Weight Decay Improves Language Model Plasticity
Abstract: The prevailing paradigm in LLM development is to pretrain a base model, then perform further training to improve performance and model behavior. However, hyperparameter optimization and scaling laws have been studied primarily from the perspective of the base model's validation loss, ignoring downstream adaptability. In this work, we study pretraining from the perspective of model plasticity, that is, the ability of the base model to successfully adapt to downstream tasks through fine-tuning. We focus on the role of weight decay, a key regularization parameter during pretraining. Through systematic experiments, we show that models trained with larger weight decay values are more plastic, meaning they show larger performance gains when fine-tuned on downstream tasks. This phenomenon can lead to counterintuitive trade-offs where base models that perform worse after pretraining can perform better after fine-tuning. Further investigation of weight decay's mechanistic effects on model behavior reveals that it encourages linearly separable representations, regularizes attention matrices, and reduces overfitting on the training data. In conclusion, this work demonstrates the importance of using evaluation metrics beyond cross-entropy loss for hyperparameter optimization and casts light on the multifaceted role of that a single optimization hyperparameter plays in shaping model behavior.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how a setting used during training LLMs called “weight decay” changes how easily those models can learn new tasks later. The authors call this ability to learn and adapt “plasticity.” They find that choosing the right amount of weight decay when first training a model can make it much better at picking up new skills during fine-tuning, even if its early test scores are not the best.
Key Objectives and Questions
The paper asks three simple questions:
- Does using more weight decay during pretraining make a LLM more “plastic” (better at learning new tasks later)?
- Is the best weight decay for early training scores also the best for later, real-world tasks?
- What is happening inside the model that explains why weight decay helps with plasticity?
Methods and Approach
The researchers trained several LLMs (from the Llama-2 and OLMo-2 families) with different sizes, up to 4 billion parameters. They changed only one setting during pretraining: how much weight decay to use. Then they fine-tuned those models on six “chain-of-thought” tasks (like math reasoning and reading comprehension) and measured how well they did.
Here are the main ideas, explained with everyday language:
- Pretraining vs. Fine-tuning: Think of pretraining like a model’s “school,” where it learns general language from lots of text. Fine-tuning is like “tutoring,” where the model practices specific skills (math problems, medical questions, etc.).
- Weight Decay: Imagine you’re building a robot that learns by adjusting lots of tiny knobs. Weight decay gently pushes those knobs back towards zero over time. It keeps the robot from over-complicating its internal settings, which can make it more stable and easier to teach later.
- Plasticity: This is how flexible the model is — like clay that can still be shaped after it’s baked a bit. A plastic model can adjust well when you teach it new tasks.
- Tokens-per-Parameter (TPP): A way to describe how long the training lasts compared to the model’s size. “20 TPP” is a shorter, “compute-optimal” training; “140 TPP” means training much longer.
- Evaluation: They tested models by asking them questions multiple times and checking:
- If a single answer was correct (Pass@1).
- If many sampled answers contained any correct one (Pass@16).
- If picking the most “high-quality” answer (with a reward model) was correct.
- The overall quality of responses.
- Peeking Inside the Model:
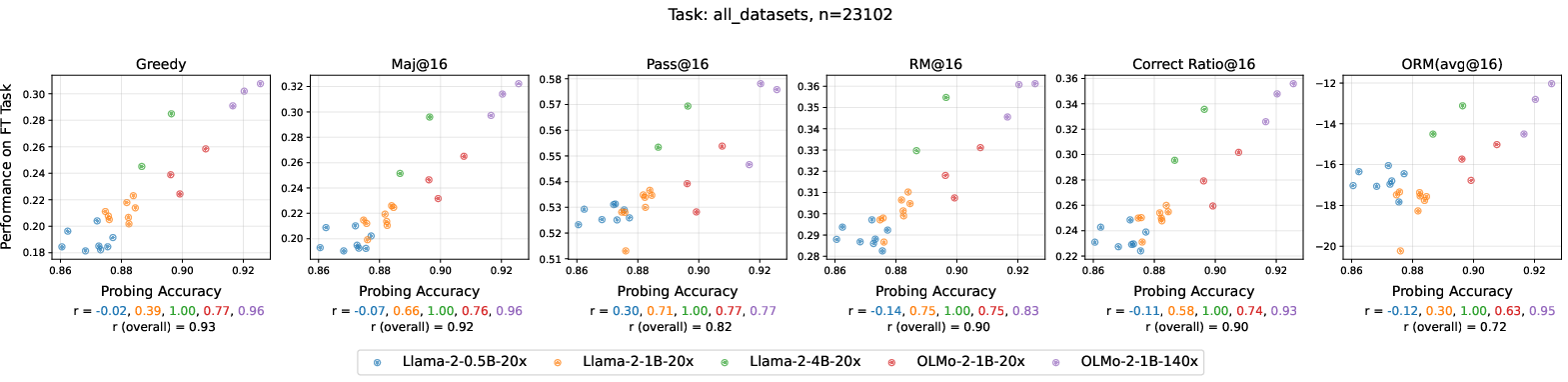
- Linear Probes: A simple test that checks how clearly the model’s internal representations separate different types of text (like positive vs. negative reviews). If a basic classifier can do well, the representations are “clean” and easy to use.
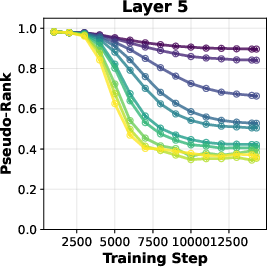
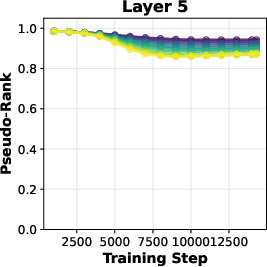
- Attention Matrices and Rank: Parts of the model decide what words to focus on. “Rank” is a way to measure how complex these parts are. Lower rank often means simpler, more general patterns.
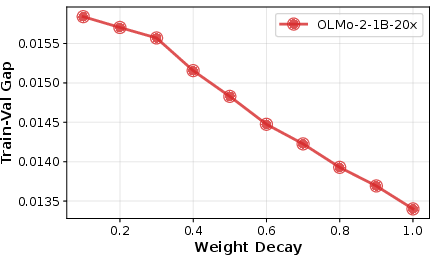
- Overfitting: When a model memorizes training data too much, it struggles to learn new things. They measured how much the model overfits by comparing performance on training vs. validation data.
Main Findings and Why They Matter
In short, using more weight decay during pretraining usually made models more adaptable later. Here’s what stood out:
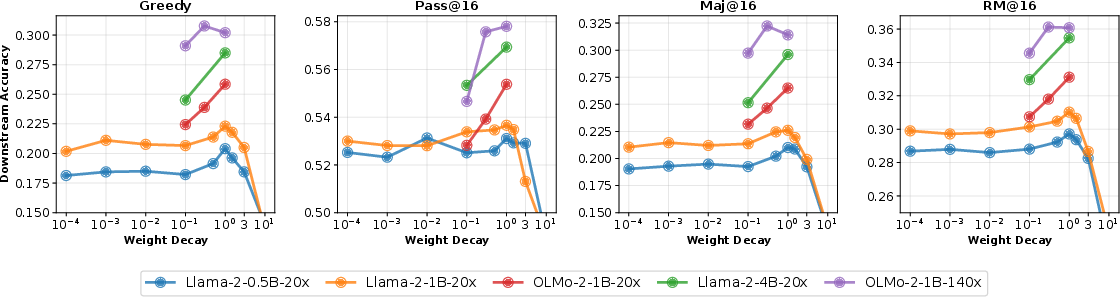
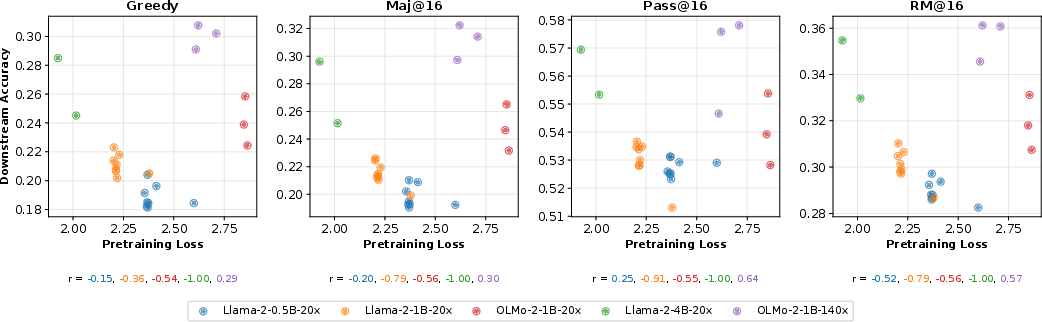
- More weight decay → better plasticity: Models trained with higher weight decay learned new tasks more effectively during fine-tuning and performed better across many benchmarks.
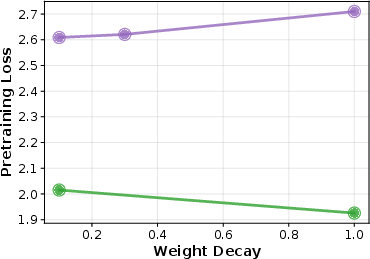
- Pretraining scores aren’t the full story: A model with slightly worse early scores (higher validation loss) sometimes did better after fine-tuning. That means picking models only by their pretraining test scores can miss the ones that will be best after tutoring.
- The “best” weight decay depends on your goal:
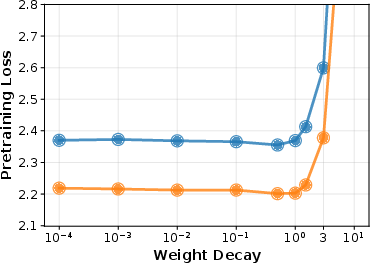
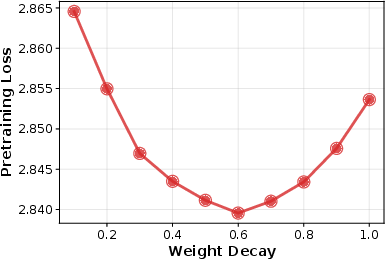
- For shorter, compute-optimal training (20 TPP), larger values (around 1.0) gave the best downstream performance.
- For longer training (140 TPP), a smaller value (around 0.3) worked best for downstream performance.
- Why this likely happens inside the model:
- Representations become cleaner and more “linearly separable,” so simple tools can read them. Think of tidy notes in labeled folders vs. a messy pile.
- Attention parts become lower rank (simpler), which may prevent overfitting to tiny details and help generalization.
- Overfitting drops as weight decay increases, making the model more willing to “forget” unnecessary training quirks and learn new tasks.
To make the main results easy to scan, here is a short list:
- Higher weight decay often improves downstream performance (plasticity).
- The weight decay that minimizes pretraining loss is not always best for later tasks.
- Mechanisms: cleaner representations, simpler attention, less overfitting.
Implications and Potential Impact
This work suggests teams training LLMs shouldn’t choose pretraining settings just to get the lowest early validation loss. Instead, they should consider the model’s future: how easily can it be fine-tuned for real tasks? Using more weight decay during pretraining can make models more flexible and practical after tutoring.
It also highlights trade-offs. If you train very long or have very large models, chasing the lowest pretraining loss might help — but you might sacrifice adaptability. Future research could test these ideas on even bigger models, different kinds of foundation models (like multimodal), and goals beyond accuracy (like safety and alignment).
Overall, the message is simple: tune models not just to look good in school (pretraining), but to learn well in the real world (fine-tuning). Weight decay is a small dial that can have a big effect on that outcome.
Knowledge Gaps
Here is a concise list of the paper’s unresolved gaps, limitations, and open questions that future work could address:
- Scale external validity: Do the reported plasticity gains from higher pretraining weight decay (WD) persist for larger, frontier-scale models (>4B, >10B, >70B) and mixture-of-experts architectures?
- Training-duration generality: How do results extrapolate beyond the two TPP regimes (20 and 140) to much longer training (e.g., >300 TPP), multi-epoch pretraining, or curriculum schedules?
- Optimizer dependence: Do the effects hold under alternative optimizers (Adafactor, Lion, Sophia, SGD+momentum) and alternative decoupled L2 implementations?
- Effective step-size confound: Since WD in AdamW affects effective step size, can matched-step-size controls disentangle WD’s effect from implicit learning-rate changes?
- Interaction with other hyperparameters: How do WD–learning rate–batch size–β1/β2–gradient clipping interactions shape plasticity; are there joint optima?
- Parameter-group WD choices: Which parameter subsets were decayed (e.g., embeddings, LayerNorm, biases)? How do module-wise WD policies affect plasticity and mechanisms?
- WD scheduling: Would dynamic schedules (e.g., cosine/phase-wise WD, layer-wise WD, early/late WD) outperform constant WD for downstream adaptability?
- Fine-tuning protocol breadth: Do results transfer from full-parameter supervised fine-tuning (SFT) to LoRA/adapter-based tuning, PEFT, prefix tuning, or partial-layer updates?
- Post-training paradigms: How does pretraining WD affect performance in RLHF, DPO, KTO, safety alignment, or preference-model–guided optimization?
- Task coverage: Are plasticity gains consistent for non-CoT tasks (code generation, multilingual QA, translation, summarization, retrieval-augmented tasks, tool use)?
- Sample efficiency: Does higher pretraining WD improve adaptation speed and data efficiency (accuracy vs. number of SFT steps/examples), not just final accuracy?
- Continual learning: In multi-round or multi-task sequential fine-tuning, does higher pretraining WD improve plasticity while controlling catastrophic forgetting across rounds?
- Stability–plasticity trade-off: Does improved plasticity from higher WD cause greater forgetting of pretraining capabilities after SFT on new tasks? Quantify retention–adaptation curves.
- Measurement of plasticity: Beyond downstream accuracy and ORM scores, can plasticity be assessed via parameter-distance moved during SFT, Fisher information changes, or gradient alignment?
- Statistical robustness: How stable are the findings across random seeds, data shuffles, and multiple repeats? Provide confidence intervals and significance tests.
- Dataset and domain generality: Are effects robust across different pretraining corpora (quality, domain composition, contamination levels), not just FineWeb-Edu and OLMo-Mix?
- Tokenization confounds: Given differing vocabularies across model families, how do tokenizer choices interact with WD’s effects on representation structure and plasticity?
- Mechanism causality: The links between linear separability, attention low-rankness, reduced overfitting, and plasticity are correlational. Can causal interventions (e.g., spectral penalties to control rank independently of WD) validate mechanisms?
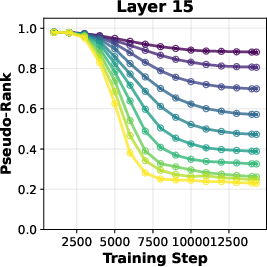
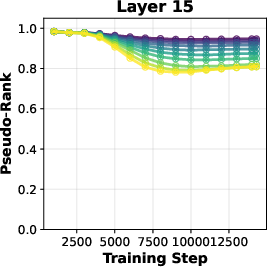
- Attention-rank methodology: The “pseudo-rank” metric and thresholding choices may affect conclusions. How sensitive are rank findings to thresholds, layers, and evaluation times?
- Representation analysis breadth: Do WD-induced changes generalize beyond sentiment/topic linear probes (e.g., CKA/SVCCA, probing for syntax, coreference, math features) and link to reasoning tasks?
- Module-specific effects: Which layers or blocks (early vs. late, attention vs. MLP, LM head vs. embeddings) contribute most to WD-driven plasticity changes?
- Fine-tuning hyperparameter fairness: SFT settings were fixed across models; do conclusions hold if SFT hyperparameters are tuned per-pretrained model to equalize adaptation conditions?
- WD during SFT: The SFT weight decay setting is unspecified. How do pretraining WD benefits interact with different SFT WD choices or regularizers?
- Regularizer comparisons: How does pretraining WD compare against or combine with other regularizers (dropout, mixout, weight noise, label smoothing, shrink-and-perturb) for plasticity?
- Memorization and privacy: Beyond train–val gap, does WD reduce memorization risks (membership inference, extraction attacks) while preserving plasticity?
- Training stability and compute: What are the divergence rates, gradient-noise scales, and compute/throughput impacts at higher WD; are there practical stability constraints?
- Practical selection rule: Can one derive a predictive rule or scaling law to set pretraining WD from TPP, model size, data quality, and intended downstream procedure?
- Cross-evaluator robustness: ORM-based quality results may depend on the chosen reward model. Do conclusions hold across multiple ORMs and human evaluation?
- Inference behavior: How does pretraining WD affect calibration, uncertainty, and hallucination tendencies post-SFT, not just accuracy/Pass@k?
- Compression and adaptation: Does WD-induced lower rank enable better low-rank adaptation (e.g., LoRA) or model compression without hurting plasticity?
- Multimodal generalization: Do the findings extend to multimodal foundation models (vision–language, audio–text), where attention and representation dynamics differ?
Practical Applications
Overview
This paper shows that increasing weight decay during LLM pretraining can substantially improve model plasticity—i.e., the ability of a base model to adapt during subsequent fine-tuning—even when it slightly worsens pretraining validation loss. Mechanistically, higher weight decay encourages more linearly separable representations, regularizes attention matrices toward lower rank, and reduces overfitting. Practically, this reframes hyperparameter optimization for LLMs as an end-to-end, downstream-aware process rather than focusing solely on pretraining loss.
Below are practical applications, organized by time horizon, with sector links, potential tools/workflows, and key assumptions or dependencies.
Immediate Applications
The following items can be piloted or deployed now with current tooling and standard training stacks.
- Plasticity-aware hyperparameter optimization in pretraining (Industry, Academia; Software)
- Use case: During base model pretraining, include weight decay sweeps that extend beyond the common 0.1 default (e.g., 0.3–1.0 for compute-optimal ~20 TPP), then select checkpoints that maximize downstream fine-tuned performance on representative tasks.
- Tools/workflows: Ray Tune/Optuna for HPO; automated pretrain→SFT→eval loops using Pass@k, Maj@k, Correct Ratio, and reward-model (ORM) scores; a simple “Plasticity Score” (composite of these metrics) for model selection.
- Assumptions/dependencies: Access to the pretraining pipeline; compute budget for HPO; representative fine-tuning tasks without data leakage; results validated up to 4B params and 20–140 TPP—extrapolation to larger scales requires caution.
- Pretrained-model selection and procurement criteria (Industry, Policy; Cross-sector)
- Use case: Buyers of base models request and evaluate “adaptability” documentation (weight decay, TPP, plasticity metrics) from vendors; prefer checkpoints shown to fine-tune better on their domains.
- Tools/workflows: RFP templates including plasticity metrics; SLAs for adaptability (e.g., “X% gain after Y steps on domain Z”).
- Assumptions/dependencies: Vendor transparency; standardized plasticity reporting.
- Faster, cheaper domain adaptation for regulated sectors (Healthcare, Finance, Legal, Education)
- Use case: Choose base checkpoints trained with higher weight decay to reduce fine-tuning steps or data required for hospital-specific QA, regulatory compliance assistants, or curriculum-aligned tutors.
- Tools/workflows: SFT with reduced epochs; sample-based evaluation (Pass@16, Maj@16); domain reward models for quality assessment.
- Assumptions/dependencies: Availability of suitable base checkpoints; careful validation for safety and compliance; results in paper focused on CoT tasks—verify on target domains.
- Continual or periodic update workflows with stability–plasticity monitoring (Software, MLOps)
- Use case: For weekly/monthly model refreshes, prefer plasticity-optimized base checkpoints; monitor stability vs plasticity using train–val gaps and probe metrics.
- Tools/workflows: Train–val gap dashboards; linear probes (e.g., SST-2, AG News) per layer; attention pseudo-rank monitors to detect harmful rank collapse.
- Assumptions/dependencies: Access to validation data; added monitoring compute; calibration to avoid over-regularization.
- Privacy and contamination risk mitigation (Policy, Industry; Compliance)
- Use case: Leverage higher weight decay to reduce overfitting and inadvertent memorization (e.g., contaminated benchmarks, PII), as part of privacy-by-design and evaluation regimes.
- Tools/workflows: Canary testing, memorization audits, contaminated-data detection; documentation linking weight decay settings to overfitting metrics.
- Assumptions/dependencies: Not a guarantee of non-memorization; still requires red-teaming, legal compliance, and auditing; risk varies by data mix and training duration.
- RLHF/alignment bootstrapping (Software, Safety)
- Use case: Start RLHF and instruction tuning from higher weight-decay bases to improve adaptation efficiency and end quality after preference optimization.
- Tools/workflows: Pre-RLHF plasticity eval suite; early stopping based on downstream metrics rather than pretraining loss alone.
- Assumptions/dependencies: Interactions with KL penalties, reward-model biases, and RLHF schedules; validate per pipeline.
- Early-warning diagnostics during training (Software, Research)
- Use case: Use linear probe accuracy and attention pseudo-rank as early signals to steer weight decay choices, catching harmful extremes before full runs complete.
- Tools/workflows: Mid-epoch probe and SVD routines; alerts when attention rank collapses or probes plateau abnormally.
- Assumptions/dependencies: Added overhead; proxy signals need local calibration.
- Academic reporting and benchmarks (Academia)
- Use case: Report plasticity metrics alongside pretraining loss when releasing new base models; evaluate across multiple tasks/metrics (Pass@k, ORM) to reflect downstream fitness.
- Tools/workflows: Open-source scripts for pretrain→SFT→eval; standardized task bundles (e.g., MMLUProCoT, MedMCQA, PubMedQA, RACE, math datasets).
- Assumptions/dependencies: Community adoption; reproducible evaluation protocols.
Long-Term Applications
The following items require further research, engineering, or scaling to larger models and diverse domains.
- Plasticity-aware scaling laws and training planning (Industry, Academia)
- Use case: Extend scaling laws to jointly optimize pretraining validation loss and post-training performance, modeling optimal weight decay as a function of size, TPP, and domain.
- Tools/workflows: Multi-run studies across sizes and TPP; budget planners that trade off pretraining loss vs plasticity.
- Assumptions/dependencies: Significant compute; generalization to 10s–100s of billions of parameters remains to be established.
- Adaptive/scheduled weight decay and per-layer policies (Software, Research)
- Use case: Design schedules or layer-wise weight decay to maintain optimization stability early while preserving plasticity later; or adaptively target attention submodules.
- Tools/workflows: AdamW variants with dynamic decay; per-layer controllers; policy-gradient or Bayesian controllers for hyperparameters.
- Assumptions/dependencies: Algorithmic advances; careful testing to avoid underfitting or rank collapse.
- Architectures and tokenization for plasticity (Software, Robotics, Multimodal)
- Use case: Introduce architectural biases that synergize with weight decay (e.g., low-rank-friendly attention, modified normalization) and tokenization schemes that promote linear separability.
- Tools/workflows: Architecture search with plasticity objectives; multimodal extensions (VLMs/VLA models).
- Assumptions/dependencies: Substantial experimentation; domain and modality variability.
- Production-grade continual learning stacks (Industry, Robotics, Education)
- Use case: Build systems that continuously adapt with minimal catastrophic forgetting by combining higher weight decay bases with replay, elastic constraints, or low-rank adapters.
- Tools/workflows: Retrieval/replay stores; EWC-like regularizers; LoRA and low-rank constraints aligned with weight decay effects; governance controls.
- Assumptions/dependencies: Data governance and safety; evaluation sandboxes; robust rollback paths.
- Standards, benchmarks, and regulation for adaptability (Policy, Standards Bodies)
- Use case: Define “model adaptability” benchmarks and disclosures for procurement (e.g., government, healthcare); include memorization/overfitting metrics in compliance audits.
- Tools/workflows: Vendor-neutral “Plasticity Score” benchmark suite; audit frameworks tying weight decay and TPP to risk profiles.
- Assumptions/dependencies: Multi-stakeholder consensus; clear, testable definitions.
- Unlearning and data deletion support (Policy, Software)
- Use case: Explore whether bases trained with higher weight decay facilitate faster or more reliable post hoc unlearning, due to reduced overfitting and more structured representations.
- Tools/workflows: Certified unlearning protocols; measurement of residual influence after deletion requests.
- Assumptions/dependencies: Active research area; legal standards for “effective unlearning” still evolving.
- Energy and cost efficiency programs (Energy, Finance, Sustainability)
- Use case: If plastic models reach target performance in fewer tuning steps, organizations can set carbon and cost budgets around downstream training rather than just pretraining loss.
- Tools/workflows: Carbon calculators tied to SFT convergence; budgeting dashboards incorporating adaptability gains.
- Assumptions/dependencies: Realized step reductions must be validated per task; efficiency gains may vary by domain and size.
- Sector-specific product lines optimized for adaptability (Healthcare, Finance, Legal, Education)
- Use case: Launch “adapt-ready” foundation model families whose checkpoints are tuned for responsiveness to rapid domain shifts (e.g., new treatment guidelines, new regulations, new curricula).
- Tools/workflows: Scheduled checkpoint releases with plasticity certifications; plug-and-play SFT kits and evaluation harnesses per sector.
- Assumptions/dependencies: Continuous domain data access; rigorous post-adaptation validation for safety and bias.
- Robotics and embodied AI transfer (Robotics)
- Use case: Pretrain policy or VLA models with plasticity-oriented regularization to improve adaptation to new tasks/environments with small amounts of experience.
- Tools/workflows: Simulation-to-real fine-tuning pipelines; low-rank adapters aligned with weight decay effects on attention.
- Assumptions/dependencies: Extension from language to sensorimotor domains; hardware-in-the-loop evaluation.
- Cross-team training-to-product workflows (Industry, MLOps)
- Use case: Operationalize end-to-end objectives that align pretraining teams and product teams on downstream targets; adopt decision policies where a slightly worse pretraining loss is acceptable if downstream wins are consistent.
- Tools/workflows: Shared KPI dashboards (pretraining loss, plasticity score, downstream quality); governance for objective trade-offs.
- Assumptions/dependencies: Organizational buy-in; clear prioritization of downstream outcomes.
Key cross-cutting assumptions and limitations
- External validity: Results demonstrated on Llama-2/OLMo-2 up to 4B parameters and TPP 20/140; behavior at much larger scales and longer training remains to be confirmed.
- Task coverage: Benchmarks emphasize chain-of-thought and reasoning tasks; domain-specific or multimodal tasks require separate validation.
- Hyperparameter interactions: Optimal weight decay depends on TPP, size, optimizer schedules, and data; overly high values can harm pretraining loss and sometimes downstream performance.
- Metric choices: Some evaluation relies on reward models (e.g., Skywork ORM); conclusions can be sensitive to the choice and calibration of these models.
- Compute and data: End-to-end HPO with downstream evaluation adds cost and complexity; benefits must justify overheads per use case.
In practice, the paper’s central implication is to treat weight decay as a lever for post-training performance and to retool training and selection workflows around end-to-end objectives—especially when the final product is a fine-tuned model rather than a standalone base.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient-based update in Adam to improve regularization and stability. "Weight decay in AdamW."
- Alignment: Post-training techniques to align model behavior with human preferences or norms. "alignment, and reinforcement learning"
- Attention matrices: The parameter matrices in transformer attention (e.g., query-key and value-projection products) that determine how tokens attend to each other. "regularizes attention matrices"
- Bilinear form: A matrix expression of the form xT W x used here to describe attention score computation. "a bilinear form "
- Chain-of-Thought (CoT): A prompting/solution style that elicits intermediate reasoning steps to improve reasoning performance. "six Chain-of-Thought (CoT) tasks"
- Chinchilla-optimal: The compute-optimal scaling setting balancing data and model size per Chinchilla scaling laws. "20 TPP Chinchilla-optimal ratio"
- Compute-optimal: A training regime that optimally allocates compute across model size and data for best performance per token budget. "compute-optimal (20 tokens-per-parameter, TTP hereafter)"
- Cross-entropy loss: A negative log-likelihood objective commonly used for LLM training and validation. "validation cross-entropy loss"
- Decoupled updates: Separate application of weight decay and gradient steps in optimizers like AdamW. "performs two decoupled updates"
- Downstream performance: Model performance on tasks after additional training such as fine-tuning. "downstream performance"
- End-to-end analysis framework: An evaluation approach that links pretraining choices to post-training outcomes in a single pipeline. "end-to-end analysis framework"
- Exponential moving average: A time-weighted averaging process with exponential decay over past values. "an exponential moving average"
- Greedy (Pass@1): Deterministic decoding that evaluates success by whether the single top-1 response is correct. "Greedy (i.e., Pass@1)"
- Linear probing: Training a linear classifier on frozen model representations to assess the linear separability of encoded features. "linear probing achieves better accuracy"
- Linearly separable representations: Feature embeddings that can be correctly classified by a linear decision boundary. "linearly separable representations"
- Low-rank attention: Attention-layer parameterizations with reduced matrix rank, often encouraged by regularization. "inducing low-rank attention layers"
- Maj@16: A metric marking a question correct if the majority answer among 16 sampled responses is correct. "the majority answer is correct (Maj@16)"
- Nuclear norm regularization: Regularization using the sum of singular values to promote low-rank structure in matrices. "nuclear norm regularization"
- Outcome Reward Model (ORM): A learned model scoring generated answers for quality, used to select or evaluate outputs. "outcome reward model (ORM; Skywork-Reward-Llama-3.1-8B-v0.2)"
- Overfitting: When a model fits training data too closely, harming generalization to validation/test data. "reduces overfitting on the training data"
- Overtrained regime: Training beyond the compute-optimal point, typically many more tokens per parameter. "overtrained (140 TPP) regimes"
- Pass@16: A metric marking a question correct if any of 16 sampled responses is correct. "Pass@16"
- Pearson correlation coefficient: A statistic measuring linear correlation between two variables. "Pearson correlation coefficient "
- Pseudo-rank: An empirical estimate of effective matrix rank based on singular value thresholds. "pseudo-rank"
- Query-key matrix (W_QK): The product W_KT W_Q whose bilinear form determines attention scores. "query-key ()"
- RM@16: A metric marking a question correct if the response with the highest ORM score among 16 samples is correct. "score is correct (RM@16)"
- Scaling laws: Empirical relationships describing how performance scales with model size, data, and compute. "scaling laws"
- Stability–plasticity dilemma: The trade-off between retaining prior knowledge (stability) and learning new information (plasticity). "stability-plasticity dilemma"
- Supervised fine-tuning (SFT): Post-training on labeled instruction–response pairs to adapt a pretrained model. "supervised fine-tuning (SFT)"
- Tokens per parameter (TPP) ratio: The number of training tokens per model parameter, indicating training duration relative to model size. "TPP ratio"
- Train–Val Gap: The difference between validation and training loss used as an overfitting indicator. "Train-Val Gap"
- Value-projection matrix (W_VP): The product W_P W_V that maps value vectors to output space in attention. "value-projection matrix "
- Warmup–cosine learning rate schedule: A schedule with an initial warmup phase followed by cosine decay. "standard warmup-cosine learning rate schedule"
- Weight decay: A regularization hyperparameter that shrinks weights during optimization to control capacity and dynamics. "Weight decay is a canonical hyperparameter"
- Zero-shot: Evaluating a model on tasks without any task-specific fine-tuning or examples. "in a zero-shot manner"
Collections
Sign up for free to add this paper to one or more collections.