- The paper introduces Generation-Augmented Generation (GAG), a framework for injecting domain-specific knowledge into frozen LLMs using a compact, single-token approach.
- GAG leverages a two-stage training protocol and a prototype-based router to achieve significant QA performance boosts on specialist tasks while maintaining generalist capabilities.
- The method delivers predictable, governance-friendly behavior with over 99.5% routing accuracy and avoids the pitfalls of fine-tuning and context dilution.
Generation-Augmented Generation: Modular, Plug-and-Play Knowledge Injection for Frozen LLMs
Motivation and Problem Setting
Domain deployment of LLMs for domains such as biomedicine, materials science, and finance is fundamentally constrained by the challenge of robust domain adaptation in the presence of private, continuously evolving corpora. The two canonical strategies for domain adaptation—full or parametric fine-tuning and retrieval-augmented generation (RAG)—suffer, respectively, from catastrophic forgetting/hard governance constraints and from high brittleness and context-competition phenomena, especially pronounced in private, chunk-fragmented corpora (Figure 1).
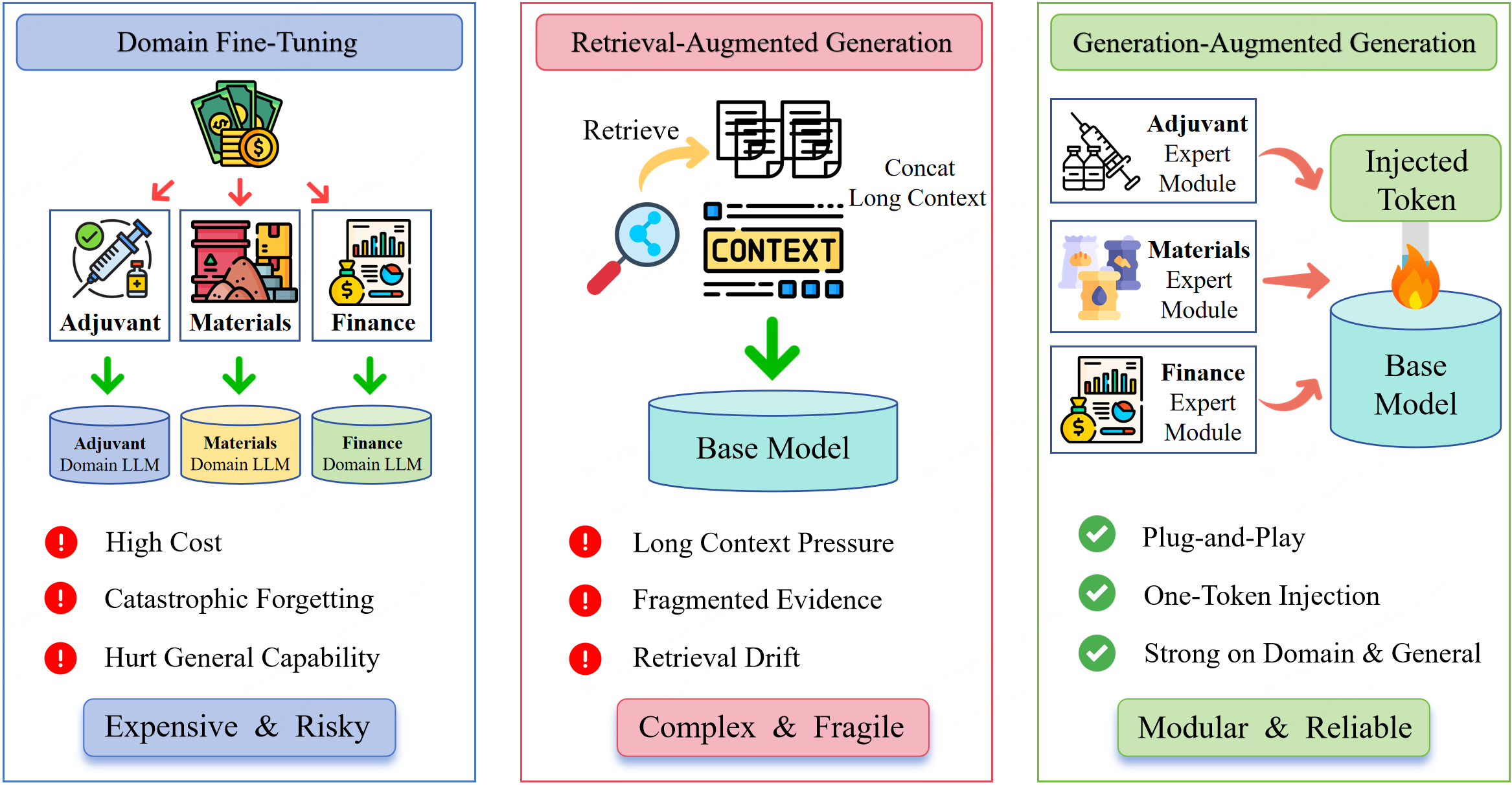
Figure 1: The three primary private knowledge injection paradigms: fine-tuning, RAG, and GAG.
Within this context, the key question is how to inject domain-private knowledge into a strictly frozen LLM, enabling robust multi-domain expansion, avoiding the drawbacks of fine-tuning and evidence-serialization, and delivering predictable, governance-friendly behavior.
GAG Architecture and Methodology
This paper formalizes "generation-augmented generation" (GAG), which reconceptualizes knowledge injection as a representation-level, retrieval-free augmentation mechanism. GAG uses a modular plug-and-play interface: domain knowledge is distilled into a lightweight domain-specific expert LLM and summarized as a single continuous embedding token that conditions the base (frozen) LLM (Figure 2). Route selection is managed by a training-free, prototype-based router (PPR), yielding a system that supports dynamic, incremental domain expansion without router training or cross-module fine-tuning.
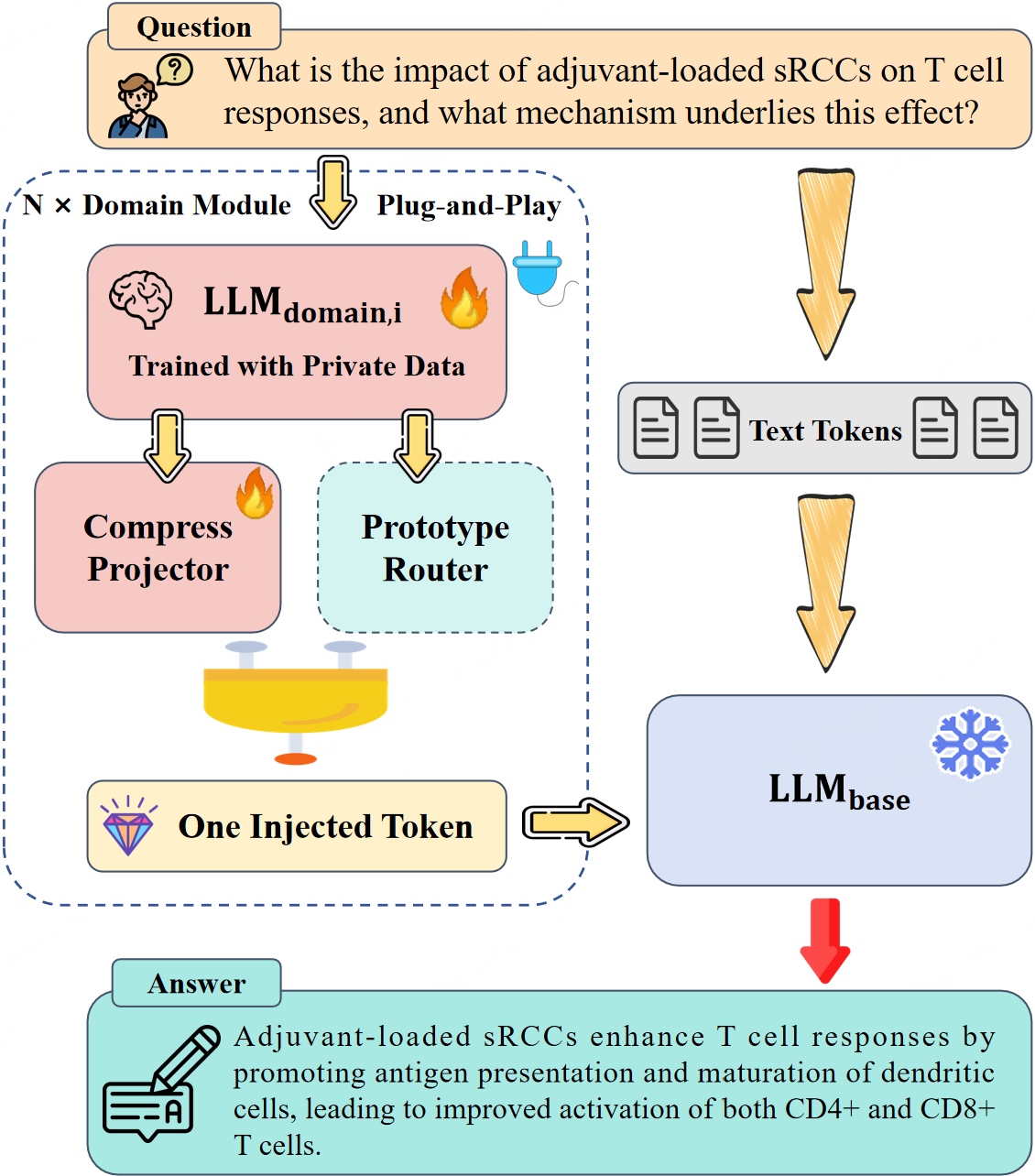
Figure 2: GAG pipeline: routing, domain modules, and one-token injection.
The GAG implementation is organized around a two-stage learning protocol (Figure 3):
- Domain Expert Adaptation: A domain LLM (e.g., Qwen3-1.7B), is finetuned on in-domain data to maximize QA performance and to encode salient domain priors in its late-layer representations.
- Projector Alignment: A lightweight projector is learned to map late hidden states of the domain expert into the base model’s embedding space, producing the injected conditioning token under a frozen base.
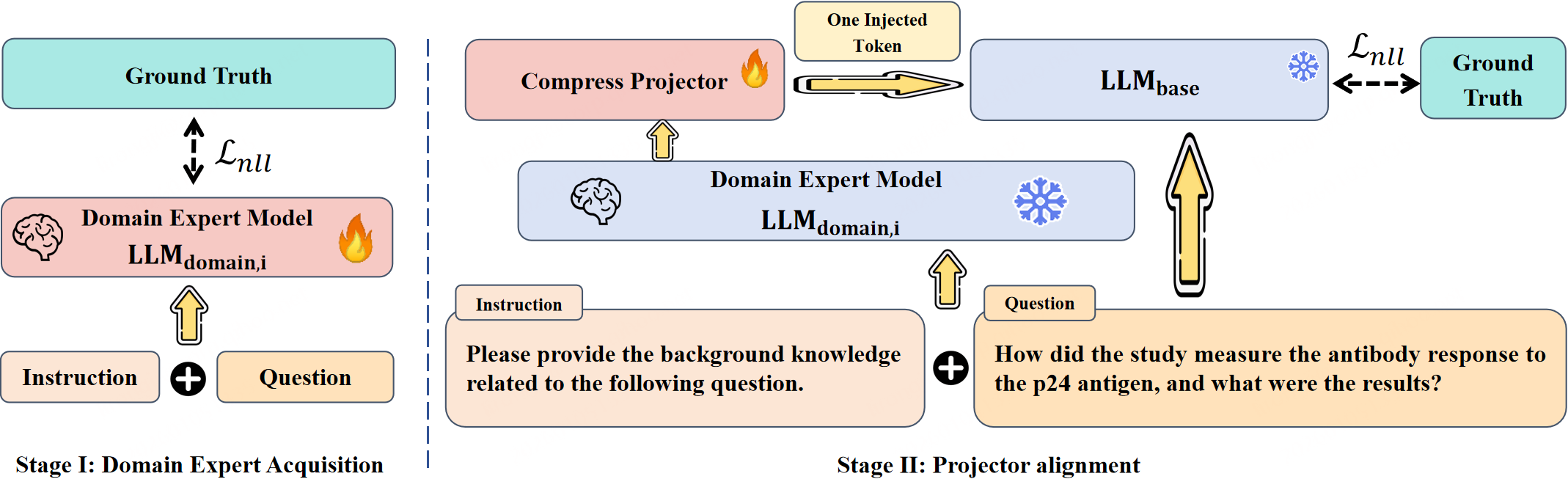
Figure 3: Two-stage training: domain competence distillation (stage I) and projector alignment (stage II).
The prototype router (Figure 4) computes domain activation by clustering frozen query embeddings per domain, then using maximum cosine similarity for non-parametric routing.
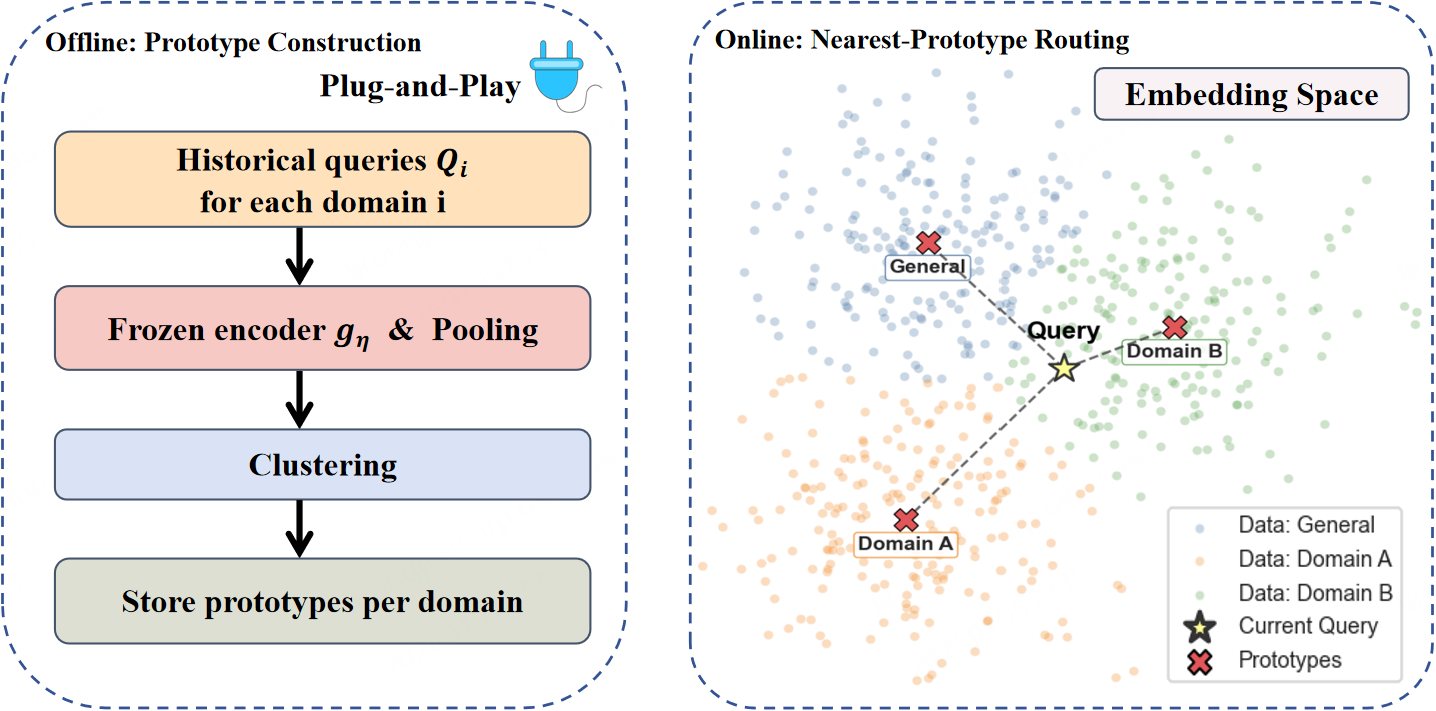
Figure 4: Prototype-based routing enables modular, incremental multi-domain expansion.
Empirical Findings
GAG is evaluated on two specialist QA settings (immunology adjuvant and catalytic materials), as well as on six general-domain QA benchmarks. For specialist tasks, GAG delivers large performance boosts over RAG—15.34% and 14.86% improvements, respectively—while introducing only a single injected token (not hundreds of context tokens as with RAG), and maintains parity with the frozen base model on general-domain tasks.
Strong specialist gains are not achieved by competitive expert-generated-context (EGC) baselines; EGC suffers substantial general-domain degradation due to dilution and misalignment in text-level concatenation, whereas GAG's embedding-level injection provides high signal-to-noise modularity.
Routing Accuracy and Scalability
The PPR router achieves >99.5% accuracy even under aggressive multi-domain incremental expansion, with no degradation in old or new routes, without any router-specific training or threshold tuning. This confirms the modular, deployment-oriented nature of GAG and its suitability for plug-and-play extension.
Qualitative Case Analyses
The paper includes a sequence of instructive error mode analyses comparing RAG and GAG:
Practical and Theoretical Implications
GAG advances the field of modular LLM adaptation by providing a blueprint for strict, governance-preserving model architectures capable of robust, domain-specific competence without catastrophic forgetting or variable-length inference. Theoretical implications include aligning private corpora adaptation with multimodal interface design (borrowing from vision-LM frameworks), and providing empirical backing for representation-level rather than text-level knowledge transfer.
The deployment-oriented benefits are substantial: GAG supports constant knowledge-injection budget, fast modular expansion, and eliminates the operational overheads of iterative fine-tuning and retrieval system maintenance. For private domains subject to rapid data evolution and confidentiality constraints, this approach provides both control and performance.
Limitations and Future Work
While GAG excels in single-domain context, its architecture as presented does not yet support compositional injection across multiple simultaneously relevant domains; selective activation assumes query-to-domain assignment is atomic. Additionally, because the mechanism uses a single expert-generated embedding, cases demanding verbatim recall of surface-form numerics (e.g., specific measured values) may require auxiliary normalization modules to supplement the high-level conceptual prior.
Ongoing work could investigate multi-token or probabilistic expert-token injection, or dynamic mixtures of domain priors, to address evolving cross-domain composition requirements and higher-fidelity grounding for highly structured answers.
Conclusion
The GAG framework introduces a robust, modular, retrieval-free schema for private knowledge injection into frozen LLMs, advancing both theoretical understanding and practical deployment of plug-and-play domain adaptation. Strong empirical improvements on specialist QA benchmarks, rigorous control over generalist regression, and near-saturated routing accuracy confirm the viability of moving away from chunk-level retrieval toward compact, interface-aligned knowledge transfer. GAG offers a scalable foundation for next-generation, scalable, governance-aligned enterprise LLM deployment.
References:
"Generation-Augmented Generation: A Plug-and-Play Framework for Private Knowledge Injection in LLMs" (2601.08209)
