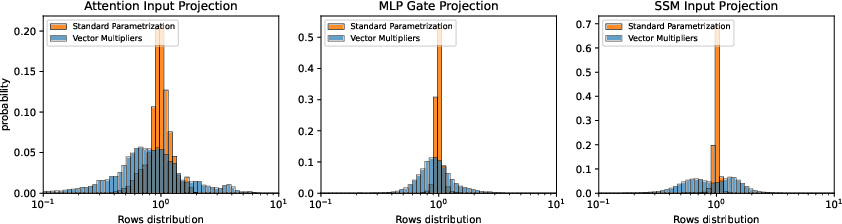
Widthwise analysis shows that vector multipliers produce significantly broader distributions of row norms within crucial projections (gate, attention, SSM input layers), implying enhanced feature diversity and specialization (Figure 4).
Figure 4: Distributions of row norms ∥Wi∙∥ widened by vector LRMs, enabling richer internal feature scales.
Architectural Symmetries and Stability
Though LRMs are not subject to WD trapping, architectural symmetries such as multiplicative and residual normalization can cause unbounded drift, quantization error, or divergent training (especially in low-precision arithmetic). The paper systematically identifies these symmetries (e.g., redundant product factors, unnormalized residual propagation) and demonstrates that applying a small WD on LRMs suffices to contain unstable drift without sacrificing scale adaptation (see Figure 3 for blockwise symmetry effects).
Scaling Laws and μP Connection
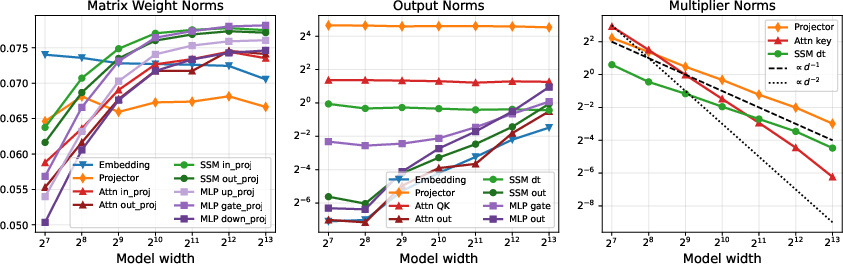
The introduction of LRMs impacts scaling laws, particularly maximal update parametrization (μP). Traditional μP relies on hyperparameter and forward multiplier tuning for cross-width stability. Here, LRMs learn optimal scaling directly, reducing the tuning overhead while maintaining stable activation scaling across widths (Figure 5).
Figure 5: Width scaling for layer matrices and select activations demonstrates that LRMs preserve constant output scales as model size varies.
Minor misalignments in scaling of learned multipliers suggest that future generalization of μP scaling rules may be required, especially as alignment between weights and inputs appears to decay with increasing width, an effect unexplained by classical infinite-width arguments.
Training Dynamics and Optimization
Gradient clipping, commonly adopted for stability, can suppress beneficial gradient flow through multipliers due to disproportionately large multiplier gradients. Empirical results indicate that excluding LRMs from global gradient norm computation during clipping solves this issue and restores the performance boost (Figure 6).
Figure 6: Excluding multiplier gradients from global clipping rapidly reduces the loss and avoids suppression of useful updates.
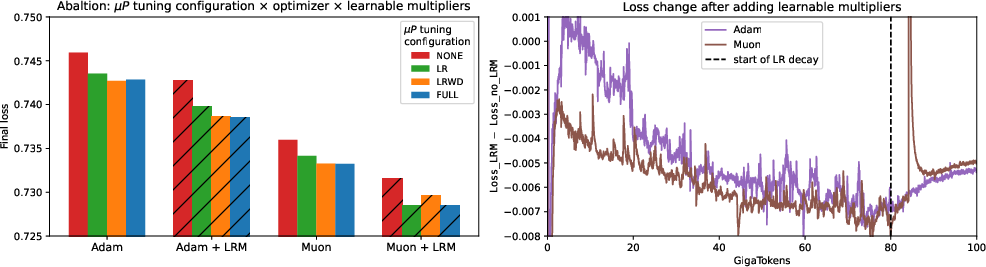
Tuning Ablations and Benchmark Performance
Ablation studies across configurations (combinations of tuned and untuned LR, WD, and forward multipliers) and optimizers (Adam, Muon) show:
LR multiplier tuning remains critical; forward and WD tuning become redundant.
LRMs confer universal benefit regardless of optimizer or initial multiplier configuration, consistently improving both general knowledge (ARC, MMLU) and reasoning-heavy benchmarks (BBH, GSM8K, MATH lvl5) with gains of +1.10 to +1.21 average score points after extensive pretraining.
Figure 7: Loss curves for different tuning configurations illustrate consistent gain from LRMs independent of optimizer or WD/forward tuning.
Implications and Future Directions
Practical Ramifications
Integrating LRMs requires no inference overhead and minimizes hyperparameter tuning, which is a major advantage in compute-intensive LLM training. LRMs provide adaptive scale adjustment that benefits both architectural expressivity and optimization, especially in deeper or wider networks, and raise the baseline for future LLM optimization methodology.
Theoretical Considerations
The work reveals previously underappreciated separation between "noise-dominated" matrices and "signal-dominated" scalar/vector weights, suggesting that parameterization strategies in deep networks can be further refined using noise metrics. This may prompt investigations into the design of scaling rules in the presence of LRMs and facilitate generalizations of μP for infinite-width, feature-learning regimes.
Additionally, observed differential benefits across benchmark types point toward a connection between scale diversity and learned circuit specialization.
Directions for Research
Future work should focus on:
Deriving comprehensive scaling laws generalizing μP to LRM-augmented architectures.
Mechanistic investigation of noise vs. signal dominance in weight parameter evolution, potentially informing automatic scale adaptation criteria.
Probing the connection between LRMs, reasoning capability, and the learning of distinct circuit structures.
Exploring further flaws of standard training protocols that may benefit from architectural intervention analogous to learnable multipliers.
Conclusion
The authors conclusively demonstrate that WD-noise equilibrium imposes rigid norm constraints on matrix weights in LLMs, inhibiting optimal representation learning. By introducing learnable multipliers at the scalar and vector level, these constraints are effectively removed, leading to improved benchmark performance and stronger, more data-adaptive internal scales—without inference costs. LRMs represent a universal architectural and optimization augmentation with immediate practical benefits and significant theoretical ramifications for future model scaling, parametrization, and optimization strategies.