- The paper introduces D^2Prune, a dual Taylor expansion method that estimates weight and activation errors to achieve a 10% reduction in perplexity and up to 40% accuracy improvement under high sparsity conditions.
- It employs an attention-aware dynamic update strategy that minimizes KL divergence by 61% and RMSE by 43%, effectively preserving the long-tail distribution of attention mechanisms.
- Experimental evaluations reveal that D^2Prune outperforms existing pruning methods across various LLMs and even extends its benefits to vision models like DeiT on ImageNet-1K.
Dual Taylor Expansion and Attention Distribution Awareness in Pruning LLMs
Introduction
The paper "D2Prune: Sparsifying LLMs via Dual Taylor Expansion and Attention Distribution Awareness" (2601.09176) targets a notable challenge in the deployment of LLMs: their considerable computational requirements, largely due to the models' size and complexity. It introduces an innovative pruning method, D2Prune, aimed at optimizing the computational efficiency of LLMs by addressing key limitations of existing pruning methods.
Limitations of Existing Methods
Existing pruning techniques are criticized for two primary deficiencies. First, they often disregard the activation distribution shifts between calibration and test data, leading to inaccurate error estimates. This results in suboptimal pruning decisions that can degrade model performance on downstream tasks. Second, they overlook the long-tail distribution characteristics inherent in the attention module of transformer models. This oversight can significantly affect the accuracy of tasks that rely heavily on attention mechanisms.
Methodology: D2Prune
The D2Prune approach innovatively uses a dual Taylor expansion to precisely estimate the error caused by both weight and activation perturbations during pruning. This enables the selection of accurate pruning masks and facilitates weight updates that minimize this error. By doing so, the method reduces perplexity in models by 10% compared to single-variable approaches, with improvements in accuracy reaching up to 40% in high-sparsity conditions.
To maintain the fidelity of attention mechanisms, D2Prune introduces an attention-aware dynamic update strategy. It simultaneously minimizes the Kullback-Leibler (KL) divergence in attention distributions and the reconstruction error to preserve the long-tail distribution pattern critical for many language understanding tasks. This approach results in a significant reduction of both the KL divergence and the root-mean-square error (RMSE) by 61% and 43% respectively, compared to other state-of-the-art (SOTA) practices.
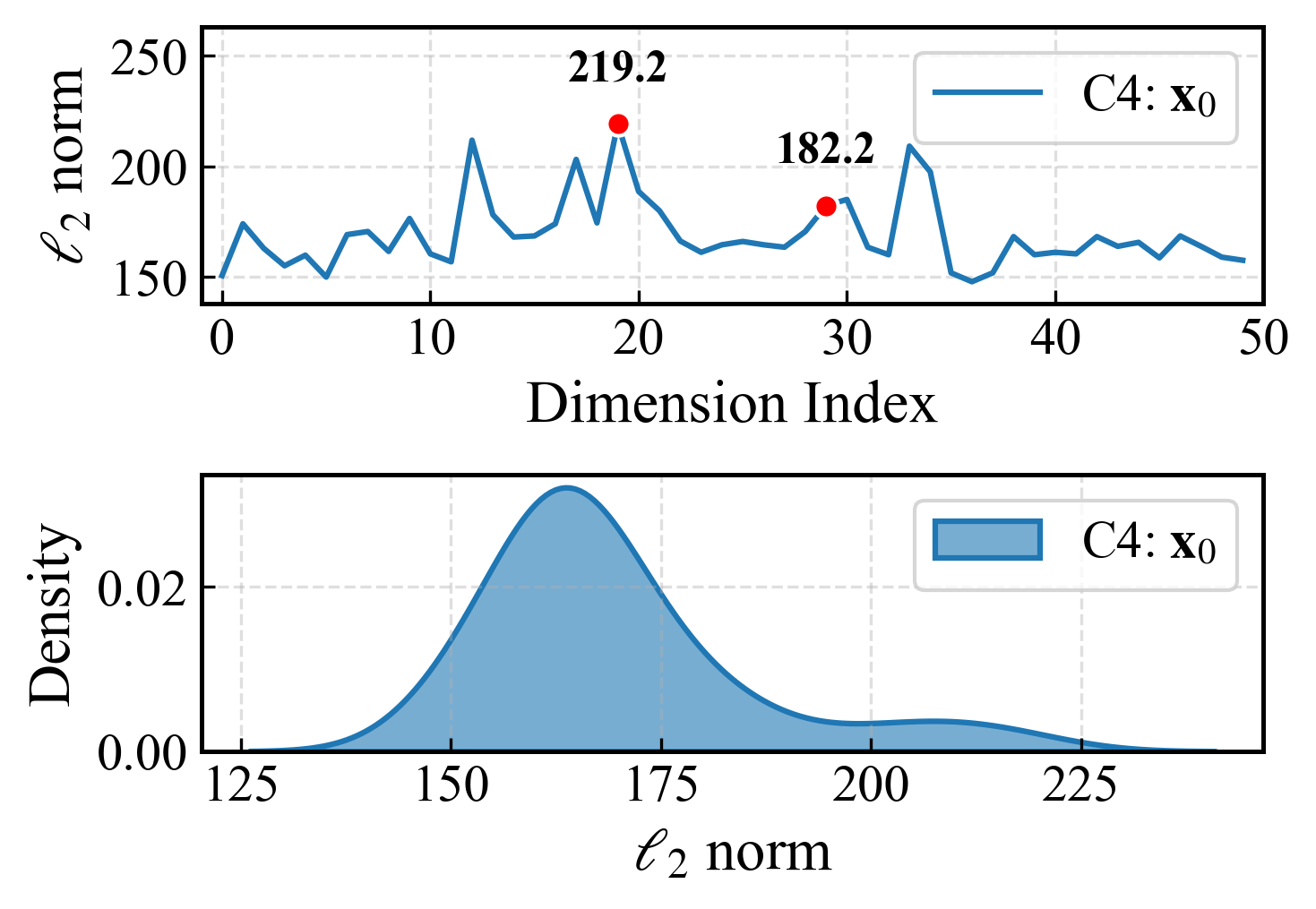
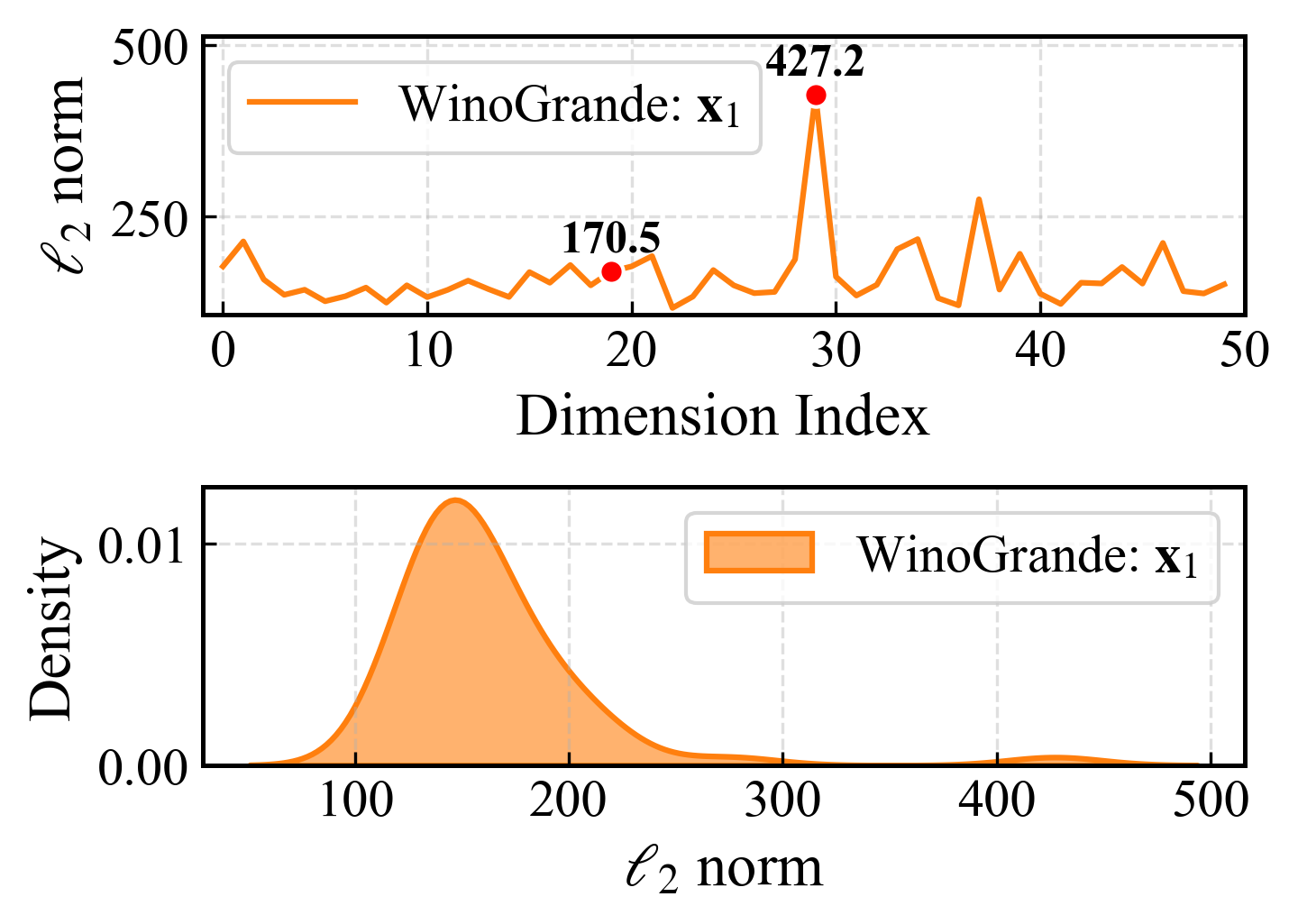
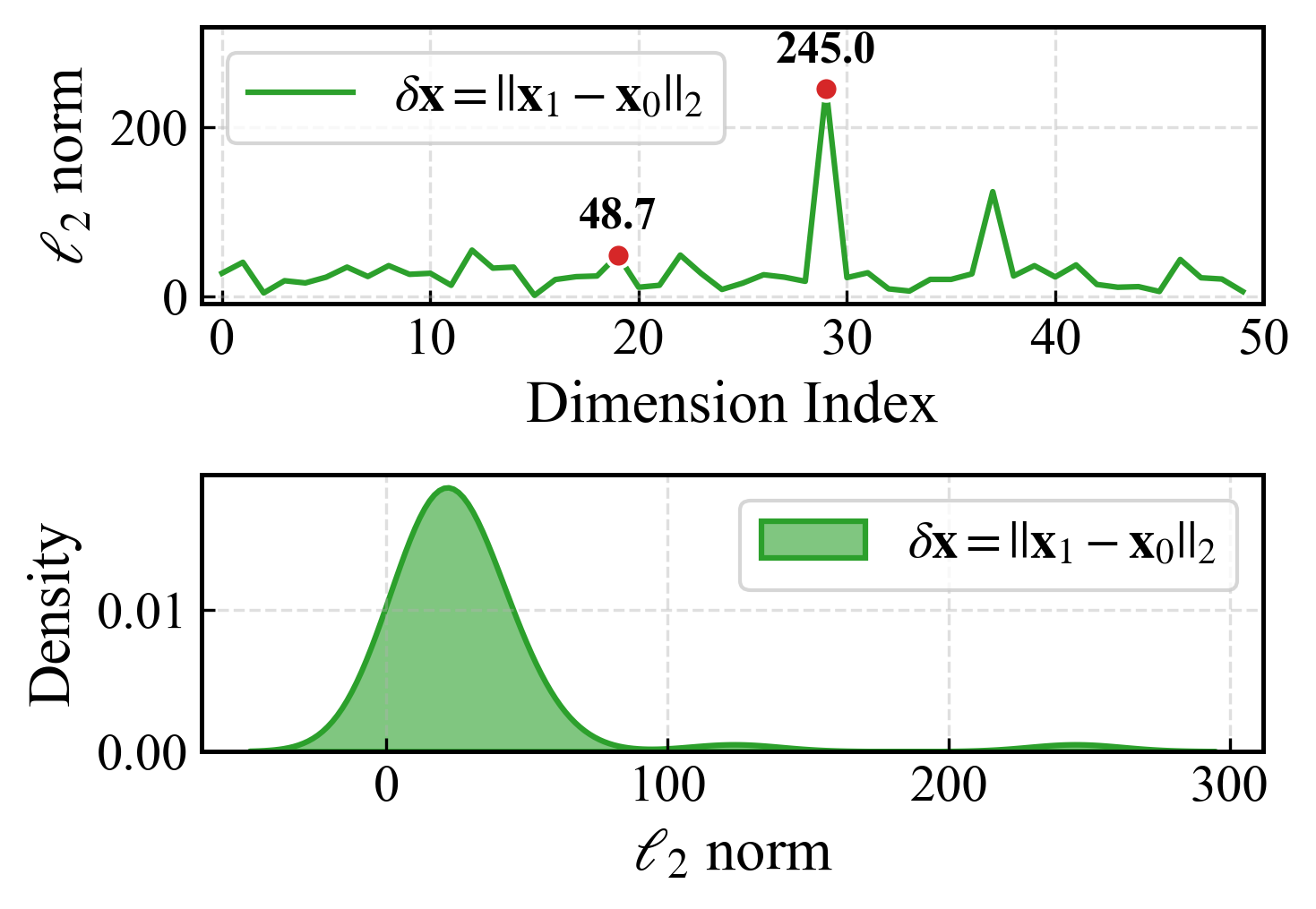
Figure 1: Activation distributions and their shift between upstream and downstream data in LLaMA-2-7B.
Experimental Evaluation
The experimental results demonstrated that D2Prune consistently outperforms existing pruning methods across various LLMs, such as OPT-125M and LLaMA models, in terms of perplexity reduction and zero-shot accuracy across different sparsity levels. The dynamic attention update mechanism has also been shown to generalize well to vision models like DeiT, achieving notable accuracy enhancements on ImageNet-1K datasets.
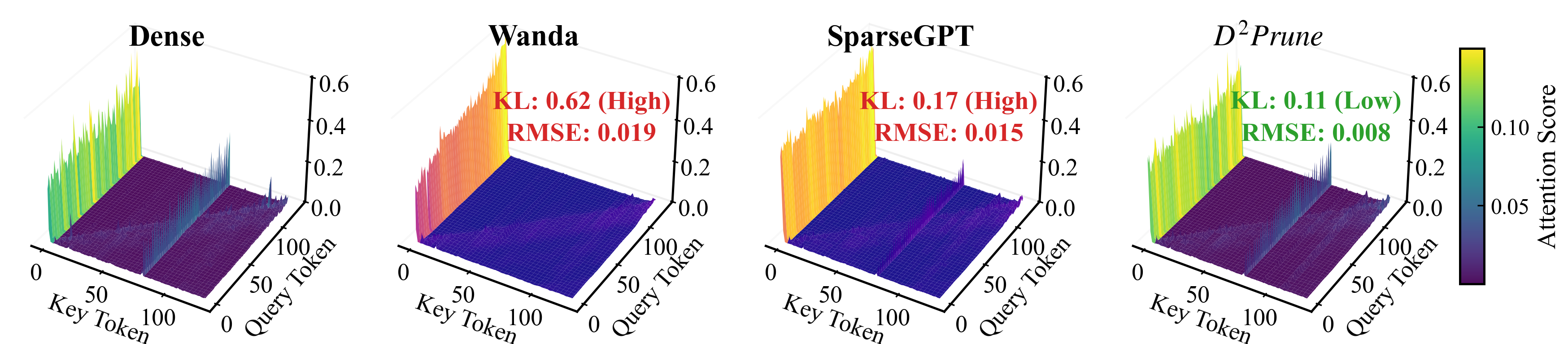
Figure 2: Visualizing uniformized multi-head attention in LLaMA-2-7B at 80% sparsity.
Discussion and Future Directions
The proposed D2Prune algorithm significantly advances the state-of-the-art in LLM pruning by offering robust solutions to two major limitations of previous methods. The introduction of the dual Taylor expansion and dynamic attention update strategies marks a promising step forward in achieving efficient model compression without sacrificing performance.
Future developments could explore integrating these pruning techniques with other forms of model compression, such as quantization, to further enhance the deployability of LLMs. Additionally, exploring non-uniform sparsity configurations that adaptively prune based on layer-specific redundancies and sensitivities could provide even greater efficiency gains.
Conclusion
In conclusion, D2Prune offers a compelling approach to reducing the computational demands of LLMs. By addressing key weaknesses in prior methods, it opens new possibilities for deploying powerful LLMs in resource-constrained environments without compromising performance. The promising results achieved with D2Prune suggest that dual expansion and attention distribution awareness may become integral components of future pruning frameworks.