Applying Embedding-Based Retrieval to Airbnb Search
Abstract: The goal of Airbnb search is to match guests with the ideal accommodation that fits their travel needs. This is a challenging problem, as popular search locations can have around a hundred thousand available homes, and guests themselves have a wide variety of preferences. Furthermore, the launch of new product features, such as \textit{flexible date search,} significantly increased the number of eligible homes per search query. As such, there is a need for a sophisticated retrieval system which can provide high-quality candidates with low latency in a way that integrates with the overall ranking stack. This paper details our journey to build an efficient and high-quality retrieval system for Airbnb search. We describe the key unique challenges we encountered when implementing an Embedding-Based Retrieval (EBR) system for a two sided marketplace like Airbnb -- such as the dynamic nature of the inventory, a lengthy user funnel with multiple stages, and a variety of product surfaces. We cover unique insights when modeling the retrieval problem, how to build robust evaluation systems, and design choices for online serving. The EBR system was launched to production and powers several use-cases such as regular search, flexible date and promotional emails for marketing campaigns. The system demonstrated statistically-significant improvements in key metrics, such as booking conversion, via A/B testing.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Airbnb needs to quickly show each guest a short list of great homes from a huge pool of options. That got much harder when new features (like flexible dates) made many more homes “eligible” for each search. This paper explains how Airbnb built a faster “retrieval” system using embeddings (think: smart numerical fingerprints) to find the best candidates quickly, so the heavier ranking models can focus on a smaller set. The new system made search faster and more accurate, and it also helped with features like flexible date search and marketing emails.
What questions the researchers wanted to answer
- How can we quickly pick high‑quality homes from tens of thousands of choices for each search?
- How do we train the system to understand a person’s whole trip‑planning journey (which can take days or weeks), not just one search?
- How can we evaluate new ideas offline (without slowing the live site), even though listings and their availability change constantly?
- Which fast search technology should we use to balance speed, accuracy, filters (like map area), and real‑time updates?
How they approached the problem (methods, with plain‑language explanations)
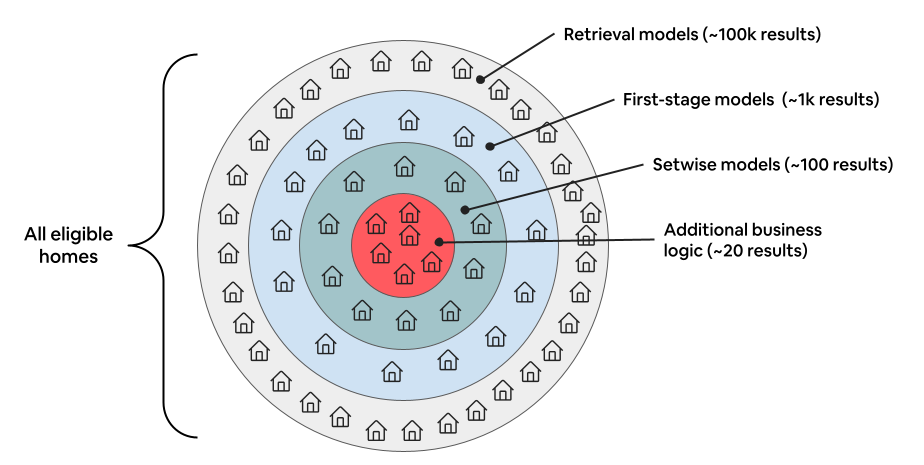
The team redesigned the “first step” of search—called retrieval—so it quickly fetches the most promising homes.
- Embeddings: Imagine turning every home and every search into a short list of numbers (a “fingerprint”). If a search and a home have fingerprints that are close together, that home is likely a good match. This is called Embedding‑Based Retrieval (EBR).
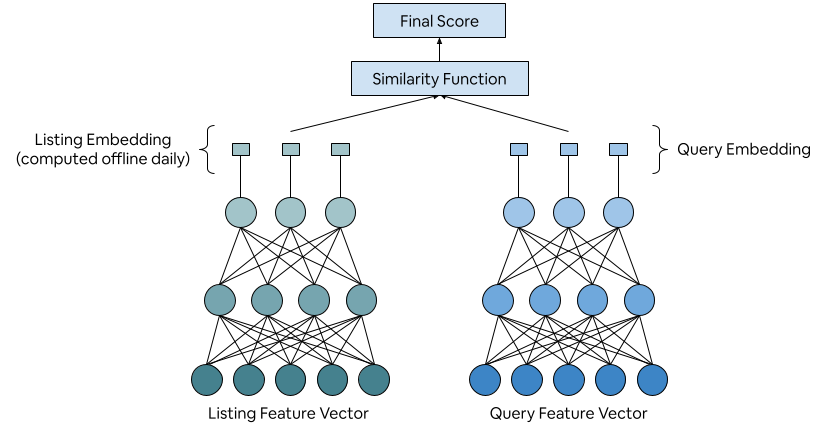
- Two‑tower model: Think of two small neural networks (little brains). One learns to make fingerprints for searches (the “query tower”). The other learns to make fingerprints for homes (the “listing tower”). During search, the system compares the two fingerprints using a simple similarity score (e.g., how close they are).
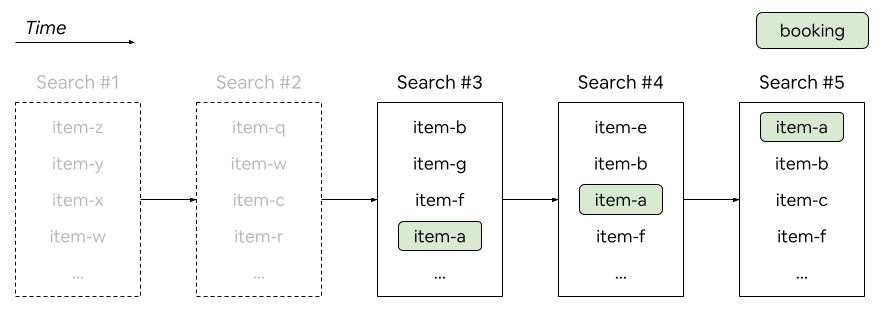
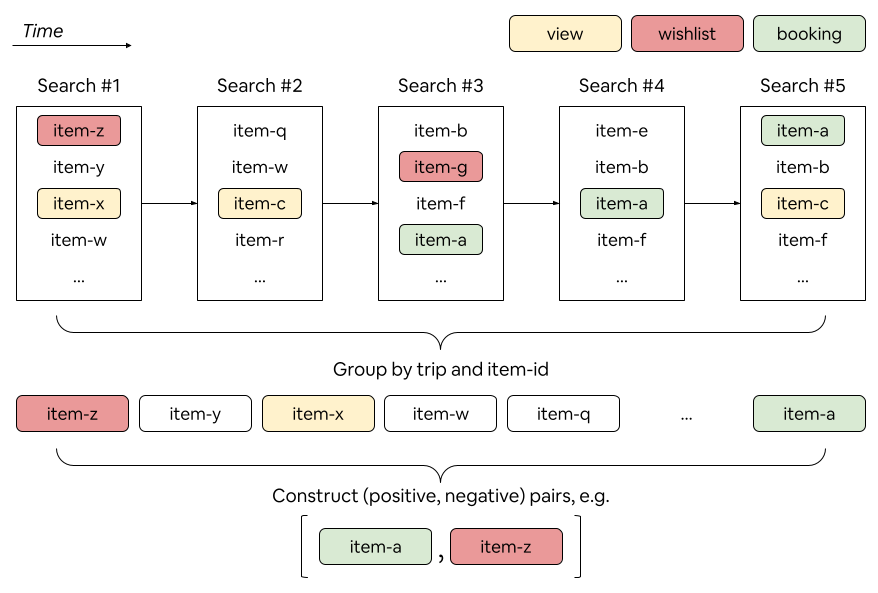
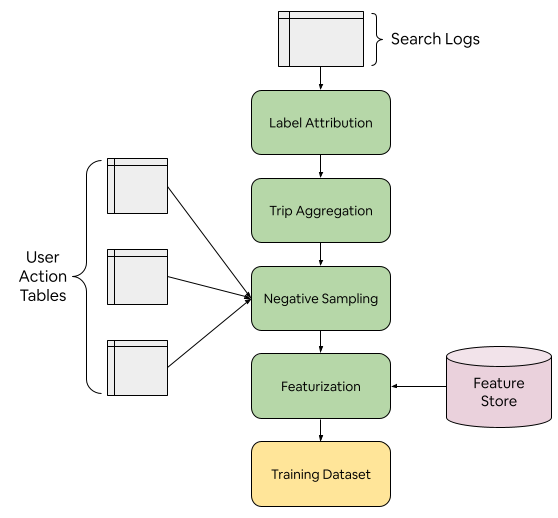
- Smart training data: People don’t book after one search. They explore, click, save to wishlists, and then book later. Earlier training methods only used searches where the booked home actually appeared, which favored the end of the journey. The new “trip‑based” method groups all the user’s related searches for a trip, includes earlier searches, and builds tougher comparisons:
- Positives: the home they eventually booked.
- Negatives: homes they saw, clicked, or wishlisted but didn’t book. Including these “hard negatives” teaches the model what “almost right” looks like, so it learns more.
- Evaluating models offline (without hurting the live site):
- Log sampling: They added small random samples of “unshown” homes to the logs to simulate a bigger choice set.
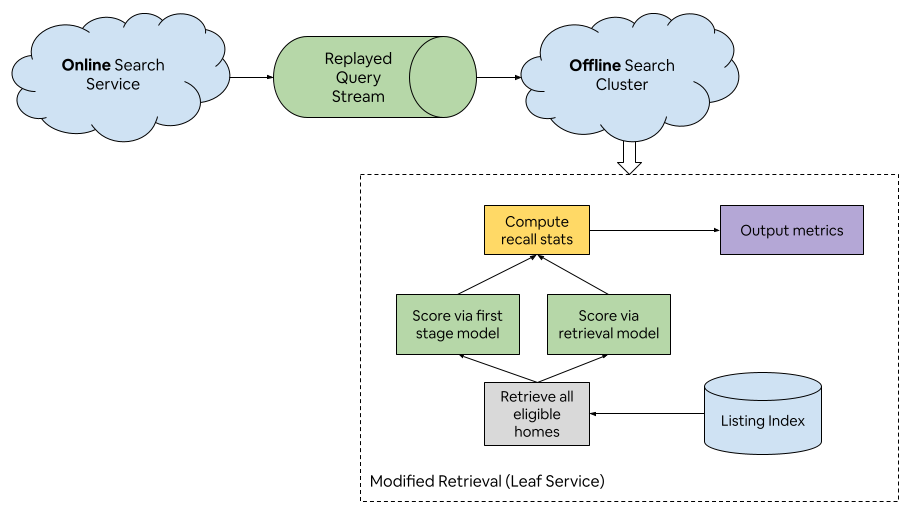
- Traffic replay: They copied a tiny slice of real searches to a separate offline cluster and scored all eligible homes with both the fast retrieval model and the slow, accurate ranking model. Then they checked “recall” (how many of the good homes the retrieval step successfully surfaced). This predicted real A/B test results well.
- Making it fast in production:
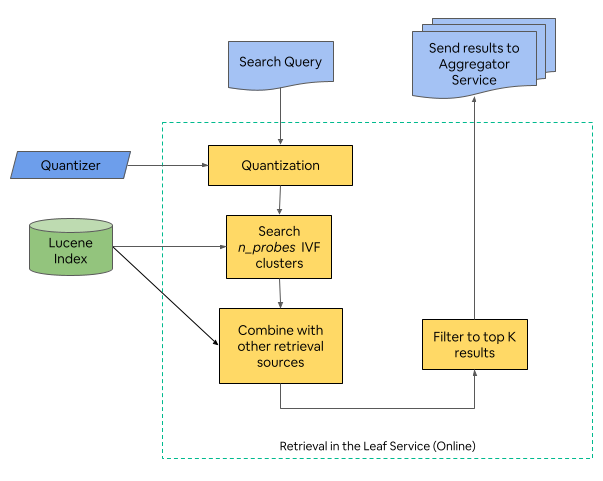
- ANN (Approximate Nearest Neighbor) search: A family of methods that quickly find the closest fingerprints without checking every single home.
- IVFs vs. HNSW: The team tried two popular ANN approaches.
- HNSW struggled with Airbnb’s needs: lots of real‑time updates (prices and availability change constantly) and heavy use of filters (like map regions).
- IVF (Inverted File Index) fit better with their system, used less memory, and played nicely with filters.
- Clustering and “nprobes”: They cluster home fingerprints daily (with k‑means). At search time, they only look inside a few nearby clusters (“nprobes”). More probes = better accuracy but slower. They tuned this to balance speed and quality.
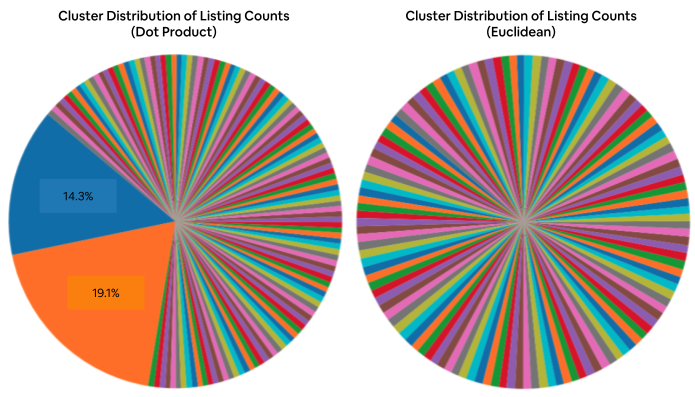
- Similarity choice matters: Using Euclidean distance (measuring straight‑line closeness between fingerprints) made clusters more balanced than dot product, so they could search fewer clusters and still get good results.
- Extra features supported:
- Flexible Date Search: Instead of issuing lots of separate date queries, they built a compact, updatable data structure of availability and price so the retrieval step stays fast.
- Promotional emails: Other teams can ask the retrieval system for “similar homes near X, in this price range, over a wide date window,” improving email recommendations.
What they found and why it matters
Here are the main results:
- Better retrieval quality:
- Moving from the old system to EBR greatly improved “recall” (finding more of the homes the heavy ranking model or the guest would consider good).
- Their strongest version (V3: bigger model, pairwise training, Euclidean distance) had the best recall in both offline tests and replayed traffic.
- Real impact in A/B tests:
- Together, the EBR launches increased booking conversion by about +0.31%.
- Using IVF reduced compute costs by ~16% versus the old system.
- The system increased bookings of new listings (good for fairness and freshness) and increased bookings from wishlisted homes (suggesting it surfaces useful options earlier in a user’s journey).
- Promotional emails saw +2.3% bookings.
Why this matters:
- Guests get better matches faster, especially in crowded places or with flexible dates.
- Hosts with newer listings get a fairer shot at being seen.
- Airbnb runs more efficiently (lower compute costs) and can power more features.
What this could mean going forward (implications)
- Smarter, earlier suggestions: Because the model understands the full trip journey (not just the last search), guests can discover good choices sooner.
- Broader platform use: The same retrieval layer can power search, flexible dates, and marketing—one solid foundation for many features.
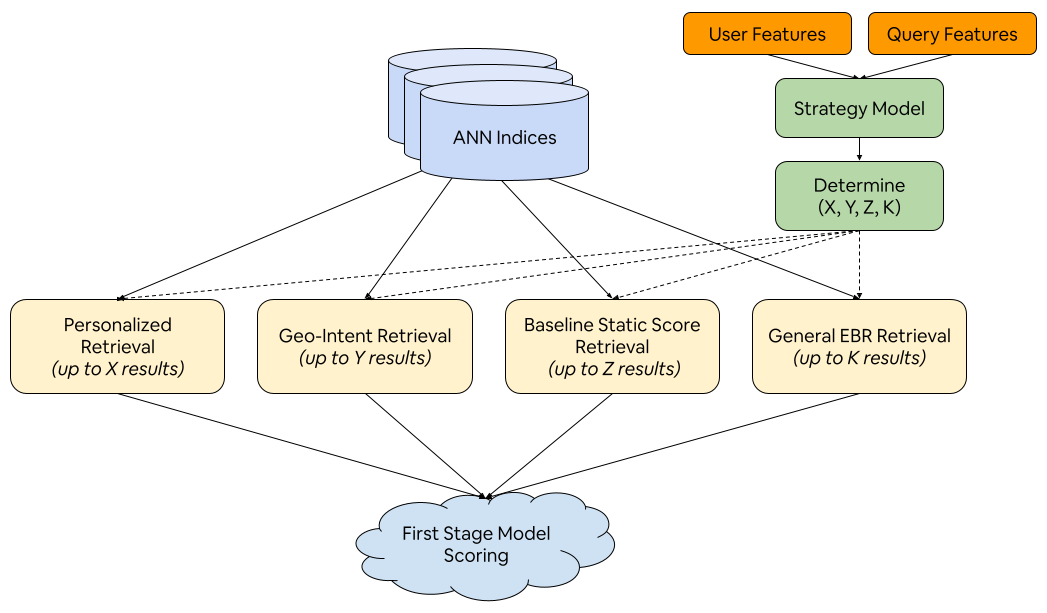
- Room to grow: The team plans new retrieval models (like using your past interactions, or understanding broad geo-intent) and a strategy layer that dynamically decides how many results to pull from each model. That could make search even faster, fairer, and more personalized.
Key idea to remember
By teaching a fast “finder” to use smart fingerprints and realistic training data that mirrors how people actually plan trips, Airbnb can quickly grab a high‑quality set of homes for deeper ranking—making search both faster and better for everyone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future research.
- Freshness of listing embeddings: Quantify the impact of daily offline embedding computation (stale price/availability) on retrieval quality, and evaluate streaming or incremental update strategies for listing embeddings with real-time features.
- Reliance on first-stage model as offline “ground truth”: Assess bias introduced by treating the first-stage model as the proxy for positives in replay evaluation; develop offline metrics that better correlate with booking conversion, user satisfaction, and marketplace health.
- Negative sampling bias and label noise: Measure false-negative rates when sampling from impressed/viewed/wishlisted pools, and design de-biasing or causal labeling (e.g., inverse propensity weighting, counterfactual inference) to reduce exposure and intent confounds.
- Static nprobes tuning: Explore adaptive, per-query nprobes selection that responds to filter selectivity, eligible set size, and query difficulty to balance recall and latency/SLOs.
- ANN choice and hybrid designs: Investigate whether filter-aware HNSW, IVF+HNSW hybrids, PQ-enhanced IVF, or GPU-based ANN can recover recall while meeting memory, update throughput (~10k/s), and filter constraints.
- Embedding geometry alignment: Provide formal/empirical analysis of Euclidean vs dot-product performance with IVF; test L2-normalization, cosine similarity, whitening, or training-time regularization to produce balanced clusters without sacrificing retrieval quality.
- Trip-based grouping sufficiency: Evaluate whether grouping by location/guests/length-of-stay misses key context (dates, seasonality, price bands, device/surface), and quantify effects on early-journey retrieval generalization.
- Limited query features: Systematically study the trade-offs of richer query signals (user/session history, personalization, natural-language intent) versus inference cost; prototype lightweight personalization in the query tower.
- Model class exploration: Compare two-tower to late-interaction (e.g., ColBERT), cross-encoders for reranking within retrieval budgets, and multi-modal embeddings (photos, text, reviews) to capture semantic relevance beyond tabular features.
- End-to-end optimization: Test joint or cascaded training where retrieval embeddings are optimized with downstream ranking objectives (conversion/diversity) or via differentiable retrieval, and measure end-to-end gains.
- Offline logging approximations: Develop scalable approximations (reservoir sampling, sketching) to better represent full eligible sets offline and reduce discrepancies between logs and true retrieval distributions.
- Real-time update robustness: Quantify indexing delay tolerance, consistency guarantees, and rollback strategies under high QPS updates; compare daily k-means reclustering to incremental/online clustering for IVF stability.
- Filter-aware retrieval behavior: Characterize recall degradation under highly discriminative multi-filter conjunctions; design ANN search that is intrinsically filter-aware (e.g., constrained ANN, multi-index fusion).
- Cold-start evaluation: Provide dedicated metrics and benchmarks for new listings; test feature augmentation or meta-learning approaches that ensure exposure equity without engagement history.
- Fairness and marketplace impacts: Measure and mitigate disparities across regions, price segments, property types, and host cohorts; define and optimize multi-objective retrieval that balances guest utility with supply fairness.
- Diversity at retrieval: Determine whether retrieval over-concentrates near-duplicates; introduce diversity-aware objectives (e.g., MMR-style constraints) at retrieval to reduce downstream burden on setwise reranking.
- Latency and tail performance: Report P50/P95/P99 retrieval latencies per shard and under peak QPS, and design SLO-aware throttling, batching, and caching strategies to control tail behavior.
- Caching strategies: Investigate caching/reuse of query embeddings and candidate sets for repeated queries, map pans, and session continuity; quantify compute savings and staleness trade-offs.
- Flexible Date Search precompute: Optimize lookahead horizon, storage/update cadence, and accuracy; extend retrieval-time availability checks to split stays and joint constraints across date combinations.
- Adversarial robustness: Evaluate susceptibility to host feature manipulation (gaming) and design adversarial defenses, anomaly detection, and integrity checks in embedding generation and retrieval.
- Internationalization and query understanding: Integrate multilingual/natural-language query embeddings, synonym/translation handling, and place disambiguation beyond placeId for text-heavy or ambiguous queries.
- Cross-surface generalization: Measure retrieval quality and conversion impacts across web/mobile, map vs list views, and marketing surfaces; develop surface-specific retrieval strategies and knobs.
- Ablation transparency in V3: Disentangle the contributions of added features, network size (+20%), pairwise loss, and Euclidean metric via controlled ablations to guide future model design.
- Metric alignment and causality: Build causal evaluation frameworks linking retrieval changes to bookings, retention, and long-term user value; verify that recall@K gains consistently translate to business outcomes.
- Operational resilience: Document and automate monitoring for cluster imbalance, embedding drift, pipeline failures, and index inconsistencies; implement rollback/playbook and alerting for serving stability.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now based on the paper’s methods, findings, and systems, along with sectors, likely tools/workflows, and key assumptions/dependencies for feasibility.
- Two-tower EBR candidate retrieval for large-catalog search
- Sectors: travel/hospitality, e-commerce/marketplaces, real estate, job boards, classifieds, media/content
- Tools/workflows: two-tower model training with trip-based negative sampling; FAISS IVF integrated with Apache Lucene filters; daily offline embedding generation and k-means clustering; recall@K proxy evaluation against a first-stage model
- Assumptions/dependencies: multi-stage user logs with action signals (impressions, clicks, wishlists/saves); feature store and daily batch pipelines; online inference infra; privacy-compliant logging; sharded scatter–gather serving
- Trip-based training data construction with action-weighted hard negatives
- Sectors: recommender systems across software, retail, media, and job matching
- Tools/workflows: session/trip attribution pipeline; negative sampler that upsamples engaged items (clicked/saved) versus non-engaged impressions; contrastive/pairwise loss training
- Assumptions/dependencies: reliable user-journey reconstruction across weeks; action taxonomy and logging quality; de-identified, privacy-compliant data governance
- Offline “traffic replay” evaluation to predict A/B performance
- Sectors: search and recommendation platforms; ad tech; fintech offers; content feeds
- Tools/workflows: fork a slice of production traffic to an offline cluster; re-score full eligible sets with first-stage model as ground truth; compute retrieval recall@K; establish correlation to online wins
- Assumptions/dependencies: offline compute pool; deterministic feature materialization; robust replay fidelity; metrics governance; limited exposure to PII
- IVF-based ANN retrieval with Euclidean distance and nprobes tuning
- Sectors: search infra vendors, cloud information retrieval, large marketplaces
- Tools/workflows: FAISS IVF indices; Euclidean similarity to produce balanced clusters; offline nprobes sweep to balance latency/recall; Lucene filter integration; monitoring for cluster size imbalance
- Assumptions/dependencies: compatibility with existing filter stack; stable daily clustering jobs; index size/memory budgets; alerting/telemetry on index quality
- Real-time filter integration at retrieval time (geo and attribute filters)
- Sectors: travel/hospitality, real estate, retail product search
- Tools/workflows: IVF cluster IDs stored in the main search index; Lucene/Elasticsearch-style filters for geography, price, amenities; parallel retrieval + filtering
- Assumptions/dependencies: high-QPS index updates; fast filter execution; consistent embedding-to-listing join keys
- Flexible date retrieval with precomputed availability/price cache
- Sectors: travel/hospitality; healthcare appointment booking (analogue); event ticketing
- Tools/workflows: compact date-window availability/price data structure with near-real-time updates; retrieval-aware prefiltering on availability; final post-filter refresh for accuracy
- Assumptions/dependencies: predictable lookahead window; fast incremental updates; cache coherence; edge cases for last-minute changes
- Batch and triggered marketing retrieval (promotional emails and alerts)
- Sectors: marketing tech across travel, commerce, fintech
- Tools/workflows: batch retrieval API that combines EBR similarity and filters (e.g., “similar to X and within 10 miles”); campaign orchestration; lift measurement
- Assumptions/dependencies: user consent and compliance for marketing; stable batch compute; deduplication, frequency capping, and relevance thresholds
- Cold-start-friendly retrieval with engagement-independent features
- Sectors: any marketplace onboarding new inventory (e.g., new sellers/providers)
- Tools/workflows: robust listing tower using amenities, location embeddings (e.g., S2Cells), capacity/attributes; dampened reliance on past engagement; offline daily embedding refresh
- Assumptions/dependencies: quality metadata coverage; geospatial encoding; schema governance to avoid sparsity
- Compute cost reduction via retrieval-stage pruning
- Sectors: cloud-native search platforms; cost-sensitive infra teams
- Tools/workflows: EBR retrieval to shrink candidate set K before heavyweight ranking; IVF to reduce inference and I/O; per-segment nprobes tuning
- Assumptions/dependencies: end-to-end profiling; service-level error budgets; stable K/N/T limits coordination across stack
- Monitoring and diagnostics for ANN indices and retrieval quality
- Sectors: platform/SRE teams running search at scale
- Tools/workflows: dashboards for cluster size distribution, recall vs. true KNN, latency vs. nprobes, index growth vs. update QPS; alarms for skew/imbalance
- Assumptions/dependencies: observability stack (metrics, logs, traces); synthetic probes; retained historical baselines
- Practitioner education and curriculum modules in IR and RecSys
- Sectors: academia, professional training
- Tools/workflows: lab assignments on two-tower EBR, traffic replay, IVF/HNSW tradeoffs, trip-based negatives; student-friendly datasets simulating multi-stage journeys
- Assumptions/dependencies: sharable synthetic datasets; institutional review for data ethics; compute credits or local alternatives
- Fairness/exposure reporting for new items
- Sectors: marketplaces, policy/compliance within platforms
- Tools/workflows: reporting that tracks exposure/clicks/bookings for new inventory pre/post EBR; guardrails to prevent popularity bias; audit-ready dashboards
- Assumptions/dependencies: standardized definitions (“new” listings/providers); variance-aware measurement; cross-team alignment on fairness KPIs
Long-Term Applications
These use cases likely require additional research, scaling, or system changes before broad deployment.
- Strategy layer to allocate retrieval budgets across multiple sources
- Sectors: large-scale rankers across commerce, travel, media
- Tools/workflows: meta-model that dynamically assigns K per retrieval source (e.g., geo-intent, history-aware, diversity sources) based on query/user context; online learning from downstream metrics
- Assumptions/dependencies: multi-source retrieval infrastructure; low-latency arbitration; online bandit/ML governance
- Retrieval with user’s past context and sequence modeling
- Sectors: personalization across marketplaces, media, fintech offers
- Tools/workflows: history-aware query tower that encodes recent interactions (views/saves); session-aware embeddings; contrastive training with temporal negatives
- Assumptions/dependencies: privacy-safe user histories; recency decay design; on-policy/off-policy evaluation methods
- Geo-intent retrieval for broad-area queries
- Sectors: travel planning, real estate search, local commerce
- Tools/workflows: sub-area (city/region) intent prediction; multi-granularity geo embeddings; hierarchical retrieval over regions then listings
- Assumptions/dependencies: high-quality geo taxonomies; map interaction signals; feedback loops for region-level recall/precision
- Incorporating real-time listing features directly into the listing tower
- Sectors: any domain with rapidly changing inventory attributes (price, availability)
- Tools/workflows: nearline feature store + streaming transformations; partial embedding refresh or hybrid towers (static + delta features); fast index updates
- Assumptions/dependencies: feature freshness SLAs; versioning and drift control; cost of frequent re-embeddings
- Hybrid ANN designs for high-update, high-filter workloads
- Sectors: search infra providers and in-house platform teams
- Tools/workflows: IVF+PQ/HNSW hybrids, filter-aware ANN; shard-local caching of hot clusters; adaptive index maintenance
- Assumptions/dependencies: rigorous benchmarks on update QPS; complexity of ops; fallback mechanisms under skew
- End-to-end optimization across retrieval, first-stage, and reranker
- Sectors: advanced ranking stacks in large platforms
- Tools/workflows: joint training/objectives across stages; distillation from reranker to retrieval; counterfactual evaluation and constraints (latency, diversity, fairness)
- Assumptions/dependencies: common feature/label schema; stable training pipelines; careful online rollout to manage risk
- Dynamic nprobes and cost-aware serving
- Sectors: cost/perf-optimized search platforms
- Tools/workflows: per-query adaptive nprobes control using predicted headroom/latency/recall; multi-armed bandit for cost–quality tradeoffs; SLO-aware controllers
- Assumptions/dependencies: real-time latency predictors; guardrails for tail latency; robust telemetry
- Privacy-preserving training and evaluation for multi-stage journeys
- Sectors: healthcare scheduling, finance, HR tech (sensitive logs)
- Tools/workflows: differential privacy for action logs; secure enclaves and federated learning for user-journey features; PII-minimized replay frameworks
- Assumptions/dependencies: legal/compliance alignment; performance tradeoffs under privacy noise; consent management
- Cross-domain adoption patterns (healthcare, education, public sector)
- Healthcare: provider/appointment matching with flexible date windows (analogue to precomputed availability)
- Education: course/program matching with session-aware retrieval and schedule flexibility
- Public sector/policy portals: citizen–service matching across regions with filter-heavy queries
- Tools/workflows: domain-specific listing metadata schemas; availability caches; compliance-grade logging and auditability
- Assumptions/dependencies: domain ontologies; regulated data handling; stakeholder governance
- Market and policy frameworks for equitable exposure
- Sectors: marketplace governance, regulators, standards bodies
- Tools/workflows: standardized exposure/quality metrics; audit protocols for retrieval-stage bias; disclosure guidelines for algorithmic changes that affect supply-side outcomes
- Assumptions/dependencies: access to platform telemetry; cross-industry consensus on fairness definitions; impact assessments
- “EBR-as-a-Service” platform offerings
- Sectors: cloud providers, ML platform vendors
- Tools/workflows: managed two-tower training, trip-based negative mining templates, traffic replay SDKs, IVF/Lucene integration, monitoring packs, recall@K against client-provided rankers
- Assumptions/dependencies: clean APIs to client indices and filters; secure data exchange; SLOs for updates and latency
- Sustainability-driven search optimization
- Sectors: platform sustainability initiatives, green computing
- Tools/workflows: compute-aware retrieval pruning; carbon budget telemetry for indexing and serving; cost–carbon co-optimization of nprobes/K/N/T
- Assumptions/dependencies: carbon accounting at service level; organizational buy-in; accurate perf–carbon models
- Standardized educational benchmarks for multi-stage IR
- Sectors: academia, research consortia
- Tools/workflows: public, synthetic datasets emulating multi-week journeys with action labels; evaluation kits for replay-style metrics (recall vs. stage-1 ground truth)
- Assumptions/dependencies: dataset curation and maintenance; community adoption; licensing and ethics review
Notes:
- Many long-term items become immediate in organizations that already have offline replay clusters, privacy-safe logging, and mature feature stores.
- Feasibility hinges on data quality (multi-stage journeys), infra maturity (batch + nearline), and governance (privacy, marketing consent, fairness KPIs).
Glossary
- A/B testing: Controlled online experiments comparing alternative systems or features. "The system demonstrated statistically-significant improvements in key metrics, such as booking conversion, via A/B testing."
- Apache Lucene: An open-source search library used for indexing and filtering in search systems. "allowing much lower memory usage and the ability to treat them as a normal filter in Apache Lucene"
- Approximate Nearest Neighbor (ANN): Algorithms and data structures that quickly find near neighbors in high-dimensional spaces with acceptable approximation. "specialized ANN solutions such as Hierarchical Navigable Small Worlds (HNSW) and Inverted File Index (IVF)"
- canonical placeId: A standardized identifier representing a geographic location for queries. "Key information such as the location (encoded via a canonical placeId and represented by a learned dense embedding)"
- centroids: Representative points of clusters used in vector indices like IVF. "IVF only requires cluster IDs and centroids to be stored in the index at runtime"
- cold start problem: The challenge of ranking or recommending new items with limited historical engagement data. "to mitigate the cold start problem and generalize across the diverse population of listings."
- contrastive learning: A training approach that brings similar pairs closer and dissimilar pairs farther apart in embedding space. "construct hard negatives for contrastive learning along with practical trade-offs for model architectures and loss functions."
- discriminative filters: Strong filtering criteria that sharply reduce the candidate set (e.g., geographic constraints). "which meant that discriminative filters were difficult to apply in parallel with retrieval without major system changes."
- Embedding-Based Retrieval (EBR): Retrieval that represents queries and items as learned vectors in the same space and ranks by similarity. "leveraged Embedding-Based Retrieval (EBR) to represent both listings and search queries as numerical vectors in the same space."
- Euclidean distance: A metric for measuring straight-line distance between embeddings, often used for similarity. "Specifically, even though dot product and Euclidean distance performed about the same in offline evaluation"
- FAISS: A library for efficient similarity search and clustering of dense vectors. "We benchmarked several approaches using the FAISS library"
- First-Stage Model: A heavyweight deep neural network producing relevance scores for listings after retrieval. "First-Stage Model (Leaf Service): A heavyweight DNN model which produces a single score per listing."
- Flexible Date Search: A product feature that expands eligible results by allowing date flexibility. "A further challenge for our EBR system was scaling to support use cases such as Flexible Date Search"
- ground truth: The reference labels or results treated as correct for evaluation. "compute recall metrics for a retrieval model using the first-stage model as the ground truth (runs in offline cluster)"
- Hierarchical Navigable Small Worlds (HNSW): A graph-based ANN index enabling fast nearest-neighbor search. "specialized ANN solutions such as Hierarchical Navigable Small Worlds (HNSW) and Inverted File Index (IVF)"
- inner product similarity: A similarity measure computed as the dot product between embeddings. "with a pointwise loss function and inner product similarity."
- Inverted File Index (IVF): A clustering-based ANN method that searches a subset of clusters to retrieve candidates. "specialized ANN solutions such as Hierarchical Navigable Small Worlds (HNSW) and Inverted File Index (IVF)"
- k-means clustering: An algorithm that partitions data into k clusters by minimizing within-cluster distances. "we introduced an offline k-means clustering stage in our offline data pipeline that ran daily"
- KNN: Exact k-nearest neighbors retrieval, used as a benchmark against ANN. "Recall with IVF vs. True KNN for different similarity measures"
- Leaf Service: A shard-level service that performs retrieval and ranking in parallel. "Each Leaf Service node performs retrieval and ranking and returns the top results to the Root Service"
- NDCG: Normalized Discounted Cumulative Gain, a ranking metric emphasizing top positions. "We compute the recall (as opposed to NDCG which is better suited to evaluate the first-stage model)"
- nprobes: An IVF parameter controlling how many clusters are probed during search. "One challenge was how to determine the value of an important parameter known as nprobes which defines the number of closest clusters (to the query embedding) to retrieve listings from."
- pairwise loss function: A training loss that optimizes relative ordering of pairs of items. "with an updated EBR model which now includes more features, larger network size (20% more parameters) and a pairwise loss function with Euclidean distance."
- pointwise loss function: A training loss that evaluates items independently rather than in pairs or lists. "with a pointwise loss function and inner product similarity."
- recall@K: The proportion of relevant items retrieved within the top K results. "metrics obtained by processing such logs (such as recall@K) tend not to generalize well to a true online setting."
- Root Service: The entry-point service that fans out requests to shards and aggregates results. "Each incoming search request first goes to the Root Service, which fans out to make parallel calls to each Leaf Service."
- Setwise Re-Ranker Model: A model that jointly optimizes the ordering of a set of top results. "Setwise Re-Ranker Model (Root Service): A setwise ranking model to optimize the top results jointly"
- sharded scatter-gather architecture: A distributed design that splits work across shards and then aggregates results. "Airbnb search uses a sharded scatter-gather architecture to scale horizontally."
- S2Cell IDs: Hierarchical geospatial identifiers from the S2 geometry library used for location encoding. "S2Cell IDs of various resolutions"
- Split Stays: A product feature that splits a trip across multiple listings to expand options. "Split Stays \cite{airbnb_split_stays_press_release} led to a significant increase in the number of eligible listings for a typical search query."
- traffic replay framework: An offline system that replays production queries to evaluate models at scale. "we used a traffic replay framework to fork a small percentage of production search traffic to an offline cluster."
- two-tower model: An architecture with separate networks for query and item embeddings combined by a similarity function. "we used two-tower model commonly seen in industry applications"
Collections
Sign up for free to add this paper to one or more collections.