- The paper proposes an innovative Energy-Entropy Regularization that transforms the loss landscape into a funnel-like geometry, enhancing training stability for minimal looped transformers.
- It integrates Tsallis entropy with Hamiltonian dynamics to maintain stable attention maps and improve out-of-distribution sequence generalization.
- Experimental results demonstrate that a minimal architecture (d=8) can outperform larger models like FOP-Looped-Adaptive in efficiency and reasoning tasks.
The paper "Energy-Entropy Regularization: The True Power of Minimal Looped Transformers" (2601.09588) introduces a novel training framework for single-head looped transformer architectures. These models are traditionally challenging to train due to their highly non-convex and irregular loss landscapes, which frequently result in optimization stagnation at poor local minima and saddle points. The paper aims to improve the training and understanding of these architectures by introducing a method involving Tsallis entropy and Hamiltonian dynamics, transforming the loss landscape to enhance optimization performance.
Training Stability Through Entropy Contraction
A key component of the proposed training framework is the introduction of entropy contraction to ensure training stability. By applying Tsallis entropy to the attention mechanism, the authors provide a formal interpretation of its information-theoretic limits. This approach ensures that the attention maps remain stable over long-term iterations by preventing collapse and divergence.
Hamiltonian Latent Dynamical System
The paper reinterprets the dynamics of latent variables in the looped transformer as a Hamiltonian system. The latent state is viewed as a physical particle traversing an energy manifold, with the potential landscape defined by input tokens. This view redefines the optimization process as a search across a landscape of potential wells, with the model guided by gravitational-like gradient terms. However, this Hamiltonian system, although insightful, is initially deemed insufficient for stable convergence due to high ruggedness in the landscape.
Energy-Entropy Regularized Loss Landscape
The core innovation is the Energy-Entropy Regularized (EER) loss landscape, which redefines the training objective by incorporating physical constraints—kinetic, potential, and entropy regularizations—directly into the objective function. This transformation smooths the optimization path, creating a funnel-like geometry conducive to efficient training even with low-dimensional model structures, as visualized in Figure 1.
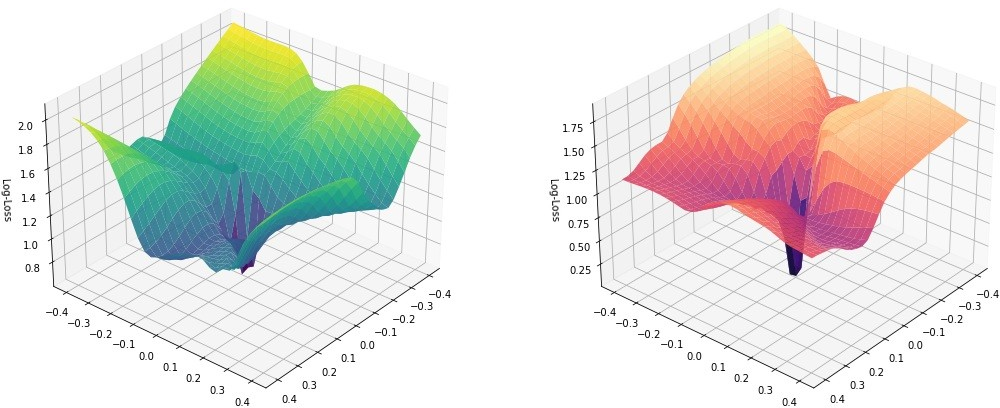
Figure 1: Visualization of the loss manifold showing a funnel-like geometry caused by the energy-entropy regularization in the loss function.
Experimental Results and Implications
The effectiveness of this approach is demonstrated through the training of a single-head looped transformer with a dimension of d=8 for an induction head task involving sequence lengths of up to 1000 tokens. The EER framework leads to significant improvements in out-of-distribution length generalization and parameter efficiency, outperforming existing models like FOP-Looped-Adaptive.
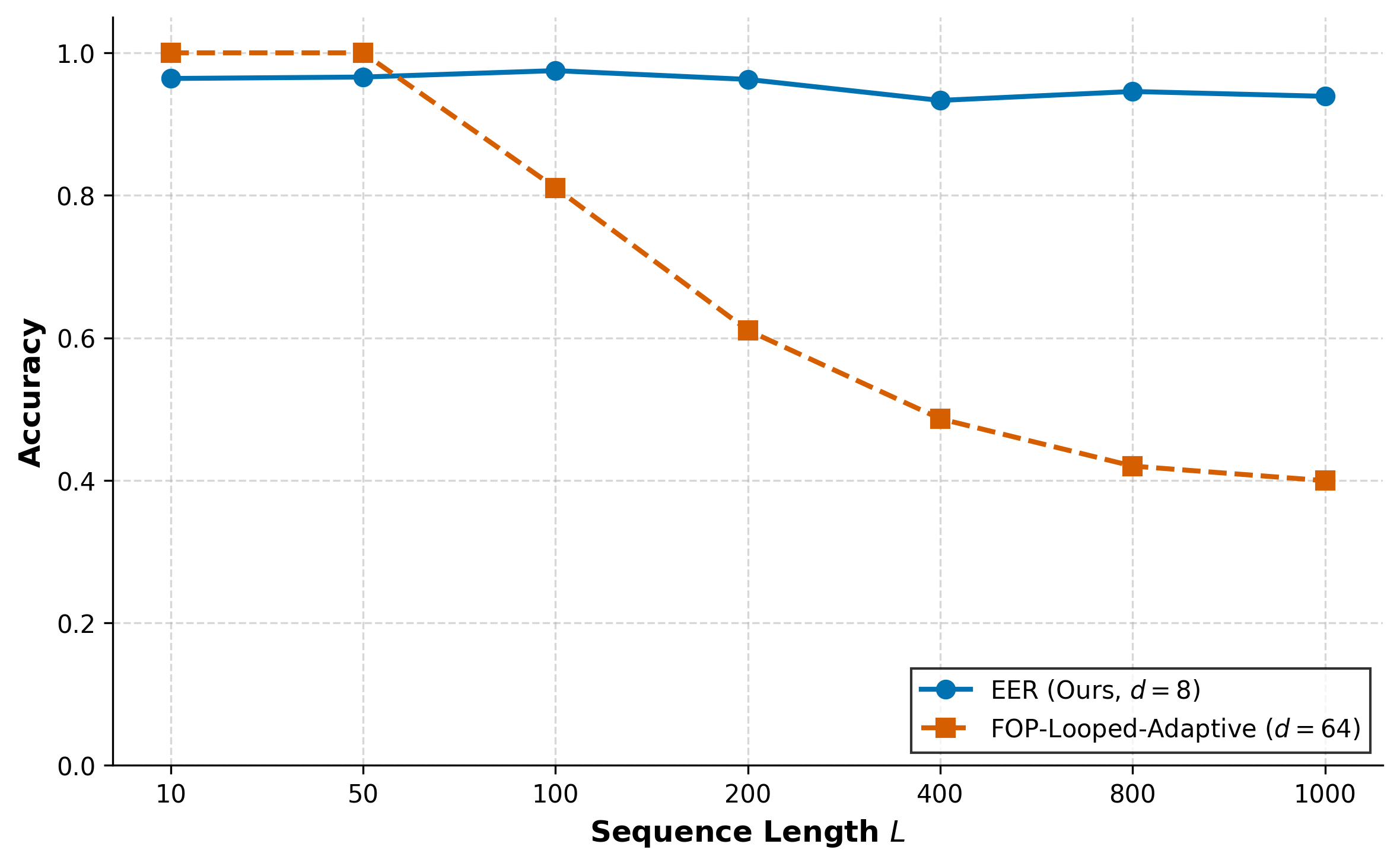
Figure 2: Baseline Comparison of EER (d=8) and FOP-Looped-Adaptive (d=64).
The results highlight the potential for minimal architectures to achieve high-level reasoning tasks generally restricted to more complex models. This suggests a shift in the paradigm from increasing model size to optimizing the underlying loss landscapes for enhanced performance.
Conclusion
The paper contributes to the understanding and practical implementation of looped transformers by leveraging principles from statistical mechanics to smooth the optimization landscape. The results offer both theoretical insights into the operation of these models and practical implications for scaling down model architectures without sacrificing performance. The work invites future exploration into more efficient AI systems grounded in fundamentally simpler designs.