MemGovern: Enhancing Code Agents through Learning from Governed Human Experiences
Abstract: While autonomous software engineering (SWE) agents are reshaping programming paradigms, they currently suffer from a "closed-world" limitation: they attempt to fix bugs from scratch or solely using local context, ignoring the immense historical human experience available on platforms like GitHub. Accessing this open-world experience is hindered by the unstructured and fragmented nature of real-world issue-tracking data. In this paper, we introduce MemGovern, a framework designed to govern and transform raw GitHub data into actionable experiential memory for agents. MemGovern employs experience governance to convert human experience into agent-friendly experience cards and introduces an agentic experience search strategy that enables logic-driven retrieval of human expertise. By producing 135K governed experience cards, MemGovern achieves a significant performance boost, improving resolution rates on the SWE-bench Verified by 4.65%. As a plug-in approach, MemGovern provides a solution for agent-friendly memory infrastructure.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
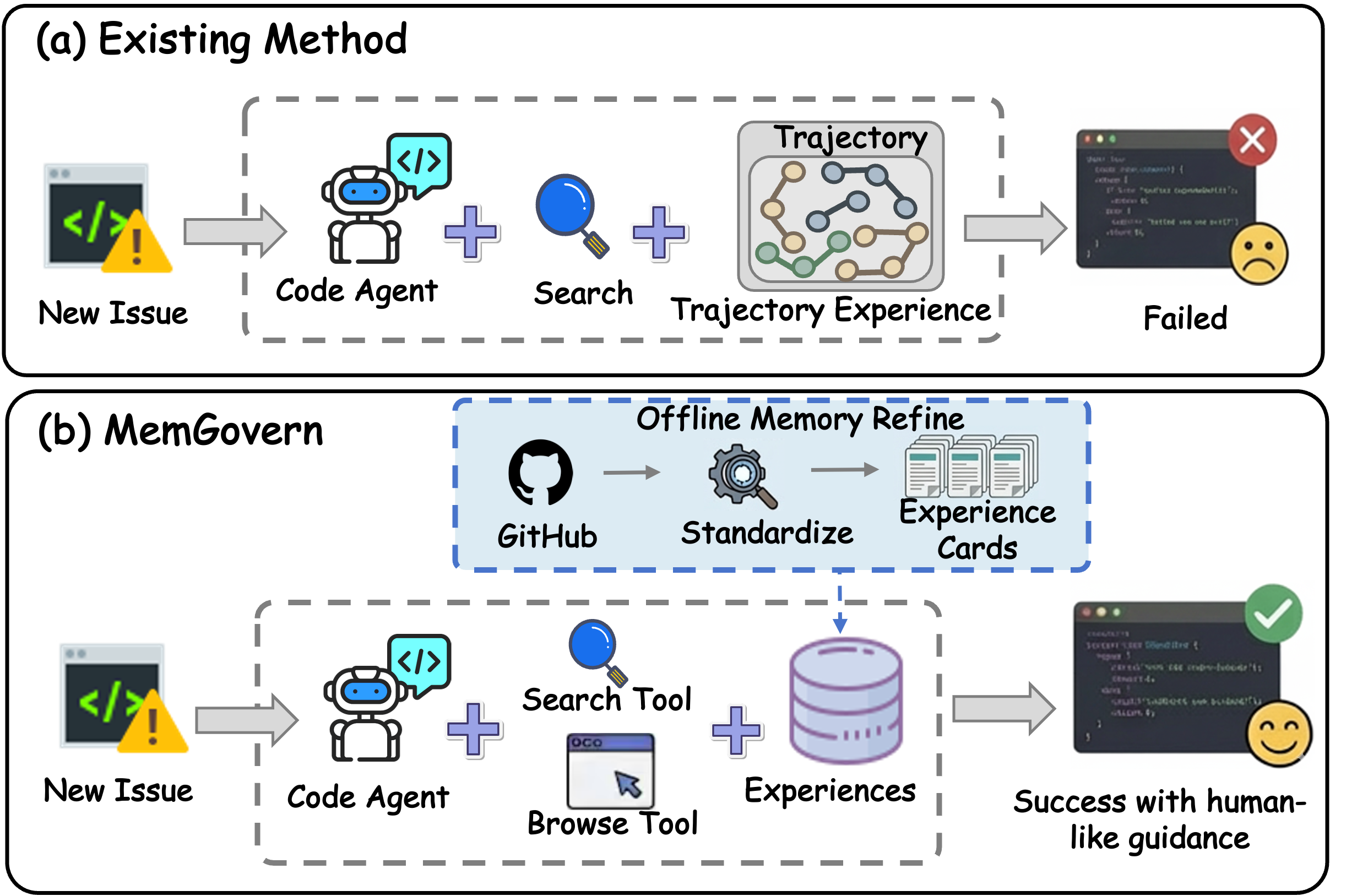
This paper is about helping AI “code agents” fix software bugs better. Today, these agents often try to solve each bug from scratch, even though the internet (especially GitHub) is full of past bug reports, discussions, and fixes from human developers. The problem is that this real-world history is messy and hard for an AI to use. The authors built MemGovern, a system that cleans up those messy records and turns them into simple, reusable “experience cards” that an AI can search and learn from while fixing new bugs.
What questions are the researchers asking?
They focus on a few simple questions:
- Can we turn messy GitHub history into clean, helpful “memories” that a code agent can understand?
- What is the best way for a code agent to search and use those memories while solving a bug?
- Does giving an agent this memory actually help it fix more real bugs?
- How big should this memory be, and how much does quality matter?
How did they do it?
Think of GitHub as a giant library of notes from thousands of past bug fixes. The notes are useful, but they’re scattered, noisy, and full of side conversations. MemGovern acts like librarians and smart search tools combined.
Step 1: Cleaning and organizing human experience
The system gathers bug-related threads from GitHub (issues, pull requests, and the code patches that got merged). Then it:
- Picks reliable sources: It prefers active, well-maintained projects (popular, many issues and pull requests, and steady updates).
- Filters out low-value cases: It keeps only “complete stories” where the issue clearly links to the final code change. It also removes threads that are mostly chit-chat instead of technical clues.
- Turns each case into an “experience card”: Imagine a 2-sided recipe card.
- Front (Index Layer): a short summary of the problem and its clues (like the error message or where it happened). This makes cards easy to find.
- Back (Resolution Layer): the root cause, the strategy that fixed it, and a short summary of what changed. This makes the fix easy to learn and reuse.
- Quality checks: A checklist and feedback loop catch missing pieces or mistakes, and the system refines the card until it’s trustworthy.
By doing this at scale, MemGovern created about 135,000 experience cards.
Step 2: Teaching the code agent to use the memory
When the AI faces a new bug, it doesn’t just grab random cards. It uses a two-part strategy, similar to how you’d use a search engine:
- Searching: The agent types a smart query (including error messages, failing tests, or file names) and gets a short list of likely matching cards based on the card fronts (the Index Layer).
- Browsing: For promising matches, the agent “flips the card” to the back (the Resolution Layer) to see the root cause and the fix strategy in detail.
This process is progressive: the agent can search, refine its query if results aren’t good, browse a few cards, and then apply the useful ideas to the current code. It’s like learning by analogy: “This looks like that other bug where the fix was to add a check,” then mapping that idea to the specific code it’s working on.
What did they find?
The authors tested MemGovern on SWE-bench Verified, a benchmark of real GitHub bugs used to measure how well AIs can fix code.
Key results:
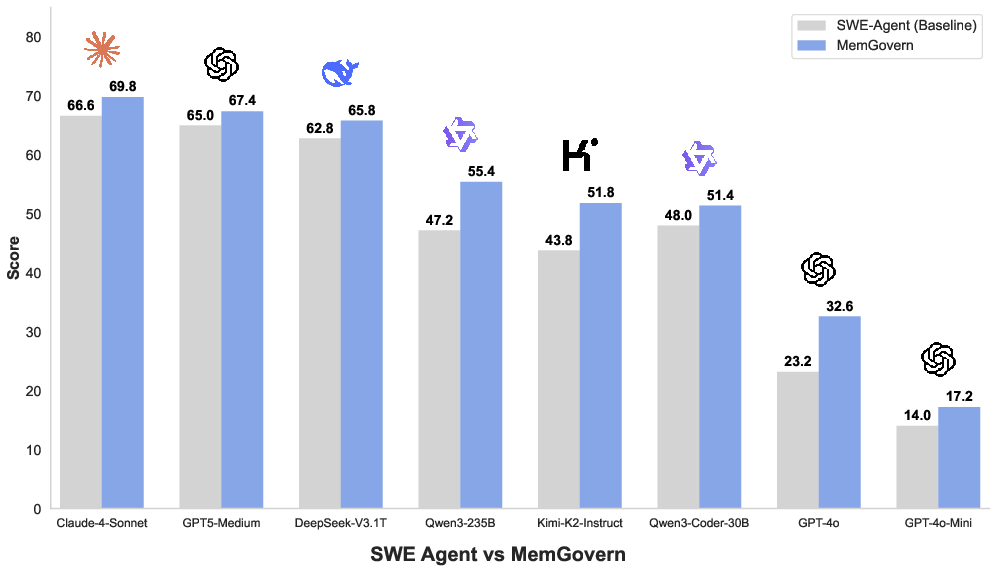
- Better bug fixes: Across many different AI models, MemGovern improved the bug-fix success rate by about 4.65% on average compared to a strong baseline agent (SWE-Agent).
- Works especially well for weaker models: Models that struggled more saw bigger boosts.
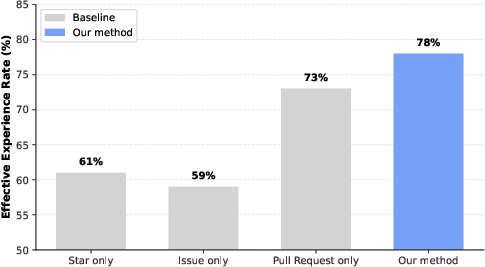
- Quality beats raw data: Using cleaned, standardized experience cards worked much better than dumping raw pull requests and code patches into the agent’s context.
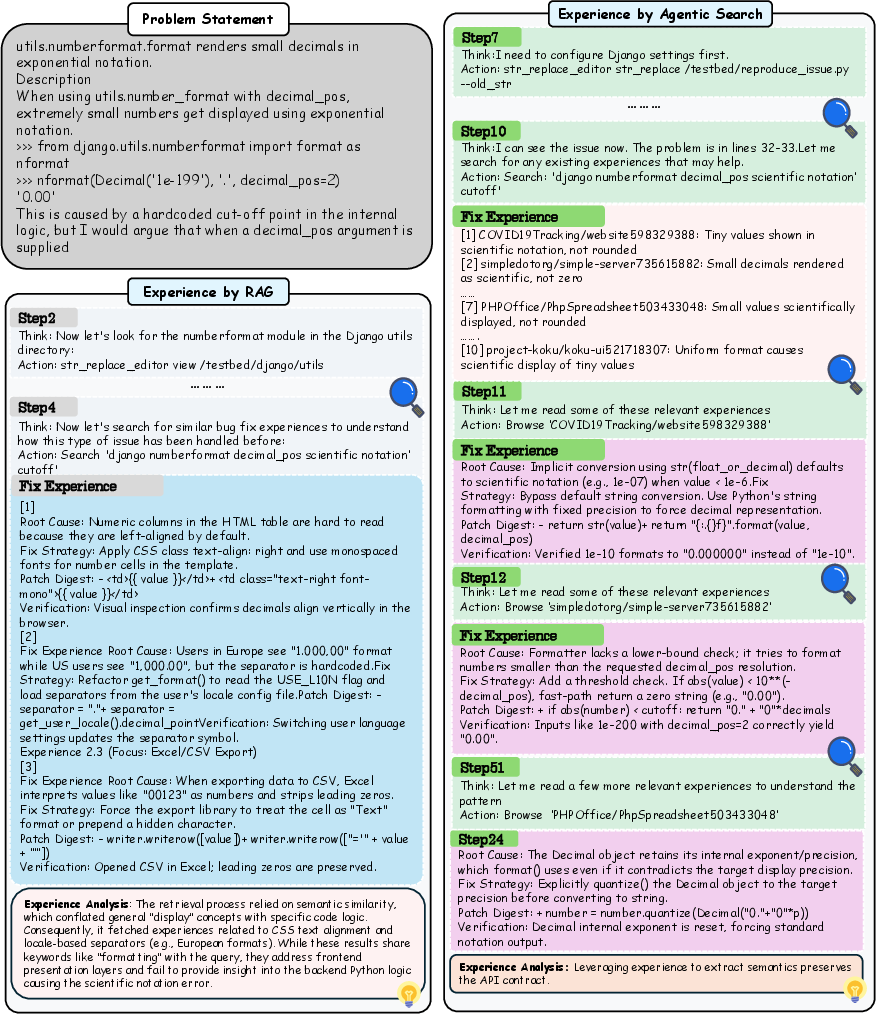
- Smart search beats simple retrieval: MemGovern’s “search, then browse” approach outperformed a basic “retrieve and paste” method (often called RAG), because it avoids flooding the agent with irrelevant info.
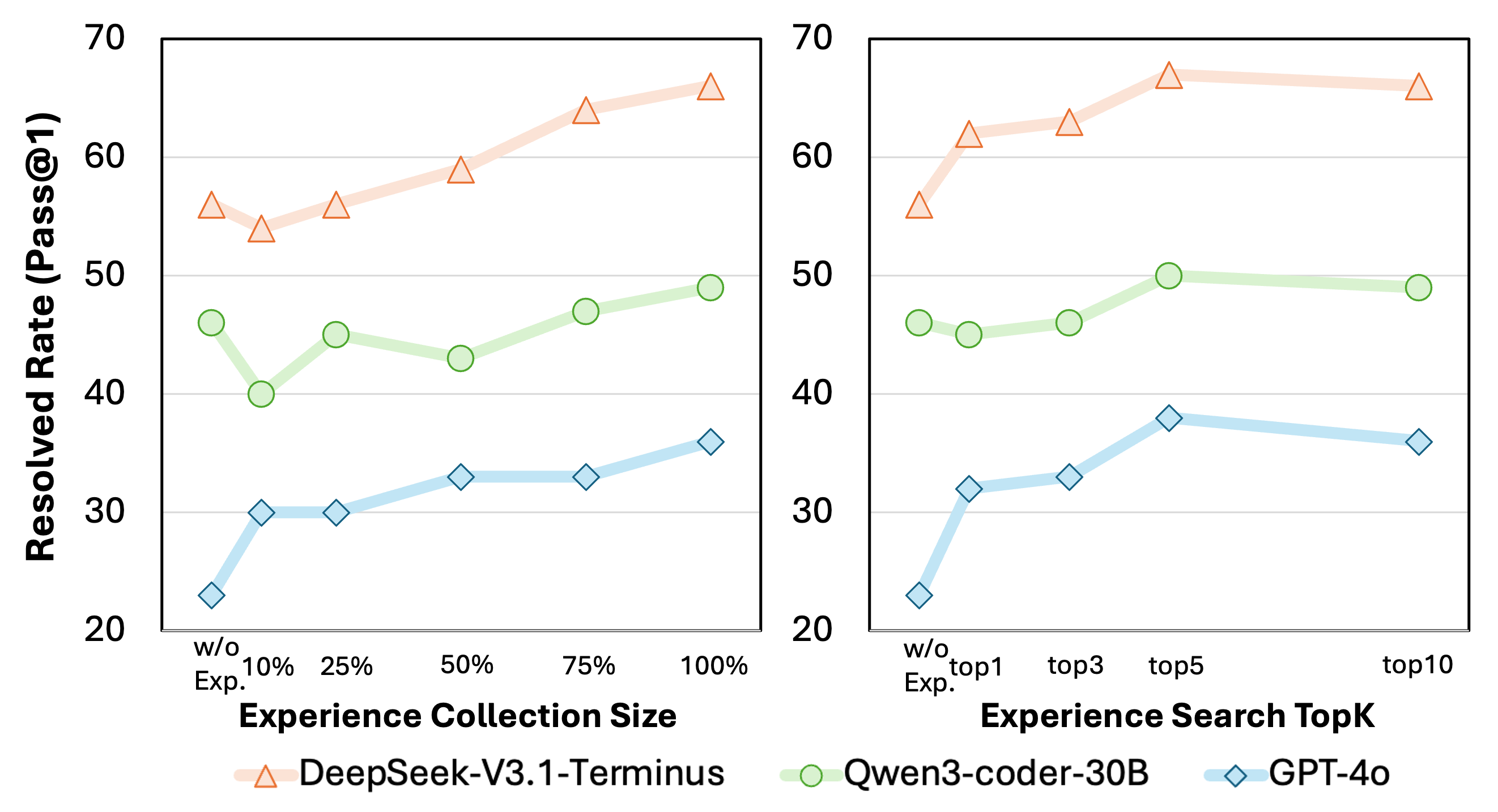
- Bigger memory helps—up to a point: Having more experience cards usually improves results, but after a moderate number of matches per query, extra results don’t help much. The agent’s selective browsing prevents overload.
They also observed behavior changes: with MemGovern, the agent spends less time wandering around the codebase and more time running tests and making targeted edits—closer to how good human developers work.
Why does this matter?
- Learns from real history: MemGovern lets AI agents stand on the shoulders of thousands of past debugging experiences, instead of reinventing the wheel.
- More reliable fixes: The cards emphasize root causes and proper fix strategies, which helps avoid “band-aid” patches that hide the bug instead of truly fixing it.
- Plug-and-play: MemGovern can be added to existing code agents with minimal changes, acting like a memory upgrade.
- Broad potential: The same idea—governing messy human experience into clean, searchable memories—could help AI in other fields that have noisy discussion logs and hard-earned human know-how.
In short, MemGovern shows that organizing and governing human experience can make AI code agents smarter, more efficient, and more trustworthy when fixing real-world software bugs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable directions for future research:
- Unclear data leakage controls: the paper does not audit whether governed experience cards overlap with or directly contain fixes for SWE-bench Verified issues, risking benchmark contamination; a formal leakage audit (e.g., hash-based PR/patch deduplication against benchmark items) is needed.
- Missing governance hyperparameters and settings: key parameters (e.g., repository score weights , , ; QC threshold ; embedding function/model for ; ANN indexing choices) are not specified, hindering reproducibility and ablation.
- Limited transparency of the QC rubric: the checklist-based quality control lacks a published schema, criteria, and quantitative validation (e.g., hallucination rates, inter-annotator agreement, failure categories); releasing the rubric and metrics would enable independent verification.
- No component-level ablations of governance stages: beyond comparing “raw PR+patch” vs. “governed cards,” the paper does not ablate hierarchical selection, standardization, and QC individually to quantify each component’s causal contribution.
- Retrieval quality unmeasured: there is no evaluation of retrieval precision/recall, MRR, or coverage at Top-K; measuring retrieval effectiveness and error modes would clarify where performance gains originate.
- Embedding/model choice sensitivity: the impact of different embedding models (text-only vs. code-aware, multilingual) on retrieval effectiveness is not studied; a systematic comparison is needed.
- Negative transfer analysis absent: the paper does not quantify how often retrieved experiences are misleading (e.g., API version mismatches) and degrade repair quality; a failure-mode taxonomy and mitigation strategies (e.g., trust scores, consistency checks) would be valuable.
- Generalization beyond SWE-agent untested: despite “plug-and-play” claims, MemGovern is only evaluated within SWE-Agent; testing across diverse agent scaffolds (e.g., Agentless, AutoCodeRover) would validate portability.
- Narrow benchmark coverage: evaluation is limited to SWE-bench Verified (primarily Python); performance on other datasets (SWE-bench Classic, RepoBench, Defects4J), other languages (Java/C++), and non-test-driven settings remains unknown.
- Lack of defect-type granularity: improvements are reported only as aggregate resolution rates; breakdowns by bug category (logic, API misuse, null checks, concurrency), patch size/complexity, and multi-file changes are missing.
- Analogical transfer mechanism under-specified: the mapping from abstract “Fix Strategy” to concrete code edits is described but not formalized or evaluated (e.g., accuracy of variable/API mapping, edit location precision); metrics and controlled tests are needed.
- Agentic search policy not characterized: no analysis of when/why the agent decides to search or browse, stop criteria, or optimal number of rounds; learning or optimizing the search policy (e.g., via RL) is an open direction.
- Dynamic Top-K selection unexplored: while Top-K ablation is reported, adaptive or learned Top-K (task-dependent) and its impact on efficiency and effectiveness remain unstudied.
- Efficiency and latency metrics missing: token/cost are reported, but runtime, latency, and throughput overhead of search/browse (including index scale and ANN recall) are not evaluated; end-to-end performance profiling is needed.
- Memory maintenance and staleness: strategies for incremental updates, recency weighting, deprecation of outdated experiences, and version alignment (e.g., framework/API changes) are not addressed.
- Conflict and redundancy handling: the paper does not describe how contradictory or duplicate experiences are detected, clustered, or resolved; semantic deduplication and conflict resolution policies are needed.
- Privacy, licensing, and ethics: governance removes social noise but does not address sensitive content, PII, or license compliance of mined artifacts; an ethical/legal compliance framework is required.
- Reproducibility of the 135K-card corpus: release status, creation prompts, LLM configs, and processing scripts are unclear (the GitHub link appears malformed); publishing artifacts and a detailed pipeline would enable replication.
- Field-level importance within cards: there is no ablation of Index vs. Resolution layers (or subfields like Diagnostic Signals, Root Cause, Fix Strategy) to identify which elements drive improvements.
- Repository selection bias: selecting repos with ≥100 stars biases toward popular ecosystems; effects on niche projects, low-activity repos, and industrial/private codebases remain unknown; alternative signals (commit frequency, issue closure rates) should be compared.
- Multilingual and non-English issues: the ability to standardize and retrieve from non-English discussions, mixed-language repositories, or differing terminology is not assessed.
- Robustness to noisy/ambiguous issue reports: the paper does not quantify how governance handles minimal reproduction info, vague descriptions, or missing stack traces; measuring resilience on “low-signal” issues is needed.
- Post-repair quality beyond tests: improvements are validated by passing tests, but semantic correctness, API contract adherence, maintainability, and long-term robustness are not examined; human review and static analysis could complement testing.
- Governance model dependence: experience extraction and QC rely on proprietary LLMs (e.g., GPT-5.1); feasibility with open-source models, cost scaling, and quality trade-offs are unreported.
- Query formulation quality: how well agents extract diagnostic signals to form effective queries (and the impact of query quality on retrieval outcomes) is not measured; automated query optimization could be explored.
- Real-world user workflows: MemGovern’s utility in interactive developer-in-the-loop settings (e.g., IDE plugins, triage assistance) is untested; user studies could assess practical adoption and UX.
- Memory compression strategies: aside from noting token overhead, the paper does not evaluate compression (e.g., salience-aware summarization, field pruning) and its effects on performance/cost.
- Time-aware retrieval: there is no use of temporal signals (e.g., recency, version tags) to prioritize up-to-date experiences; incorporating time could reduce outdated or incompatible suggestions.
Glossary
- Agent-Computer Interfaces: Specialized interfaces that equip LLMs with tools to interact with code and computing environments. "SWE-agent \cite{Swe-agent} pioneered Agent-Computer Interfaces with specialized tools for LLM-based code navigation"
- Agentic experience search: A logic-driven retrieval process where agents iteratively search and browse curated experiences to guide problem solving. "MemGovern introduces agentic experience search, which enables agents to interact with the experiential memory through multiple rounds of searching and browsing"
- Agentic RAG: An adaptive retrieval-augmented generation strategy where retrieval is triggered during debugging but still injects results directly into context. "Agentic RAG, which allows retrieval to be triggered adaptively during iterative debugging but still follows a retrieve-and-inject paradigm"
- Agentic Search: A strategy that separates broad candidate discovery from selective, in-depth evidence use for applying prior experiences. "Agentic Search, which decouples candidate discovery from evidence usage by first retrieving a broader candidate set and then selectively browsing and transferring only relevant experience cards"
- Analogical transfer: Mapping solutions from prior cases to a new context by identifying structural similarities. "The core challenge here is analogical transfer: the agent must map the historical solution to the current repository's context."
- Checklist-based quality control: A structured evaluation process using criteria and iterative refinement to ensure memory fidelity. "we introduce a checklist-based quality control mechanism that acts as a final gatekeeper before ingestion."
- Closed-loop repair records: Issue–PR–patch triplets that provide a complete, linked chain of evidence from bug report to merged fix. "retain only \"closed-loop\" repair records."
- Content purification: Compressing and cleaning discussion threads to remove non-technical chatter and redundant logs. "MemGovern begins with content purification, where an LLM compresses the original comment stream by removing non-technical interactions (e.g., greetings, merge notifications) and redundant execution logs."
- Cosine similarity: A metric for measuring similarity between embeddings by the cosine of the angle between vectors. "The relevance of an experience card is computed via cosine similarity in the embedding space:"
- De-duplication: Removing repeated or overlapping items to maintain a unique set of experiences. "After de-duplication, the final experience card collection contains 135K items."
- Diagnostic anchors: Grounding artifacts like stack traces that link symptoms to code changes. "a parsable diff, and diagnostic anchors (e.g., stack traces)."
- Diagnostic Signals: Generalizable indicators of failures (exceptions, error signatures, component tags) used for retrieval. "a set of generalizable Diagnostic Signals (e.g., exception types, error signatures, component-level tags)."
- Dual-primitive interface: An interaction model offering Searching and Browsing primitives for efficient experience use. "MemGovern introduces a dual-primitive interface that enables agents to interact with a well-governed experiential memory and complete complex coding tasks through progressively agentic search over stored experiences."
- Embedding function: The function that maps text or queries into vector representations for similarity search. "where is embedding function and represents index layer of card ."
- Embedding space: The vector space in which textual elements are represented for similarity computations. "cosine similarity in the embedding space:"
- Experience card: A standardized, structured memory unit containing index and resolution layers of a past fix. "each standardized experience card is represented as:"
- Experience governance: A systematic pipeline to filter, standardize, and quality-control raw human debugging data. "MemGovern introduces experience governance to automatically clean and standardize cross-repository experience"
- Experience Selection: The stage that filters repositories and instances to prioritize high-signal, complete repair records. "Experience Selection, which filters low-signal noise at both the repository and instance levels"
- Experiential memory: A curated collection of structured past experiences that agents can retrieve and apply. "a unified experience governance framework that transforms raw human experiences into a standardized, agent-friendly experiential memory"
- Fault localization: Techniques to identify the code regions responsible for observed failures. "enhanced fault localization through syntax tree representations and spectrum-based techniques."
- Fix Strategy: An abstract, reusable plan describing how a bug was resolved. "It contains the Root Cause analysis, an abstract Fix Strategy, and a concise Patch Digest."
- Governed experience cards: Experience cards produced after standardized curation and quality checks. "By producing 135K governed experience cards"
- Index Layer: The searchable layer of an experience card containing normalized problem summaries and signals. "Index Layer. This layer captures the information available at an agentâs initial observation stage and serves as the primary retrieval interface."
- Instance Purification: Filtering issue–PR–patch triplets to keep only complete, evidence-linked repairs and remove social noise. "Instance Purification. Within selected repositories, MemGovern rigorously filters triplets to retain only \"closed-loop\" repair records."
- Parsable diff: A machine-readable patch representation of code changes. "a parsable diff, and diagnostic anchors (e.g., stack traces)."
- Patch Digest: A concise summary of the changes made in the patch to fix the bug. "and a concise Patch Digest."
- Plug-and-play module: A component that can be integrated with minimal changes into existing systems. "Specifically, MemGovern is designed as a plug-and-play module that can be seamlessly integrated into existing agent scaffolds with minimal modifications."
- Progressive agentic search: An adaptive, multi-round search process where the agent alternates between searching and browsing based on evolving needs. "we introduce a progressive agentic search mechanism that adapts dynamically to the evolving problem-solving state."
- Pull Request (PR): A contribution workflow on GitHub where proposed changes are reviewed and merged. "raw issue and pull request discussions contain large amounts of many unstructured and fragmented information"
- RAG (Retrieval-Augmented Generation): A paradigm that augments generation with retrieved context, often in single-shot fashion. "Unlike standard Retrieval-Augmented Generation (RAG), which relies on single-shot context injection, real-world debugging is a dynamic process of hypothesis formulation and validation."
- Repository Selection: Scoring and choosing repositories based on popularity and maintenance signals to ensure high-quality sources. "Repository Selection. To ensure the agent learns from active and high-quality software engineering practices, MemGovern filters for repositories exhibiting sustained maintenance."
- Resolution Layer: The layer of an experience card containing root cause, abstract fix strategy, and patch summary for transfer. "Resolution Layer. This layer encapsulates the transferable repair knowledge distilled from human debugging processes."
- Root Cause: The fundamental reason behind a bug, identified to guide correct fixes. "It contains the Root Cause analysis, an abstract Fix Strategy, and a concise Patch Digest."
- Semantic gap: A mismatch between noisy natural-language discussions and the structured signals needed for reliable retrieval. "creating a \"semantic gap\" that hinders direct agentic retrieval."
- Spectrum-based techniques: Fault localization methods that use execution spectra (e.g., coverage) to infer suspicious code. "enhanced fault localization through syntax tree representations and spectrum-based techniques."
- Stack traces: Execution backtraces indicating the sequence of function calls leading to an error. "such as failure symptoms, failing test names, stack traces, and relevant module identifiers"
- SWE-Agent: A software engineering agent framework used as the backbone in this work. "Building on the SWE-Agent framework, we implemented two tools: an Experience Search tool and an Experience Browse tool."
- SWE-bench Verified: A benchmark evaluating whether LLMs can resolve real-world GitHub issues with verified outcomes. "improving resolution rates on the SWE-bench Verified by 4.65\%."
- Syntax tree representations: Structured code representations (ASTs) used to analyze and navigate program structure. "enhanced fault localization through syntax tree representations and spectrum-based techniques."
- Top-K: The parameter controlling how many retrieved candidates are returned by search. "we conduct a ablation study on the retrieval Top- parameter in the agentic search pipeline."
- Unified repair-experience protocol: A standardized schema for reorganizing raw records into reusable, cross-project experience. "reconstructs raw data through a Unified repair-experience protocol"
- Validation Strategy: The plan for confirming a fix works (e.g., tests, checks) after applying the modification logic. "the agent induces a transfer triplet: Root Cause Pattern Modification Logic Validation Strategy."
- Within-repository retrieval: Retrieval limited to experiences from the same repository, as opposed to cross-repository knowledge. "This limitation constitutes a primary bottleneck that confines most approaches to within-repository retrieval"
Practical Applications
Below is an overview of practical applications derived from the paper’s findings and innovations. Each item notes the sector, the nature of the tool/product/workflow, and any assumptions or dependencies that affect feasibility.
Immediate Applications
- Software — IDE plugin for governed experience search and browse: Integrate MemGovern’s dual-primitive “Search” and “Browse” tools into popular IDEs (e.g., VS Code, JetBrains) so developers and code agents can retrieve symptom-matched experience cards and apply resolution-layer logic during bug fixing.
- Assumptions/Dependencies: Availability of the 135k governed cards or similar internal corpora; compatible embeddings; LLM/tool APIs; licensing for GitHub-derived content.
- Software/DevOps — CI/CD “prior art” gate: Add a pipeline step that, before merging, searches experience cards for analogous issues, root causes, and validation strategies to reduce superficial or risky fixes.
- Assumptions/Dependencies: Build-server integration; acceptable latency/cost; policy buy-in to make checks non-blocking or advisory.
- Software — Code review assistant: Use resolution-layer elements (root cause, fix strategy, validation) to flag defensive bypasses and insufficient tests, guiding reviewers toward robust, contract-preserving patches.
- Assumptions/Dependencies: Access to governed cards; mapping from analogical strategy to project context; LLM reliability for mapping.
- Software/SRE — Incident response runbooks on demand: Query governed experience to assemble targeted runbooks (diagnostic signals → root cause patterns → validation strategies) for recurring production incidents.
- Assumptions/Dependencies: Operational logs stack-trace alignment with index-layer signals; secure access and data governance.
- Software — Enterprise memory governance for internal issue trackers: Apply the MemGovern pipeline to Jira/Phabricator/GitLab data to create a private “experience memory” that improves intra-org bug resolution.
- Assumptions/Dependencies: Data cleaning and PII removal; schema alignment; internal embeddings/indexing infrastructure.
- Security — Vulnerability fix pattern retrieval: Surface standardized resolution strategies for known CVEs (boundary checks, input validation, version pinning) and recommended verification methods.
- Assumptions/Dependencies: Curated security-focused cards; correct CVE-to-symptom mapping; secure handling of sensitive references.
- Education — Debugging pedagogy kits: Use index/resolution layers as teaching materials in software engineering courses to illustrate failure diagnostics, root-cause reasoning, and validation planning.
- Assumptions/Dependencies: Access to curated cards; curriculum alignment; examples with permissive licenses.
- Academia — Benchmarking memory systems: Employ MemGovern’s governed corpus to evaluate agentic search vs RAG variants on SWE-bench or custom tasks, enabling reproducible memory governance studies.
- Assumptions/Dependencies: Stable release of the corpus; tooling for ablation; documented governance pipeline.
- OSS maintenance — Issue triage assistant: Help maintainers link new issues to prior fixes across repos, highlight reusable strategies, and suggest validation tests to prevent regressions.
- Assumptions/Dependencies: Cross-repo search quality; maintainer workflows; permissions to surface external fixes.
- Finance/Healthcare/Robotics — Controlled patch guidance for regulated software: Use governed cards to suggest repair logic and verification steps that preserve API contracts and traceability in safety-critical systems.
- Assumptions/Dependencies: Domain-specific curation; audit/compliance requirements; strict change-management practices.
Long-Term Applications
- Software — Continual-learning repair agents: Train or fine-tune code agents on resolution-layer abstractions to develop component-agnostic “fix strategy priors” that generalize across repositories.
- Assumptions/Dependencies: High-quality, diverse governance; safe training pipelines; model update infrastructure.
- Cross-sector — Proactive defect prevention: Build analyzers that scan codebases for known root-cause patterns (e.g., null-boundary, type mismatches, missing checks) and propose preventative changes before failures occur.
- Assumptions/Dependencies: Reliable mapping of abstract patterns to code; static/dynamic analysis integration; low false-positive rates.
- Software — Organization-wide experience networks: Federate multiple governed memories (OSS + internal) with access control and provenance tracking to create an enterprise-scale repair knowledge graph.
- Assumptions/Dependencies: Data sharing agreements; privacy and IP enforcement; scalable indexing and lineage.
- Policy/Standards — Governance schema for technical discourse: Standardize an “experience card” protocol (index vs resolution layers, checklist QC) for issue/PR hygiene across platforms, improving AI-readiness of developer communications.
- Assumptions/Dependencies: Multi-stakeholder consensus; platform adoption; alignment with licenses and contributor norms.
- Compliance/Audit — Traceable AI-assisted changes: Require AI tools to reference governed experience cards in change logs, enabling transparent justification of fixes and easier audit trails in regulated domains.
- Assumptions/Dependencies: Policy mandates; toolchain support; storage for references and versioning.
- Software/SRE — Autonomous runbook generation: Extend agentic search to assemble and maintain runbooks that evolve with new incidents, combining governed cards with telemetry (logs, metrics, traces).
- Assumptions/Dependencies: Multi-modal integration; robust analogical transfer; secure observability access.
- Education — Adaptive debugging tutors: Build intelligent tutoring systems that personalize exercises and hints using diagnostic signals and resolution strategies, simulating progressive agentic search.
- Assumptions/Dependencies: Student modeling; safe LLM behaviors; curated didactic corpora.
- Security — Cross-ecosystem vulnerability response hubs: Create shared, governed repositories of CVE-linked fix strategies with validation playbooks, supporting faster, consistent remediation across vendors.
- Assumptions/Dependencies: Community curation; timely updates; legal frameworks for sharing remediation detail.
- Healthcare/Energy/Finance — Safety-case augmentation: Integrate governed experience as evidence nodes in safety cases, linking failure modes to proven repair logic and validation, strengthening risk arguments.
- Assumptions/Dependencies: Domain certification processes; formal assurance frameworks; expert oversight.
- Platforms/Marketplaces — Experience-card ecosystems: Enable publishers to contribute governed cards; consumers (teams, tools) subscribe to domains (Django, Kubernetes, CUDA) with quality tiers and provenance scoring.
- Assumptions/Dependencies: Incentives and moderation; IP/licensing; reputation systems and QC tooling.
- Research — Neuro-symbolic memory models: Use MemGovern’s structured index/resolution split to explore hybrid retrieval–reasoning systems that separate symptom matching from causal logic application.
- Assumptions/Dependencies: New model architectures; benchmark extensions; reproducible pipelines.
- Robotics/Embedded — Hardware-aware repair strategies: Expand cards with platform constraints (timing, resource limits, firmware APIs) to guide safe patches on constrained devices and real-time systems.
- Assumptions/Dependencies: Domain-specific governance; hardware-in-the-loop validation; OEM partnerships.
Collections
Sign up for free to add this paper to one or more collections.