ArenaRL: Scaling RL for Open-Ended Agents via Tournament-based Relative Ranking
Abstract: Reinforcement learning has substantially improved the performance of LLM agents on tasks with verifiable outcomes, but it still struggles on open-ended agent tasks with vast solution spaces (e.g., complex travel planning). Due to the absence of objective ground-truth for these tasks, current RL algorithms largely rely on reward models that assign scalar scores to individual responses. We contend that such pointwise scoring suffers from an inherent discrimination collapse: the reward model struggles to distinguish subtle advantages among different trajectories, resulting in scores within a group being compressed into a narrow range. Consequently, the effective reward signal becomes dominated by noise from the reward model, leading to optimization stagnation. To address this, we propose ArenaRL, a reinforcement learning paradigm that shifts from pointwise scalar scoring to intra-group relative ranking. ArenaRL introduces a process-aware pairwise evaluation mechanism, employing multi-level rubrics to assign fine-grained relative scores to trajectories. Additionally, we construct an intra-group adversarial arena and devise a tournament-based ranking scheme to obtain stable advantage signals. Empirical results confirm that the built seeded single-elimination scheme achieves nearly equivalent advantage estimation accuracy to full pairwise comparisons with O(N2) complexity, while operating with only O(N) complexity, striking an optimal balance between efficiency and precision. Furthermore, to address the lack of full-cycle benchmarks for open-ended agents, we build Open-Travel and Open-DeepResearch, two high-quality benchmarks featuring a comprehensive pipeline covering SFT, RL training, and multi-dimensional evaluation. Extensive experiments show that ArenaRL substantially outperforms standard RL baselines, enabling LLM agents to generate more robust solutions for complex real-world tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “ArenaRL: Scaling RL for Open-Ended Agents via Tournament-based Relative Ranking”
Overview
This paper is about teaching AI “agents” (smart programs powered by LLMs) to handle open-ended tasks—things like planning a complex trip or doing deep research online. These tasks don’t have a single correct answer, and there isn’t an easy way to check if the AI’s answer is “right.” The authors propose a new way to train these agents called ArenaRL, which uses a tournament-style ranking (like sports brackets) instead of trying to give each answer a single score. This makes training more stable and helps the AI learn real reasoning and planning skills.
Key Objectives
The paper focuses on simple but important questions:
- How can we train AI agents for tasks with many possible good answers, where there’s no exact “correct” solution?
- Why do current training methods stall or fail on these tasks?
- Can comparing answers directly (like judging matches in a tournament) teach the AI better than giving each answer a single score?
- How do we make this comparison process fast enough to use in real training?
- Can we build high-quality benchmarks that let researchers train and fairly test these open-ended agents?
How They Did It (Methods, with simple analogies)
To understand their approach, it helps to learn a few concepts:
Why pointwise scores fail
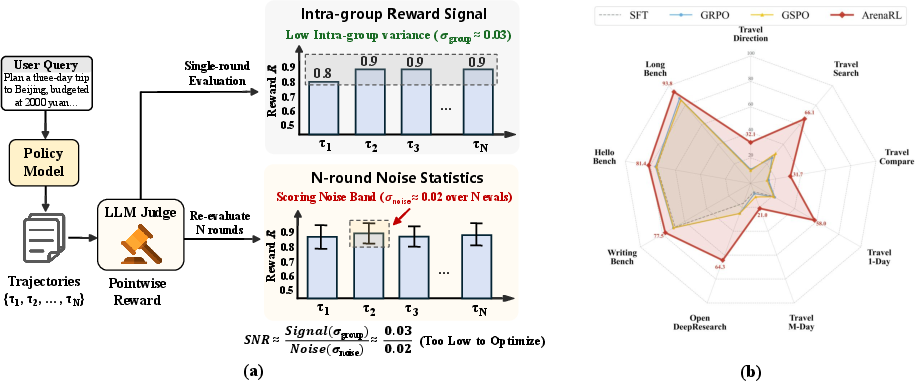
- Pointwise scoring means giving each answer a single score (like 8.6/10) from a judge model.
- Problem: When the AI gets good, most of its answers are “pretty good,” so the scores bunch up (for example, many answers get 8.5–9.0). Tiny differences get lost.
- Judges can be noisy too (they may like longer answers or be random sometimes), so the scores don’t clearly show which answer is truly better. This is like rating several great essays all “A-” and not knowing which one is the best.
The ArenaRL idea: compare answers like a tournament
- Instead of scoring answers one by one, ArenaRL compares them pairwise—like two players facing off.
- For each user task, the AI generates multiple solution “trajectories.” A trajectory is the full process the agent follows: its thinking steps, the tools it uses (like maps or web search), and its final answer.
- A judge model looks at two trajectories together and decides which one is better based on clear rubrics (rules), not just the final answer.
Process-aware judging (not just the final result)
- The judge checks:
- Chain-of-thought: Is the reasoning logical?
- Tool use: Did the agent call the right tools and use them well?
- Final answer: Is it useful, consistent, and reliable?
- This is like grading a science project by looking at the experiment steps and the report, not just the final conclusion.
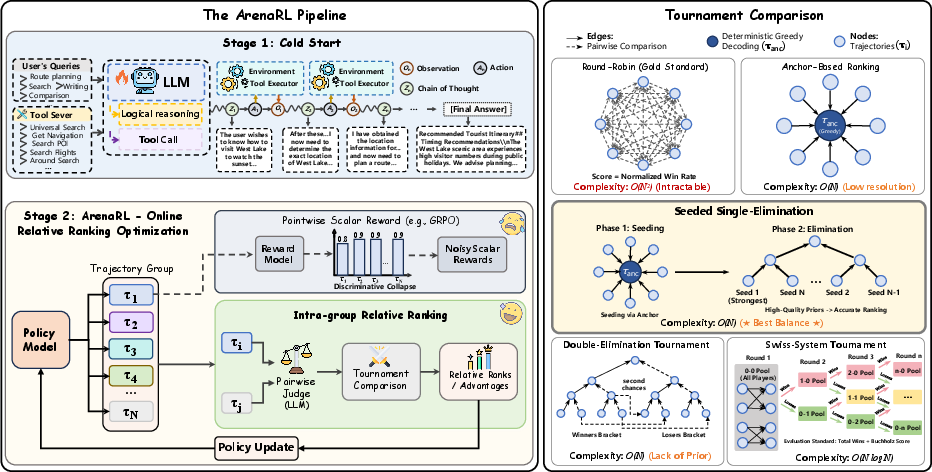
Tournament ranking formats (like sports brackets)
To find which answers are best without comparing every pair (which would be too slow), they tried several tournament styles:
- Round-robin: Everyone plays everyone. Very accurate, but slow (needs about comparisons for answers).
- Anchor-based ranking: Pick one “anchor” answer (made by greedy decoding, like choosing the most likely words at each step, which gives a stable reference), then compare each other answer to the anchor. Fast, but doesn’t compare the non-anchor answers against each other.
- Single-elimination: Loser is out, winner moves on. Faster, but can eliminate great answers early if matchups are unlucky.
- Double-elimination: You need to lose twice to be out. More forgiving, but still depends on initial pairings.
- Swiss-system: Everyone plays multiple rounds against others with similar records. Balanced, but a bit more complex.
Seeded single-elimination (their best design)
- They first use the anchor (the steady reference solution) to “seed” the bracket—like ranking teams before a tournament so strong ones don’t knock each other out early.
- Then they run a single-elimination tournament with these seeds.
- Result: Almost as accurate as round-robin but much faster (needs about $2N$ comparisons instead of ).
- Analogy: It’s like organizing a fair school competition where top students don’t meet in the first round, ensuring a better final ranking.
Turning ranks into learning signals
- After the tournament, each trajectory has a rank (best to worst).
- They convert ranks into a smooth learning signal (an “advantage”), so the AI is nudged to produce more like the top-ranked trajectories next time.
- Think of it like telling the AI: “Do more of what led to the winning solutions; do less of what led to the early exits.”
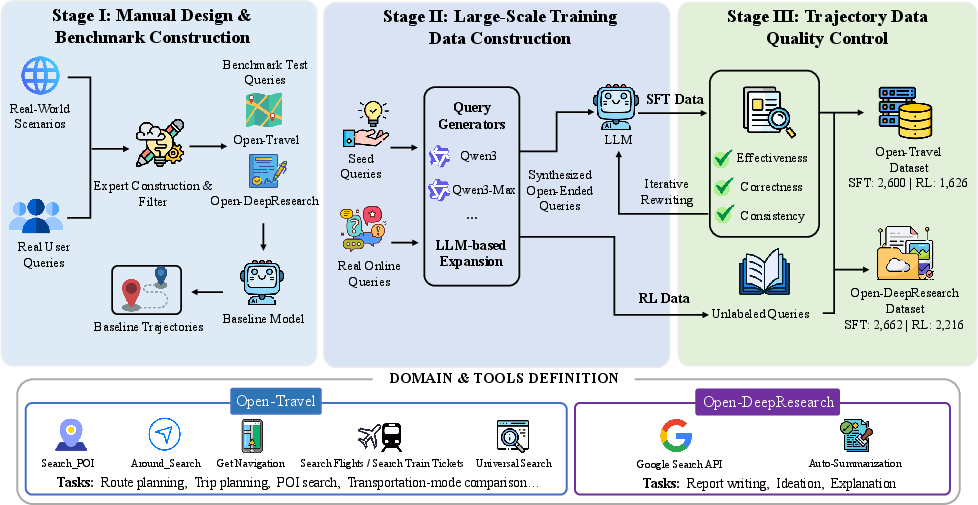
Building real benchmarks
They also created two full-cycle benchmarks to train and test open-ended agents:
- Open-Travel: Complex trip planning with constraints like budget, timing, and preferences (e.g., multi-day plans, city routes, comparisons of transport).
- Open-DeepResearch: Multi-step web research to produce useful reports, plans, or summaries in realistic internet environments. These benchmarks include supervised fine-tuning data, reinforcement learning setups, and automatic evaluation—so others can reproduce and compare results fairly.
Main Findings and Why They Matter
Here are the main takeaways from their experiments:
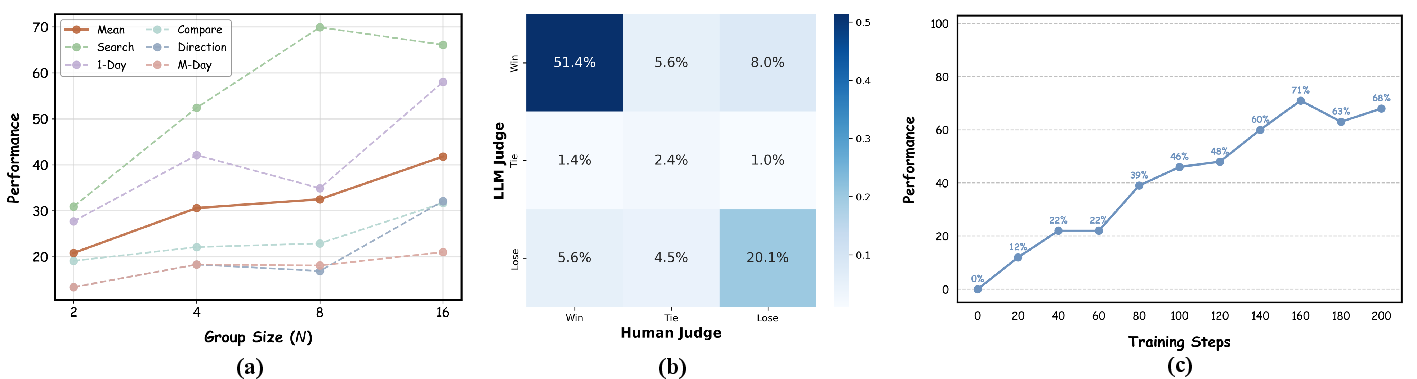
- Tournament-based ranking beats single-score (pointwise) methods:
- ArenaRL significantly outperforms common RL baselines (like GRPO and GSPO) on both Open-Travel and Open-DeepResearch.
- It also shows strong results on open-ended writing tasks, not just planning and research.
- Efficiency without sacrificing accuracy:
- Seeded single-elimination achieves almost the same ranking quality as round-robin but with far fewer comparisons (linear instead of quadratic growth).
- Better real-world performance:
- On deep research tasks, ArenaRL produces valid, complete answers much more reliably (very high valid generation rate), which is crucial for long tasks with lots of steps and tool calls.
- Robust reasoning and tool use:
- Because the judge looks at the whole process, ArenaRL helps the AI learn to think clearly, plan carefully, and use tools effectively—not just to produce a flashy final answer.
Implications and Potential Impact
- Stronger, more reliable AI agents: ArenaRL helps AI handle open-ended tasks that matter in real life—planning trips, writing reports, doing research—where there’s no single “right” answer.
- Fairer, clearer training signals: By comparing answers directly and judging the entire process, the AI learns what truly makes a solution better, not just how to game a scoring system.
- Scalable method: The seeded tournament makes pairwise training practical, opening doors to training agents in many domains with long, complex reasoning.
- Community resources: The new benchmarks and pipeline let other researchers build, train, and judge open-ended agents in a reproducible way.
- Broader adoption: This tournament-based idea could be used for other creative or multi-step tasks, like design, education, or collaborative writing—anywhere thoughtful process beats one-number scores.
In short, ArenaRL replaces noisy single-number scoring with fair, process-aware tournaments. That shift helps AI agents learn the kind of step-by-step thinking and tool use needed to succeed in complex, open-ended tasks.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. These items are framed to guide future research efforts.
- Absence of formal theory: No rigorous analysis quantifies “discriminative collapse” (e.g., conditions, SNR bounds) or provides convergence guarantees for rank-based PPO with KL regularization on open-ended tasks.
- Ranking fidelity guarantees: The seeded single-elimination tournament is empirically close to round-robin, but there is no probabilistic/error-bound analysis of misranking rates versus topology, group size, and judge noise.
- Sensitivity to hyperparameters: The method’s performance dependence on group size (N), number of groups (K), sampling temperature, seeding rules, and KL coefficient (β) is not systematically explored.
- Anchor selection bias: Greedy-decoded anchors may encode stylistic or length biases; the impact of alternative anchoring heuristics (e.g., top‑p anchors, prior best trajectories, multi-anchor ensembles) is unknown.
- Tie and margin handling: Although pairwise judges output separate scores, ranking reduces to binary wins; using score margins or calibrated pairwise distances to enhance advantage signals is not examined.
- Advantage normalization edge cases: The standardized advantage A_i still depends on intra-group variance; behavior when σ_r is small (ties/plateaus) and its effect on gradient stability remains unstudied.
- Judge robustness and calibration: Reliance on closed-source LLM judges without inter-judge agreement metrics, calibration curves, or reliability analyses (e.g., Cohen’s kappa) leaves uncertainty about reward noise and bias.
- Bias mitigation beyond order swap: Bidirectional presentation addresses positional bias, but residual biases (verbosity, length, stylistic preferences, domain familiarity, language bias) are neither measured nor corrected.
- Adversarial/judge gaming risks: Whether agents learn to exploit rubric/judge idiosyncrasies (reward hacking) rather than improving true reasoning quality is not evaluated; robust adversarial tests are needed.
- Multi-objective preferences: The rubric aggregates multi-dimensional criteria into a single rank; exploring vector-valued rewards, Pareto fronts, or principled multi-objective optimization is left open.
- Token- and step-level credit assignment: ArenaRL optimizes at trajectory level; methods to attribute credit to specific chain-of-thought steps or tool invocations for finer-grained updates are not developed.
- Cost and scalability: Real token/computational costs of process-aware pairwise judging (especially for long-horizon tasks) and strategies for budget-aware training (e.g., selective matches, early-stopping) are not reported.
- Context-overflow mitigation: DeepResearch context overflows are observed, but architectural or policy-level strategies (chunking, memory modules, retrieval compression, planning horizons) to reduce overflow are not investigated.
- Generalization across domains/languages: Benchmarks are predominantly Chinese with mixed English in DeepResearch; cross-lingual, cross-domain robustness and transfer of ArenaRL beyond the evaluated domains remain untested.
- Benchmark validity: Open-Travel includes partially verifiable constraints (budget, time, routes), yet evaluation relies on LLM judges rather than objective metrics (e.g., feasibility checks, route consistency); human studies are absent.
- Baseline coverage: Comparisons omit pairwise/preference baselines like DPO, RRHF variants, Direct Preference Optimization, and Pref-GRPO configured for long-horizon agents; fairness against stronger or tuned baselines is unclear.
- Tournament design space: Only one seeded single-elimination variant is used; adaptive seeding, multi-stage hybrid formats, or confidence-aware pairing (e.g., ELO/Bayes) to further improve fidelity at O(N) are unexplored.
- Dynamic tournaments during training: How to adapt tournament structure and seeding over training (as policy changes) for stability and sample efficiency is not studied.
- Reproducibility constraints: Closed-source judges and base models for trajectory generation limit replicability; open-source, audited prompts and judges with documented seeds/variance are needed.
- Rubric generalizability: The process-aware rubric’s portability across tasks, its weighting scheme, and susceptibility to overfitting are not examined via ablations or cross-domain transfers.
- Absolute performance vs. baseline dependency: Win rates are computed against a fixed baseline; absolute quality metrics, calibration against human preferences, and sensitivity to baseline choice are missing.
- Safety and ethics: No discussion of safety, privacy, or domain-specific risks (e.g., travel recommendations with incorrect constraints) under ranking-driven optimization.
- Data quality and leakage: Using closed-source models to produce SFT trajectories risks style leakage; how this affects ArenaRL’s learning signal or judge preferences is not evaluated.
- Learning a judge: Whether a learned, calibrated pairwise judge (trained to mimic tournament outcomes) can reduce cost while maintaining fidelity is an open direction.
Practical Applications
Immediate Applications
The following applications can be deployed with current tooling by adapting ArenaRL’s seeded tournament ranking, process-aware pairwise judging, and the provided Open-Travel/Open-DeepResearch pipelines.
- Tournament-trained itinerary planners in mapping apps
- Sectors: Travel, Mapping, Consumer Software
- Use case: Upgrade trip-planning, routing with multiple constraints (budget, time windows, POI selection), transport-mode comparisons, and multi-day itineraries.
- Tools/products/workflows: Integrate ArenaRL training into existing agent stacks; expose routing/search APIs (e.g., POI lookup, distance/time, ticketing); use seeded single-elimination ranking to train and A/B-evaluate itinerary agents; deploy judge prompts as automated QA.
- Assumptions/dependencies: Reliable tool APIs and geo data; cost budget for pairwise judge calls; localization for language/region; safeguards for hallucinations and unsafe travel suggestions.
- Enterprise deep-research assistants
- Sectors: Knowledge Management, Enterprise Software, Consulting
- Use case: Multi-turn web/intranet research, source triage, outline-to-report drafting, multi-criteria synthesis (coverage, relevance, accuracy, depth, clarity).
- Tools/products/workflows: Fine-tune internal research agents using Open-DeepResearch-style SFT→RL; use process-aware rubrics and dual-judge evaluation in CI for quality gates; provide retrieval and browser/tool APIs.
- Assumptions/dependencies: Secure access to corpora and browsing; context-length management; judge robustness to domain jargon; governance for citing sources and privacy.
- Open-ended writing copilots for marketing and documentation
- Sectors: Media/Marketing, Technical Writing, Education
- Use case: Proposals, product pages, long-form posts, design docs, and course notes that require structure, depth, and clarity beyond single-shot generation.
- Tools/products/workflows: Train with ArenaRL on open-ended writing datasets; embed tournament ranking as a training step; use bidirectional judge scoring to reduce positional bias; add human-in-the-loop checkpoints for final publication.
- Assumptions/dependencies: Domain-specific rubrics (style, brand voice, compliance); content safety and plagiarism checks; judge bias calibration.
- Multi-criteria product and transport comparison advisors
- Sectors: E-commerce, Mobility, Fintech (consumer)
- Use case: Generate ranked recommendations under user-defined trade-offs (price vs. quality vs. constraints) for products or travel modes.
- Tools/products/workflows: Model tool-use for catalog search, spec comparison, and pricing; train comparisons with tournament-based relative ranking against anchor baselines to avoid score compression.
- Assumptions/dependencies: Fresh catalogs/prices; clear constraint schemas; mitigation of length/preference bias in judges.
- Agent QA and A/B testing harness using seeded tournaments
- Sectors: ML Ops, Product QA
- Use case: Replace noisy pointwise “LLM-as-judge” checks with efficient tournament-based relative ranking for agent regression tests and launch gates.
- Tools/products/workflows: Implement seeded single-elimination brackets on candidate trajectories; log per-round judge rationales; standardize rubrics; integrate with CI/CD.
- Assumptions/dependencies: Budget for O(N) pairwise evaluations; stable judge prompts; reproducible decoding settings.
- Cost-efficient RL for open-ended agents
- Sectors: ML Platforms, Model Training
- Use case: Swap O(N2) exhaustive comparisons with O(N) seeded tournaments to scale preference optimization during online RL for long-horizon agents.
- Tools/products/workflows: Plug ArenaRL’s objective into existing RLHF/GRPO/GSPO pipelines; use KL-regularized updates and rank-to-advantage mapping; monitor advantage variance for training stability.
- Assumptions/dependencies: Access to reference models; careful KL tuning; monitoring discriminative collapse in new domains.
- Benchmarking and leaderboards for open-ended tasks
- Sectors: Academia, Industry R&D
- Use case: Evaluate agents end-to-end with tool-use and multi-dimensional rubrics (framework, tool usage, coverage, relevance, accuracy, depth, clarity).
- Tools/products/workflows: Adopt Open-Travel and Open-DeepResearch as standardized testbeds; dual-judge protocols; report valid-generation rates alongside win rates.
- Assumptions/dependencies: Transparent rubric disclosure; judge diversity (model families); prevention of benchmark leakage.
- Customer support and workflow triage agents
- Sectors: Customer Service, ITSM, Operations
- Use case: Plan multi-step resolutions that involve diagnostic questioning, tool invocation, and policy-compliant responses for open-ended tickets.
- Tools/products/workflows: Process-aware judging on chain-of-thought and tool calls; tournament ranking of candidate playbooks; deployment as guided troubleshooting flows.
- Assumptions/dependencies: Tool adapters (ticketing, KB search, device probes); policy/rubric versioning; careful handling of sensitive data.
- Academic research tooling: preference optimization and evaluation
- Sectors: Academia, Open-Source ML
- Use case: Study discriminative collapse and preference mechanisms in open-ended domains; compare tournament topologies; develop better rubrics and debiasing strategies.
- Tools/products/workflows: Extend seeded single-elimination vs. round-robin/swiss in new tasks (e.g., code review, math proofs without ground truth); release reproducible pipelines and judge prompts.
- Assumptions/dependencies: Compute budgets; access to judge models; careful statistical analysis of noise vs. signal.
- Personal planning assistants (daily life)
- Sectors: Consumer Apps
- Use case: Multi-constraint planning (study schedules, home projects, event planning) with preference-aware trade-offs.
- Tools/products/workflows: Local rubrics (budget/time/preference); seed baseline plans and refine via tournament-ranked candidates; collect optional user pairwise feedback to improve models.
- Assumptions/dependencies: Lightweight and private-by-design deployments; explicit disclosure of uncertainty; simple interfaces for users to adjust constraints.
Long-Term Applications
These use cases are feasible but likely require further research, scaling, robust tooling, and/or regulatory clarity before broad deployment.
- High-level task planning for robotics and embodied agents
- Sectors: Robotics, Logistics, Manufacturing
- Use case: Use process-aware pairwise evaluation to train planners that sequence tools/actions under multi-objective constraints for long-horizon tasks.
- Tools/products/workflows: Sim-to-real pipelines; safety-aware rubrics; seeded tournaments over candidate plans rather than scalar rewards.
- Assumptions/dependencies: Reliable low-level controllers; safe tool APIs; simulation fidelity; strong human oversight.
- Clinical care-pathway and benefits navigation assistants
- Sectors: Healthcare
- Use case: Draft care pathways, benefits navigation, and appointment/logistics planning tailored to constraints and preferences.
- Tools/products/workflows: FDA/IRB-compliant evaluation frameworks; medically curated rubrics and judges; human-in-the-loop clinical validation; provenance and citation mandates.
- Assumptions/dependencies: Strict regulatory compliance; clinician oversight; access-controlled data; bias and safety audits; no autonomous diagnosis.
- Investment and market research copilots
- Sectors: Finance
- Use case: Multi-source retrieval and synthesis, scenario analysis, and rationale-backed recommendations with tournament-trained research workflows.
- Tools/products/workflows: Regulated data access; compliance-aware rubrics (conflicts, risk disclosure); counterfactual plan tournaments.
- Assumptions/dependencies: Regulatory approvals; audit trails; delayed ground-truth feedback.
- Personalized education planners and project-based learning coaches
- Sectors: Education, EdTech
- Use case: Design adaptive curricula, project scaffolds, and multi-week study plans optimized for engagement, mastery, and time constraints.
- Tools/products/workflows: Pedagogy-aligned rubrics (mastery, scaffolding, workload); pairwise evaluation of alternative curricula; teacher-in-the-loop.
- Assumptions/dependencies: Student privacy; equitable outcomes; content suitability; integration with LMSs.
- City-scale mobility and energy planning assistants
- Sectors: Transportation, Energy, Public Sector
- Use case: Plan interventions under multi-objective constraints (cost, emissions, equity, reliability) with relative ranking of candidate policies.
- Tools/products/workflows: Scenario simulators; public-data pipelines; multi-stakeholder rubrics; participatory “tournament” deliberation with human voting and AI judges.
- Assumptions/dependencies: High-fidelity models; transparency; governance for AI-assisted policy design.
- Procurement and RFP evaluation support
- Sectors: Government, Enterprise Procurement
- Use case: Structure rubrics and pairwise comparisons to rank complex vendor proposals more robustly than noisy pointwise scores.
- Tools/products/workflows: Auditable judge prompts; bias mitigation (bidirectional ordering, committee-of-judges); human adjudication for ties.
- Assumptions/dependencies: Legal and ethical guardrails; disclosure and appeal mechanisms; domain-specific rubric calibration.
- Multi-agent self-play and marketplace optimization
- Sectors: Platforms, Autonomous Systems
- Use case: Agents iteratively improve via arena-style tournaments across tasks (negotiation, auctions, collaboration) with seeded brackets to reduce computational burden.
- Tools/products/workflows: Matchmaking services, seeding heuristics, Elo-like ratings; safety layers to prevent collusion or exploitative strategies.
- Assumptions/dependencies: Well-defined utility/rubrics; robust monitoring; sandboxing environments.
- Standardized auditing and governance of open-ended agents
- Sectors: Policy, Standards, Compliance
- Use case: Establish tournament-based, rubric-driven audits that test reasoning processes and tool-use reliability across domains.
- Tools/products/workflows: Publicly vetted rubrics; cross-model judge ensembles; reporting on valid-generation rates, robustness to prompt/order changes, and bias analyses.
- Assumptions/dependencies: Interoperable reporting standards; third-party certification; access to evaluation artifacts for reproducibility.
Notes on feasibility across applications:
- Judge quality and bias: Many applications depend on robust, calibrated LLM-as-judge ensembles with bidirectional ordering and multi-level rubrics to control positional and stylistic bias.
- Compute and cost: Although seeded single-elimination reduces complexity to O(N), training and evaluation still incur non-trivial inference costs; batching, caching, and selective evaluation are needed in production.
- Data and tools: Tool-use quality hinges on stable, well-documented APIs and domain data freshness; privacy, provenance, and access control are critical in regulated domains.
- Safety and oversight: Long-horizon, open-ended agents should include human-in-the-loop checkpoints, uncertainty disclosure, and domain-specific guardrails before high-stakes deployment.
Glossary
- Advantage estimation: The process of estimating how much better one trajectory is compared to others for RL updates. "seeded single-elimination scheme achieves nearly equivalent advantage estimation accuracy"
- Advantage signals: Numeric signals that reflect the relative superiority of trajectories used to guide policy updates. "to obtain stable advantage signals."
- Adversarial arena: A structured setting where trajectories compete within a group to derive relative rankings. "construct an intra-group adversarial arena"
- Anchor-Based Ranking: A linear-complexity ranking strategy that compares each trajectory against a fixed reference (“anchor”). "we introduce an Anchor-Based Ranking mechanism."
- Arena Judge: The evaluator that jointly scores two trajectories under process-aware rubrics. "We construct an Arena Judge, denoted as ."
- ArenaRL: The proposed RL paradigm that replaces pointwise rewards with tournament-based relative ranking. "ArenaRL introduces a process-aware pairwise evaluation mechanism"
- Bidirectional scoring protocol: An evaluation method that scores pairs in both orders to reduce positional bias. "we employ a bidirectional scoring protocol."
- Binary tournament tree: A bracket structure where winners advance through binary pairings. "We construct a binary tournament tree"
- Buchholz score: In Swiss tournaments, the sum of opponents’ wins used for tie-breaking. "the Buchholz score (the sum of wins achieved by a trajectory’s past opponents)"
- Chain-of-thought: The intermediate reasoning steps produced by the agent within a trajectory. "the logical coherence of the chain-of-thought"
- Cold-start: An initial supervised fine-tuning phase prior to RL to stabilize exploration. "Cold-start phase."
- Deterministic tasks: Tasks with objective ground truth and verifiable outcomes. "deterministic tasks such as mathematical reasoning and code generation"
- Discriminative collapse: The compression of scores within a high-quality band that obscures fine-grained differences. "a severe phenomenon that we term discriminative collapse"
- Double-Elimination Tournament: A tournament where a trajectory is eliminated only after two losses. "We further investigate the Double-Elimination Tournament topology"
- Epistemic uncertainty: Uncertainty arising from the judge model’s limited knowledge, causing unreliable scoring. "the reward model suffers from high epistemic uncertainty."
- Exhaustive comparisons: Performing all pairwise comparisons to obtain accurate rankings. "While exhaustive comparisons yield accurate rankings"
- Greedy decoding: Deterministic generation (e.g., temperature 0) used to produce a high-quality anchor. "trajectory generated by greedy decoding as a “quality anchor”"
- Intra-group relative ranking: Ranking trajectories within a sampled group against each other rather than absolute scoring. "shifts from pointwise scalar scoring to intra-group relative ranking."
- Intra-group variance: The variability of scores among trajectories within the same group. "the intra-group variance, denoted as $\sigma_{\text{group}$,"
- KL divergence: A measure of distributional difference used to regularize the policy against a reference. "the regularization strength of the KL divergence"
- KL-divergence penalty: A regularization term discouraging excessive deviation from the reference policy. "incorporates a KL-divergence penalty"
- LLM-as-Judge: Using a LLM to evaluate outputs and assign scores or preferences. "LLM-as-Judge paradigm"
- Long-horizon planning: Planning that spans many steps or actions with extended context. "By integrating long-horizon planning and tool use"
- Losers' bracket: In double-elimination, the bracket that allows a trajectory to continue after one loss. "a losers' bracket"
- Multi-level rubrics: Layered evaluation criteria used to assess different aspects of trajectories. "employing multi-level rubrics to assign fine-grained relative scores"
- Open-ended agentic tasks: Tasks lacking objective ground truth, with subjective and multi-dimensional notions of quality. "In open-ended agentic tasks, the ground-truth reward function is intractable"
- Pairwise comparison: Directly comparing two trajectories to determine which is better. "exhaustive pairwise comparison"
- Pairwise preference judgments: Comparative assessments that prefer one candidate over another, often more stable than pointwise scores. "pairwise preference judgments are known to be more stable than pointwise quantitative assessments"
- Policy optimization: The process of improving the agent’s behavior via reinforcement signals. "an online policy optimization framework"
- Pre-ranking: Initial ordering used to seed and structure the tournament. "for pre-ranking"
- Process-aware pairwise evaluation: A comparison method that considers reasoning steps, tool usage, and outcomes. "we introduce a process-aware pairwise evaluation mechanism"
- Quantile-based rewards: Rewards derived by mapping ranks to normalized quantiles to form advantages. "quantile-based rewards:"
- Quality anchor: A high-confidence reference trajectory used to seed or calibrate comparisons. "a “quality anchor”"
- Reference policy: The baseline policy used to constrain updates via KL regularization. "$\pi_{\text{ref}$ is the reference policy"
- Relative ranking: Ordering candidates based on comparative quality rather than absolute scores. "tournament-based relative ranking"
- Round-Robin Tournament: A format where every trajectory is compared against all others. "Round-Robin can theoretically provide unbiased intra-group rankings"
- Seed rankings: Assigned seeds that determine match-ups in a tournament bracket. "assign a seed ranking"
- Seeded Single-Elimination: Single-elimination with seeding derived from an initial anchor-based pre-ranking. "we innovatively propose a seeded single-elimination mechanism."
- Signal-to-noise ratio (SNR): The ratio of meaningful signal to noise in evaluation, affecting optimization reliability. "extremely low signal-to-noise ratio (SNR)"
- Swiss-System Tournament: A non-elimination format with dynamic pairing based on win–loss records. "We also evaluate the Swiss-System Tournament"
- Tool invocations: Calls to external tools made by the agent during its trajectory. "the effectiveness of tool invocations"
- Tournament topology: The structural design of comparisons (e.g., round-robin, single/double elimination, Swiss). "five tournament topologies"
- Trajectory: The full sequence of reasoning, tool calls, observations, and final answer. "a multi-step interaction trajectory "
- Win rate: The proportion of pairwise evaluations where a candidate is preferred over the baseline. "compute the win rate for each evaluation criterion"
Collections
Sign up for free to add this paper to one or more collections.