- The paper proposes a Transformer-based architecture that estimates latent dynamic factors using a double-encoder structure and granular tokenization for enhanced performance.
- It integrates traditional linear state-space models into the loss function via regularization, ensuring robustness and interpretability even with limited data.
- Monte Carlo experiments and an empirical macroeconomic application demonstrate improved predictive accuracy and effective detection of regime shifts.
Introduction and Architectural Innovations
The paper "Nonlinear Dynamic Factor Analysis With a Transformer Network" (2601.12039) introduces a Transformer-based method tailored for the estimation of latent dynamic factors from multivariate time series, emphasizing regimes deviating from standard linear-Gaussian assumptions. The approach departs from prior Transformer applications in time series, focusing on direct latent state estimation and model interpretability with a double-encoder structure and strictly granular tokenization. Observational scarcity in macroeconomic data is addressed via the introduction of a regularization framework, injecting prior information from conventional factor models into the loss function. This regularization, controlled by a weighting parameter, allows seamless interpolation between strict adherence to a misspecified traditional model (e.g., Kalman filter) and fully data-driven nonlinear estimation.
The proposed architecture accepts a P×k input context window (for k variables and P lags) tokenized at maximal granularity—each variable-lag pair is a token. Embedding combines value, positional, and variable encodings, enabling maximal interpretability of the attention patterns. The latent factor is initially estimated via a simple mapping (such as the mean across variables), then subjected to iterative refinement within a stack of State Encoders, which employ cross-attention mechanisms drawing keys/values from the observed data and queries from the current factor estimate.
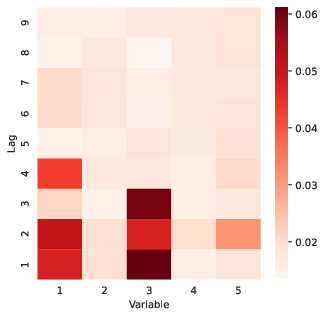
Figure 1: State Attention matrix visualizes which variables and lags are most influential for forming the latent factor estimate, with highlighted concentration on variables 1 and 3.
This design ensures attention matrices correspond directly to interpretable mappings from observable variables and their temporal structure into the latent space, providing clarity into temporal and cross-sectional dependencies exploited by the model.
Attention-Based Interpretability and Regime Change Detection
Central to the method is leveraging the Transformer's attention matrices as interpretable diagnostics. The State Attention matrix at each period can be visualized as a P×k heatmap, indicating, for each lag and variable, the marginal contribution to the latest factor estimate. Such visualizations enable the tracing of the relative importance of variables and lags dynamically and allow researchers to identify structural breaks, regime changes, or other forms of nonstationarity.
Temporal evolution of attention weights reveals regime shifts: abrupt changes in attention allocation signal changing information flow or relevance between variables, often coinciding with, or prefiguring, shifts in economic regimes or volatility.
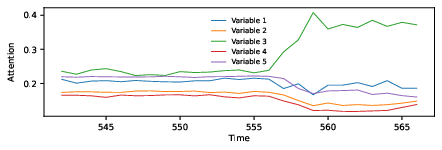
Figure 2: Attention dynamics vary over time, with pattern changes signaling regime switches—here, variable 3 becomes dominant as the process undergoes a structural shift.
Further, lags in attention spikes can be causally linked to the propagation of large, non-Gaussian shocks or to persistent shifts in latent dynamics, pinpointing the moments where recent history becomes disproportionately informative.
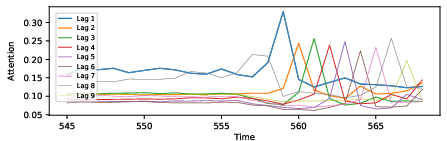
Figure 3: Dramatic reallocation of attention across lags occurs after large shocks, as observed at period 558, propagating through subsequent periods’ attention distribution.
The measurement attention matrices serve a complementary interpretive purpose: they reveal which lags of the estimated latent factor are most relevant for predicting each observable at time t+1, acting as effective proxies for time-varying factor loadings.
Regularization With Prior Models and Training Under Data Scarcity
A critical innovation is the explicit incorporation of prior information—typically the estimate from a linear state-space model (e.g., the Kalman filter)—into the training objective. The loss function blends prediction error for observables with the deviation of the Transformer's factor estimates from those provided by the conventional model, ensuring reasonable results even on small datasets. This approach (subspace regularization toward the linear model) mitigates overfitting, shrinks the solution towards interpretable subspaces, and provides a smooth pathway for uncovering actionable nonlinearities distinct from the prior.
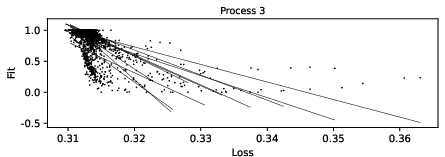
Figure 4: Plots of loss versus accuracy (fit) across epochs and initializations demonstrate stable training convergence and improved factor accuracy as loss diminishes.
The effectiveness of the regularization approach is empirically validated: omitting prior information yields substantial degradations in both out-of-sample predictive fit and consistency, while using only the prior (i.e., λ=1) collapses the solution to that of the base model, verifying the continuity between Transformer and traditional factor analysis.
The model's efficacy is evaluated using Monte Carlo experiments, critically comparing the Transformer to estimated Kalman filters and (when available) true-oracle filters across a slate of data-generating processes (DGPs) incorporating nonlinear, non-Gaussian, regime-switching, and high-lag dynamic effects. Small sample settings (800 training time points; 1000 for test) reflect the practical constraints of macroeconomic analysis. Fit, gain, and R2 metrics benchmark accuracy.
The Transformer outperforms the Kalman filter baseline by margins up to 45% on nonlinear/non-Gaussian processes, especially when the measurement equations or latent state evolve nonlinearly or with heavy tails. Attention diagnostics pinpoint the onset of regime switches, lagged shock propagation, and variable-specific saliency shifts.
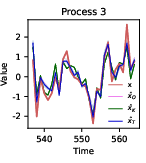
Figure 5: Out-of-sample test set snapshots illustrate the Transformer's superior factor tracking compared to the Kalman filter across diverse processes, with reduced mean error and lower variance among realization seeds.
Case diagnostics further show that, when regularized by prior information, the Transformer generalizes to unseen test examples, does not simply memorize noise, and leverages nonlinearity primarily where the linear model’s fit is poor.
Empirical Application: U.S. Coincident Index Estimation
The framework is applied to U.S. macroeconomic time series (industrial production, sales, income, and hours) to construct a nonlinear coincident business cycle index. The estimated index closely tracks both the Kalman filter-based benchmark and the official NBER recession dates, with the Transformer's index displaying lower volatility and occasionally nuanced responses during crisis periods (e.g., COVID-19) relative to the conventional model. Regime shift diagnostics from attention trajectories coincide with recession boundaries, suggesting practical relevance for real-time policy monitoring.
Theoretical and Practical Implications
This work extends the operational reach of the Transformer architecture to dynamic latent variable estimation, disintermediating the customary assumption of predetermined model structure in state-space analysis. By mapping the Transformer as a superset of traditional linear-Gaussian models under strong regularization, and as a maximally flexible nonlinear estimator otherwise, the study foregrounds a flexible model selection paradigm in applied macroeconometrics.
Attention-based interpretability addresses long-standing criticisms of neural black-boxes in economics, offering inspectable inter-variable and inter-temporal dependency mapping. This unlocks potential for transparent narrative analysis (identifying, e.g., which variables inform regime shifts or which lags propagate novel shocks), and facilitates integration with theoretical priors.
Limitations and Prospective Directions
While the proposed approach demonstrates clear benefits in simulated and empirical macroeconomic settings, limitations remain. Overparameterization, even with regularization, can in certain cases produce instability or overfit spurious nonlinearities if the prior model is miscalibrated or data is exceedingly limited. Further research is called for on adaptive selection of regularization weights, automatic early stopping protocols, and scaling architectures for even higher-dimensional economic data.
Pretraining Transformers on a corpus of simulated or related real-world time series, followed by task-specific fine-tuning, represents a promising strategy to further improve generalization and parameter recovery. Extensions to multiperiod, multifactor, and nonlinear measurement models are direct avenues for investigation, with implications for both academic research and policy toolkits.
Conclusion
The integration of Transformer architectures with prior model regularization constitutes a substantive advance in nonlinear latent factor estimation for time series. The resulting framework is interpretable, flexible, and robust to common departures from linearity and Gaussianity in economic data, with strong empirical performance and theoretically grounded diagnostics for model transparency. This paradigm holds significant promise for complex, data-constrained time series domains where latent economic structure is of central analytic interest.