Aligning Agentic World Models via Knowledgeable Experience Learning
Abstract: Current LLMs exhibit a critical modal disconnect: they possess vast semantic knowledge but lack the procedural grounding to respect the immutable laws of the physical world. Consequently, while these agents implicitly function as world models, their simulations often suffer from physical hallucinations-generating plans that are logically sound but physically unexecutable. Existing alignment strategies predominantly rely on resource-intensive training or fine-tuning, which attempt to compress dynamic environmental rules into static model parameters. However, such parametric encapsulation is inherently rigid, struggling to adapt to the open-ended variability of physical dynamics without continuous, costly retraining. To bridge this gap, we introduce WorldMind, a framework that autonomously constructs a symbolic World Knowledge Repository by synthesizing environmental feedback. Specifically, it unifies Process Experience to enforce physical feasibility via prediction errors and Goal Experience to guide task optimality through successful trajectories. Experiments on EB-ALFRED and EB-Habitat demonstrate that WorldMind achieves superior performance compared to baselines with remarkable cross-model and cross-environment transferability.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Aligning Agentic World Models via Knowledgeable Experience Learning” (WorldMind)
1) What is this paper about?
This paper is about teaching AI agents (like smart robots or game characters powered by LLMs) to make plans that actually work in the real world. The authors noticed a problem: these AIs can write smart, logical plans, but sometimes those plans are impossible to do physically (like “slice the apple” without first picking up a knife). The paper introduces WorldMind, a new way for agents to learn from their own experiences—both mistakes and successes—so their plans become both smart and doable.
2) What questions are the researchers asking?
They’re mainly asking:
- How can we stop AI agents from making physically impossible plans, without constantly retraining them?
- Can an agent learn the “rules of the real world” by paying attention to what goes wrong and what works during tasks?
- Can this knowledge be reused across different AI models and different environments?
3) How does WorldMind work? (Methods in simple terms)
Think of the agent like a person learning a new video game:
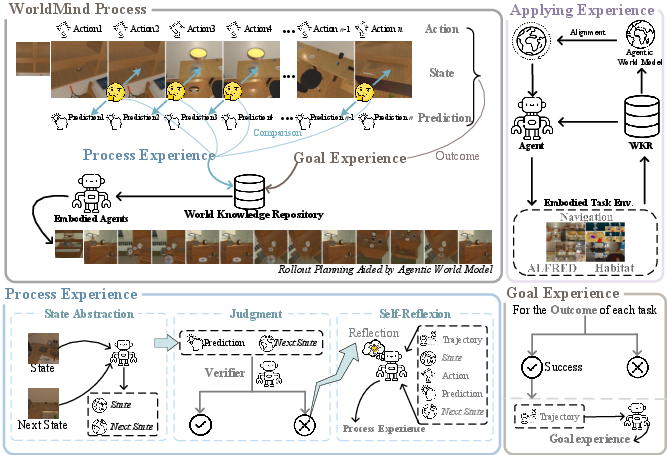
- First, they guess what will happen if they press a button (Predict).
- Then they try it (Act).
- Then they check if their guess matched what actually happened (Verify).
This is the Predict–Act–Verify loop.
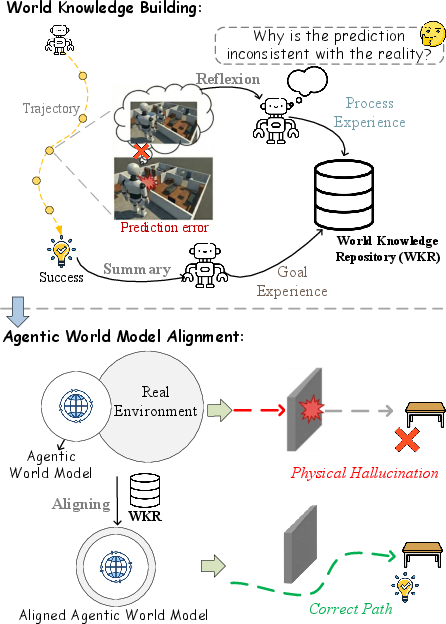
When the guess and reality don’t match, that’s a “prediction error.” WorldMind turns these moments into useful lessons and stores them in a shared “rulebook” called the World Knowledge Repository. This rulebook has two parts:
- Process Experience: lessons learned from mistakes. These are “house rules” about what’s physically possible. Example: “You can’t open a fridge if you’re too far away” or “You must hold a knife before you can slice.”
- Goal Experience: tips learned from successful runs. These are “best practices” or shortcuts to reach goals faster. Example: “To make toast, first grab bread, then put it in the toaster, then press the lever.”
Here’s the idea in everyday language:
- The agent predicts what will happen next, tries it, and checks reality.
- If reality disagrees, it writes a new rule (Process Experience) so it won’t make that mistake again.
- If the agent succeeds, it writes down a clean, high-level strategy (Goal Experience) so it can do it faster next time.
- The agent uses these rules and tips to plan future actions, only “imagining” outcomes when it can clearly see the objects involved (this avoids daydreaming about things that aren’t there).
Importantly, WorldMind doesn’t retrain the AI’s internal weights. Instead, it learns during use by building this external rulebook—like keeping a smart notebook that any agent can read.
4) What did they find, and why does it matter?
The researchers tested WorldMind on two challenging robot-like benchmarks where an agent must understand instructions and interact with objects:
- EB-ALFRED
- EB-Habitat
They measured:
- Success Rate (SR): Did the agent fully complete the task?
- Goal Condition (GC): Did it correctly complete important steps along the way, even if it didn’t fully finish?
Key results:
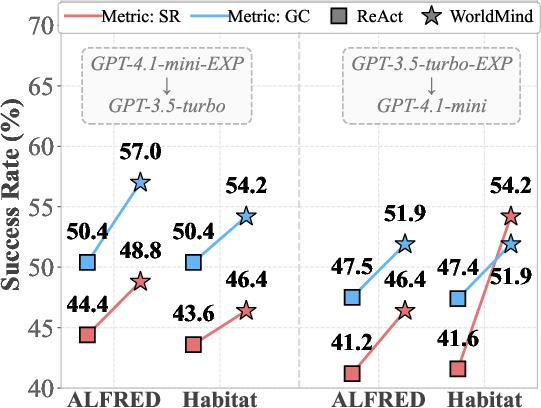
- WorldMind raised full task success compared to a strong baseline method (ReAct).
- For example, on EB-Habitat using GPT-4.1-mini, SR went up to about 50.8% (from 41.6%).
- On EB-ALFRED using GPT-3.5-turbo, SR improved to about 48.0% (from 44.4%).
- It also performed better on the step-by-step GC score, meaning it did more correct sub-steps even when it failed the whole task.
- On EB-Habitat with GPT-4.1-mini, GC rose to about 57.2% (from 47.4%).
- On EB-ALFRED with GPT-3.5-turbo, GC improved to about 54.1% (from 50.4%).
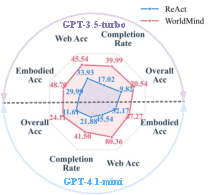
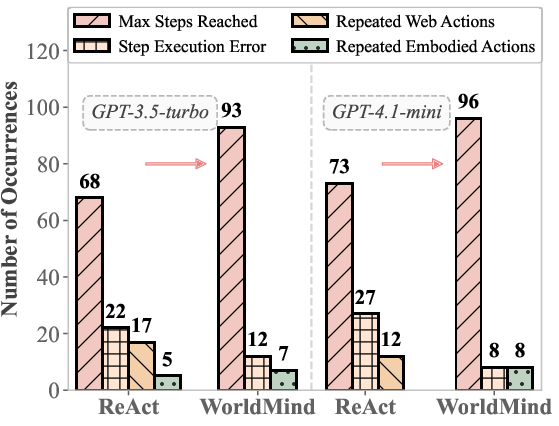
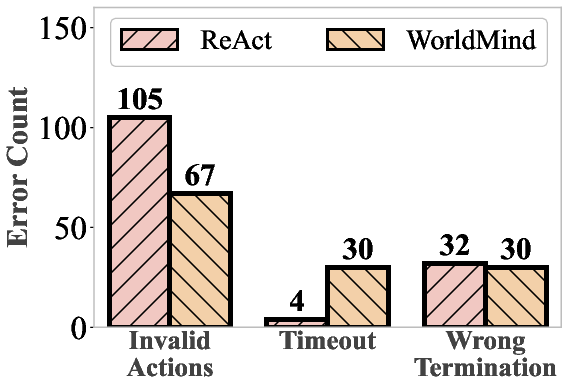
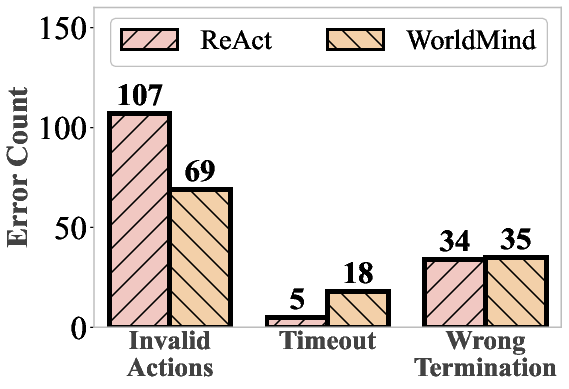
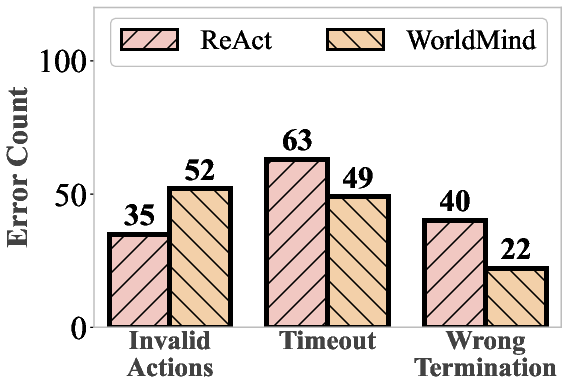
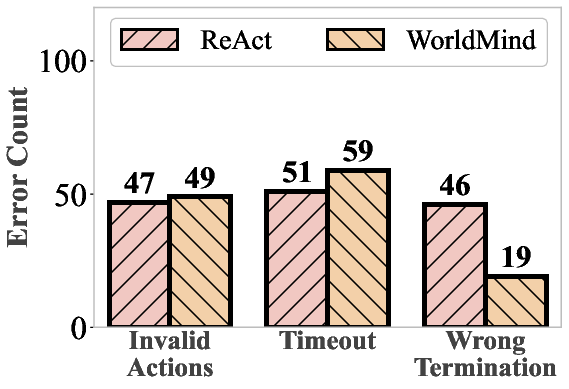
- Fewer “impossible” actions: The agent made fewer physically invalid moves (like trying to pick up objects it couldn’t reach).
- The learned rulebook transfers across models: Knowledge gathered by one model (like GPT-3.5) helped another model (like GPT-4.1-mini), showing the rules are general and reusable.
- It works across different environments (like simulated homes and web-assisted tasks), not just one setup.
Why this matters:
- Plans become not only clever but actually doable.
- The agent learns “on the fly” without expensive retraining.
- The lessons are understandable (symbolic rules), shareable, and portable across different AIs.
5) What’s the bigger impact?
WorldMind points to a practical way to make AI agents safer, more reliable, and more efficient in the real world:
- Instead of stuffing every possible rule into the AI’s brain ahead of time, let it build a clean, readable rulebook as it works.
- This rulebook can be shared among different agents, speeding up learning and reducing repeated mistakes.
- It could help future home robots, game agents, and digital assistants follow real-world constraints, finish tasks more often, and explain their behavior.
- There are still challenges (for example, if the agent mis-sees an object, it can still go wrong), but this approach is a big step toward agents that learn like people do—by turning both mistakes and successes into useful, reusable knowledge.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues and missing analyses that, if addressed, could advance and operationalize the paper’s contributions.
- Formalize the
State Abstractionfunction: specify the algorithm, features, abstraction granularity, and how abstraction choices affect performance and error detection across tasks. - Define the
Prediction Errorcomparator: detail how textual predictions are compared to abstracted ground truth (e.g., string matching, semantic entailment, structured parsing), including thresholds and tie-breaking rules. - Specify the representation of
Process Experiencerules: provide a machine-readable syntax/semantics (e.g., production rules, constraints), compositionality, and how rules map to latent dynamics in the WK-MDP. - Conflict handling among rules: outline detection, prioritization, and resolution of contradictory or overlapping causal rules, including confidence weighting and provenance tracking.
- Rule lifecycle management: describe validation, decay/aging, pruning, and re-verification policies to prevent repository bloat and stale knowledge.
- Retrieval mechanics: detail the similarity function, embedding models, indexing structure, and sensitivity analyses for retrieving
ProcessandGoalexperiences; evaluate retrieval precision/recall. - Grounding criteria for gating simulation: specify how “explicit grounding” of target objects is determined from observations or
W, including thresholds, false positives/negatives, and impact on skipped simulations. - Robustness to perceptual noise and partial observability: analyze how sensor errors or occlusions affect rule synthesis and updates; add safeguards against accumulating incorrect rules from noisy feedback.
- Quantify physical hallucinations: introduce explicit metrics (e.g., rate of invalid actions, violation types, severity) and standardized procedures for measuring and comparing hallucinations across methods.
- Compute/latency profile: report end-to-end inference time, memory usage, retrieval overhead, and scaling behavior versus multi-sampling or external simulators; conduct a cost–benefit analysis.
- Theoretical guarantees: analyze convergence properties of WK-MDP under prediction-error-driven updates, provide bounds on decreasing , and derive sample complexity for achieving certain success rates.
- Temporal credit assignment: clarify how long-horizon dependencies are captured in
Goal Experience(e.g., options, macro-actions) and how rules generalize across subgoal permutations. - Reproducibility of joint generation: document prompting templates, decoding strategies, randomness controls, and hyperparameters for generating action and predicted state jointly.
- Scalability of WKR: evaluate repository growth over long runs, memory footprint, retrieval latency under scale, and pruning strategies; test on extended horizons and larger task suites.
- Negative transfer under domain shift: measure when rules from one environment hurt performance in another; develop rule scoping, environment tags, and isolation/testing pipelines to prevent harmful reuse.
- Staleness detection: propose mechanisms to detect and invalidate outdated rules when environment dynamics change, including periodic re-validation or online consistency checks.
- Stronger baselines and cost comparisons: include training-based SFT/RL world-model baselines and quantify training/inference costs, to substantiate claims about efficiency and practicality of training-free alignment.
- Rule quality evaluation: create benchmarks or human-in-the-loop protocols to assess causal rule correctness, coverage, and utility; track precision/recall of discovered rules over time.
- Multi-agent shared WKR: design real-time synchronization protocols, consensus mechanisms, and conflict resolution for simultaneous collaboration; study privacy, ownership, and versioning of shared knowledge.
- Generalization beyond simulators: test on real robots with continuous control and safety constraints; report transferability, calibration, and recovery from unexpected physical interactions.
- Cross-model transfer boundaries: characterize transfer across modalities (LLM-only vs VLM), model scales, and languages; identify failure cases and necessary normalization layers for portability.
- Retrieval bias and fairness: audit whether experience retrieval induces spurious correlations or biases; propose debiasing strategies and fairness diagnostics for rule selection.
- Efficiency vs timeout trade-off: analyze the observed increase in timeouts, develop path-efficiency metrics, and introduce rule-level heuristics to improve planning efficiency without sacrificing feasibility.
- Abstraction granularity ablation: compare different abstraction levels (object-centric, relation-centric, predicate logic) and quantify their impacts on hallucination reduction and success rates.
- Integration with tool-use/memory frameworks: study synergy or redundancy with methods like Reflexion, ReasoningBank, or ToT; provide controlled ablations showing additive or overlapping gains.
- Formal link to latent dynamics: make explicit how symbolic rules reshape the agent’s implicit model of ; connect rule updates to changes in decision boundaries or policy class constraints.
- Safety and calibration: establish safeguards so rules do not encode dangerous or incorrect procedures; implement confidence calibration and human override for high-stakes actions.
- Benchmarking breadth and rigor: report statistical significance, multiple seeds, and robustness across diverse task distributions; open-source prompts, rule repositories, and evaluation scripts for reproducibility.
- Web–embodied bridging details: clarify sample selection and generalization in the Embodied Web Agent benchmark; examine whether web-derived rules contaminate embodied planning or vice versa.
- Hybrid symbolic–neural representations: explore translating verbalized rules into executable constraint solvers or planners, enabling stronger guarantees and faster consistency checks.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now by leveraging the paper’s training-free experiential alignment framework (WorldMind), which builds a symbolic World Knowledge Repository (WKR) from Process Experience (prediction-error-derived causal rules) and Goal Experience (heuristics from successful trajectories).
- Robotics alignment layer for LLM-based controllers (robotics, logistics, home automation)
- Description: Add a Predict-Act-Verify loop and WKR retrieval to existing ROS- or VLA-based robot stacks to reduce physically invalid actions (e.g., “pick without grasp” or “cut without tool”) and improve task sequences in domestic tasks (cleaning, cooking) and industrial handling.
- Potential tools/products/workflows: “WorldMind Alignment Layer” SDK; ROS plugin for Process Experience and Goal Experience; rule retrieval/gating module; E2E logs for prediction-error capture.
- Assumptions/dependencies: Reliable visual grounding (VLM accuracy), access to sensors and action semantics, domain-specific state abstraction schema for objects and affordances.
- Warehouse and factory mobile manipulation optimization (robotics, manufacturing)
- Description: Deploy WorldMind to reduce downtime and damage by learning explicit physical constraints per site (e.g., “cannot push pallet unless forks are lowered”) from execution errors; reuse WKR across different robot models due to cross-model transferability.
- Potential tools/products/workflows: Facility-specific “Experience Packs” (WKR snapshots), retrieval-enhanced task planner, incident-driven rule synthesis.
- Assumptions/dependencies: Consistent telemetry to detect divergences, integration with safety PLCs, mapping between low-level controls and abstract causal rules.
- Web and desktop RPA agents that learn from failures rather than retraining (software, enterprise automation)
- Description: Use Process Experience to encode UI constraints (e.g., “cannot submit until mandatory fields are filled”) and Goal Experience to improve workflow heuristics for multi-step forms, reporting pipelines, and ERP automations.
- Potential tools/products/workflows: Connectors to Selenium/Playwright; DOM-state abstraction; execution logs to WKR; constrained action gating in ReAct-style agents.
- Assumptions/dependencies: Stable UI state access (DOM or accessibility tree), consistent state abstraction, change management for evolving interfaces.
- Safety layer for LLM tool-use and DevOps assistants (software/IT operations)
- Description: Gate risky tool calls (file deletion, DB migration, service restart) if preconditions are not grounded in observed state; codify constraints as rules derived from prior failures across environments.
- Potential tools/products/workflows: Tool-call guardrails backed by WKR; policy-enforced action gating; auditable execution traces.
- Assumptions/dependencies: Reliable system-state introspection (e.g., filesystem, service health probes), appropriate access controls, human-in-the-loop override for critical actions.
- Smart home task orchestration with grounded routines (consumer IoT)
- Description: Improve home assistants’ reliability in multi-device routines (kitchen, cleaning) using Goal Experience (e.g., “preheat oven before placing tray”) and Process Experience (e.g., “must detect device online before toggling state”).
- Potential tools/products/workflows: Home hub integration; device API grounding; routine planner with gated simulation for unobserved devices.
- Assumptions/dependencies: Device discoverability/APIs, local perception (camera/sensors) where needed, privacy-preserving logging.
- AgentOps/MLOps knowledge sharing across agent versions (software tooling)
- Description: Maintain a WKR registry to share universal physical and process rules across model upgrades and variants; enable reproducibility and auditability of agent behavior without retraining.
- Potential tools/products/workflows: WKR registry service; semantic retrieval; versioned rule snapshots; CI/CD hooks for agent deployments.
- Assumptions/dependencies: Data governance and privacy policies, stable abstraction schema, compatibility across model APIs.
- Education and research labs for embodied AI (academia, education)
- Description: Use EB-ALFRED/EB-Habitat-style setups to teach predictive coding and experiential alignment; students can inspect how prediction errors become actionable rules that reduce physical hallucinations.
- Potential tools/products/workflows: Course modules; visualization tools for prediction vs actual state; open-source WorldMind implementation; benchmark-driven labs.
- Assumptions/dependencies: Access to simulated environments, basic GPU/compute for VLMs, curated tasks with clear abstractions.
- Digital twin calibration through error-driven rules (manufacturing)
- Description: Improve fidelity of digital twins by converting execution discrepancies into symbolic constraints that better reflect real-world limits (e.g., clearances, tool reachability).
- Potential tools/products/workflows: Twin-state abstraction; rule synthesis from discrepancy logs; constrained planning in the twin.
- Assumptions/dependencies: High-quality telemetry and synchronization between physical and twin states; robust abstraction mapping.
Long-Term Applications
The following use cases build on the paper’s innovations but require further research, scaling, or development—especially in perception fidelity, standardization, synchronization, and regulatory assurance.
- Fleet-level shared world models for multi-agent collaboration (robotics, logistics)
- Description: Real-time WKR synchronization across robot fleets to enable collective learning of constraints and heuristics, with conflict resolution and consensus building.
- Potential tools/products/workflows: WKR sync service; distributed knowledge graph; multi-agent conflict arbitration; privacy-aware sharing.
- Assumptions/dependencies: Low-latency networking, consistent abstraction schemas, reliable identity/traceability, organizational buy-in.
- Autonomous driving and aerial robotics experiential alignment (mobility)
- Description: Encode error-derived constraints from near-miss events and edge cases into WKR, gating planned maneuvers based on grounded observations to reduce physically invalid actions.
- Potential tools/products/workflows: Perception-to-abstraction pipelines; safety rule graphs; constrained trajectory planners with gating; simulation-to-real transfer.
- Assumptions/dependencies: High-fidelity perception, robust localization, extensive scenario coverage, regulatory approval and certification.
- Healthcare automation and assistive robotics with procedural safeguards (healthcare)
- Description: Use Process Experience for strict procedural constraints in clinical workflows and assistive devices; Goal Experience to optimize multi-step paths (non-invasive, non-critical initially).
- Potential tools/products/workflows: EHR-integrated assistants; assistive robot task planners; auditable WKR for compliance.
- Assumptions/dependencies: Rigorous validation, safety case development, human-in-the-loop supervision, HIPAA/compliance, extremely high perception accuracy.
- Standardized WKR formats and exchange protocols (industry consortiums, policy)
- Description: Establish sector-wide schemas for symbolic causal rules and procedural heuristics to enable interoperable knowledge sharing across agents and vendors.
- Potential tools/products/workflows: Open standards for WKR; benchmarks focused on physical laws and future-state prediction; certification processes.
- Assumptions/dependencies: Multi-stakeholder coordination, legal frameworks for sharing, alignment on abstractions and ontologies.
- Generalist embodied agents that robustly transfer across environments (cross-domain AI)
- Description: Build universal WKR libraries that capture transferable physical laws and procedural patterns across households, warehouses, and hospitals.
- Potential tools/products/workflows: Domain-agnostic abstraction layers; cross-environment retrieval; curriculum that sequences environment families.
- Assumptions/dependencies: Broad coverage of physical affordances; scalable retrieval; continual learning with conflict management.
- Safety certification and audit frameworks for agentic systems (policy, compliance)
- Description: Leverage explicit symbolic rules to support formal auditing, incident forensics, and standardized safety attestations for LLM-powered agents.
- Potential tools/products/workflows: Audit trail generators; conformance checkers against WKR; compliance dashboards.
- Assumptions/dependencies: Trusted logging, formal verification methods, regulatory recognition of neuro-symbolic artifacts.
- Edge deployment and latency-sensitive optimization (embedded systems)
- Description: Exploit selective, gated simulation to reduce inference latency on edge devices; local WKR caching to avoid heavy sampling or external simulators.
- Potential tools/products/workflows: On-device WKR caches; vector retrieval optimized for embedded; model compression; hardware-aware gating.
- Assumptions/dependencies: Efficient VLMs on edge, memory constraints, robust retrieval under limited compute.
- Mechanistic alignment analysis tools for world-model interpretability (academia, tooling)
- Description: Develop methods to map how explicit WKR rules reshape the agent’s latent transition boundaries, providing cognitive and mathematical explanations for alignment.
- Potential tools/products/workflows: Visualization suites; boundary-shift metrics; counterfactual analysis; integration with interpretability libraries.
- Assumptions/dependencies: Access to model internals or probe interfaces, standardized experimental protocols, collaboration between ML and cognitive science.
Cross-cutting assumptions and dependencies
- Perception fidelity: The approach depends on reliable visual-language perception; fundamental misclassifications can limit correction effectiveness.
- State abstraction design: Domain-specific schemas are necessary to convert raw observations to actionable causal variables.
- High-quality error signals: Accurate detection of divergence between predicted and actual states is crucial to synthesize useful rules.
- Governance and privacy: Sharing WKR across teams or fleets requires data governance, privacy, and compliance.
- Human oversight: For safety-critical domains, maintain human-in-the-loop review and escalation pathways.
- Tooling integration: Practical deployments need connectors to robotics middleware (ROS), RPA tools, device APIs, and logging/observability stacks.
Glossary
- Ablation study: An evaluation method that removes or isolates components to measure their individual contributions. "Ablation Study"
- Agentic AI: A paradigm of AI systems that act as autonomous, tool-using, self-correcting agents. "Agentic AI's core is a reflective, self-correcting loop, leveraging tools, memory, and constraints for open-world robustness and interpretability"
- Agentic world model: An internal simulation within an agent used to plan and predict environmental dynamics while acting. "planning with an agentic world model presents a dual challenge:"
- Best-of-N (BoN): A baseline strategy that samples multiple candidates and selects the best-performing one. "Best-of-N (BoN)"
- Constrained simulation: Generating internal predictions under explicit constraints to prevent ungrounded or impossible outcomes. "guide decision-making through constrained simulation."
- Cross-model transferability: The ability for knowledge or strategies learned by one model to benefit different model architectures. "remarkable cross-model transferability"
- EB-ALFRED: An embodied AI benchmark focused on household tasks and language-guided manipulation and navigation. "EB-ALFRED"
- EB-Habitat: An embodied AI benchmark leveraging the Habitat environment for navigation and manipulation tasks. "EB-Habitat"
- Embodied intelligence: Intelligence that emerges from acting and learning through physical or simulated bodies in environments. "foundational to the pursuit of embodied intelligence."
- Embodied Web Agent benchmark: A hybrid evaluation combining web interaction with embodied execution tasks. "the Embodied Web Agent \citep{hong2025embodied} benchmark."
- EmbodiedBench: A suite of benchmarks designed to evaluate embodied agents across diverse capabilities. "EmbodiedBench"
- Epistemic signals: Information that reduces uncertainty about the environment, aiding learning of dynamics or rules. "rich epistemic signals that reveal environmental boundaries."
- Goal Experience: Experience distilled from successful trajectories that guides efficient task completion via heuristics. "Goal Experience to guide task optimality through successful trajectories."
- Goal-Conditioned Success (GC): A metric granting partial credit for correctly executed subgoals even if the final goal fails. "Goal-Conditioned Success (GC)"
- Latent transition dynamics: The underlying (often unobserved) state-change function of the environment. "represents the latent transition dynamics."
- LLMs: High-capacity neural networks trained on vast corpora to perform language understanding and generation. "LLMs exhibit a critical modal disconnect"
- Observation function: The mapping that produces observable inputs from the hidden state of the environment. "The observation function yields visual inputs "
- Parametric encapsulation: Storing knowledge in fixed model parameters, which can limit adaptability. "such parametric encapsulation is inherently rigid"
- Partially Observable Markov Decision Process (POMDP): A decision process where the agent receives incomplete observations of the true state. "Partially Observable Markov Decision Process (POMDP)"
- Physical hallucinations: Plans or predictions that are logically coherent but violate physical constraints, making them infeasible. "significantly reducing physical hallucinations."
- Policy search space: The set of policies explored during planning or learning to achieve task objectives. "serve to constrain the policy search space towards the optimal policy "
- Predict-Act-Verify loop: An iterative cycle where the agent predicts outcomes, acts, and verifies results to learn constraints. "operates in a Predict-Act-Verify loop."
- Predictive Coding: A theory positing that intelligence minimizes prediction errors between expectations and observations. "Predictive Coding"
- Process Experience: Causal rules derived from prediction errors that enforce physical feasibility. "Process Experience to enforce physical feasibility via prediction errors"
- Reality gap: The mismatch between learned models or policies and real-world environmental dynamics. "reality gap:"
- ReAct: A prompting framework that interleaves reasoning and acting for tool-augmented agents. "ReAct"
- Semantic abstraction: Converting detailed states into high-level, concept-centric descriptions for reasoning. "semantic abstraction process"
- Sensorimotor contingencies: Regularities linking actions (motor outputs) to sensory outcomes, used for refining control. "sensorimotor contingencies."
- Self-Reflexion: A reflective procedure that synthesizes corrective rules from errors and interaction history. "through Self-Reflexion, the agent addresses the identified conflict"
- State Abstraction: The step of summarizing environment states into high-level variables for comparison and learning. "State Abstraction"
- Success Rate (SR): A strict binary metric indicating complete task achievement. "Success Rate (SR)"
- Surrogate model: An approximate model used to emulate or constrain aspects of the true dynamics. "learned surrogate model"
- Transition dynamics: The function describing how actions transform current states into next states. "transition dynamics "
- World Knowledge Model (WKM): A planner that encodes world knowledge explicitly into the agent’s planning process. "World Knowledge Model (WKM)"
- World Knowledge Repository: An explicit memory of causal rules and procedural heuristics used to guide planning. "World Knowledge Repository"
- World Knowledge-Augmented Markov Decision Process (WK-MDP): An MDP formulation extended with external world knowledge for guidance. "World Knowledge-Augmented Markov Decision Process (WK-MDP)"
- World Models: Models that learn environment dynamics to predict and plan future outcomes. "World Models learn internal representations of environment dynamics for prediction and planning,"
- WorldMind: The proposed framework that aligns agentic world models via process and goal experiences. "we introduce WorldMind, a framework that autonomously constructs a symbolic World Knowledge Repository"
Collections
Sign up for free to add this paper to one or more collections.