- The paper introduces FinMTEB, a benchmark with 64 datasets across seven financial NLP tasks, filling a gap in domain-specific evaluation.
- It presents Fin-E5, a state-of-the-art finance-adapted embedding model fine-tuned with persona-based synthetic data for superior performance.
- The study benchmarks 15 models and reveals that traditional dense embeddings underperform in financial semantic tasks, highlighting the need for domain-specific approaches.
FinMTEB: Finance Massive Text Embedding Benchmark
Introduction
The "FinMTEB: Finance Massive Text Embedding Benchmark" paper addresses the gap in existing benchmarks for text embedding models tailored to specialized domains, particularly finance. While general-purpose datasets have largely propelled the innovation in NLP applications, their applicability in the financial domain is limited due to domain-specific semantics and complex relationships inherent in financial texts. The authors introduce FinMTEB, a benchmark comprising 64 datasets across seven task types such as classification, clustering, retrieval, pair classification, reranking, summarization, and semantic textual similarity (STS) in both English and Chinese.
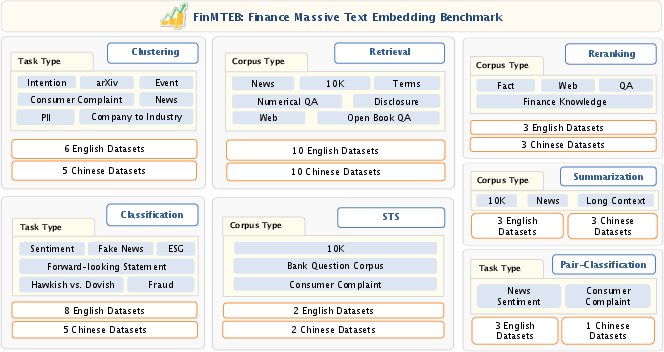
Figure 1: An overview of tasks and datasets used in FinMTEB. All the dataset descriptions and examples are provided in the Appendix.
Fin-E5 Model Development
The authors propose Fin-E5, a state-of-the-art finance-adapted embedding model that excels on FinMTEB. This model is fine-tuned from the e5-Mistral-7B-Instruct using a persona-based synthetic dataset, which enhances its ability to perform various financial embedding tasks. Fin-E5's design is rooted in the principle that domain-specific models vastly outperform general-purpose models in specialized tasks. The architecture draws on contemporary LLM-based embeddings fine-tuned for specific financial contexts, showing strong promise in tasks such as semantic similarity and text retrieval.
Benchmarks and Model Evaluation
The paper evaluates 15 prominent embedding models on FinMTEB, underscoring three critical insights:
- Domain-Specific Advantage: Domain-specific models, including Fin-E5, significantly outperform general-purpose counterparts.
- Benchmark Predictivity: Performance on general benchmarks poorly predicts success in financial tasks, highlighting the necessity of domain-specific evaluation metrics.
- Dense vs Sparse Embeddings: Traditional Bag-of-Words (BoW) models unexpectedly surpass dense embeddings in financial STS tasks, suggesting limitations in current dense embedding methodologies for nuanced financial semantics.
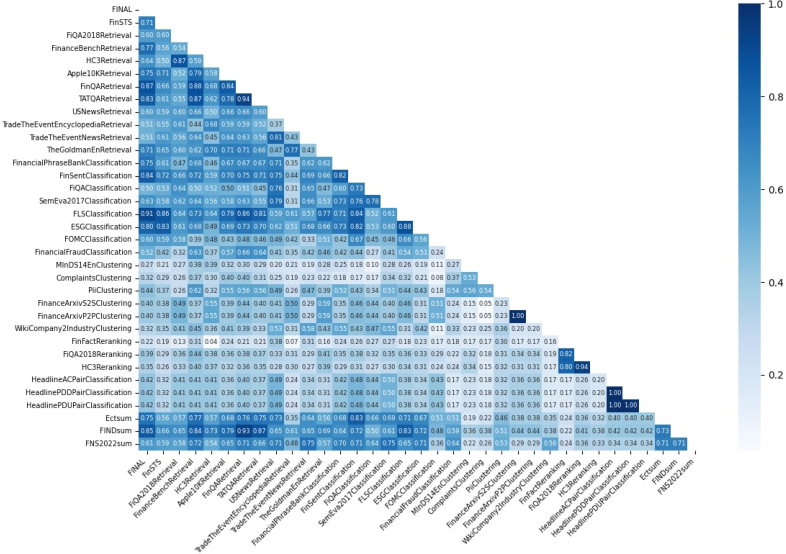
Figure 2: Semantic similarity across all the datasets in FinMTEB benchmark.
Implementation and Training
The Fin-E5 model hinges on a persona-based data generation approach, utilizing a triplet structure of query, positive document, and negative examples to refine embedding accuracy. The training pipeline involves constructing a rich dataset from InvestLM's QA resources and synthesizing task-relevant context utilizing advanced LLMs like Qwen2.5-72B-Instruct. The model is trained using a contrastive learning paradigm, adapting the InfoNCE loss to distinguish positive contextual passages effectively amidst semantically similar distracting documents.
Experimental Results
The empirical evaluations reveal that Fin-E5 sets a new standard in domain-adapted text embeddings with rigorous stratification across seven financial tasks. The model significantly improves classification and retrieval performances, though dense embedding models like NV-Embed v2 also showcase competitive results. The finance-centric evaluation elucidates the performance uplift from domain adaptation, particularly in tasks demanding precise semantic alignment and complex numerical reasoning.
Implications and Future Directions
The introduction of FinMTEB establishes a foundational protocol for evaluating embedding performance in the financial domain, providing actionable insights for developing robust financial NLP solutions. The paper advocates for open-sourcing FinMTEB and Fin-E5, inviting the research community to leverage these resources for continued advancement in domain-focused NLP initiatives. Future work may focus on extending FinMTEB beyond English and Chinese to include multilingual datasets, thereby broadening the benchmark’s applicability to global financial markets.
Conclusion
This paper pioneers in introducing FinMTEB as a comprehensive benchmarking suite for financial text embeddings, demonstrating the pivotal role of domain adaptation in enhancing embedding models. Fin-E5 achieves state-of-the-art results on FinMTEB, advancing the dialogue around specialized text representations and their profound impact on extracting meaningful insights from financial narratives.