Building Production-Ready Probes For Gemini
Abstract: Frontier LLM capabilities are improving rapidly. We thus need stronger mitigations against bad actors misusing increasingly powerful systems. Prior work has shown that activation probes may be a promising misuse mitigation technique, but we identify a key remaining challenge: probes fail to generalize under important production distribution shifts. In particular, we find that the shift from short-context to long-context inputs is difficult for existing probe architectures. We propose several new probe architecture that handle this long-context distribution shift. We evaluate these probes in the cyber-offensive domain, testing their robustness against various production-relevant shifts, including multi-turn conversations, static jailbreaks, and adaptive red teaming. Our results demonstrate that while multimax addresses context length, a combination of architecture choice and training on diverse distributions is required for broad generalization. Additionally, we show that pairing probes with prompted classifiers achieves optimal accuracy at a low cost due to the computational efficiency of probes. These findings have informed the successful deployment of misuse mitigation probes in user-facing instances of Gemini, Google's frontier LLM. Finally, we find early positive results using AlphaEvolve to automate improvements in both probe architecture search and adaptive red teaming, showing that automating some AI safety research is already possible.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Building Production-Ready Probes for Gemini”
What is this paper about?
This paper is about making smart, low-cost “detectors” that sit inside Google’s Gemini AI to spot harmful requests—especially cyber-attack instructions—before the model answers them. These detectors are called “activation probes.” The team explains how they built probes that are good enough to use in real products, and how they made them work even when the user’s input is very long or looks different from what the probe saw during training.
What questions were the researchers trying to answer?
The team focused on a few practical questions:
- How can we build probes that still work when inputs change—like moving from short questions to very long documents or multi-turn chats?
- Which probe designs work best for catching cyber-offensive prompts without flagging harmless ones?
- Can we combine a cheap probe with a more powerful (but expensive) LLM to get great accuracy at a low cost?
- Can we use automation (like AlphaEvolve) to invent better probe designs and stronger tests?
- Will these probes actually work well enough to deploy in real, user-facing Gemini systems?
How did they do it? (Explained in everyday language)
Think of the AI model as a big brain. When it reads text, its “neurons” light up in patterns called activations. A probe is a small tool that watches these activations to decide: “Does this look harmful?”
- What is an “activation probe”? It’s like a metal detector at an airport. The main AI is the airport; the probe is the detector that checks if something dangerous is coming through. The probe is fast and cheap because it uses information the AI already produced (its “activations”), instead of calling another full AI to judge every message.
- What is a “distribution shift”? That’s when the real-world inputs are different from what the detector saw in practice runs. For example, training on short messages but seeing a huge, multi-file codebase plus a question. Probes often struggle here—especially with long inputs.
- What kinds of probe designs did they test?
- Linear probes: very simple—like averaging the signal and deciding.
- Attention probes: focus on the most relevant parts of the text.
- MultiMax: instead of averaging many signals (which can get “watered down” in long inputs), it grabs the strongest signal in a few places—like a scanner that keeps the loudest beep.
- Max of Rolling Means (with Attention): slide a small window across the text, average what’s inside (weighted by attention), and then take the maximum—like scanning the text in chunks and keeping the worst (most dangerous) chunk.
- Cascading classifier (two-step safety check): First, the cheap probe checks a request. If it’s very confident, we act on that. If it’s unsure, we ask a stronger (but more expensive) LLM to make the final decision. This is like a security guard who only calls in a supervisor for tricky cases.
- Automated help (AlphaEvolve): They used a system to automatically search for better probe designs and to generate stronger “attacks” for testing. This helps speed up safety research.
- Data and testing:
- Harmless prompts that could be mistaken for attacks (like learning about past security incidents),
- Multi-turn chats,
- Very long inputs (like big code repositories attached),
- Real cyber-attack prompts,
- “Jailbreaks” that try to trick the AI, including adaptive ones designed by another AI.
They also cared a lot about not over-triggering on harmless stuff, so their scoring heavily penalized false alarms on benign inputs.
What did they find, and why does it matter?
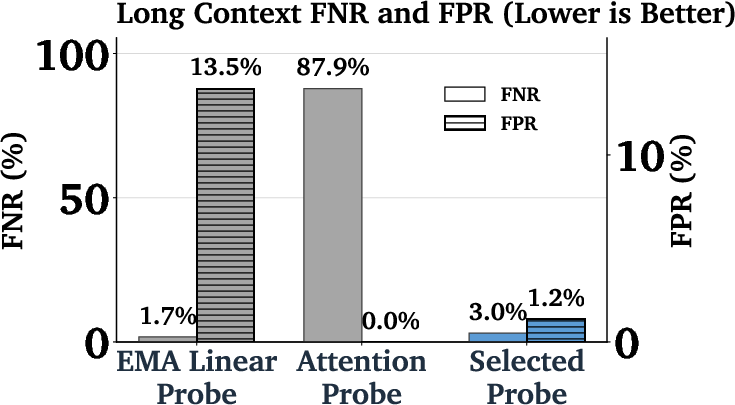
- Better probe designs matter a lot: The new MultiMax and “Max of Rolling Means + Attention” probes did much better on very long inputs than older designs. This is important because long, complex prompts are common in real life (think: long chats or big codebases).
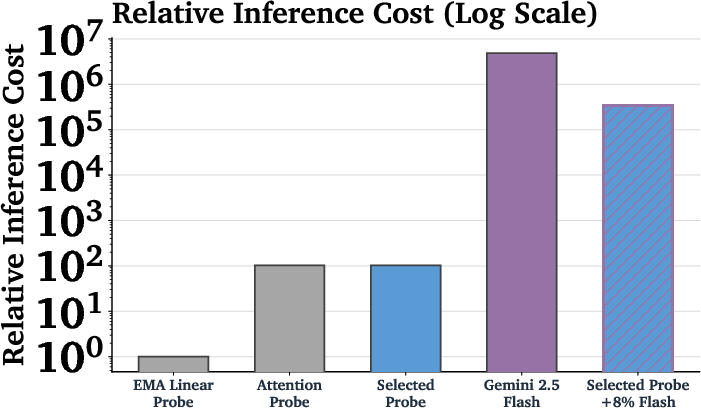
- Training only on short inputs can still work—if your design is right: Training probes directly on million-token inputs is possible but about 22× more expensive. The team showed that smart designs can avoid that cost and still work well on long inputs.
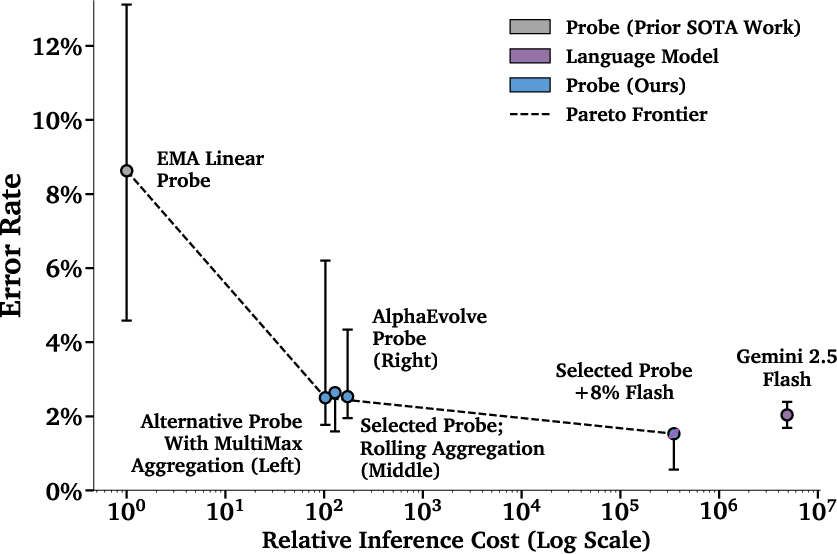
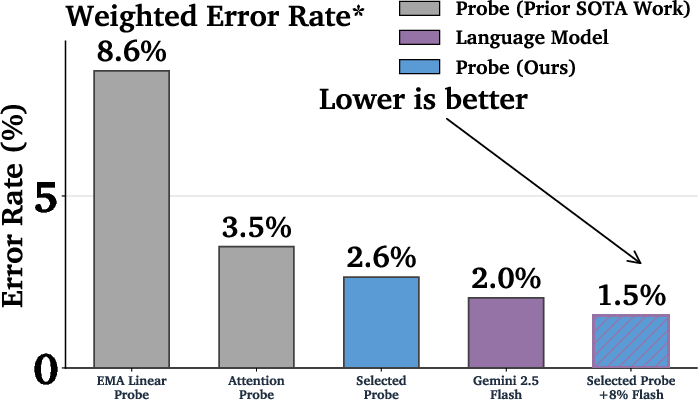
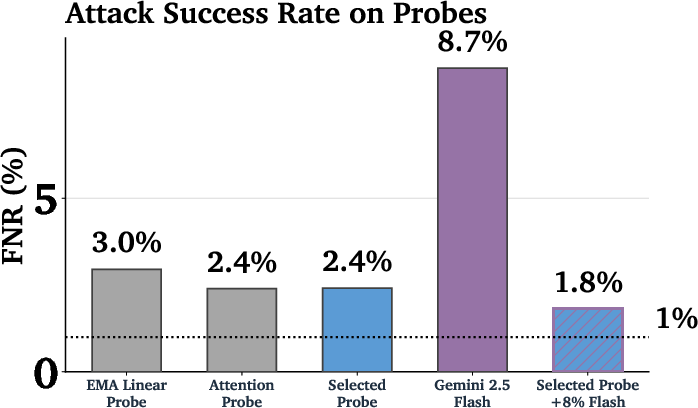
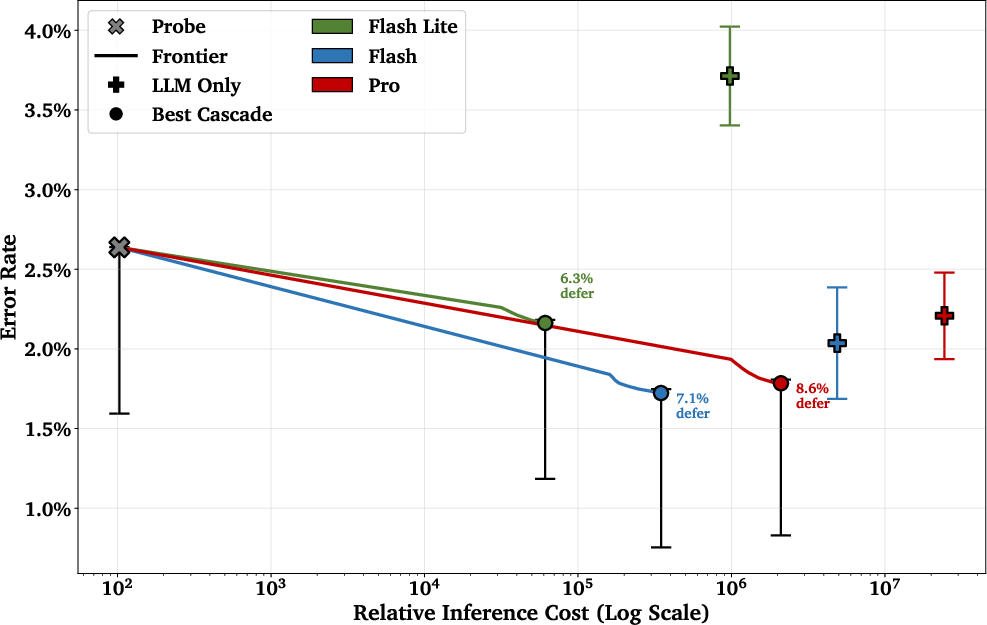
- Cheap + smart beats expensive alone: Using a cascade (probe first, then a bigger model only when needed) gave better accuracy than either one alone—at a tiny fraction of the cost. In one setup, they used the bigger model less than 10% of the time, yet matched or beat the bigger model’s accuracy, with around 1/50th the cost.
- Real-world ready: These probes have been deployed in user-facing versions of Gemini to help stop cyber misuse while minimizing false alarms on legitimate requests.
- Limits and honesty:
- No single method was best for every situation.
- Attackers who adapt (jailbreaks) still sometimes succeed. This is a hard, ongoing problem.
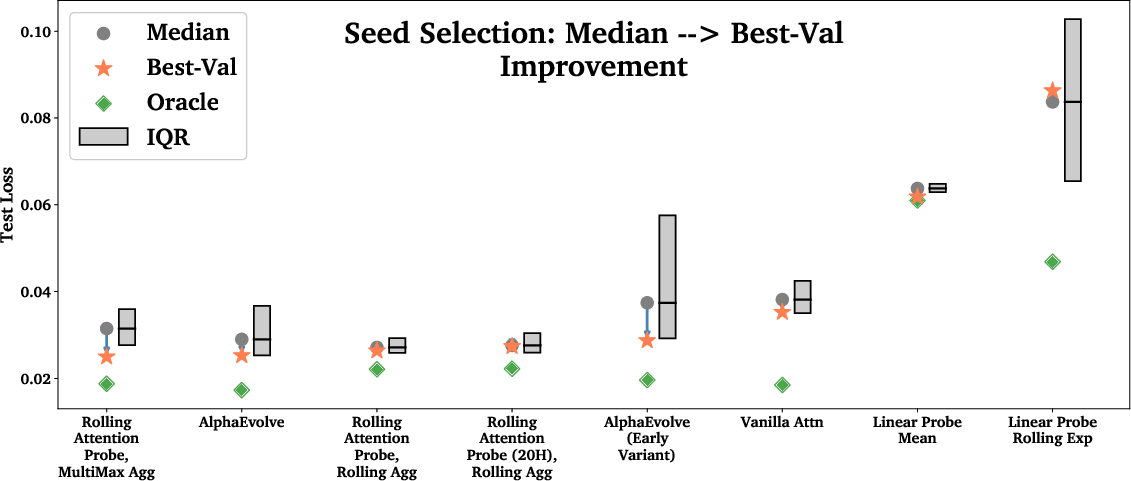
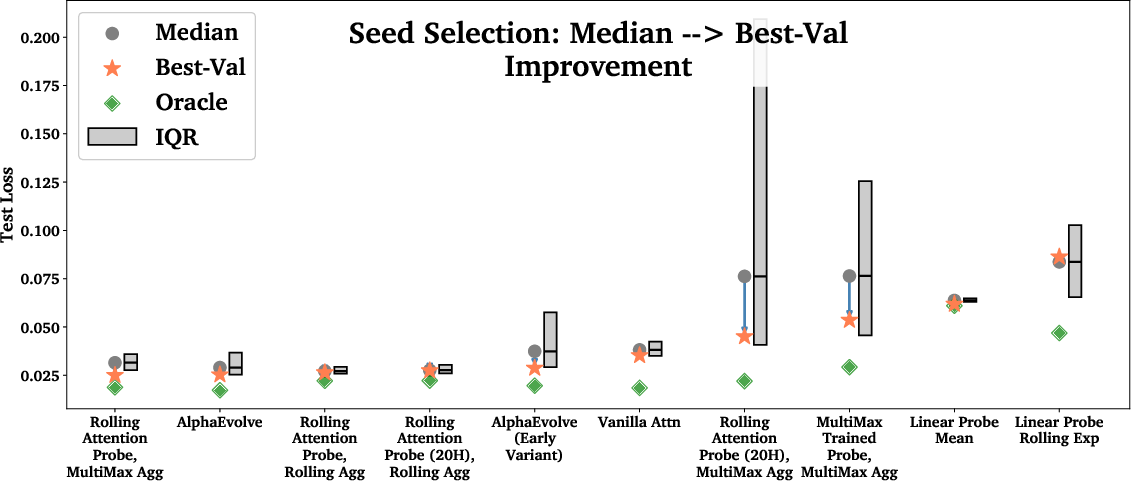
- Choosing the probe’s architecture helps more than just trying many random training seeds, but trying several seeds still gives a small boost.
- Automation is promising: Early results show tools like AlphaEvolve can help automatically discover better probe designs and generate strong tests, speeding up AI safety work.
What’s the big picture?
As AI models get more powerful, it becomes easier for bad actors to misuse them—especially in cybersecurity. This paper shows a practical way to reduce that risk: use fast, cheap detectors inside the model that are specially designed to handle messy, real-world inputs, and back them up with a bigger model only when necessary. These methods cut costs a lot while keeping safety strong, and they’re already helping protect users of Gemini.
That said, there’s no silver bullet. Adaptive attackers still pose a serious challenge, so this approach should be part of a broader safety strategy that keeps improving over time. Tools that automate safety research could help us keep pace with the risks as AI continues to advance.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
The following list enumerates concrete gaps and uncertainties left by the paper, framed so that future work can directly address them:
- Scope limited to input-only monitoring
- Action: Develop and evaluate probes trained on model outputs and joint input–output trajectories, including conversation-level summaries and tool-call traces.
- Adversarial robustness remains weak, especially against adaptive jailbreaks
- Action: Study adversarial training for probes, randomized/ensemble defenses, moving-target strategies, and evaluate under black-box, transfer, and multi-step attacker models.
- Multi-turn robustness is incomplete and relies on synthetic data
- Action: Build real multi-turn corpora with verified intent shifts; develop stateful probes that maintain history-aware features and update across turns.
- Long-context generalization lacks guarantees and relies on architectural heuristics
- Action: Formalize length-invariance properties and conduct stress tests beyond 1M tokens; analyze failure modes for harmful content placement (prefix/suffix/interleaved) and distribution of “signal token” sparsity.
- Costly long-context training is not mitigated at the data/algorithm level
- Action: Explore streaming/online training that computes probe features on-the-fly, activation compression/quantization, chunk-wise curriculum, and memory-efficient loaders with reproducible speedups.
- Cross-model and cross-version transferability is untested
- Action: Measure probe performance across Gemini variants, model updates, and quantization regimes; develop re-fitting/continual learning protocols for model drift.
- Layer and representation selection is underexplored
- Action: Systematically map performance across layers, combine multi-layer features, and investigate attention head–specific probing to identify stable representations.
- Calibration and decision-theoretic thresholding are ad hoc
- Action: Calibrate probe scores (e.g., Platt scaling, isotonic regression), use conformal prediction for coverage guarantees, and tie thresholds to explicit risk/cost models (utility-aware optimization).
- Cascading classifier policy may be exploitable and brittle under shift
- Action: Analyze adversaries steering scores into the deferral band; add randomized gating, robust policy learning, and shift-aware deferral selection with off-policy evaluation.
- Optimal cascading frontier estimated on validation may not generalize
- Action: Provide distribution-shift–robust frontier estimation (e.g., via importance weighting or domain adaptation) and report worst-group performance with uncertainty bounds.
- Interpretability of probe features is not examined
- Action: Identify concepts and circuits driving probe decisions via feature attribution, causal interventions, and token ablations to reduce reliance on spurious cues/keywords.
- Dataset coverage and label quality are insufficiently validated
- Action: Report inter-annotator agreement, conduct auditing for label noise (especially autorater-derived labels), and quantify probe robustness to noisy labels via robust loss functions.
- Synthetic long-context construction may not match real-world contexts
- Action: Evaluate on naturally occurring long sessions (PII-scrubbed), multi-document workflows, and enterprise repositories; compare synthetic vs. organic context performance.
- Multilingual and multimodal generalization is untested
- Action: Build and evaluate multilingual datasets (including code-switching) and multimodal prompts (images/diagrams + text) with corresponding activation probes.
- Resilience to content obfuscation is not assessed
- Action: Test against encoding/cipher (base64/rot13), homoglyphs, slang, code obfuscation, and paraphrase attacks; incorporate obfuscation-augmented training.
- Data scaling laws and sample efficiency are unknown
- Action: Produce performance–data scaling curves, analyze diminishing returns across datasets/shifts, and explore active learning to target informative samples.
- Hyperparameter sensitivity is largely unreported (e.g., window size, head count)
- Action: Run systematic sensitivity analyses for window width, number of heads, MLP depth/width, regularization, and training schedule; publish recommended ranges.
- Inference latency and tail performance are not characterized
- Action: Benchmark end-to-end latency and tail (p95/p99) across context lengths; quantify overhead of incremental attention-probe inference vs. baseline.
- Streaming, early-warning detection during generation is not evaluated
- Action: Implement token-wise streaming probes to enable early cut-off and measure time-to-detection vs. false alarms.
- Seed variance handling is not operationalized for deployment
- Action: Instead of best-of-k selection, evaluate bagging/ensembling across seeds, stochastic weight averaging, and selection procedures with proven generalization.
- Probe–LLM cascade interactions with other mitigations are untested
- Action: Study combined effects with policy/finetune refusals, content filters, and tool-use restrictions; quantify synergy and interference effects.
- Transfer to other misuse domains (CBRN, fraud, persuasion) is assumed, not demonstrated
- Action: Build cross-domain benchmarks and measure zero-shot and few-shot transfer; identify domain-specific architectural or training adaptations.
- Reliance on autoraters for ART dataset introduces circularity risks
- Action: Validate with independent human raters and cross-model adjudication; measure how autorater biases affect probe selection and thresholds.
- Robustness to user role and intent ambiguity is not quantified
- Action: Evaluate false positives across professional roles (e.g., security analysts vs. students), provide conditional error metrics, and explore role-aware conditioning.
- Reproducibility of AlphaEvolve search is limited
- Action: Release search space, seeds, compute budgets, and discovered architectures; assess overfitting to validation and test on blinded, external benchmarks.
- Governance for continual updates is unspecified
- Action: Define monitoring for distribution shift detection, automatic retraining triggers, rollback criteria, and evaluation gates for safe probe updates.
Practical Applications
Practical Applications Derived from the Paper
Below are actionable, real-world applications that leverage the paper’s findings, methods, and innovations. Each item notes target sectors, potential tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
- Real-time misuse monitoring for LLM products
- Sectors: software, cybersecurity, consumer apps
- What: Deploy activation probes (e.g., MultiMax or Rolling Attention) on input activations to flag cyber-offensive prompts before generation, using weighted thresholds prioritizing low overtriggering FPR.
- Tools/workflows: Probe SDK integrated into inference servers; threshold tuning via validation-weighted loss; seed sweep and selection; audit logging of probe decisions.
- Assumptions/dependencies: Access to model activations at inference; reliable labeled data and domain experts; privacy-compliant logging; model-layer selection and stable activation interfaces.
- Cost-optimized safety via cascading classifiers
- Sectors: AI platforms, enterprise SaaS, cloud AI APIs
- What: Probe-first classification with LLM fallback only for uncertain bands, achieving lower test loss than LLM-only at ~1/50th cost (typical deferral <10%).
- Tools/workflows: Two-threshold policy configuration; Pareto frontier tuning using validation data; cost tracking; gradual rollout with A/B tests.
- Assumptions/dependencies: Availability of a robust probe; ability to orchestrate LLM calls selectively; continuous calibration as distributions shift.
- Enterprise security controls for AI-assisted coding
- Sectors: software development, cybersecurity (SOC/DevSecOps)
- What: Gate harmful cyber queries in code assistants (e.g., SQL injection how-tos, exploit crafting) while minimizing false positives on legitimate secure-coding tasks (“hard negatives”).
- Tools/workflows: IDE/plugin integration; secure query routing; “hard negative” datasets for tuning; SOC alert triage pipelines consuming probe signals.
- Assumptions/dependencies: High-quality, domain-specific hard-negative datasets; developer acceptance; clear escalation and override policies.
- Safety monitoring in educational platforms
- Sectors: education, edtech
- What: Detect and prevent escalation from benign to malicious multi-turn security conversations in coursework and labs.
- Tools/workflows: Multi-turn probe aggregation (sliding/rolling windows); instructor dashboards; tiered escalation to human review.
- Assumptions/dependencies: Consent and governance for student monitoring; accurate labeling of benign security learning vs misuse.
- API-level safety for AI providers
- Sectors: cloud AI, platform ecosystem
- What: Offer an opt-in “Safety Probe” tier in model-serving APIs that flags or blocks harmful cyber prompts; provide configurable thresholds by customer risk appetite.
- Tools/workflows: Managed probe service; tenant-level configuration; compliance reporting; automated red-team evaluation bundles.
- Assumptions/dependencies: Standardized activation export and stable model versions; SLAs for latency budgets; customer-side governance.
- On-device/edge safeguards for smaller LLMs
- Sectors: mobile, embedded, consumer devices
- What: Use low-cost probes to enforce safety locally without constant server-side moderation.
- Tools/workflows: Lightweight inference libraries; battery/latency profiling; offline seed selection; periodic policy updates over-the-air.
- Assumptions/dependencies: Local activation access; constrained compute; privacy-safe telemetry.
- Compliance auditing and safety reporting
- Sectors: policy, risk & compliance, enterprise governance
- What: Use probe decisions and cascading classifier outcomes to produce audit trails and monthly safety reports (FPR/FNR per distribution shift).
- Tools/workflows: Reporting dashboards; compliance hooks; incident postmortems using probe score trajectories.
- Assumptions/dependencies: Regulator acceptance of activation-based monitoring; standardized metrics and weighting schemes.
- Internal red teaming automation for product safety
- Sectors: AI safety, product security
- What: Use AlphaEvolve to automate probe architecture search and generate adaptive red-team prompts for regular regression testing.
- Tools/workflows: Scheduled architecture sweeps; autoraters to validate harmfulness; success-criteria tracking; model-in-the-loop adaptation.
- Assumptions/dependencies: Adequate compute; safe handling of harmful artifacts; careful evaluation to avoid overfitting to synthetic attacks.
- Guardrails for consumer AI chat and parental controls
- Sectors: consumer apps, daily life
- What: Local probe filters blocking harmful cyber content while reducing false alarms on benign help (e.g., “explain vulnerability” or homework).
- Tools/workflows: Configurable sensitivity modes; parent dashboards; escalating moderation to an LLM for uncertain cases.
- Assumptions/dependencies: Clear UX for false positives; consent and privacy frameworks.
Long-Term Applications
- Output-side monitoring and streaming intervention
- Sectors: software, cybersecurity, consumer apps
- What: Extend probes from input-only to output activations to monitor and halt harmful content mid-generation, especially in long, streaming responses.
- Tools/workflows: Token-level probe inference; real-time deferral policies; reversible generation workflows.
- Assumptions/dependencies: Low-latency activation access during decoding; robust policies for interruption/recovery; additional training and evaluation.
- Cross-domain misuse detection (CBRN, finance, healthcare)
- Sectors: healthcare, energy/industrial control, finance, scientific R&D
- What: Adapt architectures (MultiMax/Rolling Attn) to detect misuse beyond cyber, including sensitive biosynthesis guidance, ICS sabotage, insider trading prompts, or hazardous medical advice.
- Tools/workflows: Domain-specific datasets and hard negatives; expert-labeled corpora; sector-specific thresholds; cascading with specialized LLMs.
- Assumptions/dependencies: High-quality labels in specialized domains; regulatory constraints; domain transferability may require retraining.
- Safety orchestration in autonomous agents and robotics
- Sectors: robotics, industrial automation, autonomous systems
- What: Embed probes into agent planning loops to intercept dangerous instructions or goals, especially under long-context mission plans.
- Tools/workflows: Plan-level activation monitoring; hierarchical cascading policies; integration with fail-safe controllers.
- Assumptions/dependencies: Access to agent internal states; stable interfaces across planning modules; rigorous real-world validation.
- Sectoral safety standards and certification
- Sectors: policy/regulation, standards bodies
- What: Codify activation-probe-based monitoring into safety certification (e.g., required reporting of weighted test loss across specified distribution shifts).
- Tools/workflows: Standard test harnesses (short/long context, multi-turn, jailbreaks); public benchmarks; minimum threshold policies; auditability requirements.
- Assumptions/dependencies: Consensus on metrics/weights; conformance testing infrastructure; transparent disclosures from model providers.
- Adaptive defense platforms
- Sectors: cybersecurity, AI safety ops
- What: Continual-learning defense combining AlphaEvolve architecture search, synthetic adaptive red teaming, and live telemetry to reduce tail-risk attacks.
- Tools/workflows: Continuous data pipelines; automated seed and architecture rotation; adversarial canaries; risk scorecards.
- Assumptions/dependencies: Robust safety review to avoid model gaming; compute and MLOps maturity; careful handling of adversarial drift.
- Safety probes for enterprise workflows (CI/CD and SOC)
- Sectors: software engineering, enterprise IT
- What: Integrate probe gates into CI/CD pipelines for AI-generated code, and SOC workflows for AI-assisted incident response tools.
- Tools/workflows: Pre-commit safety checks; PR-level probe assessments; SOC playbooks; exception management.
- Assumptions/dependencies: Developer buy-in; minimal latency overhead; organizational process alignment.
- Resilient long-context training infrastructure
- Sectors: AI platforms, research
- What: Build specialized data-loading and memory-paging systems to train probes on million-token contexts (22× cost today), improving robustness under extreme distribution shifts.
- Tools/workflows: Host↔device memory pipelines; activation sharding; curriculum schedulers for context length.
- Assumptions/dependencies: Significant infra investment; cost-benefit vs architecture-only solutions; careful privacy and data governance.
- Evaluating and hardening against adaptive adversaries
- Sectors: cybersecurity, AI safety research
- What: Systematic study and defense hardening for probe/LLM cascades under semantic jailbreaks and adaptive strategies (e.g., narrative embedding, PAIR-like methods).
- Tools/workflows: Expanded red-team suites; multi-metric evaluation (including distribution shift generalization); defense-in-depth ensembles.
- Assumptions/dependencies: Recognized difficulty of adversarial robustness; acceptance that residual risk persists; ongoing research and monitoring budgets.
- Safety probe marketplaces and interoperability
- Sectors: software ecosystems, cloud marketplaces
- What: Curated registries of probe architectures with model cards, metrics, and deployment recipes; interoperable probe APIs across models.
- Tools/workflows: Versioned probe catalogs; compatibility testing; domain extensions; commercial support.
- Assumptions/dependencies: Cross-vendor activation access; standardization of interfaces; governance of quality and safety claims.
- Human-in-the-loop governance enhancements
- Sectors: policy, enterprise governance, daily life
- What: Combine probe signals with human review tiers, calibrated thresholds by context (e.g., education vs enterprise coding), and transparent appeal processes.
- Tools/workflows: Reviewer tooling; context-aware policies; fairness audits for overtriggering vs false negatives.
- Assumptions/dependencies: Sustainable reviewer capacity; clear accountability; safeguards against chilling legitimate use.
Notes on feasibility:
- Probes are already deployed in Gemini; most probe + cascade applications are deployable now, given activation access and appropriate datasets.
- Generalization beyond cyber requires new domain data and evaluation; output-side monitoring and robotics integration need further research and engineering.
- Adaptive adversaries remain a hard open problem; ongoing monitoring and defense-in-depth are necessary regardless of the chosen architecture.
Glossary
- Activation probes: Small classifiers trained on a model’s internal hidden states to detect specific properties (e.g., misuse) at low cost. "A more cost-effective alternative is an activation probe: a small model trained on the internal hidden states of the model one plans to monitor."
- Adaptive red teaming: An adversarial evaluation approach where attacks evolve or adapt to bypass defenses, often via narrative or multi-step prompts. "We evaluate these probes in the cyber-offensive domain, testing their robustness against various production-relevant shifts, including multi-turn conversations, static jailbreaks, and adaptive red teaming."
- AdamW: An optimization algorithm for neural networks that decouples weight decay from gradient updates, improving generalization. "We use full batch gradient descent with AdamW, for 1000 epochs."
- AlphaEvolve: An automated system for architecture search and strategy optimization, used here to improve probe designs and attack generation. "Finally, we find early positive results using AlphaEvolve \citep{novikov2025alphaevolve} to automate improvements in both probe architecture search and adaptive red teaming."
- Attention probes: Probes that aggregate token-level signals via attention weights, allowing content-dependent pooling over sequences. "This confirms that attention probes have sufficient capacity to handle long contexts if given enough data."
- Autorater: An automated evaluation component that verifies whether a model’s output is harmful or meets specified criteria. "We guard against this by using an autorater to verify that the model's response is actually harmful."
- Bootstrap probability: A confidence measure derived from resampling that quantifies how often one method outperforms another. "In \Cref{secAlphaEvolveResults}, we also present results from an automated architecture search using AlphaEvolve \citep{novikov2025alphaevolve}, which discovers a probe that outperforms other baselines (bootstrap probability > 0.95, \Cref{secStatisticalSignificance})."
- Cascading classifier: A system that uses a cheap classifier first and defers uncertain cases to a more expensive model to balance cost and accuracy. "We consider two level cascading classifiers, with level one set to be a probe and level two set to be a more expensive prompted LLM ."
- CBRN: Acronym for Chemical, Biological, Radiological, and Nuclear domains, often referenced in high-risk misuse contexts. "Misuse mitigations are techniques that prevent malicious users from performing cyber-offensive, CBRN and other similar attacks using frontier LLMs."
- Cross entropy loss: A standard classification loss function measuring divergence between predicted probabilities and true labels. "We train probes to minimize cross entropy loss on these sequences:"
- Distribution shift: A change between training and deployment data distributions that can degrade model performance. "Prior work has shown that activation probes may be a promising misuse mitigation technique, but we identify a key remaining challenge: probes fail to generalize under important production distribution shifts."
- EMA (Exponential Moving Average) probes: Probes that smooth per-token scores via an exponential moving average and often take a max over positions. "EMA probes were proposed by \cite{cunningham2025cheap} as a way to improve probe generalization to long contexts."
- Frontier LLM: A cutting-edge, highly capable LLM at the leading edge of performance and risk. "Frontier LLM capabilities are improving rapidly."
- Jailbreaks: Prompt-based techniques that coerce a model to bypass safety constraints or produce restricted outputs. "We take a list of jailbreaks, i.e. functions that map strings to strings such as appending a suffix as in the GCG paper \citep{zou2023universal}, and apply them to all of the harmful cyber prompts in the Short Context Attacks evaluation set."
- Logistic regression classifier: A linear probabilistic classifier used here as a simple probe over hidden activations. "We thus consider an alternative way of classifying : training and running a small logistic regression classifier or neural network (i.e. a probe) trained on the deployed LLM's hidden states (activations)."
- Long context: Inputs with very large token lengths that stress memory and generalization, often exceeding hundreds of thousands of tokens. "In particular, we find that the shift from short-context to long-context inputs is difficult for existing probe architectures."
- Max of Rolling Means Attention Probe: A probe that computes attention-weighted averages over sliding windows and takes the maximum across windows. "``Selected Probe'' refers to our Max of Rolling Means Attention Probe (\Cref{secOurProbes})."
- Misuse mitigation: Techniques and systems designed to prevent or detect harmful use of AI models (e.g., cyber-offensive requests). "Misuse mitigations are techniques that prevent malicious users from performing cyber-offensive, CBRN and other similar attacks using frontier LLMs."
- MultiMax: A probe architecture that replaces softmax aggregation with per-head hard maxima to avoid dilution over long contexts. "We introduce a new probe architecture family, MultiMax, that has higher classifier accuracy on long context prompts compared to other probe architectures."
- Multi-turn conversations: Dialogues spanning multiple exchanges where intent may evolve, used to evaluate robustness to conversational attacks. "We evaluate these probes in the cyber-offensive domain, testing their robustness against various production-relevant shifts, including multi-turn conversations, static jailbreaks, and adaptive red teaming."
- Overtriggering: Firing safety or misuse detectors on benign inputs, a costly failure mode in deployment. "Note: we use the term ``overtriggering'' to refer to benign (non-cyber) datasets on which our classifiers should not fire"
- Pareto frontier: The set of non-dominated trade-offs between objectives (e.g., cost vs. error), used to compare classifier policies. "The two points not on the Pareto frontier (Selected Probe and AlphaEvolve) have their costs artificially increased by 1.25× for visual separation;"
- Prompted LLM: A classifier formed by pairing a prompt with an LLM and parsing its response for a decision. "A prompted LLM consists of a (prompt, LLM) pair."
- Residual stream activations: The per-token hidden states in a transformer’s residual pathway, used as probe inputs. "Residual stream activations of undergo a 2) Transformation per-position."
- Softmax weighting: The exponential normalization used in attention that can cause overtriggering when aggregating over long inputs. "We find that the attention probe's softmax weighting suffers from overtriggering on long contexts (see \Cref{secMainResults})."
- TPU HBM: High Bandwidth Memory on TPUs; device memory that may be insufficient for storing very long-context activations. "Even with large-scale accelerator clusters, the full dataset of long-context activations (each up to 1M tokens) cannot fit into TPU HBM."
- Weighted error: A composite metric that weights different error types (e.g., FPR on overtriggering vs. FNR) to select thresholds. "We make this choice by choosing a that minimizes the following weighted error metric on all validation datasets from \Cref{tabDatasets}:"
Collections
Sign up for free to add this paper to one or more collections.