Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Abstract: LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Seed‑Prover: Deep and Broad Reasoning for Automated Theorem Proving — Explained Simply
What is this paper about?
This paper shows how a team built two smart systems that can solve very hard math problems (like those from the International Mathematical Olympiad, IMO) by writing computer-checked proofs. The two systems are:
- Seed‑Prover: an AI that writes full proofs in a precise math language called Lean.
- Seed‑Geometry: a special tool that focuses on geometry problems.
The big idea is to combine long, careful thinking (like a detailed plan) with strict, automatic checking (so there are no mistakes). This lets the AI handle problems that are far too tricky to judge in everyday words.
What questions were the authors trying to answer?
In simple terms:
- How can we teach AIs to write correct math proofs when normal sentences are too vague to check automatically?
- Can we get better results by breaking big proofs into smaller “mini‑proofs” (called lemmas) and improving them step by step?
- Can we make a geometry engine that fills in helpful constructions (like extra lines or points) and proves geometry results fast?
- If we let the AI “think” longer and in smarter ways at test time, does it solve more problems?
How did they do it?
They used a few key ideas and tools. Here are the tricky parts explained with everyday analogies:
- Formal proofs in Lean: Think of Lean as a super strict math teacher who checks every tiny step of your solution instantly. If Lean accepts your proof, it’s guaranteed correct.
- Lemma‑style proving (building with Lego bricks): Instead of trying to solve the whole problem in one go, Seed‑Prover first proves small, useful facts (lemmas). These lemmas are like Lego pieces—easy to reuse, combine, and track. The system keeps a “lemma pool” (a library) with names, statements, how hard they were, and how they depend on each other.
- Iterative refinement (fix it and try again): When Lean points out errors (like syntax mistakes or missing steps), the model fixes them and refines the proof, several times if needed. It also writes quick summaries for itself to stay organized.
- Conjecture proposing (smart “what‑if” guesses): Before diving deep, the model brainstorms many possible properties that might be true (for example, “maybe this function is one‑to‑one,” or “maybe the sequence is periodic”). It then tries to prove or disprove these. The ones that succeed become extra Lego pieces (lemmas) in the pool.
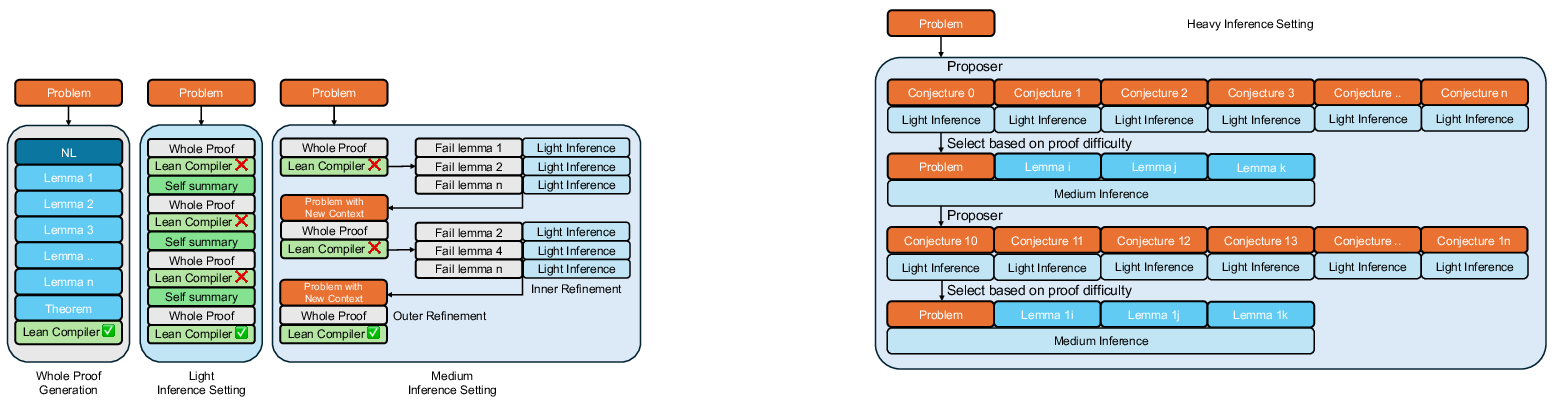
- Test‑time scaling (giving the AI time to think):
- Light: Make a proof attempt and refine it several times using Lean’s feedback.
- Medium: Like Light, but also pause to separately prove any hard lemmas the main attempt created.
- Heavy: Start by generating thousands of conjectures, try to prove lots of small facts, collect the best lemmas, then finish the main proof using those lemmas.
- Seed‑Geometry (a geometry problem solver):
- Forward‑chaining engine: Imagine a rulebook like “if A and B are true, then C must be true.” The engine keeps applying all matching rules to discover everything it can from the diagram until nothing new appears.
- Better language for constructions: Instead of using long, step-by-step “ruler-and-compass” instructions, they use compact “combo moves” (like “isogonal conjugate” or “exsimilitude center”). This makes problem descriptions short and easier for the AI and engine.
- Much faster backend: Rewriting the engine in C++ made it about 100× faster, which is crucial when exploring lots of possibilities.
- Beam search (maze exploration): The system explores multiple promising paths at once, keeping the most likely ones, like trying several routes in a maze and expanding the best ones.
- Training (practice with rewards): The AI learns by reinforcement learning (RL): it gets a reward if Lean accepts the proof (1) and no reward if it fails (0). During training, they sometimes include hints, previous failed attempts, summaries, and Lean’s error messages in the prompt so the model learns to use all kinds of help. They also gradually increase problem difficulty and output length.
What did they find?
The systems performed extremely well on many tough benchmarks:
- IMO 2025: During the actual contest, they fully solved 4 out of 6 problems by the deadline; afterward, they reached 5 out of 6.
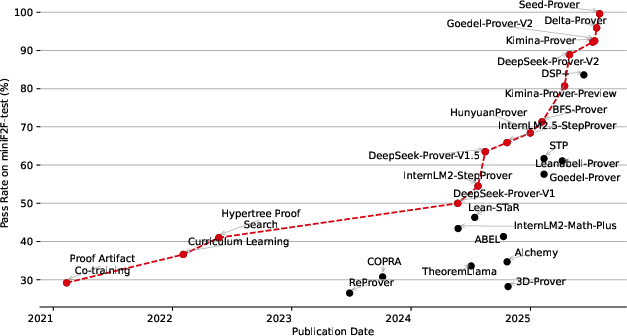
- Past IMO problems (formalized): Seed‑Prover solved 78.1%.
- MiniF2F (a popular formal math benchmark): Near 100% solved.
- PutnamBench (undergraduate math): 331 out of 657 problems—far higher than previous systems.
- CombiBench (combinatorics): 30%—better than earlier methods, though combinatorics remains challenging.
- MiniCTX‑v2 (context-heavy, real-world formalization): 81.8%.
For geometry, Seed‑Geometry outperformed earlier engines:
- It solved more IMO geometry problems (e.g., 43 on the IMO-AG-50 list) than the previous best system.
- It also set a new state of the art on difficult IMO shortlist geometry problems.
- It solved the IMO 2025 geometry problem in about 2 seconds (after the problem was formalized).
Why is this important? Because all these results are checked automatically by Lean, they aren’t guesses. They’re genuinely correct proofs—a big step toward trustworthy AI reasoning in math.
Why does this matter?
- Reliable reasoning: Formal proofs are like airtight arguments. This reduces the risk of AI “sounding convincing” but being wrong.
- Solving really hard problems: With step-by-step feedback, lemma libraries, and smart test-time “thinking,” the AI can tackle problems even expert humans find tough.
- Geometry boost: Many proof assistants don’t handle geometry easily. Seed‑Geometry fills that gap, showing how specialized engines can expand what AIs can do.
What could this lead to?
- Better math tools: Imagine homework helpers or study aids that don’t just give answers but produce guaranteed‑correct proofs.
- Stronger software checking: Formal reasoning can also verify computer programs and systems—important for safety and reliability.
- Research assistance: As these systems improve, they could help explore new math, organize big libraries of lemmas, and maybe even assist with open problems.
In short, the paper shows that combining long, careful thinking with strict, automatic checking can make AI provers both powerful and trustworthy—and that’s a big deal for the future of math and beyond.
Collections
Sign up for free to add this paper to one or more collections.