Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning
Abstract: Vision-as-inverse-graphics, the concept of reconstructing an image as an editable graphics program is a long-standing goal of computer vision. Yet even strong VLMs aren't able to achieve this in one-shot as they lack fine-grained spatial and physical grounding capability. Our key insight is that closing this gap requires interleaved multimodal reasoning through iterative execution and verification. Stemming from this, we present VIGA (Vision-as-Inverse-Graphic Agent) that starts from an empty world and reconstructs or edits scenes through a closed-loop write-run-render-compare-revise procedure. To support long-horizon reasoning, VIGA combines (i) a skill library that alternates generator and verifier roles and (ii) an evolving context memory that contains plans, code diffs, and render history. VIGA is task-agnostic as it doesn't require auxiliary modules, covering a wide range of tasks such as 3D reconstruction, multi-step scene editing, 4D physical interaction, and 2D document editing, etc. Empirically, we found VIGA substantially improves one-shot baselines on BlenderGym (35.32%) and SlideBench (117.17%). Moreover, VIGA is also model-agnostic as it doesn't require finetuning, enabling a unified protocol to evaluate heterogeneous foundation VLMs. To better support this protocol, we introduce BlenderBench, a challenging benchmark that stress-tests interleaved multimodal reasoning with graphics engine, where VIGA improves by 124.70%.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
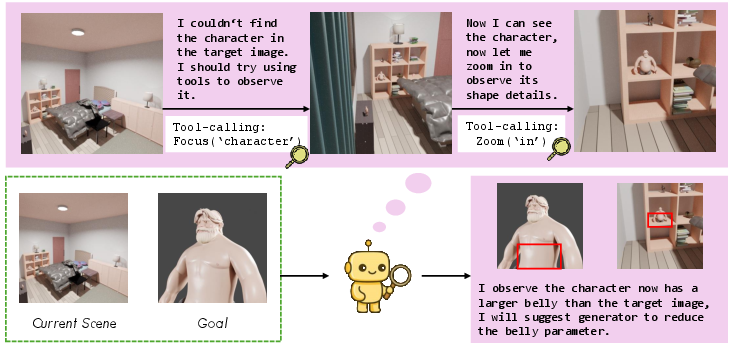
This paper introduces VIGA, a smart computer agent that can look at a picture and recreate the scene as a 3D world using code. Think of it like seeing a photo of a room and then writing step-by-step instructions to build that room inside a game or animation tool (like Blender). The big idea is “vision-as-inverse-graphics,” which means figuring out the recipe (the code) from the finished cake (the image), so the scene becomes editable and understandable.
Objectives: What were the researchers trying to do?
The researchers wanted to:
- Turn images into editable 3D scenes by writing and fixing code, not just guessing the scene in one try.
- Build an agent that can think with both pictures and text by constantly checking its work and improving it.
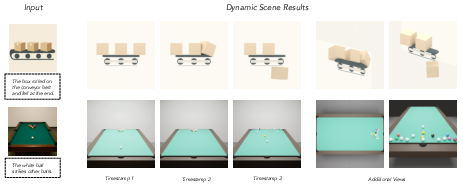
- Make this process work for many tasks, like 3D scene building, animations with physics (4D), and even designing slides (2D), without needing to retrain the agent for each task.
- Create tests to measure how well different AI models can do this kind of visual thinking and coding.
Methods: How does VIGA work?
VIGA uses a simple “do-check-fix” loop. Imagine you’re rebuilding a LEGO scene from a photo:
- You write instructions (code) to place blocks.
- You build it and take a picture (render).
- You compare your picture to the original photo.
- You fix your instructions and try again.
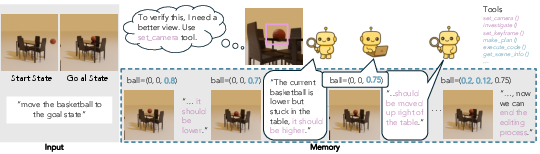
In the paper, this loop is called write → run → render → compare → revise.
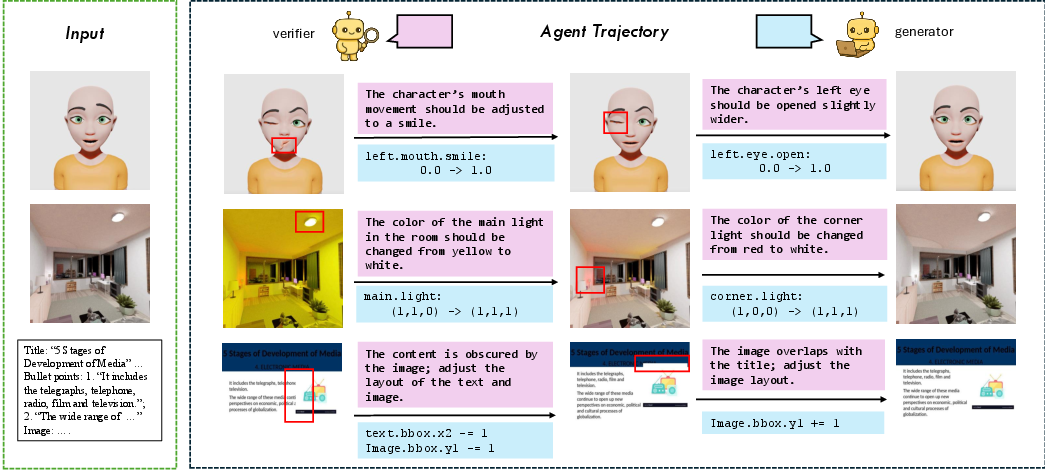
To make this work well, VIGA has two “roles” and two helpful parts:
- Roles:
- Generator: Writes and edits the code that builds the scene.
- Verifier: Looks at the rendered scene from different camera angles, finds what’s off (like wrong lighting or object position), and explains what to fix next.
- Helpful parts:
- Skill library (toolbox): A set of tools like “set_camera” (move the camera), “investigate” (look around the scene with simple commands like “zoom out”), “make_plan” (outline steps before editing), and “execute_code” (run the code to update the scene).
- Context memory (notebook): A short history that stores plans, code changes, and renders. This helps the agent remember what it did and why, without becoming too long and confusing.
By switching between writing code and checking visuals, VIGA “thinks with a graphics engine,” not just with words or 2D pictures. It also works with different AI models and doesn’t need special training for each new task.
Findings: What did the agent achieve and why is it important?
VIGA improved results across several benchmarks and tasks:
- BlenderGym (3D scene editing): About 35% better than one-shot methods on average.
- SlideBench (slide design with code): About 117% better on average, especially because it can recover from code errors by learning from feedback.
- BlenderBench (a new, harder test designed by the authors): About 125% improvement, especially in tasks that need changing camera views, making multiple edits, and combining many steps.
Why this matters:
- Many AI systems struggle to get every detail right in one try. VIGA succeeds by iterating—building, checking, and fixing—like a careful artist or engineer.
- It works across 2D (slides), 3D (scenes), and 4D (animations with time and physics), showing it’s flexible.
- It’s model-agnostic, meaning you can swap in different AI models without retraining, which makes testing and comparing them easier.
Implications: What could this change?
This approach could help:
- Robotics and simulation: Create realistic training worlds to teach robots safely.
- Movies and games: Quickly turn concept art into editable 3D scenes.
- Digital twins: Build editable virtual copies of real places for planning and analysis.
- Education and content creation: Write code for clear, well-organized slides and graphics, and fix mistakes automatically.
The authors note challenges still exist, like limits in the base AI models’ abilities and the difficulty of keeping long, complex edits organized. But as AI vision-LLMs and graphics tools get better, this “do-check-fix” loop should unlock deeper, more accurate visual understanding and make it easier to build and edit complex scenes from simple inputs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points identify what is missing, uncertain, or left unexplored in the paper and suggest concrete directions for future work:
- Quantitative 3D/4D accuracy: No metrics for geometry (e.g., Chamfer/IoU on meshes), camera pose error, material/BRDF fidelity, or physics compliance; evaluations rely on PL/N-CLIP and a subjective VLM Score.
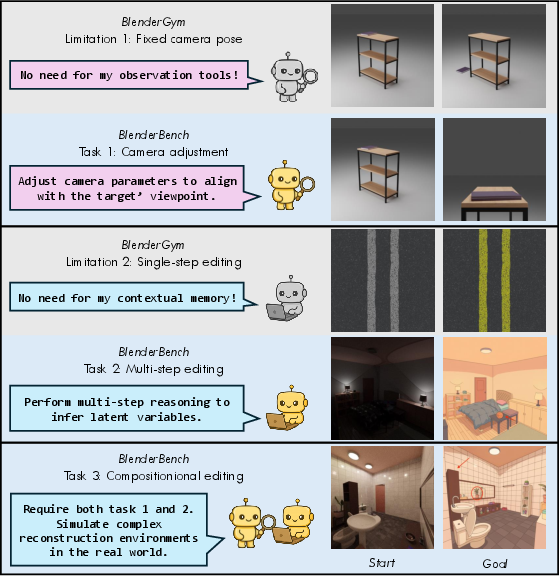
- Benchmark scale and diversity: BlenderBench has only 30 curated instances and mostly synthetic scenarios; expand to larger, more diverse, real-image tasks with occlusion, clutter, specular materials, and complex layouts.
- Single-view reconstruction assumption: Reconstruction from a single image is demonstrated without exploring multi-view/video inputs or how multi-view constraints improve camera/geometry estimation.
- Verifier precision: Natural-language camera control (“investigate”) lacks numeric grounding; introduce algorithmic camera optimization/search (e.g., PnP, gradient-based refinement, view-planning) and quantify control error.
- Memory design and scaling: The sliding-window context is heuristic; ablate window size L, test retrieval-augmented memory, program-diff compression, hierarchical scene state, and tool-call indexing to sustain long horizons.
- Convergence/stopping criteria: The loop’s termination (end_process) is ad hoc; define discrepancy metrics, convergence diagnostics, stopping rules, and analyze stability guarantees for AbS iterations.
- Component ablations: Missing systematic ablations of planning, verification tools, memory, best-of sampling, and CLIP-based candidate selection to isolate their contributions.
- Efficiency and cost: No reporting of iteration counts, wall-clock time, token usage, or compute overhead; provide budgeted performance curves and latency breakdowns per tool/action.
- Asset generation dependency: get_better_assets relies on unspecified external generators; detail models, quality control, licensing, failure modes, and a standardized asset API/dataset for reproducibility.
- Physics grounding: 4D scenes are evaluated qualitatively; define metrics for contact events, energy/momentum conservation, friction, and collision realism; benchmark physics parameter estimation from images.
- Robustness and safety: Executing model-generated code in Blender lacks sandboxing and security discussion (prompt injection, malicious code, environment determinism); establish secure execution and versioning protocols.
- Cross-engine generalization: Method is Blender-specific; assess portability to Unity/Unreal/Omniverse and propose engine-agnostic tool abstractions.
- Comparative baselines: No comparison to differentiable inverse rendering, optimization-based camera/lighting recovery, or neuro-symbolic program synthesizers under matched tasks.
- Failure mode taxonomy: Limited analysis of where VIGA fails (fine geometry, occlusion, specularities, clutter, long-horizon drift); compile quantitative error categories and prevalence.
- Metric validity: VLM Score (0–5) is subjective; define rating rubric, rater training, and inter-rater reliability; conduct blind human studies.
- CLIP-based selection bias: Best-of candidate selection via CLIP may conflict with PL/3D accuracy; evaluate multi-view scoring, geometry-aware metrics, and hybrid selection strategies.
- Downstream utility: Claims for robotics training/digital twins are not validated; run end-to-end studies measuring sim-to-real transfer, data efficiency, and fidelity requirements.
- Camera intrinsics/extrinsics estimation: No explicit algorithmic recovery; integrate geometric estimators (solvePnP, vanishing points) and quantify accuracy.
- Scene complexity: Unclear performance on large scenes (hundreds of objects, hierarchies, rigging); stress-test scalability and tool orchestration strategies.
- 2D document generalization: PowerPoint is the only 2D format; evaluate on LaTeX, Figma, SVG with layout constraints, accessibility, and semantic correctness.
- Auxiliary modalities: The agent does not leverage depth, segmentation, or scene graphs; study how optional modalities can boost verification/synthesis while preserving task-agnosticity.
- Tool determinism/calibration: Map language camera commands to numeric parameters with known precision; measure and calibrate tool accuracy across scenes.
- Data release details: Specify BlenderBench asset sources, licenses, generation scripts, annotation protocols, and provide full reproducible artifacts.
- Learning from traces: The proposed use of execution-grounded data to train models is not realized; define training pipelines (supervised/RL/feedback learning) and measure gains.
- API heterogeneity: Tool-calling differences across closed/open models affect reliability; quantify impact and propose a standardized, model-agnostic tool-call schema.
- Occlusion/visibility handling: set_visibility relies on manual targeting; add automatic object localization in clutter via detection/scene graphs to drive visibility control.
- Reproducibility and stochasticity: Blender versions, random seeds, and physics determinism are not reported; include sensitivity analyses and reproducibility controls.
- Search/planning policy: Generator–Verifier sequencing is heuristic; explore tree search, RL policies, or curricula to reduce edits and improve convergence.
- Material/lighting evaluation: PL conflates geometry and appearance; add metrics for light position/intensity, color temperature, and photometric consistency under relighting.
- Numeric parameterization: Bridging natural-language feedback to precise code values is underspecified; test learned parameter regressors or numeric optimization wrappers.
- Human-in-the-loop: No interactive correction studies; quantify how minimal human hints or constraints improve speed, accuracy, and reliability.
Practical Applications
Below is an overview of practical applications that follow directly from the paper’s findings, methods, and innovations. Each item includes sector(s), potential tools/products/workflows, and assumptions/dependencies that affect feasibility.
Immediate Applications
- Bold: Blender inverse-graphics assistant for scene editing and reconstruction from single images
- Sectors: software, media/entertainment (VFX/animation), product visualization, architecture/interior design
- Tools/products/workflows: a VIGA-powered Blender add-on that alternates generator/verifier roles, uses write→run→render→compare→revise, leverages tools like make_plan, execute_code, set_camera, investigate, and get_better_assets for asset retrieval; code-diff driven scene updates and multi-view verification
- Assumptions/dependencies: foundation VLM with reliable tool-calling and multimodal reasoning; Python-accessible graphics engine (Blender) and basic asset libraries; acceptance of approximate geometry/materials in early iterations; sandboxed code execution for security
- Bold: Slide generation co-pilot with iterative verification (python-pptx)
- Sectors: education, enterprise productivity, marketing/communications
- Tools/products/workflows: Office/PowerPoint plugin that generates slide programs from instructions, auto-detects layout/content/color/overlap issues via verification, recovers from execution errors and refines code based on error logs and render feedback
- Assumptions/dependencies: access to python-pptx execution sandbox; VLM robustness to long-context reasoning; organizational standards for style and branding; data privacy/compliance for embedded images
- Bold: Synthetic dataset bootstrapping with programmatic labels
- Sectors: academia (computer vision research), software (ML data ops), robotics
- Tools/products/workflows: reconstruct approximate scenes from real images to produce editable programs; render diverse views with known camera/geometry/material parameters to auto-generate labels (depth, segmentation, 3D boxes) for training; iterative loop to reduce distribution gap via visual comparison
- Assumptions/dependencies: tolerance for distribution shift due to approximate reconstructions; compute for large-scale rendering; CLIP/VLM-based verification adequacy; licensing for any third-party assets used
- Bold: Foundation-model spatial reasoning evaluation via BlenderBench
- Sectors: academia (benchmarking), AI platforms, procurement/governance
- Tools/products/workflows: Benchmark-as-a-Service using BlenderBench tasks (camera adjustment, multi-step edits, compositional edits); unified protocol to compare heterogeneous VLMs without finetuning; scoring via PL, N-CLIP, and VLM Score
- Assumptions/dependencies: standardized test environments and metrics; consistent tool-call interfaces; governance processes to interpret scores for model selection
- Bold: Rapid robotics simulation prototyping from single images and text
- Sectors: robotics, industrial R&D, logistics
- Tools/products/workflows: VIGA builds 4D scenes with basic physics properties (e.g., rigid bodies, keyframes) from a reference image and instruction; quick scenario setup for training/evaluation; camera control to probe visibility and occlusions
- Assumptions/dependencies: physics fidelity limited by graphics engine (e.g., Blender) vs. dedicated simulators; integration with robotics simulators (PyBullet, Isaac Gym) may need adapters; human-in-the-loop validation for safety-critical scenarios
- Bold: Asset QA and material tuning in product visualization pipelines
- Sectors: e-commerce, industrial design, advertising
- Tools/products/workflows: verification agent identifies mismatches in materials, lighting, and placement relative to target references; generator updates code parameters and replaces assets via get_better_assets; iterative quality loop before publishing visuals
- Assumptions/dependencies: reliable visual discrepancy detection by the base VLM; asset licensing/management; consistent rendering settings across iterations
- Bold: Sketch-to-3D “blockout” for makers and design education
- Sectors: education, maker community, industrial design
- Tools/products/workflows: convert stylized drawings into editable scene programs for rapid blockouts; multi-view inspection to refine proportions and layout; export to downstream CAD or printing workflows
- Assumptions/dependencies: tolerance for coarse geometry; downstream conversion from Blender meshes to CAD formats; manual corrections for manufacturability
- Bold: Document layout auditing and remediation
- Sectors: enterprise compliance, education, publishing
- Tools/products/workflows: agent detects missing text, overlaps, color and alignment issues in slides/documents; proposes code edits that restore style guide adherence
- Assumptions/dependencies: access to style guide specifications; VLM’s ability to parse and apply layout rules; permissioned handling of internal documents
Long-Term Applications
- Bold: Code-grounded digital twins for interpretable simulation and robotics training
- Sectors: manufacturing, smart buildings, autonomous systems
- Tools/products/workflows: reconstruct facility or workspace visuals as executable scene programs with materials, lighting, and physics; use iterative AbS to align simulation renders with operational imagery; structured memory keeps long-horizon edits consistent; plug-ins for industrial simulators (Isaac Sim, Unity/Unreal)
- Assumptions/dependencies: scaling to complex multi-room/multi-asset environments; higher-fidelity geometry and physics; standardized data pipelines and safety validation; stronger VLM spatial reasoning and memory beyond sliding windows
- Bold: AR/VR content authoring from photos/drawings with physics-aware occlusion
- Sectors: AR/VR, gaming, experiential marketing
- Tools/products/workflows: transform 2D inputs into parameterized 3D/4D scenes for headset/runtime engines; support real-time verification loops; auto-tune camera poses and lighting to blend virtual content into real scenes
- Assumptions/dependencies: real-time inference constraints; engine-specific integrations (Unity, Unreal); improved occlusion and material realism; privacy considerations when reconstructing real spaces
- Bold: End-to-end robot autonomy co-pilot that “thinks with a graphics engine”
- Sectors: robotics, warehousing, last-mile delivery
- Tools/products/workflows: interleaved perception→simulation→program-edit loops to hypothesize scene state, test plans, and verify outcomes; persistent memory to carry context across missions; integration with task planners and control stacks
- Assumptions/dependencies: tighter coupling with sensor streams; robust online updates; stronger physical grounding; formal guarantees for safety and reliability
- Bold: Film/game previsualization from storyboard or concept art to parameterized scenes
- Sectors: media/entertainment, game development
- Tools/products/workflows: pipeline that converts art boards into scene programs, iteratively tunes camera, lighting, and layout to match creative intent; cross-engine exporters; collaborative memory across multi-artist iterations
- Assumptions/dependencies: higher accuracy in style/material reproduction; interoperable asset formats; human-in-the-loop creative direction; IP/licensing clarity for generated assets
- Bold: Automated compliance and safety checking in simulated environments
- Sectors: architecture/engineering/construction (AEC), occupational safety, policy/regulation
- Tools/products/workflows: generate scenes that reflect as-built conditions; encode checks (clearances, lighting, signage) as program rules; verification agent highlights violations and proposes edits; audit trails via code diffs and render history
- Assumptions/dependencies: authoritative codification of standards into machine-readable rules; validated mapping from visual cues to compliance metrics; governance for automated recommendations
- Bold: Execution-grounded training data and curricula for next-gen multimodal agents
- Sectors: academia, AI platform providers
- Tools/products/workflows: use AbS trajectories (plans, code diffs, renders, verification feedback) as supervision signals to pretrain agents for spatial reasoning, tool use, and long-horizon memory; standardized datasets (BlenderBench extensions)
- Assumptions/dependencies: scalable data generation pipelines; open benchmarks and licensing; model architectures that leverage execution traces; ethical use of synthetic data
- Bold: Real-time collaborative design copilots with durable memory and code provenance
- Sectors: product design, UX, AEC
- Tools/products/workflows: multi-user agent that retains evolving context memory across long sessions, surfaces code diffs and render histories, supports role-based tooling (generator/verifier), and integrates with source control for scene programs
- Assumptions/dependencies: richer memory mechanisms (beyond sliding window); identity/permission systems; conflict resolution and versioning; UI/UX for human–agent collaboration
- Bold: Enterprise AI governance using interleaved multimodal tests for model certification
- Sectors: finance/insurance (model risk), public sector procurement, regulated industries
- Tools/products/workflows: adopt BlenderBench-like tasks to certify spatial reasoning and tool-use reliability before deployment; scorecards for model selection and updates; continuous monitoring via AbS task suites
- Assumptions/dependencies: consensus on evaluation protocols; integration with MLOps compliance workflows; reproducible environments; transparency around closed-source model behavior
These applications leverage VIGA’s core strengths—interleaved multimodal reasoning, executable scene programs, tool-assisted verification, and evolving memory—while acknowledging current limitations such as dependence on base VLM capabilities, approximate physical/geometry fidelity, context length constraints, and the need for secure, sandboxed execution. As foundation models and asset-generation tools improve, these workflows can be scaled and hardened for broader real-world deployment.
Glossary
- 4D physical interaction: The modeling of dynamic scenes over time with physical properties and motions. "covering a wide range of tasks such as 3D reconstruction, multi-step scene editing, 4D physical interaction, and 2D document editing, etc."
- analysis-by-synthesis (AbS): An iterative approach that synthesizes outputs, compares them to targets, and refines the process based on discrepancies. "As a VLM agent, VIGA operates through an iterative analysis-by-synthesis (AbS) loop."
- agentic: Describing systems that act autonomously as agents, planning and making decisions in a loop. "From a modern agentic perspective, this analysis-by-synthesis loop is also a direct instantiation of interleaved multimodal reasoning."
- best-of-N: An evaluation protocol where multiple outputs are generated and the best-performing one is selected. "We report the best-of- performance, where denotes the number of samples generated per instruction."
- BlenderBench: A benchmark designed to stress-test agents’ interleaved multimodal reasoning and compositional editing in Blender. "We release BlenderBench, a challenging benchmark for agentic inverse graphics to stress-test real-world scenarios"
- BlenderGym: A benchmark for programmatic 3D graphics editing tasks within Blender. "We first evaluate programmatic 3D graphic editing on BlenderGym"
- camera intrinsics/extrinsics: Intrinsics are the internal camera parameters; extrinsics specify the camera’s pose relative to the world. "camera intrinsics/extrinsics, object pose/scale, layout"
- compositional graphic editing: Multi-step editing that composes several spatial and visual changes within a scene. "compositional graphic editing."
- compositional scene representations: Structured, interpretable scene descriptions that can be manipulated and recombined. "compositional scene representations that can be easily manipulated or simulated"
- differentiable renderers: Rendering systems that allow gradients to flow through the rendering process for optimization. "The perceptual verification process of VIGA requires no auxiliary predictors or differentiable renderers"
- digital twins: Virtual replicas of physical systems or environments used for analysis or simulation. "applications like robot training or creating interpretable digital twins."
- evolving context memory: A dynamic memory that accumulates plans, code, and feedback across iterations to support long-horizon reasoning. "an evolving context memory that contains plans, code diffs, and render history."
- execution accuracy: The rate at which generated programs execute successfully without errors. "We report execution accuracy, reference-based, reference-free, and overall score."
- execution-grounded: Grounded in actual program execution and its outcomes, rather than only static predictions. "viewing analysis-by-synthesis as an execution-grounded closed loop."
- finetuning: Additional training of a model on task-specific data to adapt its behavior. "VIGA is also model-agnostic as it doesn't require finetuning"
- foundation VLMs: Large, general-purpose vision-LLMs used as base models across tasks. "heterogeneous foundation VLMs."
- interleaved multimodal reasoning: Alternating reasoning across different modalities (e.g., code, images) and actions within an iterative loop. "closing this gap requires interleaved multimodal reasoning through iterative execution and verification."
- keyframes: Specific frames on a timeline that define important states in an animation. "navigate along the timeline in 4D scenes to inspect different keyframes and motion phases."
- latent variables: Hidden or unobserved factors inferred from data (e.g., lighting conditions) that affect scene appearance. "performing reasoning to infer latent variables like lighting or occluded states"
- long-horizon reasoning: Planning and executing over many steps while maintaining coherence and context. "To support long-horizon reasoning, VIGA combines (i) a skill library... and (ii) an evolving context memory"
- memory-less: An approach that does not retain or use state from previous iterations. "BlenderAlchemy~... a memory-less variant of VIGA."
- model-agnostic: Designed to work with different underlying models without needing changes. "VIGA is also model-agnostic, as it does not require finetuning."
- Negative-CLIP Score (N-CLIP): A semantic alignment metric derived from CLIP; lower values indicate better alignment in this setup. "We report Photometric Loss (PL, pixel-level difference) and Negative-CLIP Score (N-CLIP, semantic alignment)."
- occluded states: Scene conditions where objects are partially or fully hidden behind others. "infer latent variables like lighting or occluded states"
- one-shot: A single-pass generation or decision without iterative refinement. "a one-shot code generation approach currently cannot produce accurate reconstructions"
- Photometric Loss (PL): A pixel-wise difference metric measuring visual discrepancy between images. "We report Photometric Loss (PL, pixel-level difference)"
- probabilistic programming: A programming paradigm where models include probability distributions and inference is performed over them. "introduced a probabilistic programming framework for representing arbitrary 2D and 3D scenes"
- procedure content generation approaches: Rule-driven methods that generate visual content procedurally (not via learned analysis). "procedure content generation approaches rely on predefined rules to generate specific 3D content."
- reference-based metrics: Evaluation measures that compare outputs directly against reference targets. "We report execution accuracy, reference-based, reference-free, and overall score."
- reference-free metrics: Evaluation measures that assess outputs without a ground-truth reference, often using heuristic or learned criteria. "We report execution accuracy, reference-based, reference-free, and overall score."
- rigging: Setting up skeletal structures and controls to animate 3D models. "novel tasks like rigging and physics simulator without any finetuning."
- skill library: A curated set of tools that the agent can invoke for generation and verification. "a skill library of generation and verification tools"
- sliding window: A memory management tactic that retains only the most recent fixed number of iterations. "we implement a fixed-size sliding window of size that retains the most recent iterations"
- tool-assisted: Processes that explicitly involve invoking external tools or APIs to perform subtasks. "this is a tool-assisted process."
- Verifier: An agent role responsible for inspecting the current scene and providing feedback for revision. "Subsequently, a Verifier inspects against the reference to generate visual feedback ."
- Vision-as-inverse-graphics: The perspective of reconstructing an image as an editable graphics program. "Vision-as-inverse-graphics, the concept of reconstructing an image as an editable graphics program"
- Vision-LLM (VLM): A model that jointly processes visual and textual inputs to perform tasks. "vision-LLMs (VLMs)"
- vision-language grounding: Linking linguistic descriptions to precise visual or spatial parameters. "fine-grained vision-language grounding for spatial and physical parameters"
- VLM Score: A 0–5 rating by a VLM for task completion, visual quality, and spatial accuracy. "we introduce a VLM Score (0â5 scale) to rate task completion, visual quality, and spatial accuracy."
- zero-shot: Performing a task without any task-specific training or finetuning. "operates in a zero-shot setting"
Collections
Sign up for free to add this paper to one or more collections.