CoDance: An Unbind-Rebind Paradigm for Robust Multi-Subject Animation
Abstract: Character image animation is gaining significant importance across various domains, driven by the demand for robust and flexible multi-subject rendering. While existing methods excel in single-person animation, they struggle to handle arbitrary subject counts, diverse character types, and spatial misalignment between the reference image and the driving poses. We attribute these limitations to an overly rigid spatial binding that forces strict pixel-wise alignment between the pose and reference, and an inability to consistently rebind motion to intended subjects. To address these challenges, we propose CoDance, a novel Unbind-Rebind framework that enables the animation of arbitrary subject counts, types, and spatial configurations conditioned on a single, potentially misaligned pose sequence. Specifically, the Unbind module employs a novel pose shift encoder to break the rigid spatial binding between the pose and the reference by introducing stochastic perturbations to both poses and their latent features, thereby compelling the model to learn a location-agnostic motion representation. To ensure precise control and subject association, we then devise a Rebind module, leveraging semantic guidance from text prompts and spatial guidance from subject masks to direct the learned motion to intended characters. Furthermore, to facilitate comprehensive evaluation, we introduce a new multi-subject CoDanceBench. Extensive experiments on CoDanceBench and existing datasets show that CoDance achieves SOTA performance, exhibiting remarkable generalization across diverse subjects and spatial layouts. The code and weights will be open-sourced.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces CoDance, a new way to turn a single picture with multiple characters into a moving video, even when the “dance moves” (a pose sequence) don’t line up perfectly with where those characters are in the picture. It focuses on making group animations look natural, coordinated, and controllable.
Key Objectives
The researchers wanted to solve three common problems in multi-character animation:
- How to animate any number of characters (not just one or two).
- How to handle characters of different kinds (humans, cartoons, robots, etc.).
- How to work even when the “driving pose” (the motion you want to copy) isn’t in the same place or size as the characters in the picture.
Put simply: make group dance videos from a single image and a pose sequence, without everything needing to line up perfectly, and still keep each character’s look and identity.
How It Works (Methods and Approach)
The problem with older methods
Imagine you have a stage photo of several dancers, and a separate stick-figure “dance guide” showing the moves. Many older methods demand the stick-figure dancer be in the exact same spot and scale as the dancer(s) in the photo. If they don’t match perfectly, the system gets confused: it may animate the wrong part of the image, merge characters together, or even invent a new person in the wrong place.
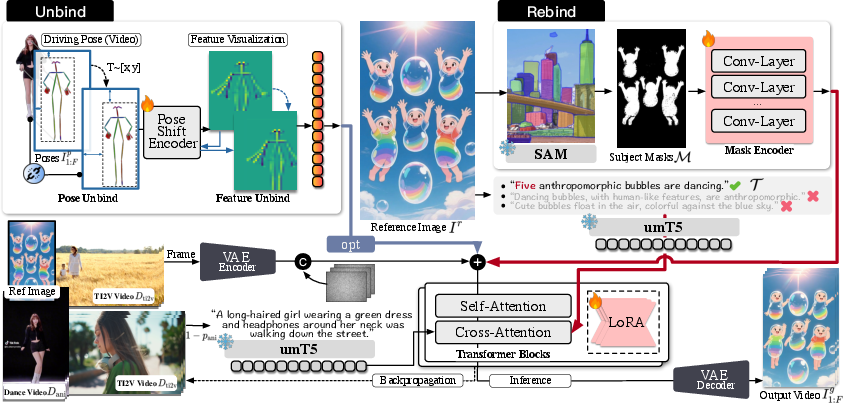
CoDance’s main idea: Unbind-Rebind
CoDance solves this with two steps: Unbind and Rebind.
- Unbind: Learn the dance moves, not the exact coordinates.
- The system deliberately “shakes up” the input poses during training—randomly shifting and scaling the stick-figure moves, and also perturbing their internal features.
- This forces the model to understand motion as “what” (the semantics of the movement), not “where” (the exact pixel location).
- Think of it like teaching a choreographer the steps regardless of where the dancer is standing on stage.
- Rebind: Aim those moves at the right characters.
- Semantic guidance (text): You give a short text prompt, like “Five bubbles are dancing.” A text encoder reads this so the system knows how many characters to animate and what kind they are.
- Spatial guidance (masks): The system uses an image segmentation tool (like SAM) to create masks—clear outlines showing where each subject is in the picture. This is like pointing a spotlight at exactly the characters you want to move, and keeping the background still.
- Together, text + masks “rebind” the learned motion to the correct subjects, even if the poses were shifted during training.
The engine underneath (in everyday terms)
- Diffusion models: Think of creating a video by starting with random static (noise) and gradually removing it until a clear, realistic video appears. The model learns how to remove the noise step-by-step.
- Transformer backbone (DiT): The video is split into small patches (like tiles). A Transformer (a powerful pattern-recognizer used in AI) processes these tiles along with pose, text, and mask information.
- VAE: A tool that compresses images/videos into a “latent space” (a compact representation) and then decodes them back, making training and generation more efficient.
- LoRA: A lightweight way to fine-tune the big model—like adding small clip-on adapters—so it learns new tasks without retraining everything.
- Mixed-data training: To make the text prompts truly useful, they train the model with both animation data and general text-to-video examples. This teaches the system to pay attention to text instructions and not ignore them.
Main Findings and Why They Matter
Here are the key results reported by the authors:
- Better visual quality and identity preservation: CoDance keeps each character looking like themselves while they move, reducing weird distortions and blending.
- Stronger motion control: It assigns the right moves to the right subjects, even in multi-character scenes, and even when the pose sequence doesn’t spatially line up with the image.
- Works for many subject types and counts: It generalizes to humans, stylized characters, and scenes with multiple people or creatures.
- State-of-the-art metrics and user preference: On well-known benchmarks (like Follow-Your-Pose-V2) and a new multi-subject test set, CoDance outperforms previous methods on common measures (like LPIPS, PSNR, SSIM, FID, FVD). In user studies, people preferred CoDance’s videos for overall quality, identity preservation, and smoothness over time.
These results matter because they show we can make group animations from single images more reliable, flexible, and realistic—without the strict setup older methods needed.
Implications and Potential Impact
CoDance’s Unbind-Rebind idea is simple but powerful:
- It could help creators make ads, music videos, educational content, and social media clips with multiple characters more easily.
- It supports diverse characters and layouts, so animators can tell more creative stories without spending hours aligning poses perfectly.
- The approach could be applied beyond dancing—any scenario where you need to map motion to multiple targets (like sports, classroom scenes, or cartoon casts).
In short, CoDance takes a big step toward flexible, robust multi-subject animation: learn the dance moves in a general way, then aim them precisely where they belong.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of the key uncertainties, missing pieces, and unresolved questions that future work could address to strengthen and extend the paper’s contributions.
- Dataset scale and diversity are limited (≈20 multi-subject videos; human-centric sources). A larger, standardized multi-subject benchmark with varied subject counts (1–10+), non-human/anthropomorphic characters, diverse camera motions, occlusions, and controlled misalignment sweeps is needed, with annotations for masks, identities, instance-level associations, depth/occlusion order, and choreography labels.
- Claims of “arbitrary subject counts/types/positions” are not stress-tested. Systematic evaluations of scalability (e.g., 6–10+ subjects), scene complexity, and memory/latency trade-offs are missing.
- The method relies on offline SAM-based masks from a single reference image. It remains unclear how mask inaccuracies, incomplete segmentation, or ambiguous boundaries affect results; robustness curves under synthetic mask noise and failure modes should be quantified.
- No mechanism is provided to handle dynamic masks over time. When subjects move beyond reference mask bounds, does animation clip or spill? A mask propagation strategy (e.g., optical flow, learned mask tracker) or end-to-end trainable segmentation is needed.
- Inter-subject occlusion and contact are not modeled (e.g., depth ordering when dancers overlap). Incorporating depth, ordering priors, or learned occlusion handling and evaluating in heavily interacting scenes are open directions.
- The “single pose drives multiple subjects” mapping policy is under-specified. How is a single skeleton distributed across multiple instances (synchronization vs. role-wise variation)? Experiments contrasting synchronized copying vs. learned per-subject variations are missing.
- Text-guided semantic “rebind” lacks instance-level referential grounding. How to resolve ambiguity when multiple similar subjects are present (“five bubbles,” which bubble moves first)? Methods for phrase-region alignment, referring expressions, instance IDs, or spatial text grounding should be explored and evaluated.
- Arbitration between text guidance and mask constraints is not defined. In cases of conflicting text and masks, what wins? A principled guidance weighting scheme, confidence-aware fusion, and reporting of failure cases are needed.
- The mixed-data training strategy is under-detailed (probabilities, schedules, losses). Sensitivity analyses (e.g., varying , curriculum design, batch mixing) and checks for catastrophic forgetting of animation control vs. text understanding are missing.
- Quantitative evaluation of text compliance (does the video follow the prompt content/subject count) is absent. Develop and report automatic text-video alignment metrics (e.g., CLIP-based compliance, object counting accuracy) and human studies focused on prompt adherence.
- Robustness to spatial misalignment is claimed but not systematically measured. Provide controlled experiments that sweep translation/scale/rotation of poses and report performance curves.
- The Unbind module’s perturbation hyperparameters (shift/scale ranges, feature duplication strategies) are not analyzed. Ablations on magnitudes, distributions, and temporal consistency impacts, including risks of training instability or artifacts, are needed.
- Feature duplication in “Feature Unbind” could induce unintended biases (e.g., repeated motion fragments). Investigate regularizers (e.g., diversity/consistency constraints), alternative augmentations, and adverse cases.
- The approach uses 2D skeletons; generalization to other motion representations (3D joints, SMPL/parametric bodies, optical flow, audio-driven motion) is unexplored. Comparative studies across motion modalities would clarify robustness.
- Camera motion handling is not addressed. Evaluate and/or model scenarios with handheld/moving cameras and background parallax; consider camera stabilization or explicit camera motion estimation.
- Background behavior is unspecified. Does the method preserve static backgrounds or allow background motion? Quantitative boundary quality and background consistency metrics (e.g., temporal boundary F-score) should be reported.
- Identity preservation metrics are limited to PSNR/SSIM/LPIPS. For human subjects, report ID-aware metrics (e.g., face recognition similarity); for non-human subjects, define and evaluate appropriate identity/appearance consistency measures.
- Long-horizon coherence is not characterized (sequence lengths, drift over time). Report performance vs. video length and introduce drift metrics (e.g., temporal LPIPS, trajectory smoothness).
- Efficiency and deployability are unclear given the Wan 2.1 14B backbone with LoRA fine-tuning. Provide inference speed, memory, batch size constraints, and explore model compression (distillation, quantization, smaller backbones) without losing control fidelity.
- Comparison to specialized multi-subject baselines is missing (code unavailable). Re-implement or approximate comparable baselines (e.g., Follow-Your-Pose variants) for stronger evidence, or release unified evaluation scripts enabling future fair comparisons.
- Failure case taxonomy is absent (e.g., severe occlusion, extreme misalignment, complex non-human morphologies, mask leakage). Provide a catalog of failure modes with qualitative/quantitative characterization and mitigation strategies.
- Group choreography fidelity and inter-subject coordination are not measured. Propose metrics for synchronization, collision avoidance, spacing consistency, and role differentiation; evaluate whether “coordinated” dancing emerges beyond synchronized copying.
- Safety/ethics/data governance are not discussed. Clarify consent/rights for TikTok/fashion data, identity misuse risks, watermarking, and safeguards against deceptive content.
- Open-sourcing details are incomplete. Specify release plans for code, weights, and the multi-subject benchmark (licensing, annotations, mask generation scripts) to enable reproducibility and community benchmarking.
Practical Applications
Below are practical, real-world applications that leverage the paper’s Unbind–Rebind paradigm (pose shift encoder for location-agnostic motion, semantic text guidance, spatial mask guidance via segmentation, DiT+LoRA backbone, and mixed-data training). Applications are grouped by time-to-deploy and linked to sectors, with notes on dependencies and assumptions impacting feasibility.
Immediate Applications
- Multi-character ad creatives with brand mascots or models (Advertising/Marketing)
- Use a single driving pose clip to animate multiple subjects in a reference image (including stylized or non-human characters), enabling rapid production of coordinated group dances or reactions without per-subject alignment.
- Potential tools/workflows: “CoDance API” for creative pipelines; Adobe After Effects/Premiere plug-in; batch-generation service for A/B testing.
- Assumptions/dependencies: High-quality subject masks via SAM or similar; clear text prompts to bind roles; GPU inference; licensing/consent for depicted identities.
- Social media content generation for influencers and SMBs (Media/Creator Economy)
- Turn a group photo into a coordinated dance from one pose driver; generate meme-style multi-character remixes quickly.
- Potential tools/workflows: Mobile app or web tool with pose templates; auto-mask extraction; prompt presets (“Five bubbles dancing”).
- Assumptions/dependencies: Cloud or on-device acceleration; user-friendly mask editing; content safety checks (faces, minors).
- Previsualization for choreography and music video staging (Film/TV/Entertainment)
- Prototype multi-subject sequences from a single pose to explore camera, layout, and motion beats before full production.
- Potential tools/workflows: Blender/Unity add-on for quick animatics; integration with storyboard tools; CoDance batch render scripts.
- Assumptions/dependencies: Reliable identity retention across takes; precise spatial masks to avoid animating background; compute resources for iteration.
- Fast multi-subject cartoon and mascot animation (Animation Studios)
- Animate stylized characters (anthropomorphic, non-human) robustly under spatial misalignment, enabling quick iterations for shorts or explainer videos.
- Potential tools/workflows: Pipeline hook into Toon Boom/TVPaint; mask generator tuned to stylized art; text guidance to assign motions per character.
- Assumptions/dependencies: Segmentation quality for stylized inputs; domain-specific LoRA fine-tuning; IP/brand usage rights.
- Classroom choreography and PE instruction clips (Education)
- Create short demonstrative videos from class photos showing coordinated movements (e.g., warm-ups, dance steps) driven by a single pose sequence.
- Potential tools/workflows: Teacher-facing web interface with pose libraries; auto mask extraction; captioned prompts for roles/counts.
- Assumptions/dependencies: Consent for student images; pedagogical accuracy of demonstrated motion; school IT constraints and data protection.
- Rapid 2D cinematic assets for game cutscenes (Gaming)
- Generate multi-NPC 2D animatics from one motion driver for early narrative prototyping and pitch materials.
- Potential tools/workflows: Middleware to export sequences into Unity timelines; “assign masks to NPCs” UI; prompt-driven role mapping.
- Assumptions/dependencies: Not a 3D rig animation—output is video; may require blending with 3D assets; legal rights for character art.
- Personalized greetings and event invitations (Daily Life/Consumer)
- Animate a photo of friends/family into a coordinated dance for birthdays, weddings, or invitations.
- Potential tools/workflows: Consumer app with templates; privacy-safe mask editing; shareable exports for messaging platforms.
- Assumptions/dependencies: Clear disclosures and consent; simple UI for non-experts; light-weight inference or cloud processing.
- Synthetic multi-person video datasets for model development (Academia/Computer Vision)
- Generate controlled, labeled multi-subject action sequences to augment training for activity recognition, segmentation, and tracking.
- Potential tools/workflows: Data generation scripts; structured prompts to vary cardinality/layout; synthetic labeling of roles.
- Assumptions/dependencies: Domain gap vs. real footage; ethical use and transparency; dataset documentation and provenance.
- Localized ad variants at scale (Advertising/Localization)
- Produce culturally adapted group animations (different subject counts/appearances) from one motion driver for regional campaigns.
- Potential tools/workflows: Prompt catalogs per locale; mask libraries; automated asset pipeline.
- Assumptions/dependencies: Cultural sensitivity review; brand approvals; content moderation and watermarking.
- Video editing plug-in for multi-subject motion transfer (Software/Creative Tools)
- Drop-in effect to “animate reference group via single motion clip,” with mask picker and prompt-based role binding.
- Potential tools/workflows: Premiere/Resolve plug-in; node in Nuke/Fusion; Python API for batch jobs.
- Assumptions/dependencies: Access to open-source weights; GPU acceleration; user support for mask corrections.
Long-Term Applications
- Real-time multi-avatar animation for live streaming and virtual events (Media/Metaverse)
- Drive multiple avatars in real time from minimal signals (single performer or music beat), with per-avatar semantics and spatial constraints.
- Potential tools/workflows: Low-latency inference on edge GPUs; streaming SDK; live mask tracking; audio-to-pose coupling.
- Assumptions/dependencies: Significant model optimization; robust real-time segmentation; latency <100 ms; content moderation/watermarking.
- Extension to 3D rigs and volumetric avatars (Gaming/AR/VR)
- Map the Unbind–Rebind paradigm to 3D character rigs (skeletal meshes), enabling multi-character 3D animation from 2D or text inputs.
- Potential tools/workflows: Pose-to-rig retargeting layers; 3D mask/part segmentation; DIT variants trained on rigged datasets.
- Assumptions/dependencies: Large 3D motion datasets; new encoders/decoders; domain adaptation to 3D pipelines.
- Autonomous multi-subject choreography generation from text/music only (Entertainment/Tooling)
- Eliminate pose inputs by learning motion priors conditioned on text and audio rhythm to synthesize coordinated group dances.
- Potential tools/workflows: Music-to-motion models; role-wise prompt decomposition; scene-aware occlusion reasoning.
- Assumptions/dependencies: Additional training on diverse music/choreo datasets; safety and copyright of music content.
- Scene-aware, occlusion-robust multi-character animation in complex environments (VFX/Film)
- Integrate depth/order reasoning and background stabilization so multiple subjects interact and occlude realistically.
- Potential tools/workflows: Depth/flow estimators; spatially aligned cross-attention; compositing tool integration.
- Assumptions/dependencies: More training data with complex scenes; improved mask quality; compute-intensive inference.
- Interactive multi-agent authoring tools (Creative Software)
- GUI to assign motions to subjects via masks and prompts, scrub timelines, and fine-tune per-character motion styles.
- Potential tools/workflows: WYSIWYG editor; prompt+mask timelines; style libraries and per-character LoRA slots.
- Assumptions/dependencies: UX research; efficient incremental updates; collaboration features and versioning.
- Enterprise-scale creative pipelines with governance (Enterprise/Policy)
- Large organizations adopt standardized workflows with watermarking, consent tracking, and provenance to mitigate deepfake risks.
- Potential tools/workflows: Trust/traceability (C2PA) integration; automated consent logs; policy-compliant render queues.
- Assumptions/dependencies: Industry standards adoption; legal/ethical reviews; secure model hosting and access controls.
- Group training and rehabilitation visuals (Healthcare/Education)
- Generate tailored multi-subject exercise visuals for group therapy or classroom instruction with role-specific motions.
- Potential tools/workflows: Clinician/teacher dashboards; validated motion libraries; accessibility overlays.
- Assumptions/dependencies: Clinical validation; privacy protections; bias and fairness audits for representations.
- Crowd and extras previsualization (Film/Architecture/Urban Design)
- Quickly prototype crowd movement and staging (extras, audience reactions) from minimal motion drivers for planning and visualization.
- Potential tools/workflows: Layout planners; role distribution via prompts; shot-blocking tools.
- Assumptions/dependencies: Scalable synthesis for high subject counts; realistic temporal consistency; background integration.
Notes on general dependencies and assumptions that cut across applications:
- Availability of open-sourced code/weights and compatible licenses; access to the pretrained DiT backbone (e.g., Wan 2.1) and SAM-like segmentation.
- GPU/accelerator resources for inference and optional fine-tuning (LoRA); potential need for domain-specific LoRA adapters.
- High-quality subject masks and accurate, unambiguous text prompts are critical for reliable “Rebind.”
- Rights, consent, and brand/IP considerations for depicted subjects; adoption of watermarking/provenance to address deepfake risks.
- Domain gaps between synthesized and real footage may affect training or evaluation workflows; careful validation is required for regulated domains (e.g., healthcare, education).
Glossary
- 3D convolutions: Convolutional layers that operate across spatial dimensions and time, enabling models to capture motion dynamics in videos. "such as temporal attention blocks or 3D convolutions"
- Anthropomorphic: Having human-like characteristics or form, often used to describe non-human characters in animation tasks. "non-human / anthropomorphic characters"
- Classifier-free guidance: A conditioning technique for diffusion models that strengthens adherence to input conditions without a separate classifier. "For conditional generation, classifier-free guidance is often used to strengthen the influence of the condition ."
- ControlNet: An architecture that adds conditional control (e.g., keypoints) to diffusion models to guide generation. "ControlNet-style keypoint guidance"
- Cross-attention: An attention mechanism that conditions one sequence on another (e.g., text on video tokens) to inject external guidance. "via the cross-attention layers within the DiT blocks"
- Cross-frame coherence: The consistency of appearance and structure across consecutive video frames. "to enforce cross-frame coherence and suppress jitter"
- Depth order: The relative front-to-back arrangement of objects in a scene, used to reason about occlusions and layering. "depth-order"
- Diffusion Models: Generative models that synthesize data by learning to reverse a noise-adding process. "Diffusion Models are generative models that learn to create data by reversing a noise-adding process."
- Diffusion Transformer (DiT): A transformer-based diffusion architecture that tokenizes inputs and predicts noise over sequences. "Diffusion Transformers (DiT) demonstrated that a standard Transformer can serve as a highly effective and scalable backbone."
- Element-wise addition: Combining two tensors by adding corresponding elements, often used to inject conditioning signals. "are added element-wise to the noisy latent."
- Feature Unbind: A training module that perturbs pose features to prevent models from relying on rigid spatial correspondence. "Feature Unbind module"
- FID (Fréchet Inception Distance): A distribution-level metric comparing real and generated data via feature statistics from an Inception network. "we further measure FID \cite{heusel2017gans}, FID-VID \cite{balaji2019conditional}, and FVD \cite{unterthiner2018towards}, capturing the gap between synthesized and real video distributions."
- FID-VID: A video-oriented variant of FID that evaluates distributional realism for videos. "we further measure FID \cite{heusel2017gans}, FID-VID \cite{balaji2019conditional}, and FVD \cite{unterthiner2018towards}, capturing the gap between synthesized and real video distributions."
- FVD (Fréchet Video Distance): A metric measuring distributional similarity between real and generated videos using spatiotemporal features. "we further measure FID \cite{heusel2017gans}, FID-VID \cite{balaji2019conditional}, and FVD \cite{unterthiner2018towards}, capturing the gap between synthesized and real video distributions."
- Hallucination (in generative models): The model invents content not present in the input or reference, often due to misalignment. "it hallucinates a new, pose-aligned person in the corresponding spatial region."
- Identity drift: Deviation of a subject’s appearance over time or frames, leading to loss of identity consistency. "yet often suffer from texture distortion, identity drift, and temporal flicker"
- Latent features: Internal feature representations in a compressed space used by generative models. "introducing stochastic perturbations to both poses and their latent features"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique injecting learnable low-rank matrices into attention layers. "Fine-tuning is performed exclusively on newly introduced Low-Rank Adaptation (LoRA) layers"
- LPIPS (Learned Perceptual Image Patch Similarity): A perceptual metric that correlates with human judgments of image similarity using deep features. "we report PSNR \cite{hore2010image}, SSIM \cite{wang2004image}, L1, and LPIPS \cite{zhang2018unreasonable}, which are standard indicators of perceptual fidelity and distortion."
- Mask Encoder: A network that encodes segmentation masks into features to spatially guide generation. "a Mask Encoder, consisting of stacked 2D convolutional layers."
- Mixed-data training: Training that alternates between different datasets or tasks to improve generalization and conditioning robustness. "we propose a mixed-data training strategy."
- Occlusions: Situations where one object blocks another from view, complicating motion and appearance modeling. "to stabilize backgrounds and handle occlusions"
- Optical flow: A dense field describing per-pixel motion between frames, used for motion reasoning or supervision. "using optical-flow, depth-order, and reference-pose guiders"
- Patchified tokens: Image or video inputs split into non-overlapping patches and embedded as tokens for transformer processing. "These are concatenated with patchified tokens from the noisy latent input for the DiT backbone."
- Pixel-wise alignment: Strict spatial correspondence enforced at the level of individual pixels between conditioning and target signals. "forces strict pixel-wise alignment"
- Pose encoder: A neural module that extracts pose features from keypoints or pose images for conditioning generative models. "pose encoder and the diffusion network"
- Pose shift encoder: A specialized encoder that applies stochastic pose perturbations to learn location-agnostic motion features. "we propose a novel pose shift encoder"
- PSNR (Peak Signal-to-Noise Ratio): A distortion-based metric measuring fidelity between generated and reference frames. "we report PSNR \cite{hore2010image}, SSIM \cite{wang2004image}, L1, and LPIPS \cite{zhang2018unreasonable}, which are standard indicators of perceptual fidelity and distortion."
- SAM (Segment Anything Model): A general-purpose segmentation model used to obtain subject masks for spatial guidance. "we employ an offline segmentation model (e.g., SAM)"
- Semantic guidance: Conditioning that uses text or labels to specify what content should be generated or animated. "leveraging semantic guidance from text prompts"
- Spatial misalignment: A mismatch in spatial arrangement between conditioning inputs (e.g., pose) and the reference image. "spatial misalignment between the reference image and the driving poses."
- Spatial rebind: A mechanism to re-associate motion with specific regions or subjects using spatial constraints. "we introduce a spatial rebind mechanism"
- SSIM (Structural Similarity Index): A perceptual quality metric assessing structural similarity between images. "we report PSNR \cite{hore2010image}, SSIM \cite{wang2004image}, L1, and LPIPS \cite{zhang2018unreasonable}, which are standard indicators of perceptual fidelity and distortion."
- Subject masks: Segmentation masks that delineate specific subjects to localize where motion should be applied. "subject masks to direct the learned motion to intended characters."
- Temporal adapters: Lightweight modules that inject temporal modeling into image backbones for video generation. "with lightweight temporal adapters"
- Temporal attention: Attention mechanisms extended across time to capture dependencies between frames. "temporal attention blocks"
- Temporal consistency: The stability of appearance and structure over time in a generated video. "frames must evolve smoothly and remain temporally consistent"
- U-Net: A convolutional encoder–decoder architecture historically used in diffusion models for image/video generation. "abandons the U-Net in favor of transformer diffusion backbones"
- umT5: A text encoder variant used for extracting semantic features to guide video generation. "semantic features from a umT5 text encoder are injected via cross-attention"
- VAE (Variational Autoencoder): A generative model with an encoder–decoder that learns a latent space for reconstruction and synthesis. "A VAE encoder extracts the latent feature from ."
- ViT (Vision Transformer): A transformer architecture for images that operates on patch tokens. "similar to a Vision Transformer (ViT)."
Collections
Sign up for free to add this paper to one or more collections.