- The paper introduces a multilingual, multimodal, and difficulty-aware benchmark designed to evaluate large language models in financial domains.
- It details a framework with 34 datasets across 7 task categories in 5 languages, emphasizing challenging cross-modal, cross-lingual financial tasks.
- Experimental results demonstrate that even state-of-the-art models struggle with complex financial inputs, underscoring the need for improved multimodal integration.
MultiFinBen: A Multilingual, Multimodal, and Difficulty-Aware Benchmark for Financial LLM Evaluation
Introduction
MultiFinBen is a comprehensive benchmark developed to evaluate LLMs in the financial domain. This benchmark extends the capabilities of existing evaluations by introducing multilingual and multimodal components that reflect the complexity of real-world financial tasks. With a dynamic, difficulty-aware selection mechanism, MultiFinBen provides a rigorous framework for assessing the performance of LLMs across text, vision, and audio modalities in multilingual contexts.
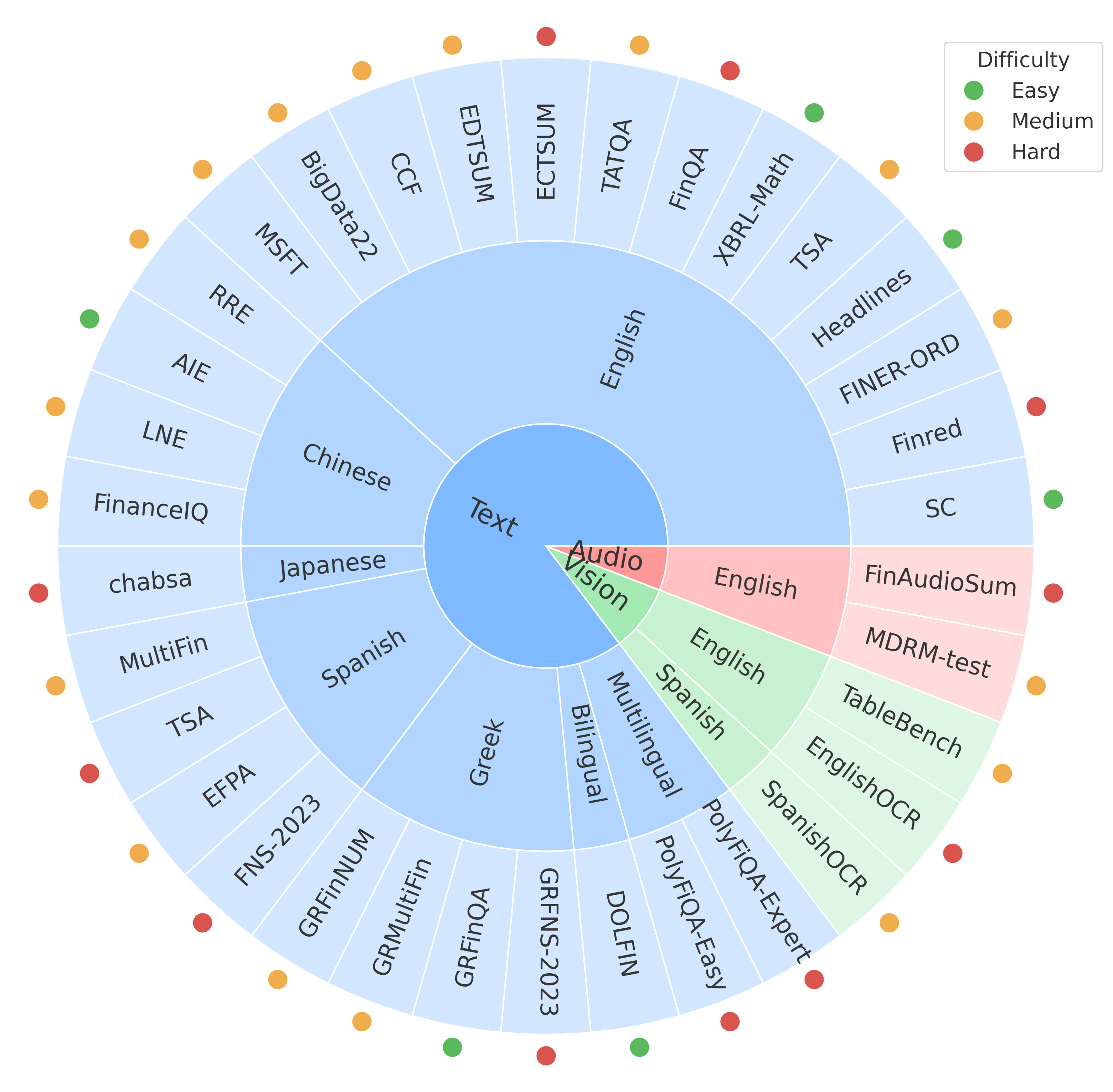
Figure 1: Overview of MultiFinBen.
MultiFinBen addresses two critical limitations of current benchmarks: their predominant focus on monolingual, unimodal settings and their reliance on simple aggregation without accounting for task difficulty. By incorporating diverse languages and modalities, MultiFinBen evaluates models' capabilities in handling the complexities typical of global financial tasks.
Benchmark Design
MultiFinBen is structured to evaluate LLMs on three modalities (textual, visual, and audio) and in five languages (English, Chinese, Japanese, Spanish, and Greek). It comprises 34 datasets organized across seven task categories and stratified into three difficulty levels. The benchmark introduces novel tasks, including PolyFiQA-Easy and PolyFiQA-Expert, for multilingual reasoning and EnglishOCR and SpanishOCR, for visual-text document analysis.
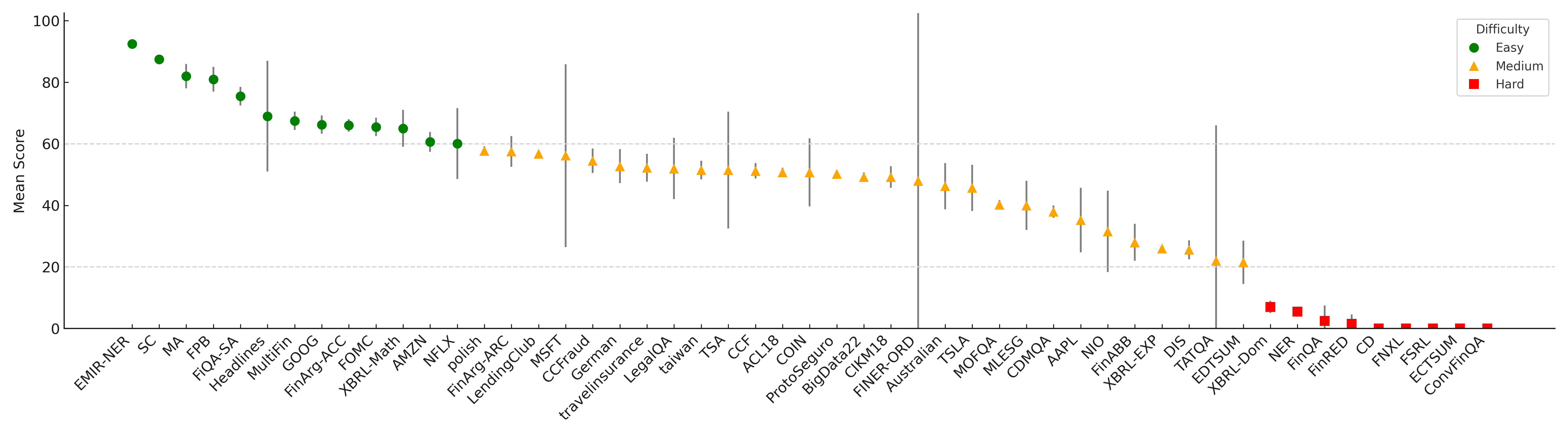
Figure 2: Structured difficulty-aware benchmarking of English datasets.
To ensure balanced and meaningful evaluations, tasks are selected based on their challenge to existing models, emphasizing those with the largest inter-model performance gaps. This approach highlights the areas where LLMs still face significant limitations, particularly in cross-lingual and cross-modal scenarios.
Multimodal and Multilingual Dataset
MultiFinBen's datasets include:
- Text Modality: The benchmark includes multilingual datasets for question answering, information extraction, textual analysis, and text generation. Among these, PolyFiQA tasks challenge models with multilingual financial documents requiring complex reasoning.
- Vision Modality: EnglishOCR and SpanishOCR datasets test models' ability to extract and reason over information from visually rich financial documents, such as balance sheets and charts.
- Audio Modality: The benchmark evaluates models on financial audio tasks including speech recognition and summarization using datasets like FinAudioSum.
Experimental Results
The evaluation of 22 state-of-the-art models revealed that even leading models like GPT-4o struggle with MultiFinBen's challenging tasks, achieving only a 50.67% average score. Performance discrepancies were particularly pronounced in multilingual and multimodal tasks, underscoring ongoing challenges in these areas.
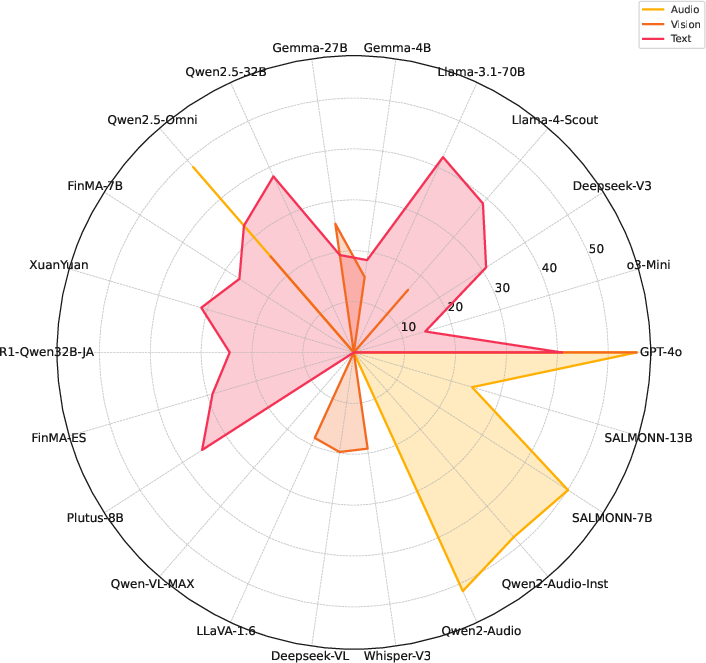
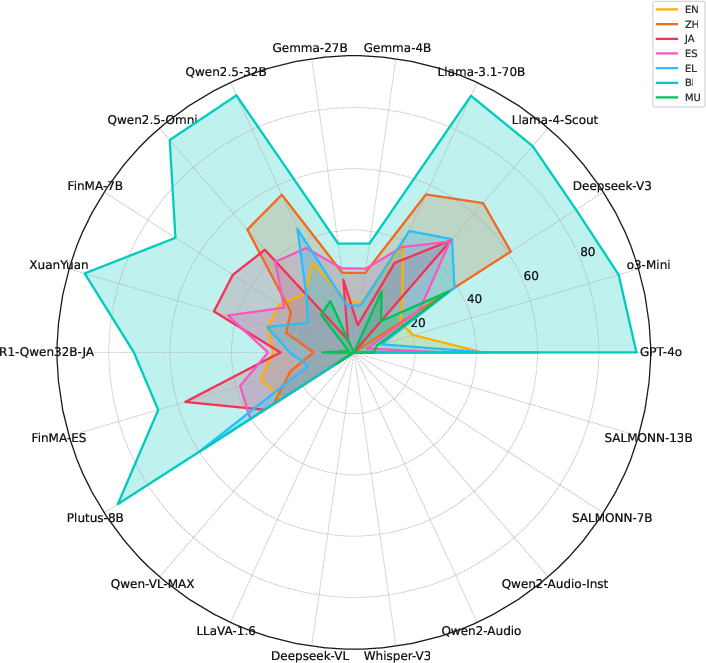
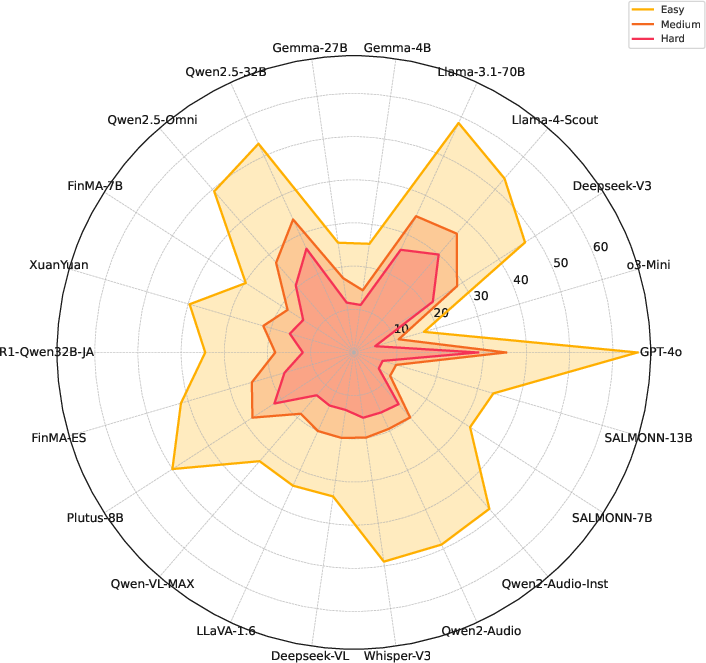
Figure 3: Performance across modalities: Audio, Vision, Text.
Text-only models performed poorly compared to multimodal models, highlighting the importance of integrated modalities for handling complex financial inputs. The benchmark's difficulty-aware design further exposed significant performance drops from simpler to harder tasks, with structured difficulty revealing clear weaknesses in current model capabilities.
Implications and Future Directions
MultiFinBen sets a new standard for financial LLM evaluation, emphasizing the need for models capable of nuanced, multilingual understanding across diverse data types. This benchmark provides a valuable tool for guiding future AI development, emphasizing enhancements in multilingual and multimodal processing.
Looking ahead, MultiFinBen can act as a catalyst for the creation of more sophisticated models and datasets, aimed at bridging the gap between current capabilities and real-world financial task demands. The benchmark's public release aims to foster collaborative progress in AI research, promoting transparent, reproducible, and inclusive advancements in the financial domain.
Conclusion
MultiFinBen represents a significant advancement in the evaluation of LLMs for financial applications. By integrating multilingual and multimodal challenges with a focus on task difficulty, it provides a robust framework for assessing and guiding the development of more capable and versatile AI systems in finance. As the financial landscape continues to evolve, benchmarks like MultiFinBen will be crucial in ensuring that AI systems can meet the complex needs of global markets.