Observations and Remedies for Large Language Model Bias in Self-Consuming Performative Loop
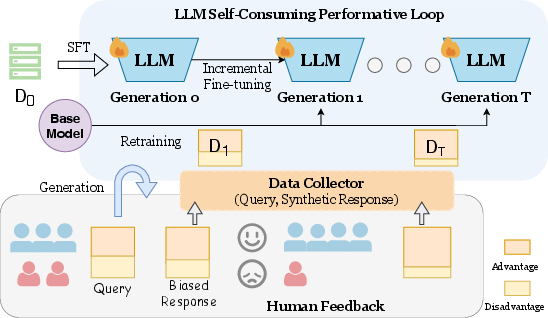
Abstract: The rapid advancement of LLMs has led to growing interest in using synthetic data to train future models. However, this creates a self-consuming retraining loop, where models are trained on their own outputs and may cause performance drops and induce emerging biases. In real-world applications, previously deployed LLMs may influence the data they generate, leading to a dynamic system driven by user feedback. For example, if a model continues to underserve users from a group, less query data will be collected from this particular demographic of users. In this study, we introduce the concept of \textbf{S}elf-\textbf{C}onsuming \textbf{P}erformative \textbf{L}oop (\textbf{SCPL}) and investigate the role of synthetic data in shaping bias during these dynamic iterative training processes under controlled performative feedback. This controlled setting is motivated by the inaccessibility of real-world user preference data from dynamic production systems, and enables us to isolate and analyze feedback-driven bias evolution in a principled manner. We focus on two types of loops, including the typical retraining setting and the incremental fine-tuning setting, which is largely underexplored. Through experiments on three real-world tasks, we find that the performative loop increases preference bias and decreases disparate bias. We design a reward-based rejection sampling strategy to mitigate the bias, moving towards more trustworthy self-improving systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at what happens when AI LLMs (like chatbots) are trained over and over on their own writing instead of on fresh human-written text. The authors call this a self-consuming performative loop (SCPL). They ask: Does this loop make the model more biased over time, and can we fix that?
Think of it like making a photocopy of a photocopy again and again: the picture may get blurrier, and certain parts might get emphasized without you noticing. Also, people’s reactions to the model affect what data it sees next. If the model treats one group better, that group keeps using it and sending more data, while other groups may leave—this changes the training data going forward.
Key Questions
- What happens to bias when models repeatedly learn from their own outputs?
- Does the model start favoring one group or viewpoint more (preference bias)?
- Does the performance gap between groups change (disparate bias)?
- Are there differences between two training styles:
- Retraining: starting each new model from the original base model each time.
- Incremental fine-tuning: continuing to train the current model step by step.
- Can we reduce growing bias using smarter ways to pick which AI-generated data to train on?
How They Studied It (In Simple Terms)
The researchers set up a careful, controlled “feedback loop” where:
- A model answers prompts.
- Those answers are used to create new training data.
- That new data trains the next version of the model.
- The loop repeats for several “generations.”
They also simulate a real-world effect called performative feedback: if the model performs better for one group (the “advantaged” group), people in that group keep asking it questions, so their data shows up more in training next time. People in the “disadvantaged” group ask fewer questions, so their data shrinks. Over time, this can bend the training data toward whoever the model already serves best.
They test this on three tasks:
- News continuation: The model continues a news article. They check if the model leans more right or left politically and measure writing quality.
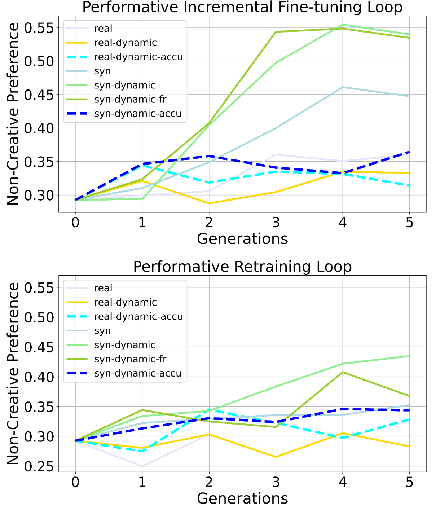
- Preference dissection: The model chooses between “non-creative” vs. “creative” styles to see if it starts preferring one style.
- Math problem solving: They compare performance on easy vs. hard questions (like seeing if the model gets lazier and forgets how to solve tough problems).
They study two training loops:
- Retraining: each new model is fine-tuned from the original base model using new (possibly synthetic) data.
- Incremental fine-tuning: each new model is trained on top of the previous one, which is more realistic when you can’t always start from scratch.
They also test “accumulation,” which means keeping and reusing all past data (not just the latest batch) to slow down quality loss.
Finally, they try a fix: reward-based rejection sampling. For each prompt, they generate several answers and score them (for quality and how well they balance preferences). Then they keep better-scoring answers and throw away poorer ones, guiding the training toward less biased data.
Main Findings
Here are the main takeaways from their experiments:
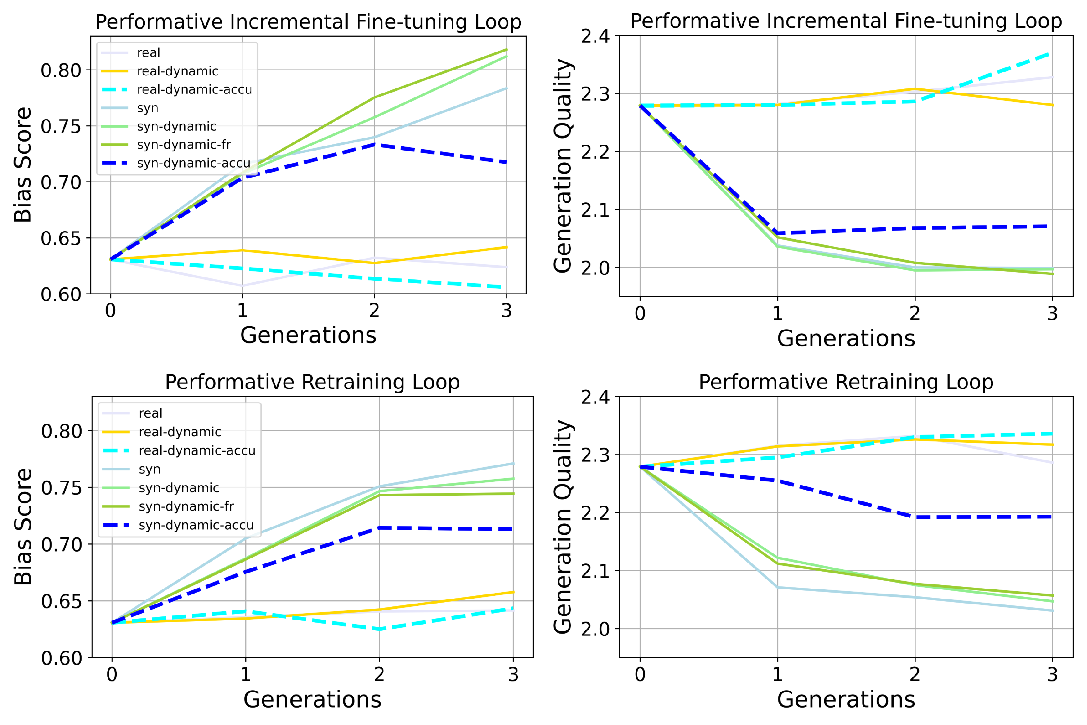
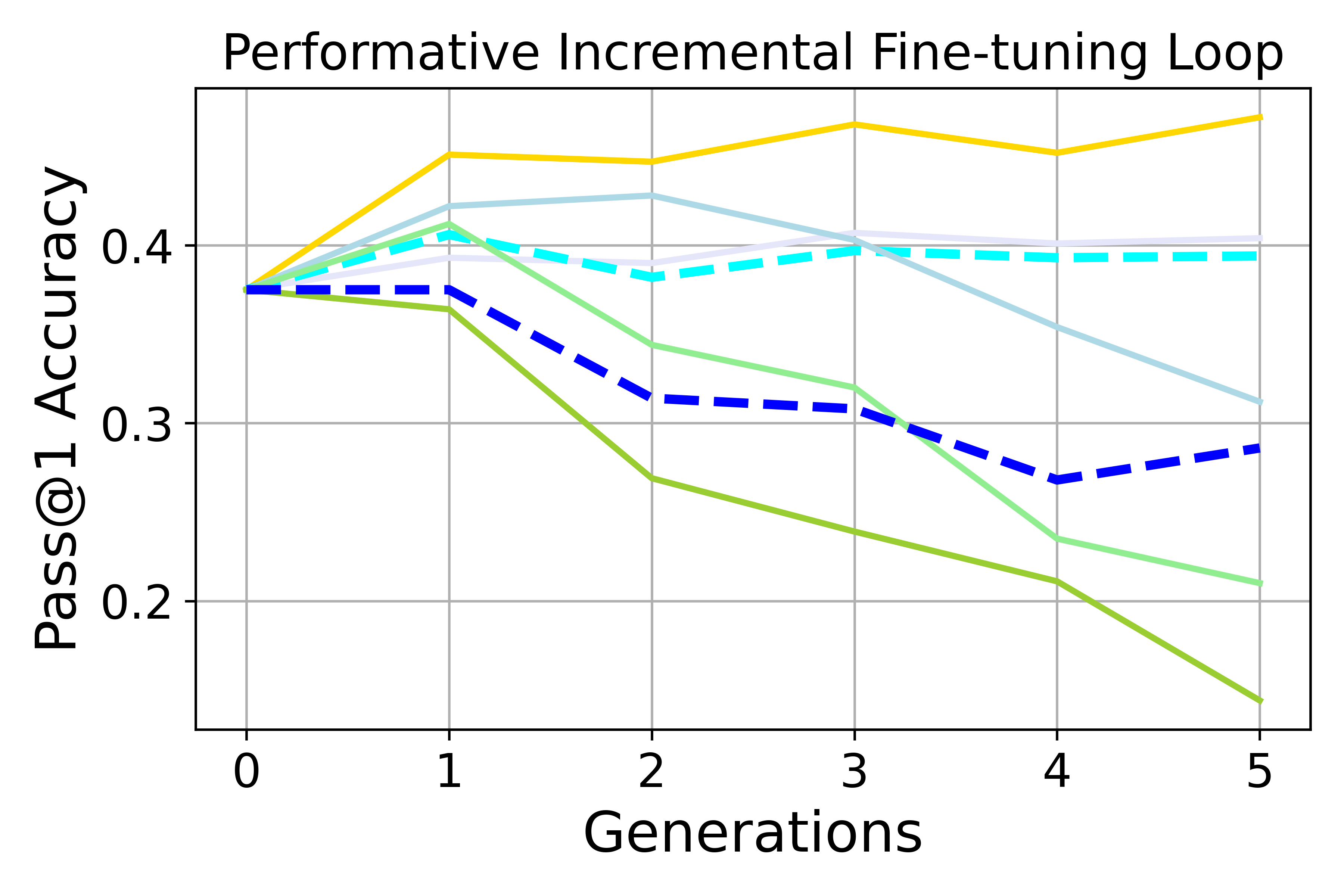
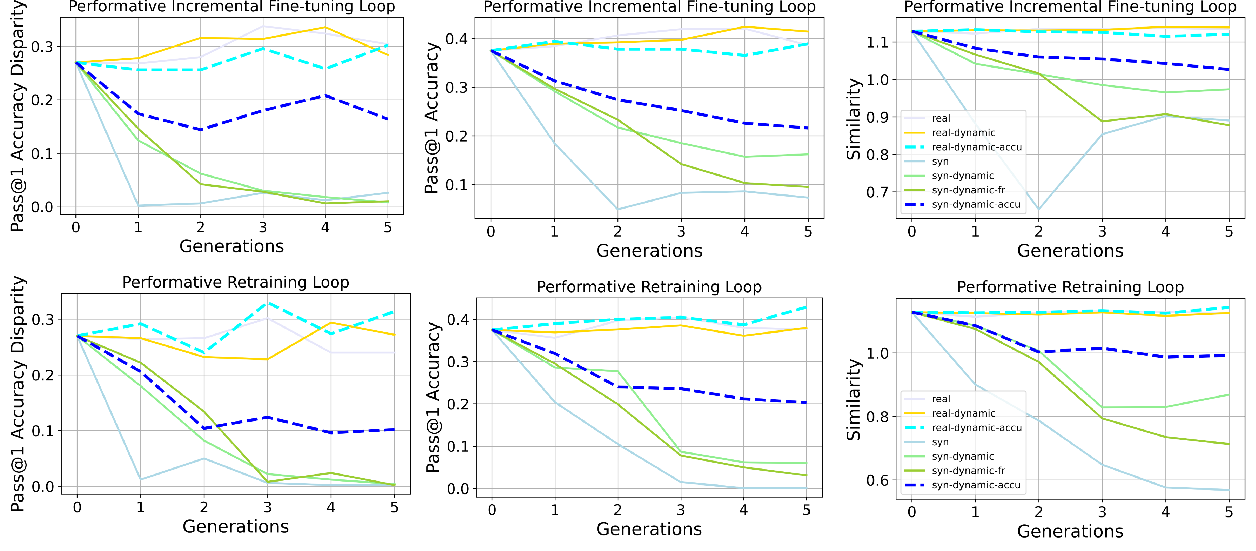
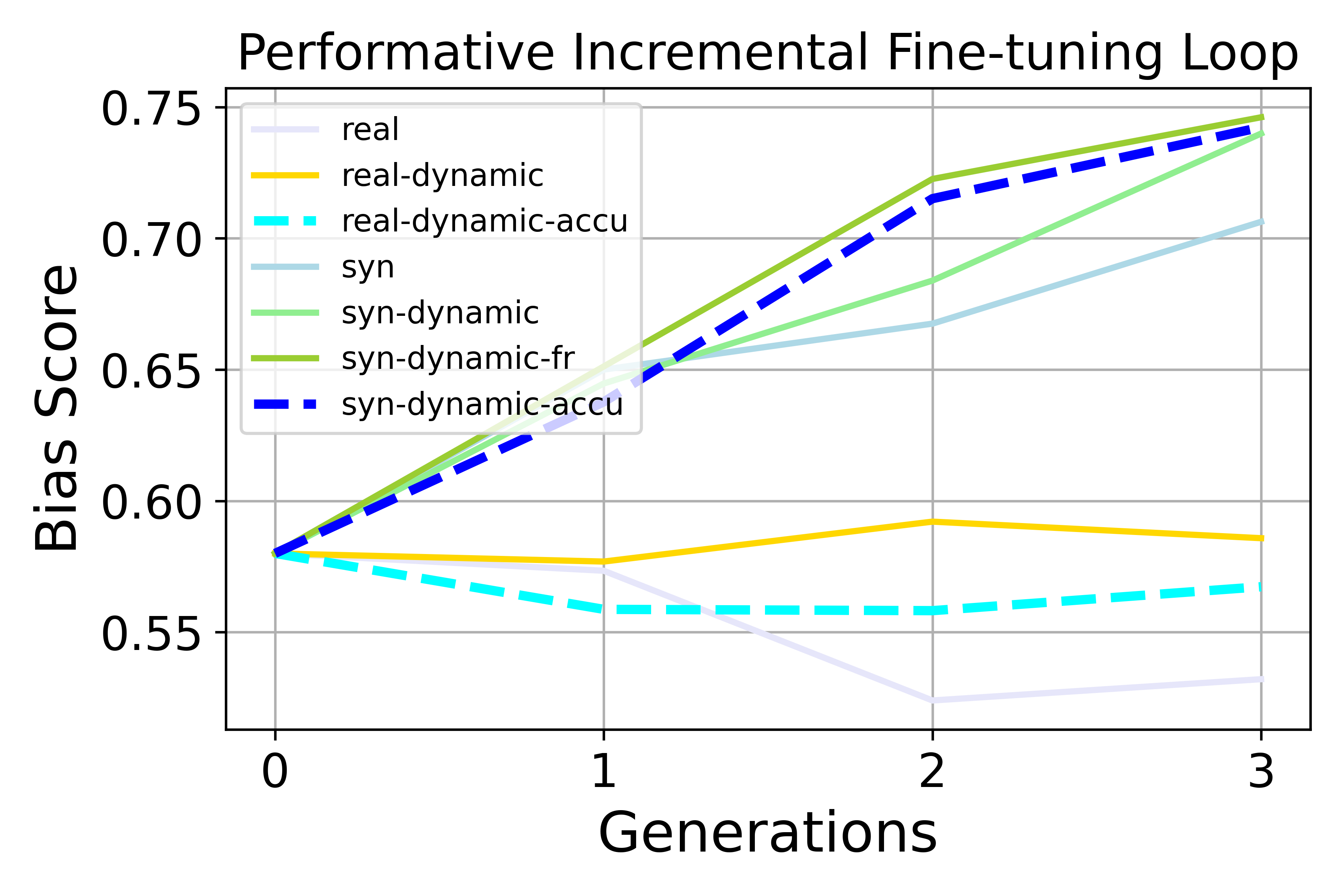
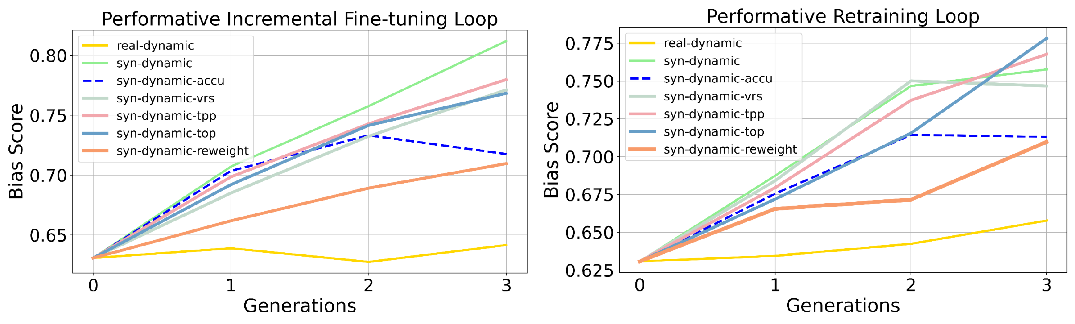
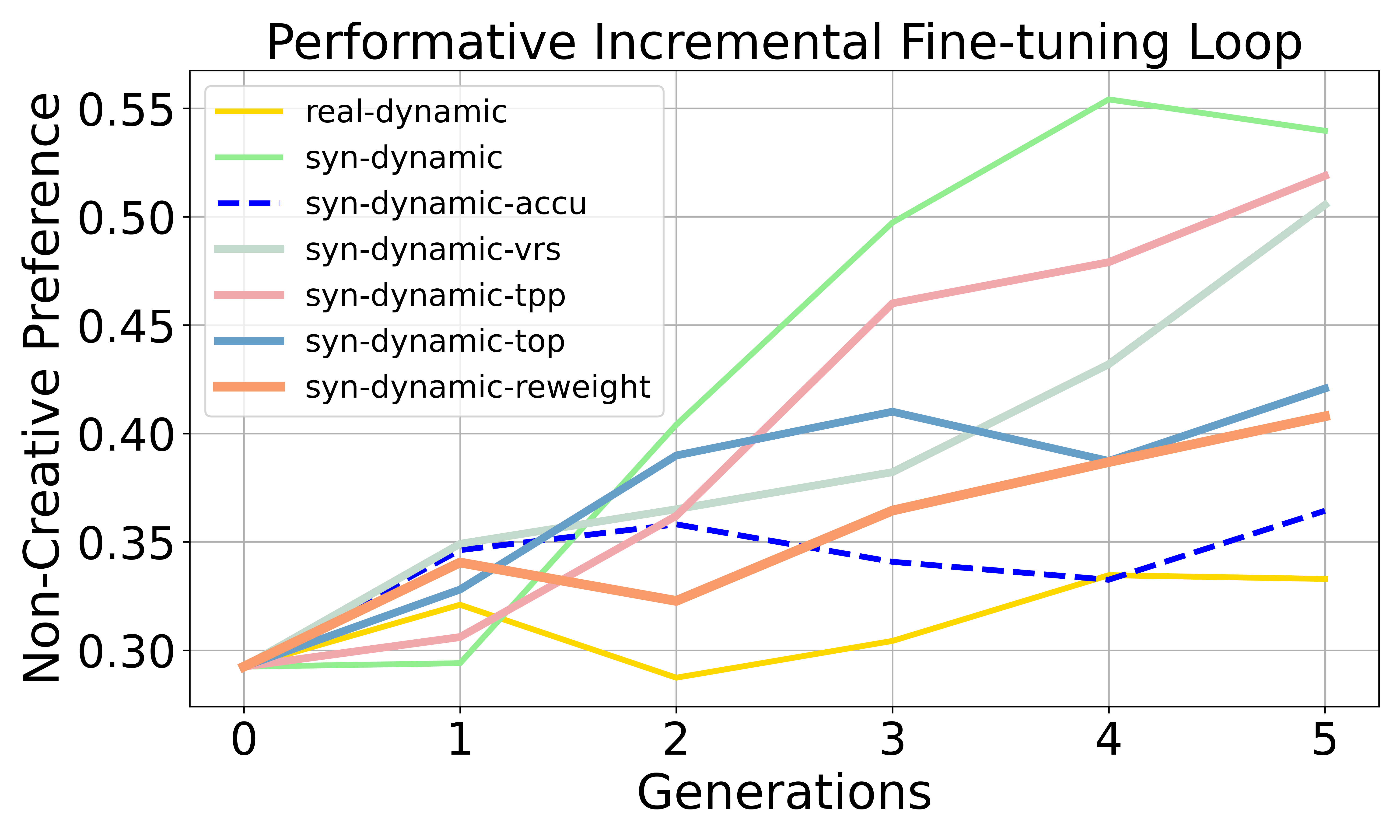
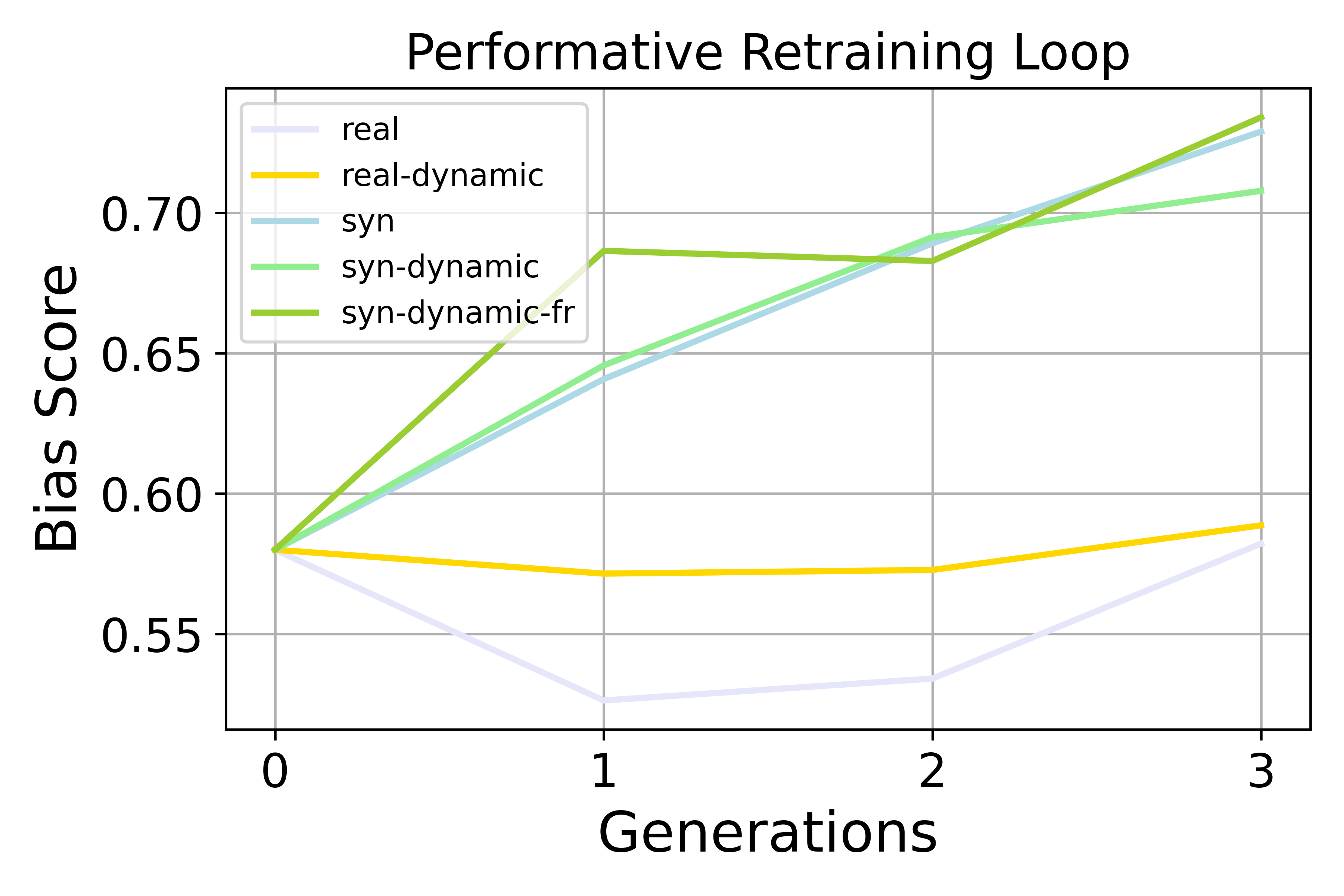
- Preference bias goes up. Over generations, the model increasingly favors the advantaged group or a dominant style (for example, leaning more toward one political side or preferring non-creative writing). This happens in both retraining and incremental fine-tuning loops, and it’s stronger when user feedback is “performative” (dynamic) and when using incremental fine-tuning.
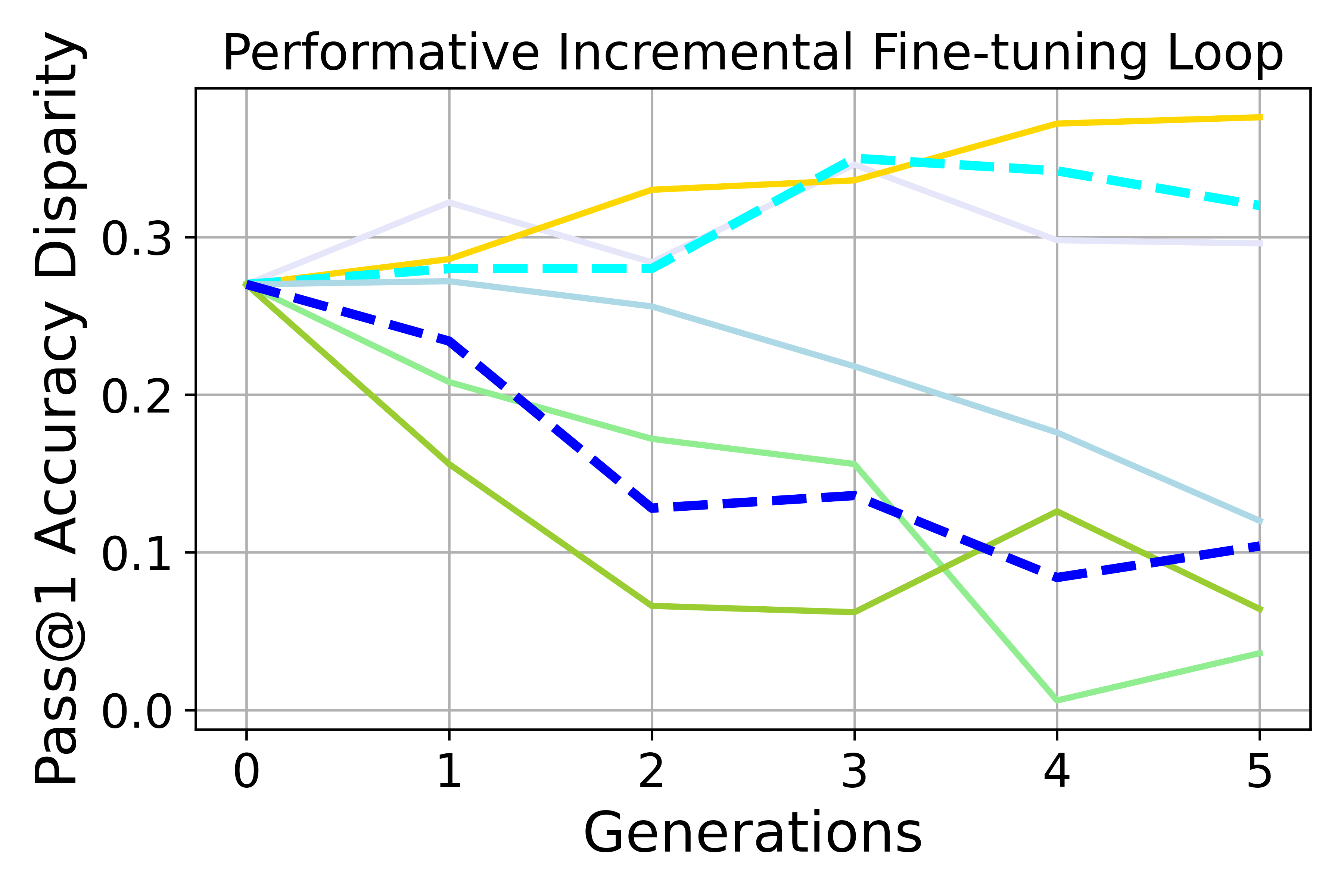
- Disparate bias goes down—but not for a good reason. The performance gap between groups (like easy vs. hard math) shrinks. However, this often happens because overall performance falls, especially on harder items, so both groups end up doing similarly—but worse.
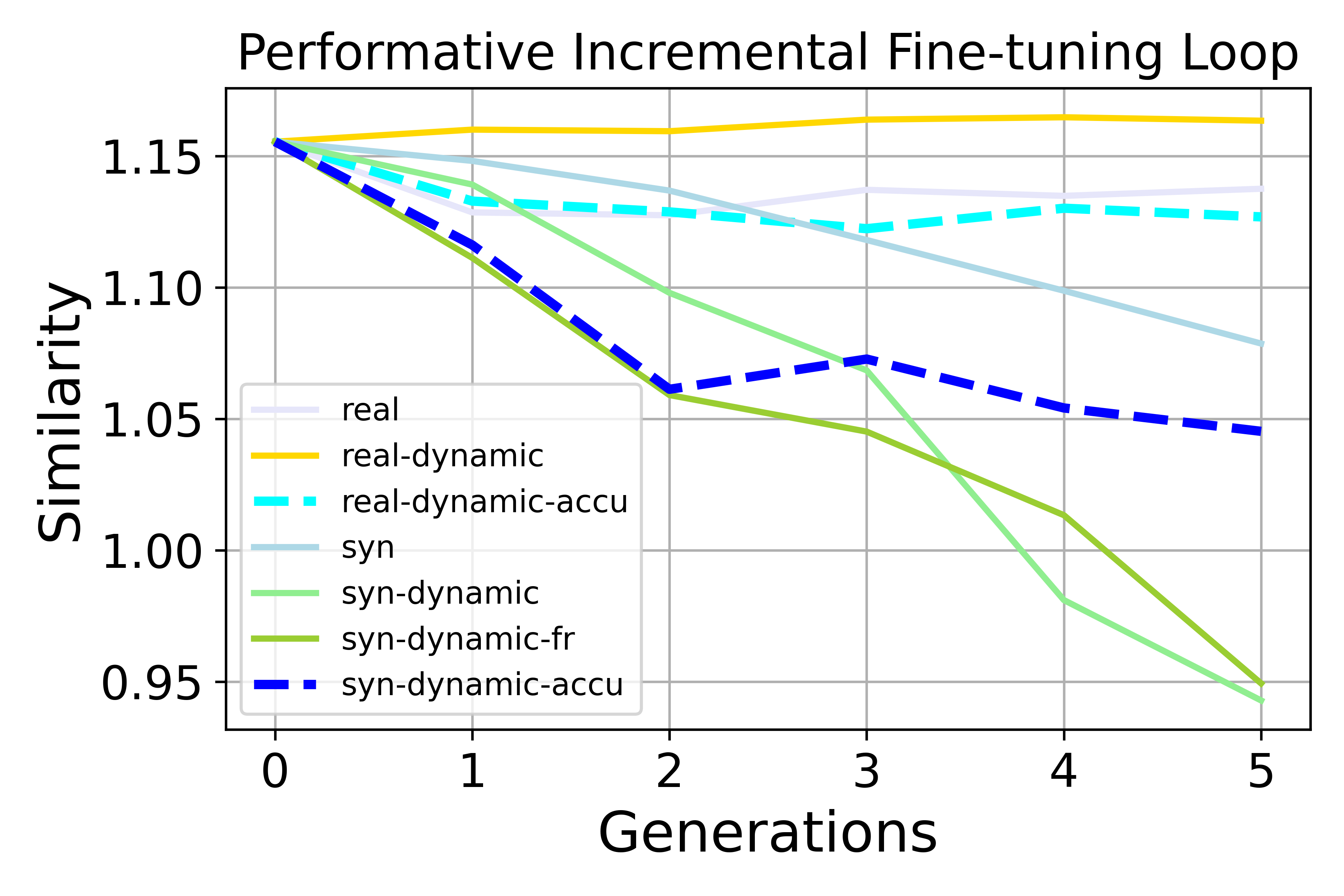
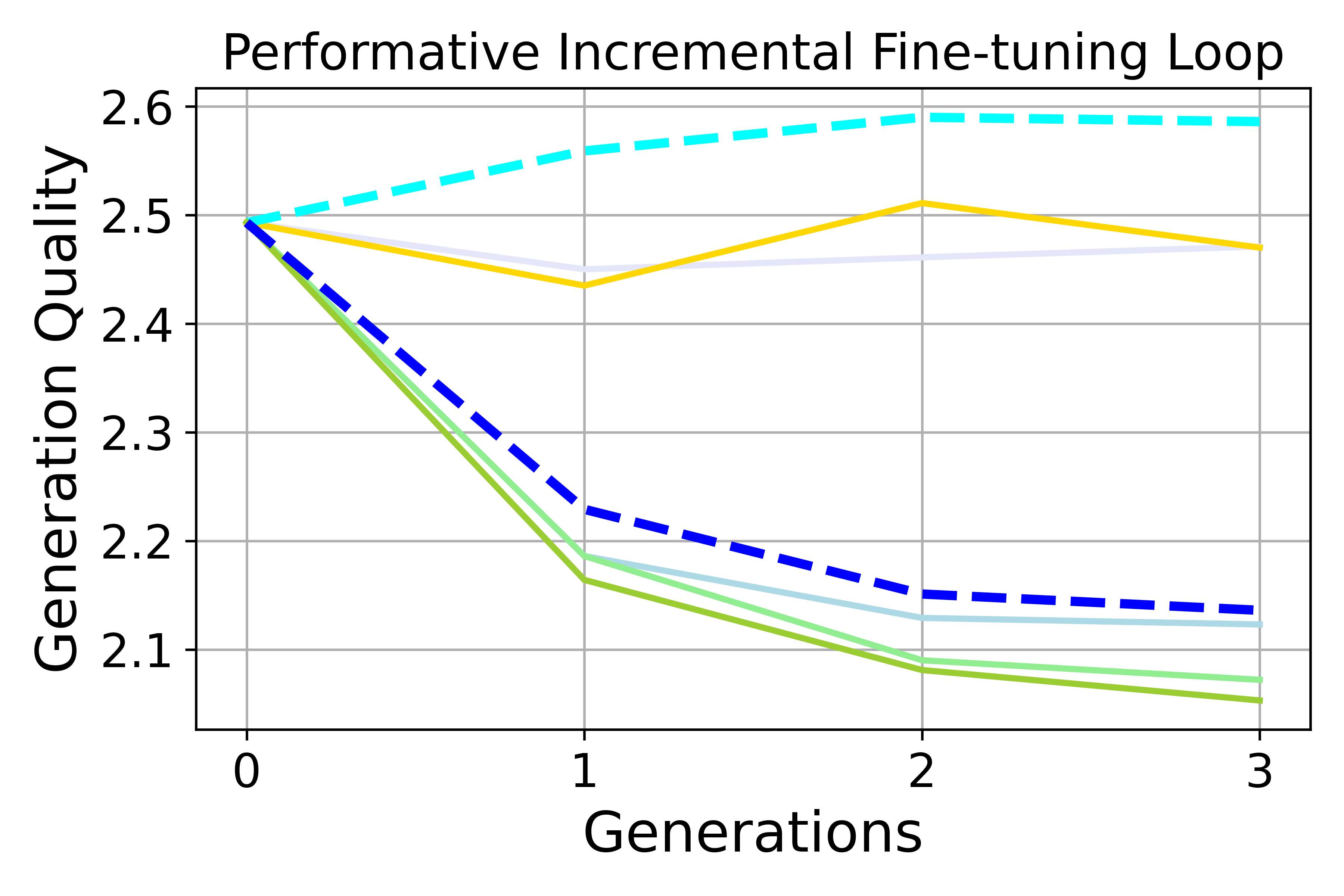
- Quality drops over time when training on synthetic data. Writing quality and math accuracy tend to decline as the model recycles its own outputs. Using real data keeps things more stable.
- Accumulation helps, but doesn’t fix it. Reusing all past data slows down bias growth and quality loss, but doesn’t bring bias back to neutral. It’s a helpful brake, not a cure.
- The proposed fix works best overall. Their reward-based rejection/reweighting strategy reduces preference bias more effectively than simpler filtering methods, while keeping reasonable quality.
Why This Matters
- For developers: If you keep training models on their own outputs—especially while user behavior shifts the data you see—your model can become more biased and less capable over time. This is a risk for chatbots, recommendation systems, and other AI tools used by real people every day.
- For fairness: Bias doesn’t always look like a widening performance gap. Sometimes the gap shrinks because the model gets worse for everyone. That can hide fairness issues if you only look at averages.
- For safety and reliability: With careful data curation—like the reward-based sampling in this paper—you can slow or reduce bias growth and maintain better quality, even when you must rely on synthetic data.
Final Thoughts and Impact
This study introduces a realistic way to think about how AI and users interact over time: the model changes people’s behavior, which changes the data, which then changes the model again. In these loops:
- Expect rising preference bias unless you intervene.
- Expect overall quality to drift downward if you train mostly on model-made text.
- Use smart data selection (reward-based sampling) and accumulation to counter these effects.
In short, if we want AI systems that improve themselves safely and fairly, we must actively shape the data they learn from—especially when that data comes from the models themselves.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for follow-up research.
- Lack of theoretical guarantees: No formal analysis of SCPL dynamics (e.g., stability, convergence, equilibria, conditions under which preference bias amplifies or disparate bias declines), nor bounds quantifying how mitigation or accumulation affects long-run outcomes.
- Unspecified/opaque performative feedback function: The mapping F(Sa, Sd) that drives group ratios is not fully defined or justified; sensitivity of results to the choice, smoothness, or noise in F, and robustness to imperfect/strategic feedback remain untested.
- Reliance on controlled, synthetic “performative” feedback: No experiments with real user interaction data, heterogeneous user behaviors, or adversarial/strategic agents; external validity to production settings is unclear.
- Short horizons and few generations: Results are reported for a small number of iterations (up to M3); long-run behavior (e.g., eventual collapse, steady states, cycles) is unknown.
- Binary-group simplification: Only two groups are modeled; no treatment of multi-group, continuous attributes, or intersectional fairness—limiting applicability to real-world demographics.
- Confounding in group/task definitions: “Advantaged” vs “disadvantaged” groups are operationalized via datasets (e.g., Dolly vs ShareGPT; easy vs hard math), which differ along many axes (style, length, content). Causal attribution of bias shifts to group membership vs dataset artifacts is not disentangled.
- Measurement validity of bias metrics:
- Political leaning classifier and gibberish detector may themselves be biased or domain-misaligned; robustness to choice of classifiers/thresholds is not evaluated.
- Preference bias proxies (e.g., news continuation leaning, non-creative preference scores) may not align with human-perceived bias; no human evaluation or cross-metric validation.
- Disparate bias reduction coincides with overall performance drop; no fairness-utility trade-off analysis to distinguish “equalization by degradation” from genuine fairness gains.
- Limited task and domain coverage: Only three English-language tasks are studied (news, preference dissection, math); generalization to other domains (safety, medical/legal), languages, conversational settings, or multi-turn interactions is untested.
- Model scale and family generalization: Results shown for a few open models (Qwen/Llama) and small-to-mid scales; sensitivity to frontier-scale models, instruction-tuned vs base models, and pretraining recipes is unknown.
- Data-cycle design space underexplored: Only “full synthetic” and “accumulation” are considered; missing analysis of mixed real/synthetic ratios, curriculum schedules, or targeted replay strategies, and when each stabilizes SCPL.
- Fine-tuning vs retraining mechanisms: Beyond high-level trends, no ablation on optimizer settings, learning rates, freezing strategies, or regularization that might modulate bias drift or forgetting in incremental fine-tuning.
- Decoding/sampling effects: SCPL depends on how synthetic data are generated (temperature, nucleus/top-k, prompt reuse vs fresh prompts). The impact of decoding policies and k (number of samples per prompt) on bias amplification is not systematically studied.
- Train–test leakage and evaluation coupling: Algorithm 2 uses held-out test performance to drive sampling; this risks contaminating evaluation and conflating deployment and test-time signals. Alternatives (e.g., validation-only feedback, bandit estimators) are not assessed.
- Small, fixed candidate pools: The composition and renewal of D_candidate can bottleneck diversity and bias; effects of candidate pool size, refresh strategies, and distributional shift in prompts are not explored.
- Mitigation method scope and robustness:
- Reward-based reweighting uses hand-crafted rules (r1, r2, r3) and fixed weights (α1, α2) without principled tuning, ablations, or guarantees; risk of “reward hacking” and induced biases is acknowledged but not quantified.
- No comparison to learned/retrained reward models, constrained optimization (e.g., fairness-aware objectives), or causal data curation.
- Interactions between mitigation and accumulation, or adaptive schedules for k and weights over generations, are not studied.
- Missing self-consuming RL settings: Self-consuming RLHF/RLAIF loops are excluded due to compute; open questions on whether RL exacerbates or mitigates SCPL bias, and how to stabilize such loops.
- Fairness taxonomy is narrow: Only preference leaning and group accuracy gaps are measured; calibration, equalized odds, subgroup and intersectional metrics, toxicity/safety harms, and representational harms are not evaluated.
- Utility beyond MMLU: Global capability is proxied by MMLU, which the authors note is weakly sensitive to performative bias; broader capability/robustness metrics (e.g., knowledge retention, reasoning robustness, hallucination rates) are missing.
- Realistic deployment constraints: Effects of data licensing, right-to-be-forgotten, privacy constraints, and partial access to historical data on SCPL bias dynamics are discussed conceptually but not empirically evaluated.
- Causal identification of feedback effects: The paper does not disentangle how much bias comes from (a) skewed sampling induced by feedback vs (b) training on biased synthetic responses themselves; causal or counterfactual analyses are absent.
- Safety and alignment side effects: Potential interactions between SCPL, bias mitigation, and other alignment properties (toxicity, misinformation, jailbreak susceptibility) are not assessed.
- Reproducibility details and variance: Sensitivity to random seeds, initialization, hyperparameters, and multiple runs is not reported; statistical significance of observed trends is unclear.
- Open design questions for practitioners:
- What target group ratios (or dynamic schedules) minimize bias growth without sacrificing utility?
- How much real data (and of what type) is needed per generation to prevent collapse and bias amplification?
- Which prompts should be retained or refreshed to preserve diversity and reduce drift?
- When should one prefer retraining vs incremental fine-tuning under data access constraints?
These gaps suggest concrete next steps: formalizing SCPL dynamics; validating with real user feedback; broadening tasks, models, and fairness metrics; rigorously auditing measurement tools; expanding data-cycle and decoding ablations; and developing principled, provably robust mitigation strategies (including self-consuming RL settings).
Practical Applications
Below is a concise synthesis of practical, real-world applications enabled by the paper’s concepts, findings, and methods. Each item notes sectors, likely tools/workflows, and key assumptions/dependencies.
Immediate Applications
- Bias-aware synthetic data curation pipeline using reward-based rejection sampling and reweighting
- Sectors: software/LLM providers, media, education (edtech), finance customer support, healthcare documentation
- Tools/workflows: multi-sample generation (k>1), rule-based reward functions combining generation quality (e.g., gibberish detector) and content similarity, VRS/TPP/TOP selection strategies, group-aware reweighting toward disadvantaged prompts, accumulation of prior data across iterations
- Assumptions/dependencies: reliable proxy rewards and classifiers; access to group labels or ethically collected attributes; extra compute for multi-sample generation; careful thresholding to avoid introducing new biases
- Offline SCPL simulation for deployment safety testing and bias forecasting
- Sectors: MLOps/product teams, academia
- Tools/workflows: implement SCPL and performative sampling (Algorithms for loop and sampling), unbiased held-out test sets, preference bias and disparate bias metrics, A/B scenarios comparing retraining vs incremental fine-tuning
- Assumptions/dependencies: representative test sets; valid demographic/task group definitions; function F(Sa, Sd) calibrated to realistic feedback dynamics
- Fairness monitoring dashboards for feedback-driven systems
- Sectors: MLOps across all sectors
- Tools/workflows: track “preference bias,” “disparate bias,” generation quality (GQ), Pass@1 disparity, group ratio dynamics; integrate into MLFlow/Weights & Biases; alerting on trend changes
- Assumptions/dependencies: ongoing measurement, privacy-compliant group segmentation; resilient classifiers; governance to act on alerts
- Training policy selection and scheduling (retraining vs incremental fine-tuning) with accumulation
- Sectors: LLM training teams
- Tools/workflows: bias thresholds to choose training regime; dataset accumulation across generations; mixing in fresh real prompts; guardrails for synthetic fraction
- Assumptions/dependencies: access to prior data and licenses; reliable estimates of synthetic proportions; compute budget
- Difficulty-aware curriculum maintenance for math and reasoning assistants
- Sectors: education/tutoring, assessment platforms, interview prep
- Tools/workflows: maintain target ratios of hard/easy items; inject hard examples; monitor Pass@1 disparity and similarity metrics; accumulate historically diverse problems
- Assumptions/dependencies: difficulty labels; sufficient supply of hard problems; monitoring infrastructure
- Political drift mitigation in content generation and moderation
- Sectors: media/newsrooms, social platforms, content studios
- Tools/workflows: political leaning classifiers; reward rules emphasizing topic consistency and neutral balance; reweighting toward underrepresented viewpoints; periodic real-data infusion
- Assumptions/dependencies: classifier accuracy and calibration; editorial policies; risk of overcorrection without human oversight
- Synthetic data governance and provenance controls
- Sectors: all data-driven organizations
- Tools/workflows: data catalogs and lineage; caps on synthetic proportions per generation; periodic human data refresh; source tagging (e.g., content credentials)
- Assumptions/dependencies: synthetic detection/watermarking; policy enforcement; audit trails
- License-aware training continuity plans
- Sectors: legal/compliance for AI, data procurement
- Tools/workflows: track license expiry; prefer incremental fine-tuning plus accumulation of permitted data; prioritize fresh user prompts; risk/graceful degradation plans
- Assumptions/dependencies: accurate license metadata; compliant prompt intake
- Bias-aware user prompt intake and sampling to counter performative disenfranchisement
- Sectors: e-commerce recommendation, customer support chatbots
- Tools/workflows: quotas/oversampling for disadvantaged groups; controlled prompt selection; regular rebalancing based on performance scores (Sa, Sd)
- Assumptions/dependencies: ethical group identification; user consent; avoiding harmful manipulation of engagement
- Replicable evaluation suites for SCPL across tasks
- Sectors: academia, benchmarking consortia
- Tools/workflows: news continuation (political bias), preference dissection (creative vs non-creative), math Pass@1 disparity; open datasets; standardized metrics
- Assumptions/dependencies: community buy-in; transparent methodology; updates to maintain relevance
Long-Term Applications
- Performative training orchestrators for safe self-consuming loops
- Sectors: MLOps platforms, enterprise AI
- Tools/workflows: end-to-end systems encoding feedback-driven data dynamics, scheduling safe retraining, automated bias mitigation via reward-guided selection, dynamic F(Sa, Sd) calibration
- Assumptions/dependencies: robust simulation fidelity; integration with production data pipelines; organizational adoption
- Learned fairness-aware reward models (beyond handcrafted rules)
- Sectors: LLM developers, healthcare triage, education platforms
- Tools/workflows: train multi-objective reward models balancing quality, safety, and fairness; plug-and-play reward modules; DPO/RLHF variants with formal bias guarantees
- Assumptions/dependencies: high-quality labeled data across groups; scalable training; rigorous auditing
- Standards and regulation for synthetic training loops and performative systems
- Sectors: policy/regulators, industry consortia
- Tools/workflows: disclosures of synthetic proportions; mandated bias tracking; minimum real-data infusion; audit protocols for feedback loops
- Assumptions/dependencies: consensus on metrics and thresholds; enforceability; sector-specific adaptations
- Cross-platform synthetic provenance and watermarking infrastructure
- Sectors: media, software, education
- Tools/workflows: robust watermarks/content credentials; provenance registries; bias/collapse tracing across ecosystems
- Assumptions/dependencies: watermark resilience; interoperability; broad adoption incentives
- Adaptive data marketplaces that balance group representation via performative signals
- Sectors: data brokers, platforms
- Tools/workflows: dynamic quotas/pricing to ensure disadvantaged group presence; supply-side incentives tied to fairness outcomes
- Assumptions/dependencies: lawful group identification; market depth; governance to prevent gaming
- Multi-group and multi-agent SCPL extensions for complex platforms
- Sectors: social networks, large-scale recommender systems
- Tools/workflows: multi-agent performative prediction; chaos/stability analyses; simulation-based deployment policies
- Assumptions/dependencies: scalable models of interaction; robust convergence criteria; platform telemetry
- Early-warning systems for collapse and bias amplification
- Sectors: all AI-driven organizations
- Tools/workflows: anomaly detection on generation quality and bias trajectories; trigger policies (e.g., pause training, inject human data, switch regime)
- Assumptions/dependencies: reliable baselines; explainable alarms; clear operational playbooks
- Efficient self-consuming reinforcement learning with fairness guarantees
- Sectors: advanced model training teams
- Tools/workflows: RL loops that incorporate rejection sampling/DPO hybrids; theoretical bounds on bias and performance under recursion
- Assumptions/dependencies: compute resources; new theory/algorithms; evaluation at scale
- Edtech personalization that resists performative drift
- Sectors: education platforms
- Tools/workflows: dynamic curriculum balancing per learner; fairness-aware progress metrics; guaranteed exposure to challenging content
- Assumptions/dependencies: student modeling quality; careful handling of demographic attributes; pedagogical validation
- Healthcare and clinical decision support fairness under feedback
- Sectors: healthcare delivery, digital triage
- Tools/workflows: bias-aware intake and training; reward models aligned with clinical quality and equity; continuous governance boards
- Assumptions/dependencies: protected health information governance; validated clinical metrics; multidisciplinary oversight
- Finance credit/advice systems robust to disengagement bias
- Sectors: finance, fintech
- Tools/workflows: performative sampling that protects disadvantaged groups from dropout effects; fairness audits with SCPL metrics; adaptive training policies
- Assumptions/dependencies: regulatory compliance; trustworthy group attribution; customer consent and transparency
Glossary
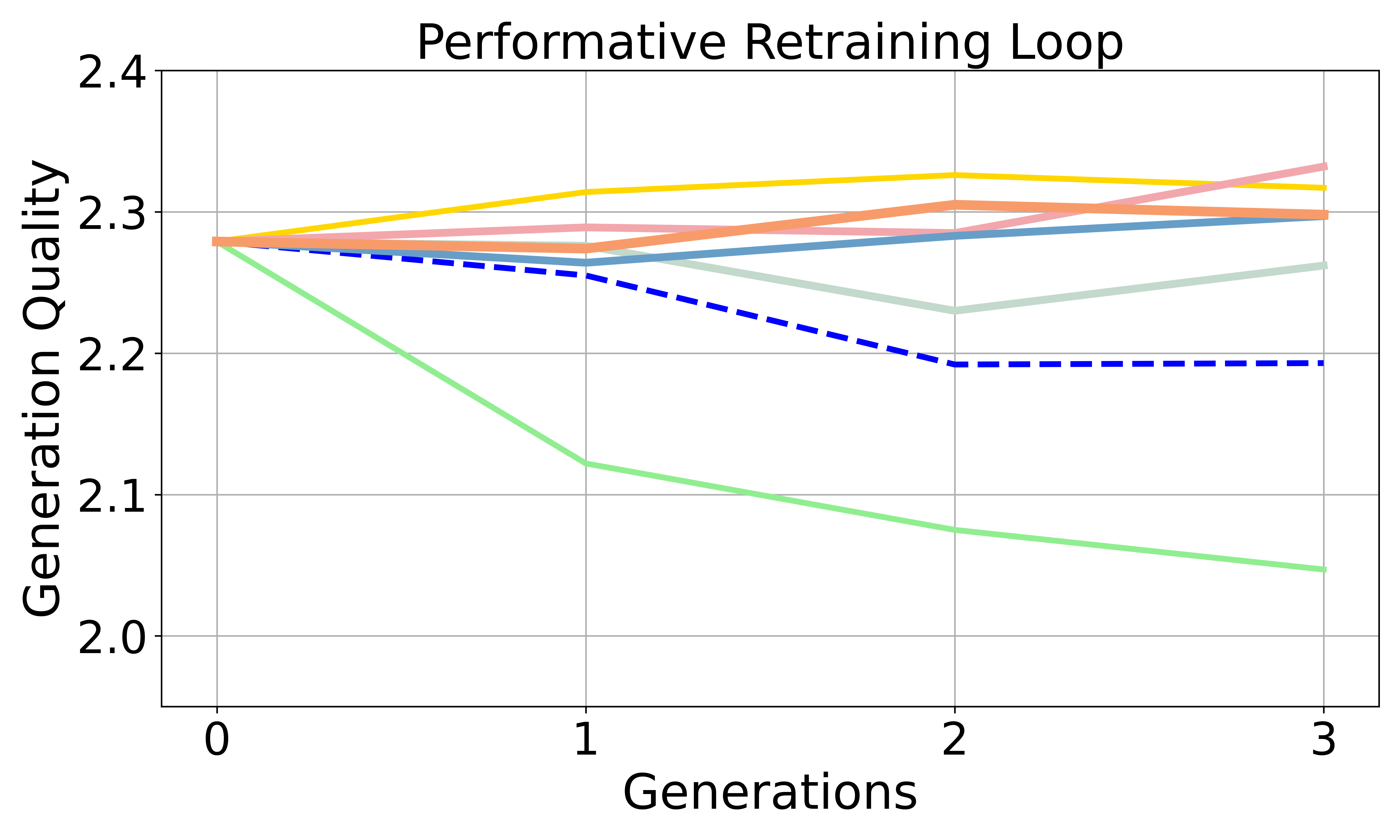
- Accumulation: A data cycle that reuses and aggregates past datasets across generations to stabilize training and bias. "Accumulation helps mitigate the amplification of preference bias and the degradation of generation quality."
- Advantaged group: The group that benefits from better model performance or higher representation in the data loop. "We consider a two-group situation consisting of an advantaged group and a disadvantaged group "
- Bertscore: A text generation evaluation metric that measures semantic similarity to references using contextual embeddings. "it utilizes the sum of ROUGE-L~\cite{lin2004rouge} and Bertscore~\cite{zhang2019bertscore} to represent the problem solving ability."
- Data cycle: The design specifying how real and synthetic data are generated, mixed, and reused across generations. "depending on the data cycle design (Section~\ref{sec:pre:data-cycle})"
- Direct Preference Optimization (DPO): An alignment method that directly optimizes model parameters from preference data without explicit reinforcement learning. "In addition to SFT, we also conduct preliminary experiments using Direct Preference Optimization~\cite{rafailov2023direct}."
- Disparate bias: A fairness notion capturing performance disparities across groups. "disparate bias tends to decrease"
- Disparate performance: The measured difference in accuracy or outcomes between groups. "The third assesses disparate performance"
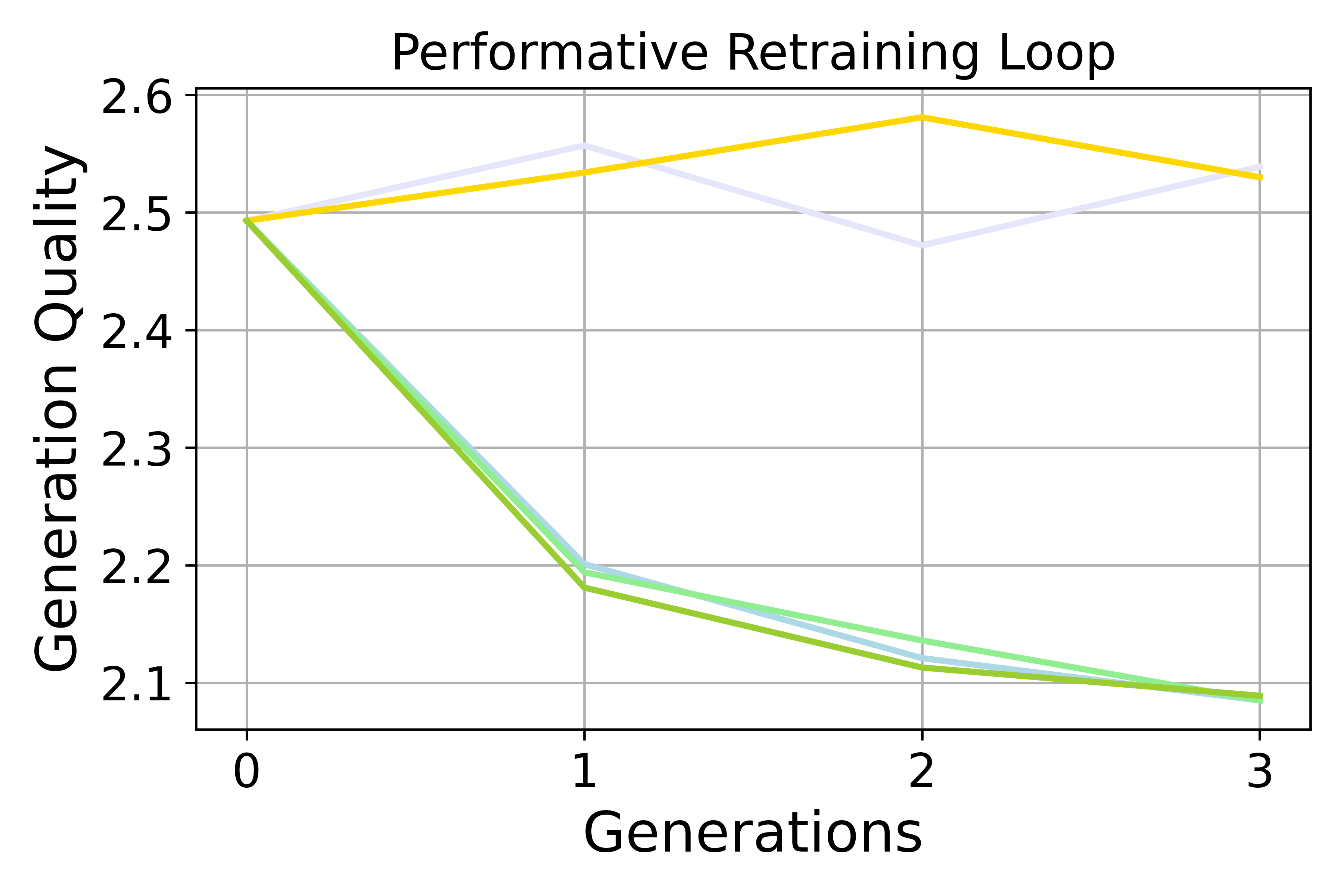
- Gibberish Detector: A classifier used to score fluency and coherence of generated text. "GQ is the average score for all generated articles using the Gibberish Detector"
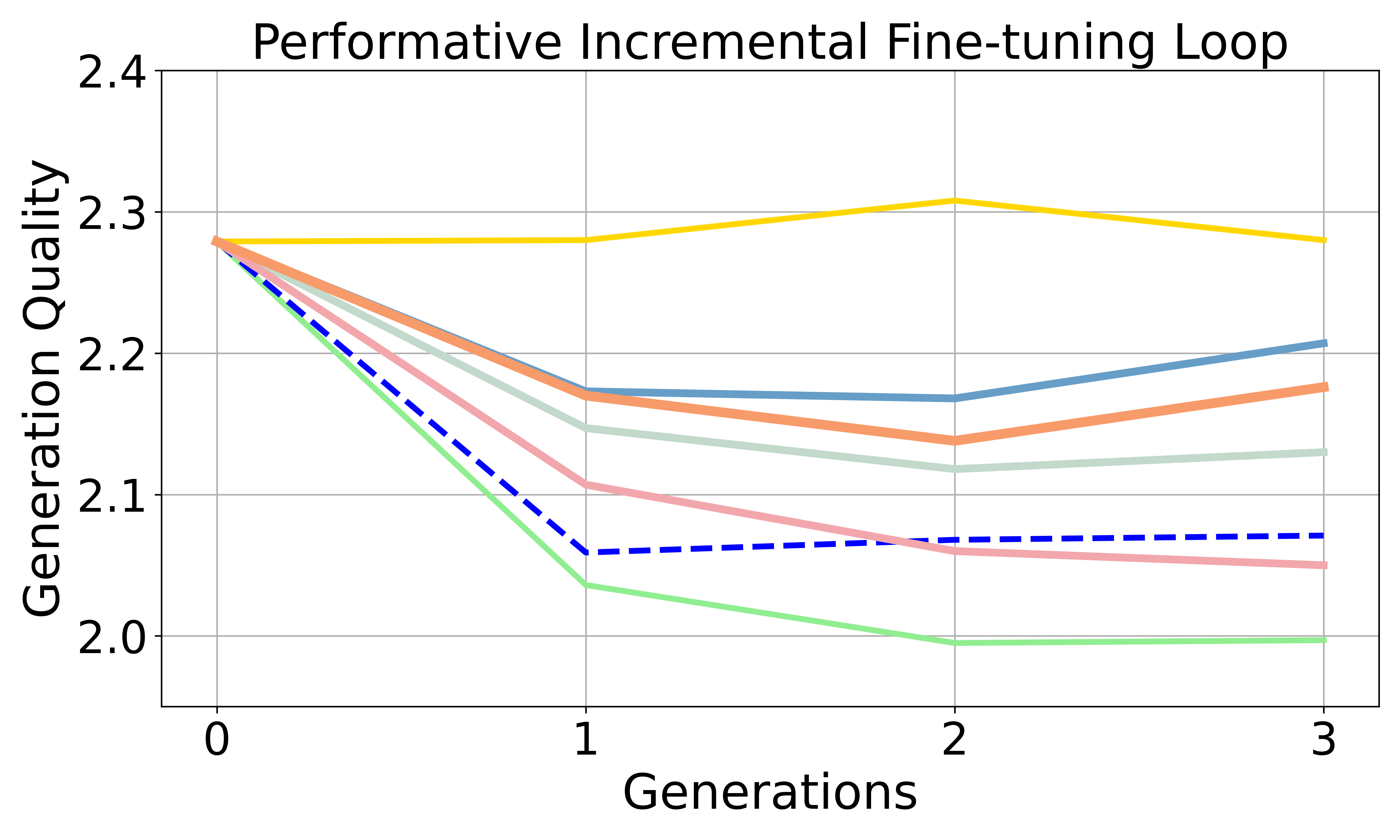
- Incremental fine-tuning: Continuing to fine-tune the current model on new data rather than retraining from the base model. "However, this incremental fine-tuning setting in self consuming loop remains underexplored in current research."
- Linear dynamic setting: A controlled performative setup where group proportions change linearly across iterations. "we primarily study a controlled linear dynamic setting"
- MMLU: A broad knowledge benchmark (Massive Multitask Language Understanding) evaluating model accuracy across many tasks. "We additionally report accuracy results on the standard MMLU benchmark"
- Model collapse: Degradation of quality and diversity when models are repeatedly trained on their own synthetic outputs. "The recursive training loop on synthetic data may lead to model collapse"
- Non-dynamic (self-consuming) loop: A self-training setup with fixed group ratios and repeated prompts across generations. "is referred to as Non-dynamic, which is the typical self-consuming training loop"
- Online continual learning: Iterative training that incorporates ongoing feedback to update and align models over time. "Unlike static supervised fine-tuning (SFT) with a fixed dataset, online continual learning~\cite{wang2024dealing} collects feedback from humans or AI agents to iteratively train models that are more capable and better aligned."
- Pass@1 Accuracy: The probability that the first generated answer is correct. "Pass@1 Accuracy is the accuracy of solving problems correctly."
- Performative dynamics: Feedback-driven distribution shifts caused by model deployment that alter future data. "Performative dynamics accelerate preference bias amplification compared to non-dynamic self-consuming loops in both fine-tuning and retraining settings, though the effect depends on the task and training regime."
- Performative feedback: User or environment responses to model behavior that influence subsequent data generation and training. "under controlled performative feedback."
- Performative fine-tuning loss: The training loss computed on data generated by the previous model under performative feedback. "leading to a performative fine-tuning loss defined as:"
- Performative prediction: A learning paradigm where predictions influence the data distribution the model later encounters. "which is known as performative prediction"
- Preference bias: Systematic tilting of outputs toward one group’s preferences over another’s. "Preference bias increases more rapidly in the SCPL than in the Non-dynamic loop"
- Preference Dissection: A benchmark/dataset for analyzing how models express non-creative vs. creative attribute preferences. "We adopt the Preference Dissection dataset~\cite{li2024dissecting} as test dataset."
- Preference optimization: Steering models toward desired behaviors by optimizing with respect to explicit or implicit preferences. "data curation implicitly acts as preference optimization in self-training loops"
- Rejection sampling: Filtering generated samples by accepting only those meeting predefined criteria or reward thresholds. "We also explore several naive rejection sampling~\citep{yuan2023scaling} strategies as baselines."
- Reward-based reweighting: A sampling/selection approach that weights or filters synthetic data using reward signals to mitigate bias while preserving quality. "We propose a modular and extensible reward-based reweighting method to reduce bias while maintaining generation quality."
- ROUGE-L: A summarization metric based on longest common subsequence overlap between generation and reference. "the sum of ROUGE-L~\cite{lin2004rouge} and Bertscore"
- SCPL (Self-Consuming Performative Loop): A dynamic loop where models train on their own outputs under feedback that changes future data distributions. "we introduce the concept of Self-Consuming Performative Loop (SCPL)"
- Self-consuming training loop: Recursive retraining where a model repeatedly learns from synthetic data generated by prior model generations. "a self-consuming training loop emerges"
- Supervised fine-tuning (SFT): Standard fine-tuning on labeled prompt–response pairs using gradient-based optimization. "Unlike static supervised fine-tuning (SFT) with a fixed dataset"
Collections
Sign up for free to add this paper to one or more collections.