- The paper demonstrates that LLMs signal truthfulness through two mechanisms: Q-Anchored (question-driven) and A-Anchored (answer-driven) encoding.
- The authors use saliency analysis, attention knockout, and token patching experiments to validate distinct pathway sensitivities in truthfulness encoding.
- The pathway-aware applications, including Mixture-of-Probes and Pathway Reweighting, significantly enhance hallucination detection and model reliability.
Two Pathways to Truthfulness in LLMs: Mechanistic Insights and Implications for Hallucination Detection
Overview and Motivation
The paper "Two Pathways to Truthfulness: On the Intrinsic Encoding of LLM Hallucinations" (2601.07422) conducts a rigorous analysis of how LLMs encode internal signals of truthfulness and hallucination. While prior work has demonstrated that probing internal model states can recover reliable truthfulness signals, the mechanisms underlying such representations have remained opaque. This work provides a comprehensive mechanistic characterization via a series of interpretability experiments, revealing two fundamentally distinct pathways by which LLMs encode truthfulness: the Question-Anchored (Q-Anchored) pathway and the Answer-Anchored (A-Anchored) pathway.
Mechanistic Dissection of Hallucination Encoding
Saliency Analysis and Bimodal Mechanisms
Initial experiments employ saliency-driven interpretability to measure information flow from question tokens to answer tokens in QA settings. Kernel density estimation of saliency scores discloses a bimodal distribution, suggesting two atypical regimes: instances with negligible question-to-answer flow and others with significant dependence.
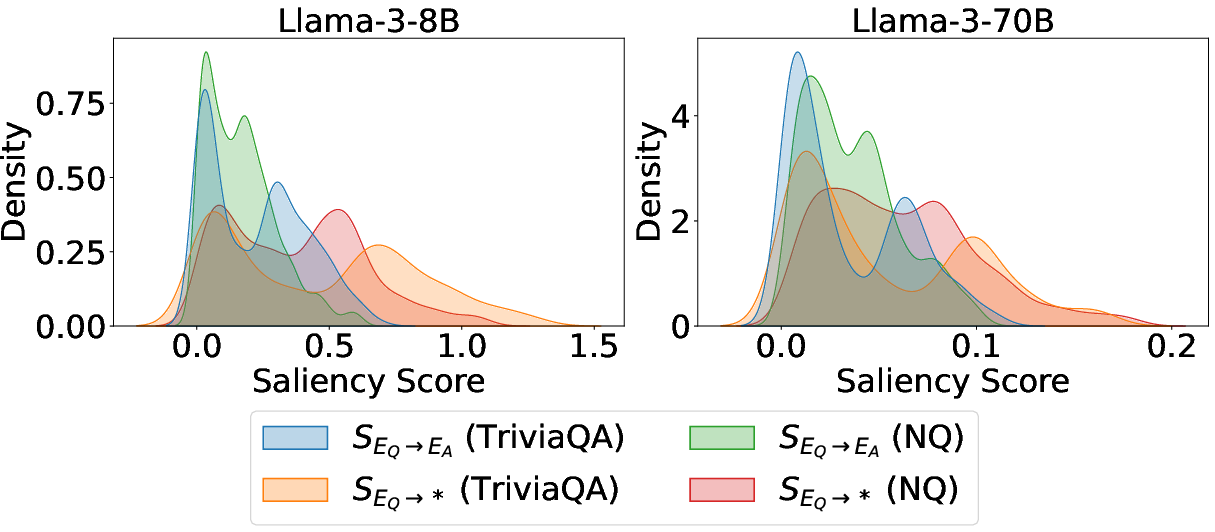
Figure 1: Kernel density estimates of saliency-score distributions for question-to-answer flows; clear bimodality evidences two mechanisms.
This bimodality postulates two diverging modes of internal truthfulness encoding: one that relies on information transfer from questions (Q-Anchored) and another largely independent of the input context (A-Anchored).
Attention Knockout and Patching Experiments
To validate this dichotomy, attention knockout interventions selectively suppress attention weights from exact question tokens to downstream answer positions. Probing classifier predictions exhibit bifurcated responses: Q-Anchored samples undergo marked prediction shifts, while A-Anchored samples are robust to the intervention.
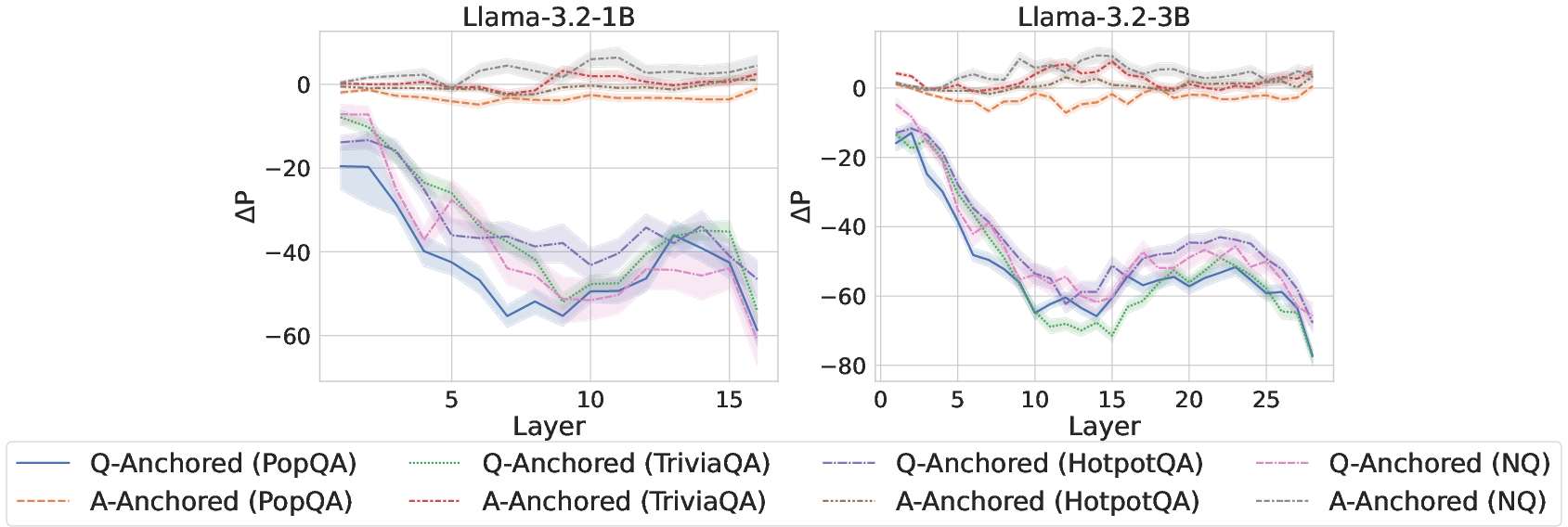
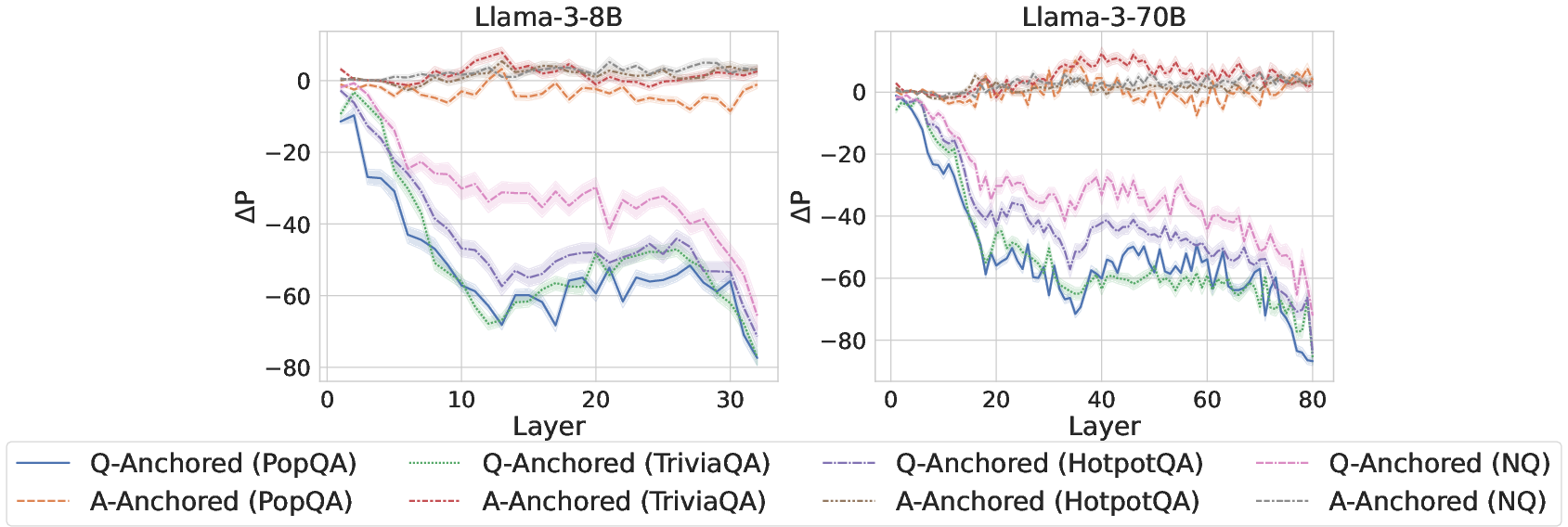
Figure 2: ΔP under attention knockout, subdivided by pathway, with sharp probability changes for Q-Anchored samples and stability for A-Anchored.
Complementary token patching experiments inject hallucinatory cues into questions, confirming that Q-Anchored encodings are sensitive to such corruption, unlike A-Anchored, whose predictions persist.
Source Attribution: The A-Anchored Pathway
To dissect the information source for A-Anchored encoding, "answer-only" experiments exclude the question altogether, forwarding only model-generated answers. Consistently, Q-Anchored samples display substantial prediction drift, whereas A-Anchored samples remain invariant, indicating self-contained evidence in the answer representation.
Knowledge Boundaries and Self-Awareness
Pathway Association with Knowledge Boundaries
Cross-dataset analysis shows that Q-Anchored encoding predominantly occurs for high-certainty, in-domain factual queries (with higher accuracy), while A-Anchored encoding is overrepresented for long-tail, low-support entities lying outside the model’s knowledge boundary.
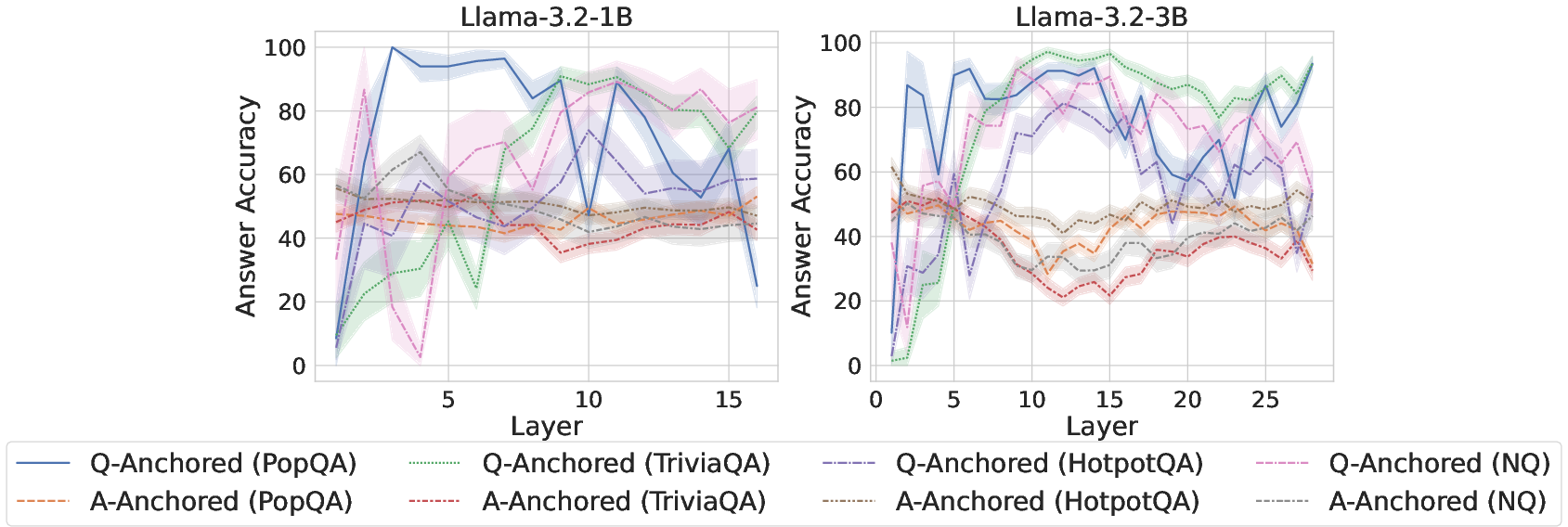
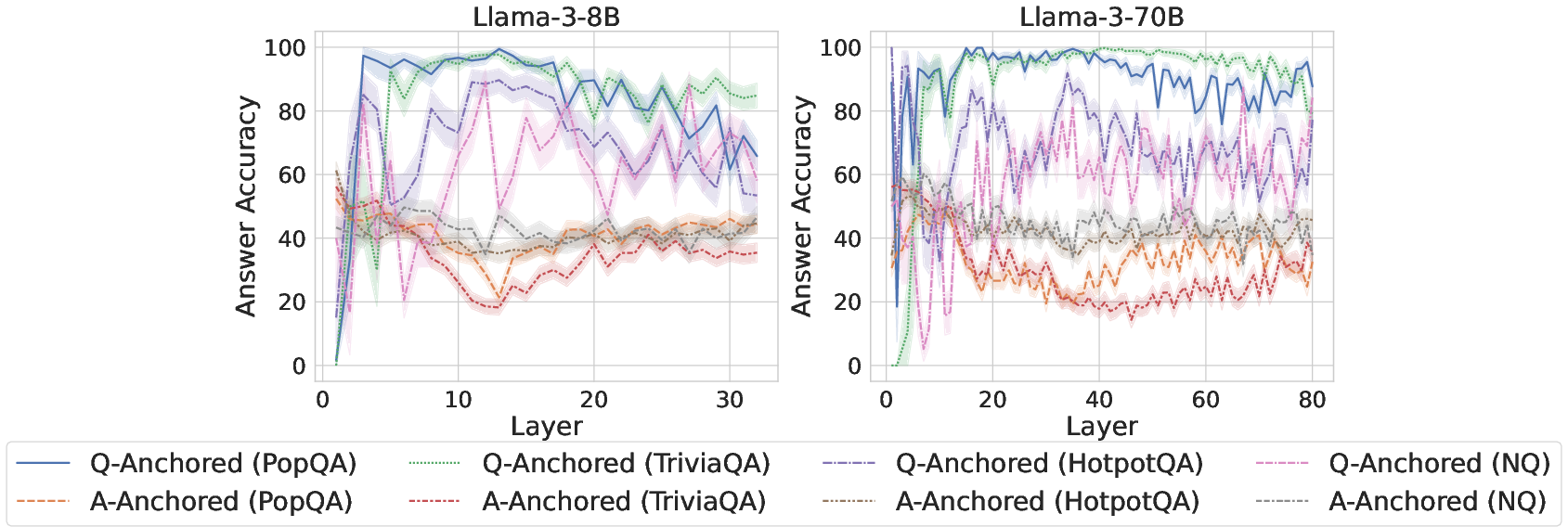
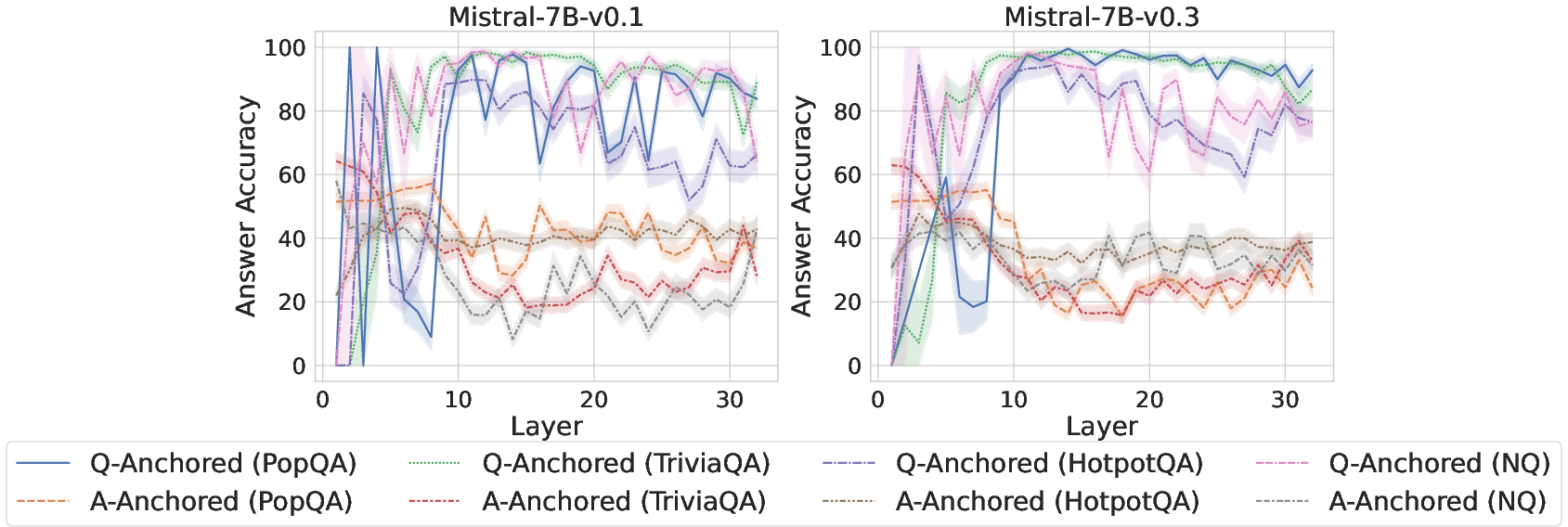
Figure 3: Comparisons of answer accuracy between pathways, evidencing Q-Anchored dominance in high-accuracy regimes.
Entity popularity analysis further substantiates that Q-Anchored activation is correlated with storage of parametric knowledge about popular entities, while A-Anchored is invoked in cases of parametric deficiency.
Intrinsic Pathway Awareness
The model’s hidden states themselves can reliably discriminate which encoding pathway is active. Probing classifiers trained to predict pathway mode achieve high AUC on multiple datasets and architectures, substantiating genuine mechanistic self-awareness.
Pathway-Aware Applications: Advancing Hallucination Detection
Mixture-of-Probes Architecture
Leveraging pathway specialization, the Mixture-of-Probes (MoP) architecture routes samples via a gating network to expert probes trained on each pathway type. This configuration substantially outperforms generic probing and ablated ensemble variants (with up to 10% AUC improvement over strong baselines).
Pathway Reweighting
Pathway Reweighting (PR) adaptively amplifies attention between answer and question tokens based on predicted pathway membership, thereby enhancing the saliency of truthfulness signals most germane to hallucination detection. This plug-and-play technique yields further AUC gains across a spectrum of datasets and model scales.

Figure 4: Comparisons of answer accuracy between pathways, probing mlp activations of the last exact answer token.
Aggregate Results
Both MoP and PR methods demonstrate consistent superiority over uncertainty-based (semantic entropy, logit metrics), self-consistency, and vanilla probing approaches, generalizing robustly across model architectures and QA formats.
Implications and Prospects
This work elucidates key properties of LLM internal truthfulness encoding:
- The presence of mechanistically distinct Q-Anchored and A-Anchored pathways resolves ambiguities in latent knowledge representation and offers clear mappings to parametric knowledge boundaries.
- Intrinsic model awareness of pathway selection enables fine-grained, dynamically specialized hallucination detection, a capability markedly superior to monolithic probing.
- Pathway specialization provides practical handles for developing intervention, analysis, and downstream reliability controls, both at inference-time and within model design.
Prospectively, dissecting further how these pathways arise during model pretraining, instruction tuning, and RL alignment may suggest principled strategies to suppress hallucinations. Moreover, generalizing pathway-aware techniques to tasks beyond QA (e.g., dialogue, summarization) would expand the utility and theoretical reach of this mechanistic framework.
Conclusion
The paper presents a detailed, empirical dissection of truthfulness encoding in LLMs, revealing synergistic but distinct Q-Anchored and A-Anchored pathways, each aligned to knowledge boundaries and associated with explicit patterns of hallucination sensitivity. By harnessing pathway self-awareness, the authors achieve measurable advances in hallucination detection efficacy, establishing a foundation for robust, interpretable generative modeling. These findings inform both practical techniques for reliability and broader theoretical models of LLM internal computation.