- The paper introduces a hint-based approach that extracts intermediate facts from SMT proofs to guide certified Lean proof reconstruction.
- It details a translation pipeline from Lean to SMT-LIB, emphasizing natural number and datatype handling alongside improved set-of-support strategies.
- Empirical results on nearly 10,000 theorems demonstrate querysmt's efficiency over traditional replay methods by leveraging granular SMT hints.
Hint-Based SMT Proof Reconstruction in Lean
Motivation and Context
Integrating SMT solvers with proof assistants aims to harness the complementary strengths of ATPs and ITPs: ATPs, notably SMT solvers like cvc5, produce machine-generated proofs rapidly but often sacrifice strong soundness guarantees, while ITPs (e.g., Lean) provide foundational rigor and expressivity at the cost of significant manual guidance. Bridging these paradigms has historically relied on either direct proof replay (verifying an SMT proof in the assistant) or premise selection (rediscovering a proof inside the ITP using minimal dependencies suggested by the external prover). Both approaches entail trade-offs in robustness, modularity, and user transparency.
"Hint-Based SMT Proof Reconstruction" (2601.14495) introduces a new methodology centered on extracting "hints" from SMT solver proofs and feeding these as intermediate facts to guide the ITP’s internal automation. This approach is implemented as the querysmt tactic in Lean, leveraging the cvc5 solver as an external oracle, but without requiring persistent dependency on it.
The querysmt Approach
Unlike traditional proof replay, the hint-based approach aims to capture salient derived facts (hints) during SMT solving, formalize their Lean analogues, and use these as waypoints in reconstructing a certified Lean proof. These hints include preprocessing lemmas, theory lemmas, and intermediate rewrites—crucial logical fragments that SMT solvers utilize but are typically opaque to or discarded by traditional reconstruction pipelines.
The implementation pipeline consists of:
- Preprocessing: The Lean goal is normalized, Skolemized, and restated in a context suitable for SMT translation, ensuring all necessary premises and Skolem functions are exposed.
- Translation: Lean’s dependent type-theoretic statements are translated into SMT-LIB, with special attention to datatypes and natural number encodings (including expanded non-negativity constraints to preserve semantics, especially for types like Nat×Int).
- Hint Generation: cvc5 is instrumented to emit preprocessing and theory reasoning steps instead of only final certificates.
- Hint Interpretation: Hints from cvc5 are mapped back into Lean, sometimes via the construction of synthetic selectors or coercions due to the non-injective and non-surjective characteristics of SMT-LIB/Lean translations.
- Proof Reconstruction: Utilizing the grind tactic for theory side-goals and the superposition prover duper for first-order reasoning, querysmt composes a Lean-native, self-contained proof script.
The procedure is succinctly captured in the querysmt pipeline schematic:
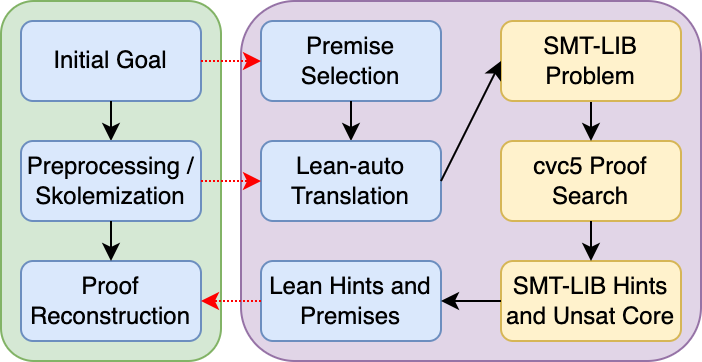
Figure 1: The querysmt workflow, showing the interaction between Lean and SMT stages, and delineating which proof stages are replayed in Lean and which remain as external guidance.
Example Proof Script Synthesis
An application of querysmt yields proof scripts that explicitly codify intermediate SMT lemmas. These scripts are minimal, as they are post-filtered to retain only hints contributing to the final reconstructed proof. The produced Lean source can be further cleaned up or simplified by the user.
Technical Contributions
- cvc5 Instrumentation: Extended to report granular proof search data (preprocessing, theory lemmas, rewrites).
- Natural Number and Datatype Handling: The translation not only captures the complexities of Lean types but also ensures that well-formedness and non-negativity constraints are preserved, in line with the original semantics.
- Set of Support in duper: The given-clause superposition strategy in duper is improved to incorporate SMT hints efficiently, balancing theory axiom explosiveness and search tractability.
- Benchmarking: Extensive empirical evaluation on 9,904 theorems in Lean’s init, Batteries, and Mathlib collections, focusing on integer/nat/list domains.
Empirical Results
The primary experimental findings demonstrate:
- Significant advantage from SMT hints: On integer and natural number theorems, querysmt (with hints) outperforms prior tactics, proving 840 Int, 892 Nat, and 749 List theorems within the 30s timeout.
- Improvement over replay-only methods: In the same benchmarks, direct proof replay (lean-smt) or grind alone solve strictly fewer goals.
- Hint Utility: The majority of cvc5’s provided hints are automatically discharged by grind; only ~5% require further user intervention.
- Proof Script Readability: After relevance filtering, most proofs have 0–2 extra lemmas in addition to the user-supplied premises, balancing script succinctness and proof auditability.
A key claim, strongly substantiated by the results, is that granular SMT hints substantially increase the reconstructive capacity and success rate of internal Lean proof automation compared to approaches not leveraging such fine-grained guidance.
Theoretical and Practical Implications
The hint-based approach obviates continued reliance on external SMT solvers for proof checking. This increases the long-term stability, auditability, and maintainability of proof artifacts in Lean, especially when external ATPs are subject to version and heuristic variability. Additionally, the explicit representation of intermediate results—and the decoupling from the SMT solver after proof script generation—makes proof engineering more transparent and resilient to upstream changes.
From a theory perspective, the approach reifies a middle ground between proof replay (which suffers from brittleness and theory divergence) and “premise minimization” (which offloads all search responsibility and easily fails for complex SMT tactics). It highlights the feasibility and technical benefits of extracting “just right” information granularity from ATP proofs.
Limitations and Future Prospects
Several intrinsic limitations remain:
- Induction and Completeness: Querysmt’s efficacy is constrained by the SMT solver’s inability to perform induction, especially on datatype theorems requiring nontrivial inductive reasoning.
- Type System Mismatches: The non-injective and non-surjective nature of Lean–SMT-LIB mappings complicates hint replay in some cases, especially with custom datatypes.
- Proof Script Verbosity: In cases of SMT-level Skolemization or large unsat cores, generated scripts can be verbose or harder to interpret, though postprocessing can mitigate this.
Potential extensions include broader SMT theory support, handling quantified formulas more robustly (mirroring recent improvements in Sledgehammer for metis), and systematic integration in assistants beyond Lean.
Conclusion
Hint-based SMT proof reconstruction, as realized in the Lean querysmt tactic, offers a robust, modular, and empirically validated solution to bridging ATPs and ITPs. By extracting semantically meaningful intermediate facts—rather than replaying or rediscovering entire proofs—this approach enhances the automation and soundness guarantees available to Lean users, while maintaining transparency and proof independence from SMT solvers. The paradigm is readily extensible and forms a solid foundation for future work in interactive theorem-prover/SMT integration.