- The paper proposes a novel mapping approach that leverages foundation models and hierarchical graphs to achieve robust, scalable localization.
- It integrates dynamic programming-based sequence matching with confidence-calibrated metric optimization for accurate cross-device mapping.
- Empirical results demonstrate sub-meter accuracy and an order-of-magnitude reduction in storage compared to traditional structure-based maps.
OpenNavMap: A Structure-Free Topometric Mapping System for Large-Scale Collaborative Localization
Introduction and Motivation
OpenNavMap addresses critical scalability and robustness limitations in large-scale visual navigation (VNav) by proposing a structure-free, topometric mapping paradigm tailored for collaborative, cross-device multi-session mapping. Unlike conventional structure-based approaches, which maintain explicit and dense 3D reconstructions for localization, OpenNavMap utilizes the representational power of 3D geometric foundation models (GFMs) to perform on-demand inference of scene geometry and camera parameters, leveraging a lightweight graph structure where nodes store RGB images and associated visual/topometric metadata.
This shift enables significant reduction in map maintenance complexity and computational overhead, accommodates the heterogeneity of modern data sources (e.g., smartphones, AR glasses, street-view panoramas), and maintains robustness even in feature-poor environments or under significant temporal/viewpoint shifts. OpenNavMap is underpinned by a hierarchical integration of dynamic programming-based sequence matching, geometric verification, and confidence-calibrated optimization, making it agnostic to pre-built 3D metric maps and thus scalable for lifelong, crowd-sourced, or robot-captured mapping deployments.
Core System Architecture
The system models environments as a three-layer topometric graph: the Covisibility Graph (CvG), Odometry Graph (OdG), and Traversability Graph (TrG). Nodes in these graphs represent image observations, odometric poses, or traversable spatial locations, with multi-modal, multi-temporal attributes that support robust localization, global consistency, and real-time path planning. Data acquisition is distributed and device-agnostic, supporting keyframe-based map construction from RGB(-D), egocentric, vehicular, or panoramic platforms with varying intrinsic parameters.
Collaborative Localization Pipeline
Collaborative localization and map merging are formulated as a hierarchical pipeline:
- Topological Localization uses discriminative global image descriptors and a dynamic programming (DP) sequence matcher to efficiently establish candidate loop closures even for disjoint or irregularly overlapping trajectories. Geometric verification (GV) based on feature matches and RANSAC discards false positives, ensuring high precision and recall in data association.
- Metric Localization utilizes a GFM (MASt3R) to predict dense, scale-aware pointmaps and per-pixel confidence maps for query-reference image pairs. A global optimization framework then aligns these predictions, explicitly calibrating confidence maps via robust loss (e.g., Geman-McClure kernel within IRLS), yielding consistent pose, scale, and geometry for multi-view consistency. This confidence-calibrated map (CCM) provides a principled way to reject unreliable loop closures.
- Pose Graph Optimization (PGO) integrates intra-map odometry and inter-map metric constraints in a global factor graph, robustly optimizing the joint pose set for all submaps, leveraging the calibrated covariance of loop closure edges.
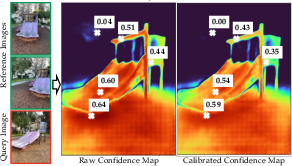
Figure 2: The raw and calibrated confidence maps of the query image after global alignment; confidence values are adaptively down-weighted in regions of high residual error.
Cross-Device and Heterogeneous Mapping
The architecture natively supports cross-device data fusion via pre-processing and IQA-based filtering. Virtual perspective projections from equirectangular panoramas and undistortion routines ensure geometric consistency for foundation model inference. A learned MOSIQ-based image quality assessment (IQA) filters perceptually degraded inputs. This enables robust operation in both crowd-sourced and autonomous multi-platform contexts, removing dependency on calibrated, high-end sensing arrays.
Lifelong Map Maintenance via Node Culling and Connectivity Augmentation
As maps grow, a probabilistic node culling strategy operates on information contribution metrics that combine image quality, temporal recency, and geometric novelty (information gain). Nodes offering little marginal value are selectively culled post-PGO, maintaining a compact but informative map topology suitable for long-term operation. Edge augmentation dynamically densifies the CvG and TrG as new evidence of spatial or covisible connectivity emerges.
Numerical Results and Empirical Analysis
Localization and Mapping Benchmarks
Topological Localization: On the self-collected dataset spanning >18 km across varied environments, CosPlace and the proposed DP-based sequence matching with GV achieve top-1 precision/recall exceeding 86%/75%, outperforming both traditional (SeqSLAM, NetVLAD) and deep classification-based place recognition models under large viewpoint and temporal variation.
Metric Localization: On Map-Free, GZ-Campus, and self-collected datasets, OpenNavMap’s GFM-based localization consistently reaches sub-meter accuracy (0.62 m average translation error on Map-Free, ATE <3 m on large-scale map merging, >80% correct within $1$ m/10∘ using just two references). Structure-based pipelines (COLMAP/HLoc) degrade significantly under view sparsity or long baselines where triangulation is poorly conditioned, requiring >5 references for similar accuracy.
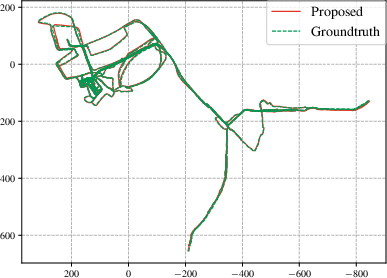
Figure 4: Estimated multi-session trajectory by OpenNavMap with GT from Aria Glasses; absolute trajectory error remains <3 m over a $15$ km dataset.
Map Size: The image-based, structure-free map requires an order of magnitude less storage than explicit 3D maps, e.g., $1.3$ MB per scene versus $20$ MB for feature descriptor-based maps at equivalent coverage.
Heterogeneous and Lifelong Mapping
On the $360$Loc dataset (cross-device, panoramic to pinhole conversion), translational/rotational ATE remains around $1$ m/1∘, demonstrating resilient merging despite multi-session, multi-intrinsic, and GPS-denied mapping. On self-collected, multi-platform maps (>3.5 months, heterogeneous devices and street-view panoramas), the system integrates global path planning and visual navigation even to images never observed by the robot, with cumulative maps covering up to $15.7$ km.
Visual Navigation Trials
Twelve autonomous image-goal navigation tasks using OpenNavMap as the spatial backbone demonstrate practical viability: robots navigate point-to-point using only visual topometry, without external metric priors, sustaining robust operation indoor, outdoor, and under significant environmental/illumination changes.
Implications and Future Prospects
From a theoretical perspective, OpenNavMap redefines the representational trade-off between map compactness and metric accuracy by decoupling dense 3D structure storage from localization and planning capability. Leveraging GFMs mitigates the limitations of geometric feature sparsity, permits scalable crowd-sourced mapping, and abstracts hardware-specific calibration.
Practically, the topometric paradigm, where image nodes and traversability/covisibility/odometry edges constitute the operational backbone, enables real-time navigation and planning in unprepared, dynamic, or GPS-denied spaces with limited resource requirements. The cross-device compatibility and probabilistic culling ensure compactness and adaptability for lifelong autonomy, supporting continuous data integration from arbitrary user sources.
Challenges remain in scaling foundation model inference for real-time embedded applications, improving adaptation under extreme cross-device domain shifts, and decentralizing collaborative mapping protocols. Future research directions include explicit exploitation of underlying graph topology for non-sequential matching, enhancement of GFM robustness, and distributed map maintenance enabling truly global lifelong mapping.
Conclusion
OpenNavMap establishes a new baseline for large-scale, collaborative, structure-free visual navigation and mapping. By combining sparse, image-indexed topometric maps with on-demand 3D scene inference via foundation models, and integrating dynamic, robust data association, the system matches or exceeds prior state-of-the-art structure-based pipelines on both metric accuracy and operational scalability—with significantly reduced storage and computational cost. This paradigm is well-aligned with the increasing heterogeneity and ubiquity of modern visual mapping platforms, supporting robust robotic perception and navigation in complex, changing, and unstructured environments.
(Figures were included where essential to illustrate the confidence calibration and empirical trajectory quality. The essay references the salient numerical results and implementation details critical to evaluating the robustness and scalability of OpenNavMap.)