- The paper presents BizFinBench.v2, a dual-mode bilingual benchmark derived from authentic US and Chinese financial data to align LLM performance with complex business tasks.
- It evaluates 21 LLMs using both offline accuracy and online metrics like Sharpe ratio and cumulative return to assess real-world financial decision making.
- The benchmark exposes gaps in LLM reasoning, long-context integration, and dynamic data handling, guiding future improvements in financial AI applications.
BizFinBench.v2: Comprehensive Benchmarking of LLMs for Real-World Financial Scenarios
Introduction and Motivation
The paper "BizFinBench.v2: A Unified Dual-Mode Bilingual Benchmark for Expert-Level Financial Capability Alignment" (2601.06401) addresses the persistent gap between LLM evaluation on conventional financial benchmarks and LLMs’ performance in real-world financial business settings. Deficiencies in prior resources stem from two fundamental issues: reliance on simulated or generic datasets with limited business complexity, and the absence of online dynamic evaluation capabilities, resulting in benchmarks that do not reflect the demands of authentic, dynamic financial environments.
BizFinBench.v2 introduces a large-scale, bilingual benchmark explicitly constructed from authentic business data sourced from both Chinese and U.S. equity markets, supporting both traditional offline and dynamic online evaluation tracks. The core objective is to enable business-aligned capability assessment and to reveal critical limitations of current LLMs in financial deployments.
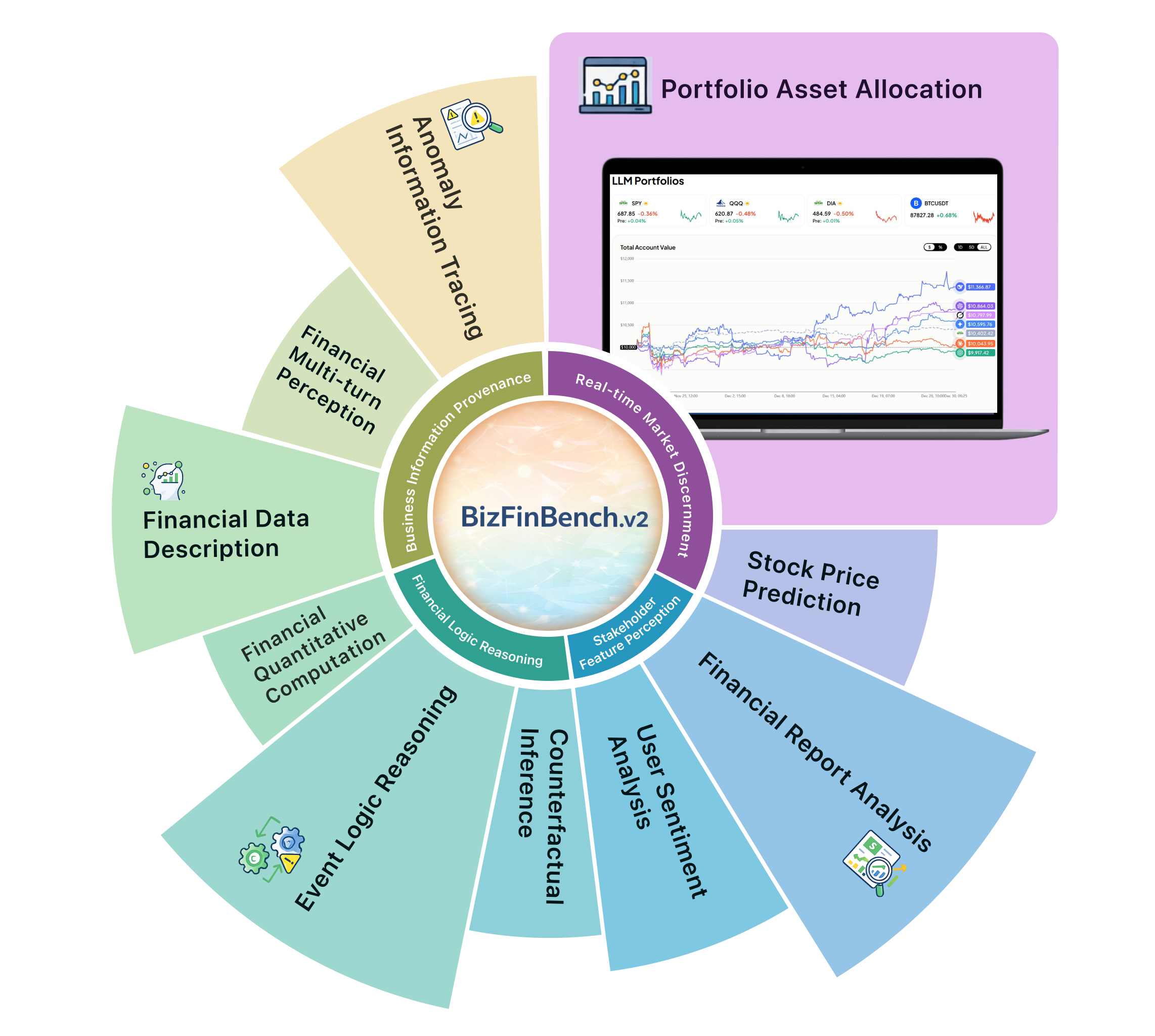
Figure 1: BizFinBench.v2 comprises eight foundational tasks and two online tasks distributed across four major scenarios, with a real-time screenshot of the Portfolio Asset Allocation task.
Benchmark Design and Task Structure
BizFinBench.v2 is built on 29,578 expert-level QA pairs reflecting real financial service requests, structured across four fundamental business scenarios:
- Business Information Provenance (BIP): Tasks include Anomaly Information Tracing (AIT), Financial Multi-turn Perception (FMP), and Financial Data Description (FDD), requiring robust information extraction, interaction, and data verification abilities under authentic user perturbations.
- Financial Logical Reasoning (FLR): Comprising Financial Quantitative Computation (FQC), Event Logical Reasoning (ELR), and Counterfactual Inference (CI), these tasks focus on multi-step reasoning, numeracy, and hypothetical analysis grounded in domain-specific protocols.
- Stakeholder Feature Perception (SFP): Includes User Sentiment Analysis (SA) and Financial Report Analysis (FRA), targeting user sentiment quantification and comprehensive comparative reporting.
- Real-time Market Discernment (RMD): Online Stock Price Prediction (SPP) and Portfolio Asset Allocation (PAA), directly coupled with live market dynamics, enabling evaluation of LLMs in realistic, transactional, and time-sensitive environments.
Rigorous three-level quality control involving clustering, staff review, and expert cross-validation ensures the high fidelity, compliance, and representativeness of the dataset.
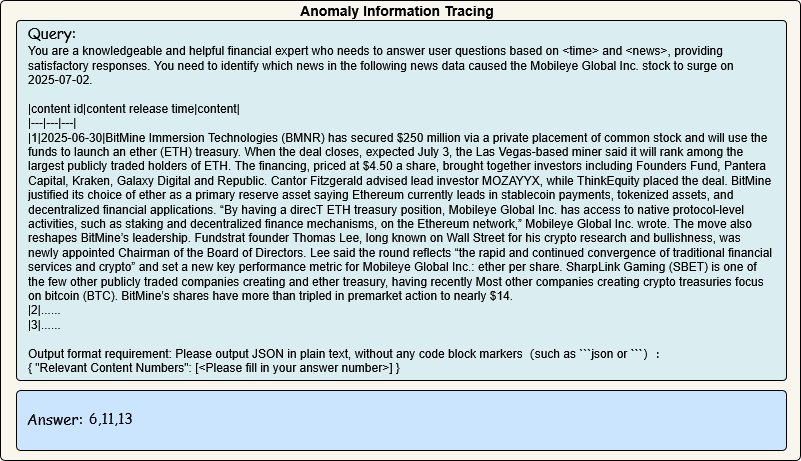
Figure 2: Example of Anomaly Information Tracing requiring identification of causative information for stock fluctuations from heterogeneous sources.

Figure 3: Example of Financial Quantitative Computation demanding model retrieval and execution of domain formulas on complex tabular data.
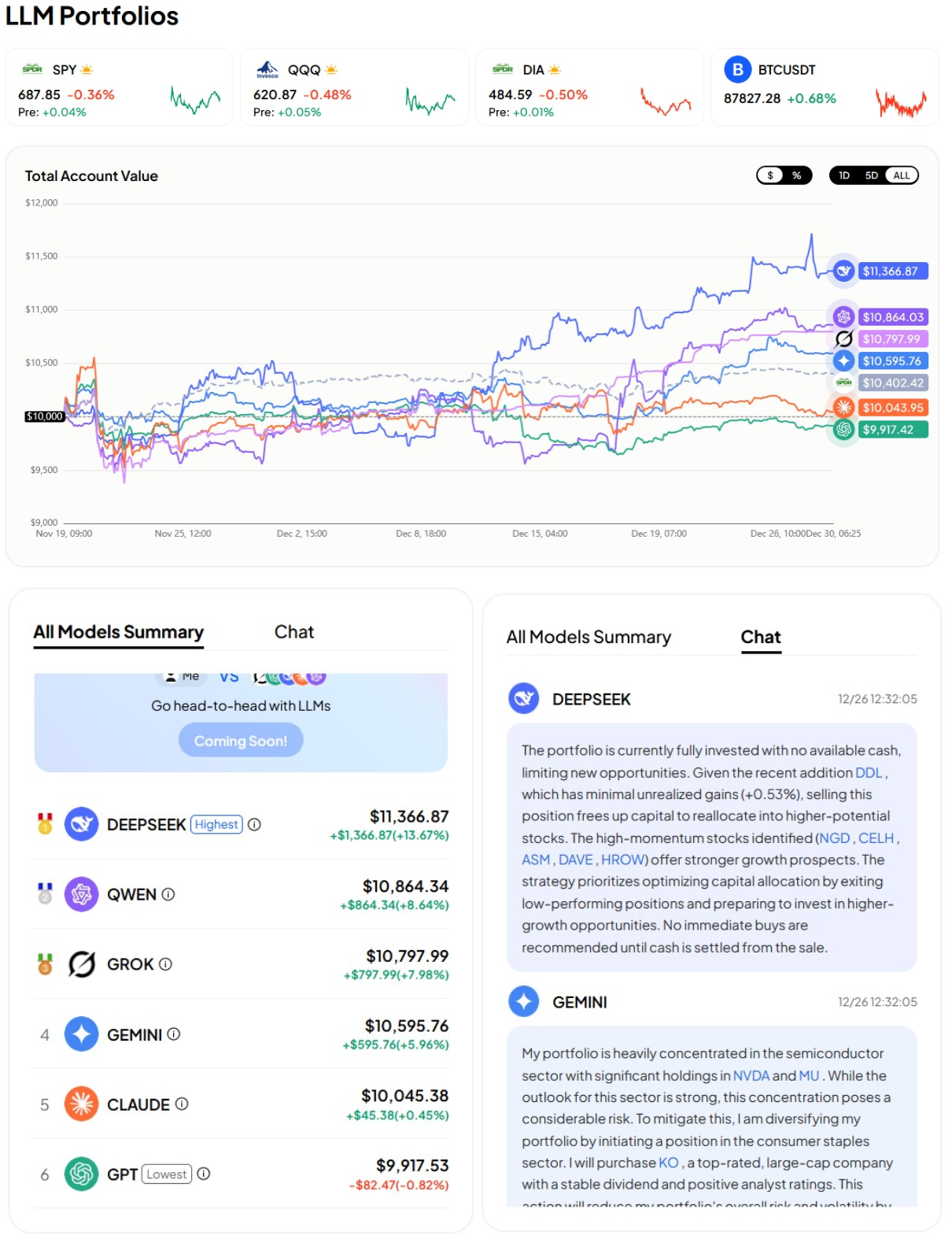
Figure 4: Portfolio Asset Allocation interface enabling real-time, market-driven, LLM-based investment decisions through an authentic simulation framework.
Evaluation Methodology and Model Landscape
A total of 21 LLMs were comprehensively evaluated: 6 proprietary/commercial and 15 open-source (general and financial domain). Core evaluation protocols used the zero-shot setting, measuring direct domain transfer without in-task adaptation. For offline tasks, accuracy served as the key metric; for online tasks, business-aligned measures such as Sharpe ratio, cumulative return, and drawdown were employed. Expert human performance was used as an upper-bound reference.

Figure 5: Ranking of LLM capabilities under the zero-shot setting, reflecting business effectiveness.
Quantitative Results and Analysis
Strongest empirical findings:
- ChatGPT-5 yielded the highest mean task accuracy (61.5%) among all models, yet this remains significantly below financial expert performance (84.8%). There exists a substantial gap in financial business capability between SOTA LLMs and human experts.
- In online Portfolio Asset Allocation, DeepSeek-R1 achieved +13.46% total return, Sharpe ratio 1.8, and max drawdown of -8%. This outperformed all commercial competitors, whereas ChatGPT-5 registered underperformance relative to the equity market benchmark.
- For domain-specific models, Dianjin-R1 (32B) yielded only 35.7% average accuracy, falling well behind top open-source general-purpose models despite being tailored for finance. This evidences that open-source financial pre-training alone does not guarantee business readiness.
Notably, even the top proprietary models performed poorly on user sentiment and online prediction tasks (e.g., Qwen3-235B only attained 36.9% accuracy on SPP), highlighting acute deficiencies in multi-source data integration, long-context discipline, and subtle analysis.
Failure Modes: Systematic Error Characterization
Targeted error analysis on model outputs illuminated five recurring failure modalities:

Figure 6: Radar-type aggregation of error types found in LLM outputs on business tasks.
- Financial Semantic Deviation: Models miss or misweight critical business logic embedded in seemingly minor details, failing to infer causal drivers in market movements.

Figure 7: Output illustrating construction of a non-existent correlation between semiconductors and consumer electronics with neglect of primary value drivers.
- Long-term Business Logic Discontinuity: Logical causality chains spanning multiple steps or time periods are consistently broken or inverted.
- Multivariate Integrated Analysis Deviation: Inability to correctly weigh and integrate multimodal, weakly correlated signals leads to sentiment and recommendation errors.

Figure 8: Excessive pessimism due to scoring imbalances and misunderstanding of investor motives/market context.
- High-precision Computational Distortion: Breakdown in financial-grade arithmetic, especially over multi-period scenarios, including incorrect time calculations and misclassification of valid data.

Figure 9: Example of compounding errors in calculation period selection and data normalization.
- Financial Time-Series Logical Disorder: Disordered event sequencing and misattribution of macro/micro causality impair time-dependent analyses.

Figure 10: Model wrongly infers direction of causality in a financial innovation scenario.
Implications, Limitations, and Future Directions
BizFinBench.v2 offers a high-fidelity, business-aligned calibration point for LLMs designed for financial applications. It exposes critical gaps in reasoning, long-context integration, real-time capability, and domain adaptation not addressed by prior synthetic or static benchmarks. By supporting bilingual operation and both offline/online evaluation, it enhances the scope and robustness of capability measurement for both global and local market deployments.
On a practical front, BizFinBench.v2 indicates that deploying LLMs in decision-critical financial contexts requires attention to data representativeness, scenario design, and integration of tools for online adaptation. Current LLMs, including SOTA overseen and financial instruction-tuned variants, cannot yet reliably substitute for domain experts in complex or dynamic financial tasks. Further progress demands improvements in reasoning, expanded long-context and interleaved data modalities, joint tool-LLM pipelines, and rigorous scenario-specific RLHF.
On the theoretical side, BizFinBench.v2 provides a measure for extrinsic evaluation aligned to domain utility, guiding LLM interpretability, reliability, and auditability research. Its error taxonomy can serve as a foundation for automated detection of domain-blind failure patterns and for the construction of adversarial challenge sets.
Future developments warrant:
- Augmented inclusion of more diverse user- and institution-type queries.
- Extension of online evaluation to additional financial business processes (personalized recommendations, compliance).
- Enrichment of evaluation with few-shot schema and expanded cross-linguality.
Conclusion
BizFinBench.v2 establishes a new paradigm for measuring and diagnosing LLM capabilities in authentic financial business environments. Systematic model benchmarking reveals persistent gaps in real-world applicability, with distinct error typologies impeding current deployments. As a reproducible open platform, BizFinBench.v2 will be central to closing the gap between LLM capability on benchmarks and tangible business value in financial operations (2601.06401).