- The paper introduces FastLane, a routed retrieval architecture that dynamically selects informative token views to reduce redundancy and enable scalability.
- The paper demonstrates that integrating a differentiable Gumbel-Softmax mechanism allows for efficient view selection, achieving up to a 30x speedup while preserving retrieval accuracy.
- The paper validates its approach through empirical evaluation on MS MARCO and TREC DL-19, showing competitive performance against traditional ColBERT models with significant efficiency gains.
Efficient Routed Systems for Scalable Retrieval: A Technical Overview
Introduction and Motivation
Contemporary information retrieval (IR) faces the dual challenge of efficiently disambiguating semantically complex queries and serving results at scale. Traditional single-vector dense retrieval models, despite their compatibility with Approximate Nearest Neighbor Search (ANNS) and their widespread production usage, lack the token-level granularity required to accurately distinguish fine semantic variations in ambiguous queries (Figure 1).
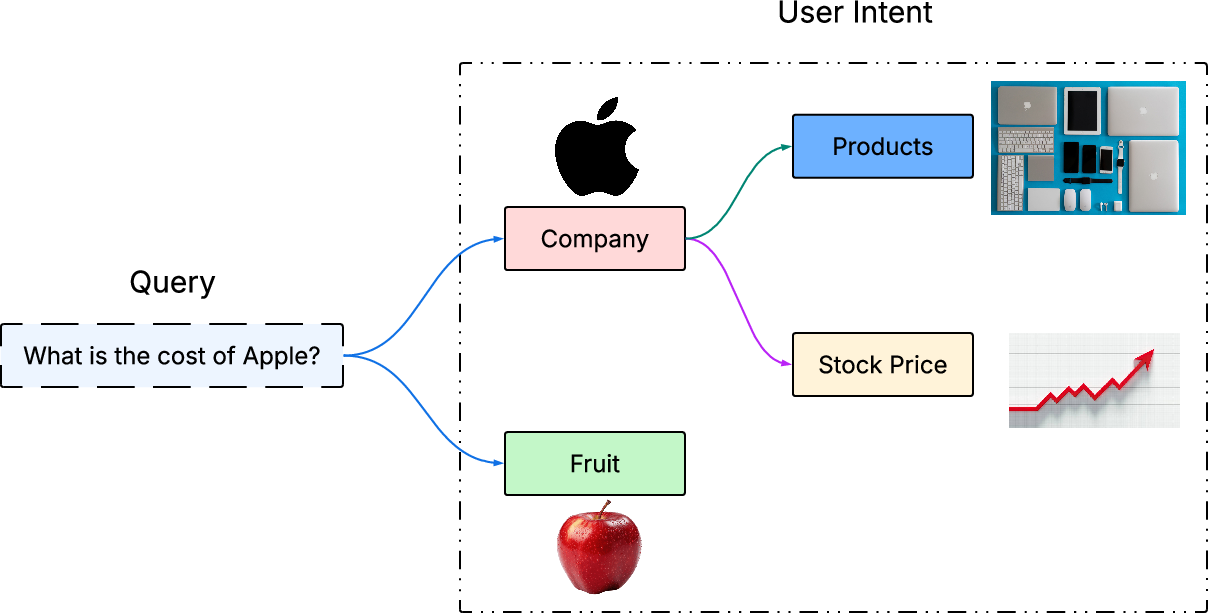
Figure 1: The query "What is the cost of Apple?" exemplifies how context-dependent intent demands fine-grained token-level understanding for disambiguation, which is not supported by standard single-vector dense retrieval models.
Late-interaction models, notably ColBERT, address this semantic gap via token-level representations and explicit aggregation (e.g., sum-max pooling), resulting in improved retrieval precision. However, this architectural gain carries a substantial computational cost: these models cannot effectively leverage standard ANNS due to their non-parallelizable, exhaustive token-to-token matching. Consequently, late-interaction models are restricted to re-ranking roles on a few candidate documents rather than powering first-stage retrieval at scale.
Analysis of Token Redundancy and View Clustering
The paper presents a critical analysis demonstrating that many token-level embeddings generated by late-interaction models exhibit high inter-token correlation. Most queries, even with large token counts, encode their semantics in a small number of distinct "views" (4–6 clusters per query), revealing significant redundancy. This observation is supported by the inspection of similarity matrices (Figure 2).
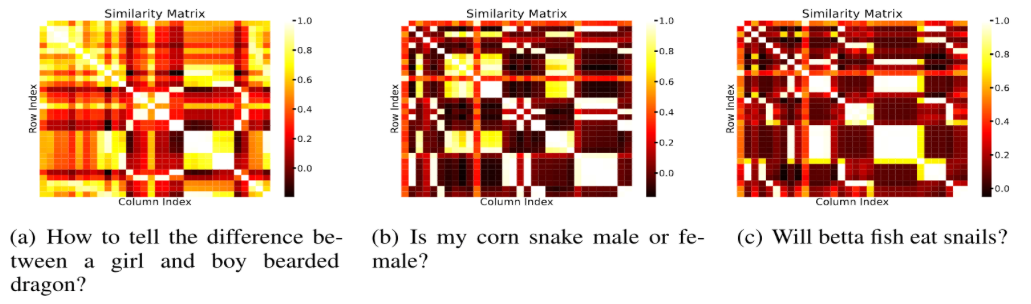
Figure 2: Token-level similarity matrix for a ColBERT-embedded query, illustrating that only a handful of token interactions encapsulate the query’s core semantics.
This analysis motivates the dynamic selection of informative "views" per query, instead of aggregating over all tokens, thereby enabling effective model compression, computational savings, and seamless integration with scalable ANNS infrastructures.
The FastLane Paradigm: Architecture and Algorithmic Contributions
The authors propose a routed retrieval architecture—here referred to as FastLane—that enables scalable late-interaction retrieval through dynamic view selection. The system integrates with a ColBERT backbone, adding a self-attention mechanism followed by a dense layer, which scores all token "views" of a query. Selection is made using a Gumbel-Softmax reparameterization, ensuring differentiable, trainable, and stochastic view selection. A straight-through estimator propagates gradients through the hard selection during training, while masking regularizes view selection.
The approach is formally articulated as follows:
- Each query’s token embeddings are transformed into a probability distribution reflecting informativeness via a self-attention layer.
- Differentiable sampling (Gumbel-Softmax) enables single-view selection per query.
- During training, regularization discourages trivial solutions, ensuring that informative views are consistently chosen.
- Resulting architectures are fully compatible with off-the-shelf ANNS, yielding a computational complexity of O(nlog(dvdoc)) per query (where n is the embedding dimension, d is document count, and vdoc is the number of document views to index).
The FastLane design reduces late-interaction computational overhead by up to 30× while maintaining retrieval effectiveness comparable to ColBERT. Figure 3 schematically contrasts this approach with traditional ColBERT.
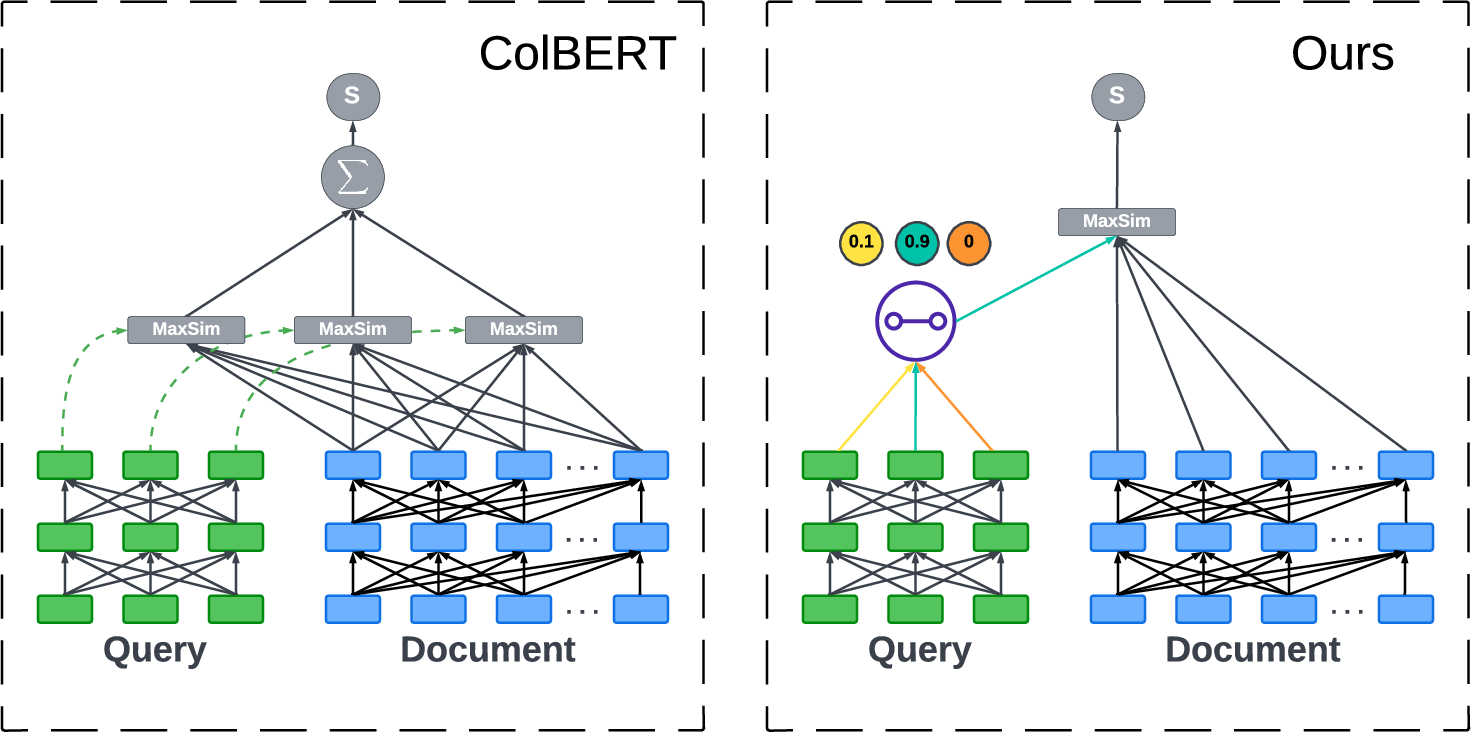
Figure 3: Architectural comparison between late-interaction ColBERT and the proposed FastLane routing model, highlighting FastLane’s token selection and parallelizability.
Empirical Evaluation
The FastLane paradigm is benchmarked against both SOTA single-view dense retrieval and late-interaction models using MS MARCO and TREC DL-19 datasets. Experimental results demonstrate:
- Retrieval Performance: FastLane achieves MRR@10 of 0.372 and nDCG@10 of 0.430 on MS MARCO, and nDCG@10 of 0.754 on TREC DL-19. These metrics are within 1% of ColBERT’s sum-max aggregation, outperform static dual-encoder baselines, and yield an 8.14% gain over strict single-vector approaches in MRR@10.
- Efficiency Gains: FastLane delivers up to 30× speedup compared to traditional ColBERT due to its ability to select and operate on a compact, informative view set and integrate with ANNS infrastructure.
- Ablation Studies: Static routing using [CLS] tokens, with either tied or split encoders, underperforms dynamic routing, confirming that intelligent view selection is critical.
The relative performance improvements are summarized in Figure 4.
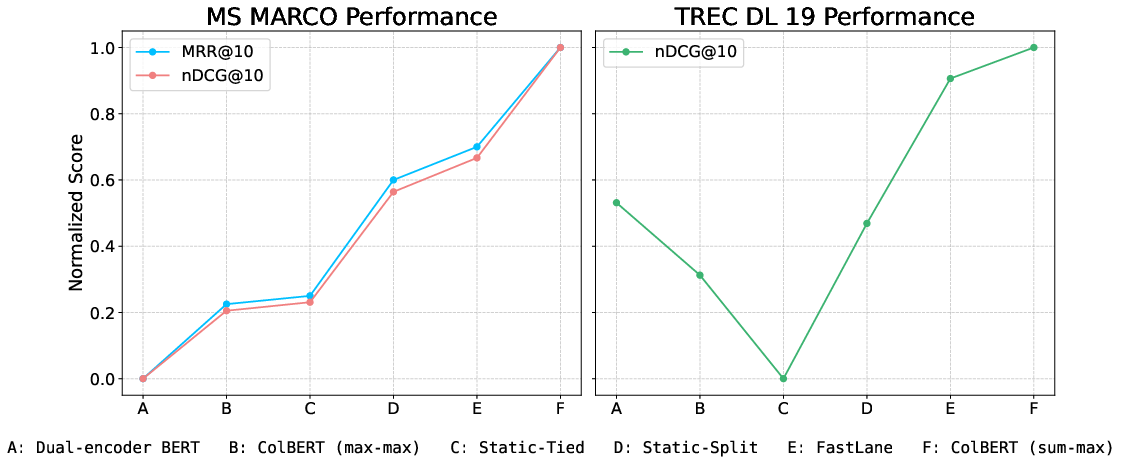
Figure 4: Comparative normalized performance curves of multiple retrieval models (MS MARCO and TREC DL-19), highlighting FastLane’s competitive accuracy and efficiency improvements over both dual-encoder and late-interaction baselines.
Practical and Theoretical Implications
By introducing an end-to-end differentiable, learnable routing mechanism for late-interaction retrieval, the FastLane approach effectively bridges the gap between the expressive capacity of multi-view models and the scalability of ANNS-based systems. The implications are multifold:
- Scalability: Late-interaction methods can now be deployed as first-pass retrieval engines, not merely re-rankers.
- Expressiveness: Enabling dynamic view selection sustains multi-view representation expressivity while suppressing redundant computation.
- Memory Footprint: While token-level storage for documents remains an open challenge, the proposed architecture allows for future extensions such as aggressive document view clustering or selective indexing.
- Extensibility: The routing mechanism’s adaptability opens the path for retrieval in multi-lingual, long-context, or multi-modal scenarios (e.g., CLIP-based or RAG pipelines), fostering alignment with contemporary trends in retrieval-augmented generation.
Future Directions
Several promising avenues are suggested by the FastLane study:
- Memory optimization: Storing only the most salient or diverse token views via clustering or DPP-based selection could further minimize index size.
- Multi-view selection: Generalizing from single-view to multi-view selection may enhance robustness to noise and further boost retrieval performance.
- Cross-modal retrieval: Integrating the routing paradigm with retrieval tasks involving longer sequences or multi-modal data.
- Bias and Fairness: Since routing mechanisms might amplify or suppress certain query interpretations based on training distributions, explicit research into robustness and bias mitigation is warranted.
Conclusion
The FastLane paradigm establishes a rigorous, efficient, and adaptable framework for routed dense retrieval, reconciling the precision of late-interaction models with the computational efficiency demanded by real-world applications. By leveraging learnable, differentiable view selection, FastLane narrows the practical gap between research-grade multi-view models and deployable retrieval systems, enabling token-level semantic distinction at the scale and latency required by industrial search and recommendation platforms. Further research along this direction will likely enable more expressive, robust, and scalable retrieval architectures suitable for evolving requirements in large-scale, multi-lingual, and multi-modal AI systems.