Large Language Models Are Bad Dice Players: LLMs Struggle to Generate Random Numbers from Statistical Distributions
Abstract: As LLMs transition from chat interfaces to integral components of stochastic pipelines across domains like educational assessment and synthetic data construction, the ability to faithfully sample from specified probability distributions has become a functional requirement rather than a theoretical curiosity. We present the first large-scale, statistically powered audit of native probabilistic sampling in frontier LLMs, benchmarking 11 models across 15 distributions. To disentangle failure modes, we employ a dual-protocol design: Batch Generation, where a model produces N=1000 samples within one response, and Independent Requests, comprising $N=1000$ stateless calls. We observe a sharp protocol asymmetry: batch generation achieves only modest statistical validity, with a 13% median pass rate, while independent requests collapse almost entirely, with 10 of 11 models passing none of the distributions. Beyond this asymmetry, we reveal that sampling fidelity degrades monotonically with distributional complexity and aggravates as the requested sampling horizon N increases. Finally, we demonstrate the propagation of these failures into downstream tasks: models fail to enforce uniform answer-position constraints in MCQ generation and systematically violate demographic targets in attribute-constrained text-to-image prompt synthesis. These findings indicate that current LLMs lack a functional internal sampler, necessitating the use of external tools for applications requiring statistical guarantees.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple question: Can today’s AI chatbots (LLMs, or LLMs) actually “roll the dice” properly when we ask them to make random choices? The authors show that, for many kinds of randomness, the answer is no. When LLMs are used in places where true randomness matters—like making fair multiple‑choice tests or building balanced image datasets—they often produce biased results unless they rely on outside tools.
What questions did the researchers ask?
They set out to find:
- Can LLMs generate numbers that follow specific probability distributions (think: fair coin flips, normal/Gaussian “bell curve” numbers, or other common random patterns)?
- Does their performance change depending on how we ask them (all at once vs. one at a time)?
- Do things get worse for harder distributions or when we ask for more samples?
- Do these problems cause real‑world issues, like biased answer positions in quizzes or unbalanced descriptions in image prompts?
How did they test the models?
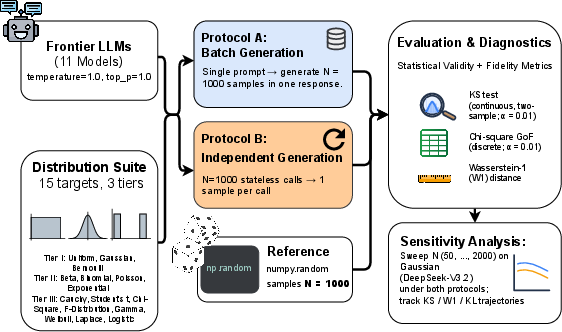
They tested 11 well‑known LLMs on 15 different probability distributions (from simple ones like Uniform and Bernoulli/coin flips to trickier ones like Cauchy, Gamma, and Student’s t). For each setup, they asked for 1,000 random samples and checked if the results looked like they should.
The two ways of asking
- Batch Generation: Ask the model once to produce a list of 1,000 numbers in a single answer. The model “sees” its own previous numbers as it continues the list.
- Independent Requests: Ask the model 1,000 separate times for one number each. Each request is isolated, like the model has no memory of the previous answers.
Why this matters: If a model really understands how to be random, it should do fine even when asked one number at a time. If it only does okay when writing a long list, it might be “self‑correcting” by looking at what it already wrote, not because it truly knows how to sample fairly.
What they measured
They used standard checks that compare what the model produced to what a correct random generator would produce:
- Goodness‑of‑fit tests (like chi‑square for categories and KS for continuous numbers) to see if the model’s outputs match the target pattern.
- A distance score (Wasserstein‑1) that you can imagine like “how much sand you need to move to reshape one pile into another.” Smaller distance means the model’s “shape” is closer to the true distribution.
What they tested on
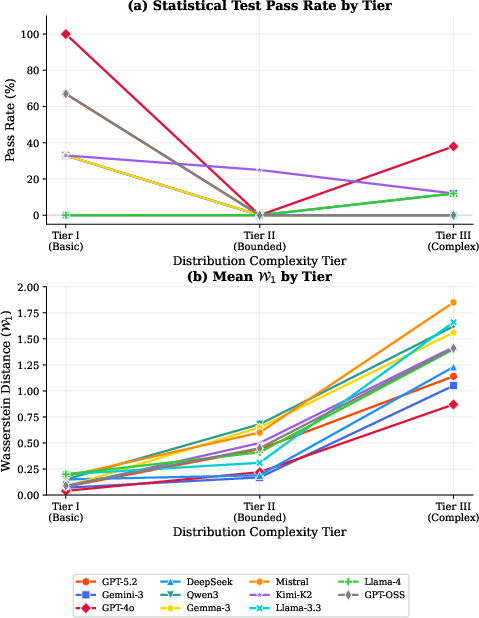
Distributions were grouped by difficulty:
- Easier: Uniform (numbers spread evenly), Gaussian/Normal (bell curve), Bernoulli (coin flips with a set chance).
- Medium: Beta, Poisson, Exponential, Binomial, etc.
- Harder: Cauchy (very heavy tails), Student’s t, Gamma, Weibull, and others with tricky shapes or long tails.
They also tried different sample sizes to see what happens as you ask for more numbers (from 50 up to 2,000).
Downstream (real‑world‑style) tests
- Multiple‑Choice Question (MCQ) generation: They told models to create questions where the correct answer’s position (A, B, C, or D) should be evenly spread (25% each). Then they checked how often each position was used.
- Text‑to‑image prompt generation: They asked models to write prompts following specific target distributions for attributes like gender, race/ethnicity, height (bell curve), and coat color (uniform over several colors). Then they checked if the outputs matched the requested percentages.
What did they find?
- Independent requests mostly failed: When asked for one sample at a time (the strictest test of real randomness), 10 out of 11 models failed every distribution they tested. In simple terms, the models showed strong built‑in biases rather than true randomness.
- Batch lists did only “so‑so”: When writing a long list in one go, models did a bit better (median pass rate 13%), likely because they can “see” what they’ve already produced and try to balance it out. But this isn’t the same as truly sampling correctly.
- Harder distributions = worse results: As distributions got more complex (heavier tails, tighter constraints), accuracy dropped steadily. Models might mimic familiar shapes but struggle with precise mathematical details.
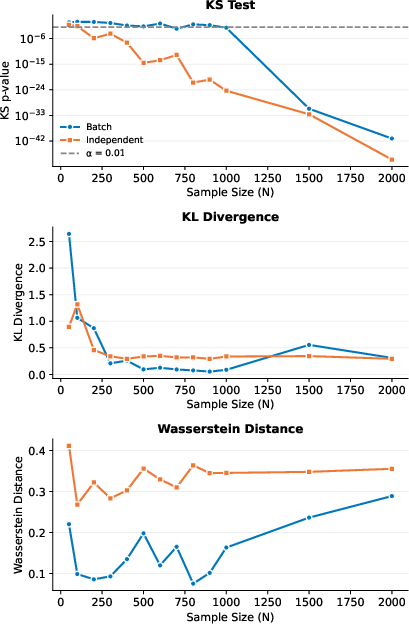
- More samples made problems clearer: Instead of improving with bigger sample sizes (which is what true random generators do), LLM outputs often got worse or revealed stronger mismatches as the sample count grew. Asking for more numbers exposed the bias more clearly.
- Real‑world tasks broke the rules:
- MCQs: Even with explicit instructions to spread correct answers evenly, all tested models produced skewed patterns (for example, heavily favoring a specific option like B or C). That’s unfair for test‑takers.
- Image prompts: Models ignored the requested distributions. Examples included over‑ or under‑representing specific demographic groups, producing heights with far too little variation, and favoring certain colors instead of keeping them balanced.
Why does this matter?
- Fairness and integrity: If an LLM can’t follow simple randomness rules, it can build hidden biases into tests, simulations, or datasets. That can cause unfair outcomes or misleading results.
- Practical takeaway: For any application where correct randomness matters (education tools, scientific simulations, synthetic data, fair sampling), don’t rely on the LLM’s “native” randomness. Use external tools (like proper random number libraries in code) to get guaranteed statistical behavior.
- Big picture: Today’s LLMs are great at producing fluent text, but this study shows they do not have a “functional internal sampler”—they can talk about randomness, but they don’t reliably generate it. Improving this may require new training methods or architectures so models can truly handle probabilities, not just describe them.
Knowledge Gaps
Knowledge gaps, limitations, and open questions left unresolved
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for future research.
- Exact prompt wording and formatting are omitted for both protocols; without full prompt text, system and user messages, and output formatting expectations, reproducibility and sensitivity to phrasing cannot be assessed.
- Pre-/post-processing details for numeric extraction are unspecified (e.g., parsing rules, allowed number formats, rounding, out-of-range rejection, handling of non-numeric tokens), leaving potential measurement bias and data cleaning effects unquantified.
- Independence of “stateless” calls is assumed but not verified; there is no audit for server-side caching, rate limiting, cross-request context leakage, or time-varying nonstationarity that could affect per-call outputs.
- Autocorrelation and inter-sample dependence in batch mode are not measured; runs tests, lag-1 autocorrelation, or sequence diagnostics (e.g., Ljung–Box) could quantify the “correction vs. drift” narrative more rigorously.
- The proposed Context–Fidelity Dilemma is not validated across models/distributions with formal time-series analyses; no quantitative evidence is provided for where the “critical horizon” occurs or whether it generalizes beyond the single Gaussian case studied in the sensitivity sweep.
- Decoding hyperparameters are fixed (temperature=1.0, top_p=1.0), but key sweeps are missing (top_k, typical sampling, presence/frequency penalties, repetition penalties, min/max tokens, sampling seeds), leaving the role of decoding policy in sampling fidelity unresolved.
- Model-scale and architecture effects are not disentangled; there is no analysis of how parameter count, training data, tokenizer, or architecture family correlate with sampling fidelity.
- Parameter sensitivity of distributions is barely explored; each distribution is tested at a single parameter setting, with no systematic study of how fidelity varies across shape/scale parameters, skewness, boundedness, or tail-heaviness.
- Crucial distribution classes are not evaluated: mixtures (e.g., Gaussian mixtures), multimodal densities, truncated/conditional distributions, categorical with large support, Dirichlet/Multinomial, and multivariate/joint distributions with correlations or constraints.
- No evaluation of conditional or compositional sampling (e.g., sampling from , joint attribute constraints) beyond the text-to-image prompt task, leaving general conditional sampling capabilities and joint consistency unexplored.
- The paper does not test algorithmic prompting strategies (e.g., instructing inverse-CDF sampling, Box–Muller for Gaussians, rejection sampling) without external code, so it remains unknown whether structured reasoning or chain-of-thought can materially improve native sampling.
- In-context example strategies, self-checking loops, or iterative correction (generate–evaluate–revise) are not examined; the potential of reflexive prompting to enforce target distributions is left open.
- The KL divergence for continuous distributions is computed via fixed histograms with unspecified bin edges and supports; choices of support truncation, bin count, and binning strategy (adaptive vs. fixed) may materially affect conclusions but are not analyzed.
- KS tests for continuous distributions compare against a finite reference sample () rather than the exact theoretical CDF; the added sampling noise and its impact on Type I/II errors are not characterized.
- Multiple hypothesis testing corrections are not applied despite testing 15 distributions across 11 models; how conclusions change under Bonferroni/Holm or FDR control is unknown.
- Wasserstein-1 computation details are unclear (numerical integration method, grid resolution, support truncation); the robustness of estimates—especially for heavy-tailed distributions—is not assessed.
- Digit-level and formatting biases (e.g., preferred digits, decimal precision, token-level number morphology) are not analyzed; tokenization and numeric representation effects may explain “favorite numbers” but remain unexamined here.
- The paper does not report error handling rates (e.g., how often models output non-numeric text, malformed numbers, or out-of-support values), nor the impact of filtering on statistics.
- The single-model, single-distribution sensitivity analysis (DeepSeek-V3.2 on Gaussian) does not generalize across distributions or models; broad -scaling trajectories are still an open question.
- The downstream MCQ experiment lacks methodological transparency on question parsing, detection of the correct option, de-duplication, and guarding against model reuse of templates that could confound positional analysis.
- The attribute-constrained prompt study does not describe the attribute extraction pipeline (automatic classifier rules, regex, human labeling, inter-rater reliability), leaving measurement validity and label noise unquantified.
- For the prompt-generation bias study, only prompts are audited; whether downstream image generators honor the intended distributions (and how LLM biases propagate through the vision model) is not evaluated.
- No ablation assesses whether structured output formats (e.g., enumerated options, JSON schemas with constrained fields) mitigate distributional violations compared to free-form text.
- The findings rely heavily on proprietary models and version identifiers that may change over time; without open-weight baselines and full documentation, long-term reproducibility and cross-lab verification remain limited.
- The causal mechanisms of failure are speculative; there is no diagnostic linking observed distributional errors to training data priors, tokenizer biases, or decoding dynamics via logit-level or token-level analyses.
- Potential mitigations are not systematically tested: lightweight fine-tuning, instruction tuning on sampling tasks, RL with distributional objectives, or tool-use hybrids (e.g., internal PRNG modules) are proposed implicitly but remain unexplored.
- Cross-lingual and cross-modality generalization is untested; whether sampling fidelity differs with prompt language, code prompts, or multi-modal contexts is unknown.
- Security and platform factors (rate limits, content filters, safety policies) that may distort numeric outputs in independent requests are not audited, leaving a potential operational confound.
Practical Applications
Immediate Applications
The following applications can be deployed now to reduce or eliminate the risks revealed by the paper’s findings. Each item includes relevant sectors and key dependencies.
- Replace native LLM “randomness” with external samplers
- Sectors: software, education, healthcare, finance, robotics, energy
- What to do: Route all random draws (Uniform, Bernoulli, Beta, etc.) to a trusted RNG (e.g., numpy.random, JAX, randomgen) via function-calling/tools; return structured JSON back to the LLM for downstream generation.
- Tools/products/workflows: “Sampler microservice” (HTTP/GRPC), LangChain/Semantic Kernel tool for distributions, seed management and audit logs.
- Assumptions/dependencies: Tool-use or code-execution capability; deterministic logging and seeding in production; security review for code execution.
- Add a statistical validation guardrail to LLM pipelines
- Sectors: software, education, synthetic data, research platforms
- What to do: Insert KS, χ², and Wasserstein-1 checks on batches of generated outputs against target distributions; auto-reject and resample on failure; alert and fallback to external samplers.
- Tools/products/workflows: “Randomness QA” module; CI/CD checks that run the paper’s benchmark distributions as acceptance tests; dashboards tracking pass rates over time.
- Assumptions/dependencies: Access to sufficient sample sizes to achieve statistical power; reference samplers and fixed α thresholds; storage for audit trails.
- Fair MCQ generation with deterministic post-processing
- Sectors: education (assessment platforms, content authoring)
- What to do: Let the LLM generate question content only; select the correct option position with external code; deterministically shuffle choice order; enforce/monitor uniformity (25% per A/B/C/D).
- Tools/products/workflows: “MCQ fairness shim” that shuffles answers and logs option frequencies; nightly χ² audits; item-bank builders that treat randomization as a non-LLM step.
- Assumptions/dependencies: Reliable parsing of the correct answer; integration with templating and export formats (QTI, LMS APIs).
- Attribute-quota controllers for prompt/dataset generation
- Sectors: synthetic data, computer vision, fairness/ML ops
- What to do: Sample demographics and other attributes with an external RNG; inject into prompt templates; run post-hoc taggers/validators; resample until quotas match targets.
- Tools/products/workflows: “Distribution controller” that enforces quotas; integration with T2I/TTS pipelines; automatic label verification and rebalancing.
- Assumptions/dependencies: High-precision attribute taggers; robust prompt templating; clear governance of demographic targets.
- Correctly randomized assignment in experiments and allocation
- Sectors: healthcare (clinical trial arms), tech (A/B tests), operations, HR/lotteries/games
- What to do: Use cryptographically secure RNGs for assignment; never ask an LLM to “pick at random”; store seeds and assignments for auditability.
- Tools/products/workflows: “Assignment service” with CSRNG (e.g., OS entropy, HSM-backed), immutable logs.
- Assumptions/dependencies: Compliance constraints (e.g., GxP, HIPAA), audit readiness.
- Monte Carlo and simulation orchestration without LLM sampling
- Sectors: finance (VaR, option pricing), energy (grid sim), robotics (domain randomization), supply chain
- What to do: LLMs can orchestrate, explain, and parameterize simulations, but sampling must occur in trusted numerical libraries; record seeds and provenance.
- Tools/products/workflows: “Simulation orchestrator” prompts → code → external sampler → results back to LLM for narration/analysis.
- Assumptions/dependencies: Sandbox for safe code execution; reproducibility; computational resources.
- Agent framework enhancements for safe randomness
- Sectors: software (agent ecosystems)
- What to do: Ship a built-in Random tool (distributions API), reject any attempt to “roll dice” natively; chunk long generations and validate between chunks; auto-fallback on failures.
- Tools/products/workflows: LangChain/LlamaIndex plug-ins; policy routes that require tool-use for any sampling instruction.
- Assumptions/dependencies: Tool-use policies enforced at the orchestrator; output schema contracts.
- Procurement and model evaluation policies
- Sectors: enterprise IT, public sector
- What to do: Add a “Randomness Capability Profile” to model evals using the paper’s dual-protocol tests; require mitigations (tool-use) if pass rates are low; document that decoding temperature ≠ statistically valid sampling.
- Tools/products/workflows: Vendor scorecards; pre-deployment gates; red-team checklists for randomness.
- Assumptions/dependencies: Access to candidate models with consistent decoding configs; legal and risk approval processes.
- Documentation and product disclaimers
- Sectors: edtech, fintech, govtech, general SaaS
- What to do: Explicitly state that model outputs must not be treated as unbiased random samples; surface warnings where users request “random picks.”
- Tools/products/workflows: UX nudges, API error states requiring tool-use, “fairness mode” toggles that activate external samplers.
- Assumptions/dependencies: Willingness to trade friction for correctness; content and legal review.
- Daily life utilities
- Sectors: consumer apps
- What to do: For coin flips, dice rolls, random name pickers, use device/OS RNG not LLM text; show provenance (“seeded by …”).
- Tools/products/workflows: Lightweight RNG SDKs, verifiable randomness beacons for public draws.
- Assumptions/dependencies: UI updates; user trust in provenance displays.
Long-Term Applications
These opportunities require further research, scaling, or productization to deliver robust, certifiable behavior.
- Built-in, verifiable randomness modules in LLM stacks
- Sectors: foundational model providers, enterprise platforms
- Vision: First-class “sample(distribution, params)” API that calls a certified RNG under the hood and returns structured outputs with signed provenance; composable with function-calling.
- Dependencies: Secure RNG infrastructure, API standards, attestation for compliance.
- Distribution-constrained decoding and training
- Sectors: model R&D, applied ML
- Vision: Decoders that adjust token logits to satisfy target marginals/quotas over sequences; sequence-level objectives minimizing Wasserstein/KS/χ²; RL or control-theoretic methods to manage correction vs drift.
- Dependencies: New inference-time algorithms; training data with explicit distributional supervision; evaluation harnesses.
- Probabilistic programming integration
- Sectors: software, research, education
- Vision: LLMs compile natural-language specs to Pyro/NumPyro/Stan/Turing programs, execute samplers, and verify fits; round-trip “spec → code → sample → test.”
- Dependencies: Reliable code generation/execution sandboxes; interpretable diagnostics; user education.
- Standardization and certification for randomness
- Sectors: policy/regulation, industry consortia
- Vision: A “Randomness Reliability Standard” covering Protocol A/B pass rates, complexity tiers, and sample-size scaling; required for edtech, clinical, and public-sector procurements.
- Dependencies: Multi-stakeholder consensus; reference test suites; conformity assessment bodies.
- Self-auditing, quota-aware agent teams
- Sectors: synthetic data, content operations
- Vision: Generator + Auditor agents; the Auditor runs KS/χ² in-loop, tracks quotas, detects drift, and forces resampling or tool-use; supports multi-attribute joint constraints.
- Dependencies: Robust orchestration, fast validators, policy resolution for conflicts (e.g., semantic coherence vs quota satisfaction).
- Fair MCQ and assessment compilers as products
- Sectors: education
- Vision: End-to-end “Fair MCQ Compiler” that separates content generation from randomization and delivers certified uniformity across forms; item-bank analytics for ongoing audits.
- Dependencies: LMS integrations, psychometrics expertise, content QA.
- Balanced dataset synthesis platforms
- Sectors: vision/NLP data platforms, AI safety/fairness
- Vision: Drag-and-drop demographic targets with guaranteed sampling from certified samplers; integrated label verification and auto-rebalancing; compliance-ready reporting.
- Dependencies: High-accuracy attribute classifiers; scalability and governance.
- Research on the Context–Fidelity Dilemma
- Sectors: academia, labs
- Vision: New training curricula/architectures to reduce long-horizon drift, disentangle autoregressive correction from exposure bias, and support i.i.d.-like sampling under independent calls.
- Dependencies: Open benchmarks, compute budgets, collaboration across modeling and statistics communities.
- Adaptive decoding schedules and hybrid samplers
- Sectors: model R&D
- Vision: Inference strategies that interleave external sampling with controlled generation (e.g., schedule tool calls when drift detectors fire) and use learned calibrators.
- Dependencies: Drift detectors, latency budgets, UX for degraded/repair modes.
- Governance playbooks for randomness-critical workflows
- Sectors: healthcare, finance, public sector
- Vision: Sector-specific guidance (e.g., trial arm assignment, benefit lotteries, exam construction) that mandates audited RNG use and prohibits native LLM randomization for fairness-critical steps.
- Dependencies: Regulator engagement, change management, compliance training.
Glossary
- Attribute-Constrained Prompt Generation: generating prompts whose attributes follow specified target distributions; "attribute-constrained text-to-image prompt synthesis."
- Autoregression: sequence modeling where each output depends on previously generated outputs; "long-horizon autoregression risks accumulating deviation"
- Batch Generation: a sampling protocol where many samples are produced in a single response; "Batch Generation, where a model produces samples within one response,"
- Bernoulli: a discrete distribution over two outcomes with parameter ; "Bernoulli (coin-flip) tasks"
- Beta: a continuous distribution on parameterized by ; "Tier~II covers distributions with bounded supports or discrete domains (e.g., Beta, Poisson), assessing adherence to strict validity constraints."
- Binomial: a discrete distribution counting the number of successes in Bernoulli trials; "Binomial & "
- Cauchy: a heavy-tailed continuous distribution with undefined moments; "Heavy-tailed distributions such as Cauchy and Chi-Square prove particularly challenging"
- Chi-Square (distribution): a distribution of sums of squared standard normal variables, parameterized by degrees of freedom; "Heavy-tailed distributions such as Cauchy and Chi-Square prove particularly challenging"
- Chi-square goodness-of-fit test: a statistical test comparing observed counts against expected counts under a target distribution; "Chi-square goodness-of-fit test ()"
- Concentration results: probabilistic bounds describing how sample-based estimates converge with increasing sample size; "standard concentration results imply the expected error decreases with at the canonical rate"
- Context--Fidelity Dilemma: the trade-off where larger context can enable self-correction but also induce drift that degrades sampling fidelity; "The Context--Fidelity Dilemma arises because larger contexts can increase correction, yet beyond a critical horizon, the incremental increase in drift outweighs the incremental correction, causing net fidelity to degrade."
- Cumulative Distribution Function (CDF): a function giving the probability that a random variable is less than or equal to a value; " admits the CDF form"
- Dirac measure: a probability measure concentrated entirely at a single point; "where is the Dirac measure ."
- Empirical CDF: the CDF constructed from sample data; "where is the empirical CDF induced by "
- Empirical measure: a measure representing the sample distribution as a sum of point masses; "inducing an empirical measure "
- Exponential: a continuous distribution over positive values with rate parameter ; "Exponential & "
- F-Distribution: a distribution of the ratio of scaled chi-square variables, parameterized by two degrees of freedom; "F-Distribution & "
- Gamma: a positive continuous distribution parameterized by shape and scale; "Tier~III comprises heavy-tailed or multi-parameter distributions (e.g., Student's , Gamma)"
- Gaussian: the normal distribution characterized by mean and variance; "Tier~I includes canonical distributions such as Gaussian and Uniform"
- Heavy-tailed: distributions whose tails decay slowly, leading to large outliers with non-negligible probability; "Tier~III comprises heavy-tailed or multi-parameter distributions (e.g., Student's , Gamma)"
- Independent Requests: a sampling protocol where each sample is produced by a stateless, separate call; "Independent Requests, comprising stateless calls."
- Induced distribution: the stationary output distribution a model produces under a fixed prompt and decoding configuration; "outputs are modeled as conditionally i.i.d.\ draws from a stationary induced distribution ."
- Kolmogorov--Smirnov (KS) test: a nonparametric test comparing empirical CDFs to assess distributional similarity; "two-sample Kolmogorov--Smirnov (KS) test"
- Kullback--Leibler (KL) divergence: an information-theoretic measure of how one probability distribution differs from another; "We measure information loss using an approximation of the differential Kullback--Leibler divergence"
- Laplace: a symmetric, double-exponential distribution with sharp peak and heavier tails than Gaussian; "Laplace & "
- Logistic: a symmetric distribution with a sigmoid-related form and heavier tails than Gaussian; "Logistic & "
- Nucleus sampling: a decoding strategy that samples from the smallest set of tokens whose cumulative probability exceeds a threshold ; "top_p=1.0 to disable nucleus sampling truncation"
- Poisson: a discrete distribution modeling counts of events occurring at a constant rate; "Tier~II covers distributions with bounded supports or discrete domains (e.g., Beta, Poisson)"
- Student's t: a heavy-tailed distribution controlled by degrees of freedom, often used for robust modeling; "Student's "
- Top-p (nucleus sampling): the parameter controlling the cumulative-probability cutoff in nucleus sampling; "top_p=1.0 to disable nucleus sampling truncation"
- Uniform: a distribution with constant density over an interval; "Tier~I includes canonical distributions such as Gaussian and Uniform"
- Wasserstein-1 distance: an optimal transport metric measuring the geometric effort to transform one distribution into another; "Wasserstein-1 Distance ()."
- Weibull: a flexible distribution commonly used in reliability and survival analysis; "Weibull & "
- World simulators: LLMs used to model and predict environment dynamics for planning; "LLMs can function as world simulators, predicting environment state transitions to enable multi-step planning."
Collections
Sign up for free to add this paper to one or more collections.