- The paper introduces scaffolded data synthesis and verifier-guided self-correction to iteratively repair and refine proofs in the Lean system.
- It employs an innovative training pipeline combining long chain-of-thought reasoning, self-correction using Lean compiler feedback, and model averaging to boost performance.
- Empirical results show a significant accuracy boost with up to 90.4% pass@32 on MiniF2F, achieving state-of-the-art performance with reduced model size and compute.
Introduction
Goedel-Prover-V2 presents a significant advancement in automated formal theorem proving, specifically targeting the Lean proof assistant. The model series leverages a combination of long chain-of-thought (CoT) reasoning, scaffolded data synthesis, verifier-guided self-correction, and model averaging to achieve state-of-the-art performance on standard benchmarks, notably MiniF2F and PutnamBench, with substantially reduced model and compute requirements compared to prior systems. The approach demonstrates that high-level formal reasoning can be achieved without resorting to extremely large models or excessive inference budgets.
Framework Innovations
Verifier-Guided Self-Correction
A central innovation is the integration of Lean compiler feedback into the proof generation loop. After an initial proof attempt, the model receives error messages from the Lean verifier, which are then incorporated into the input for subsequent rounds of proof repair. This iterative self-correction process enables the model to diagnose and fix errors in its own outputs, substantially improving synthesis accuracy and sample efficiency. The ablation studies confirm that explicit error messages and retention of previous CoT traces are critical for effective revision.
Scaffolded Data Synthesis
The training pipeline is augmented by scaffolded data synthesis, which generates synthetic problems of varying difficulty to provide dense learning signals. Two complementary strategies are employed:
- Formal-based synthesis: When a proof attempt fails, the extract_goal tactic in Lean is used to extract unsolved subgoals, which are then formalized as new training statements. Negations of these statements are also included to teach the model to recognize false propositions.
- Informal-based synthesis: LLMs are prompted to generate simpler subproblems or harder variants in natural language, which are subsequently formalized and filtered for correctness and non-triviality. This process is highly parallelized and leverages majority voting for quality control.
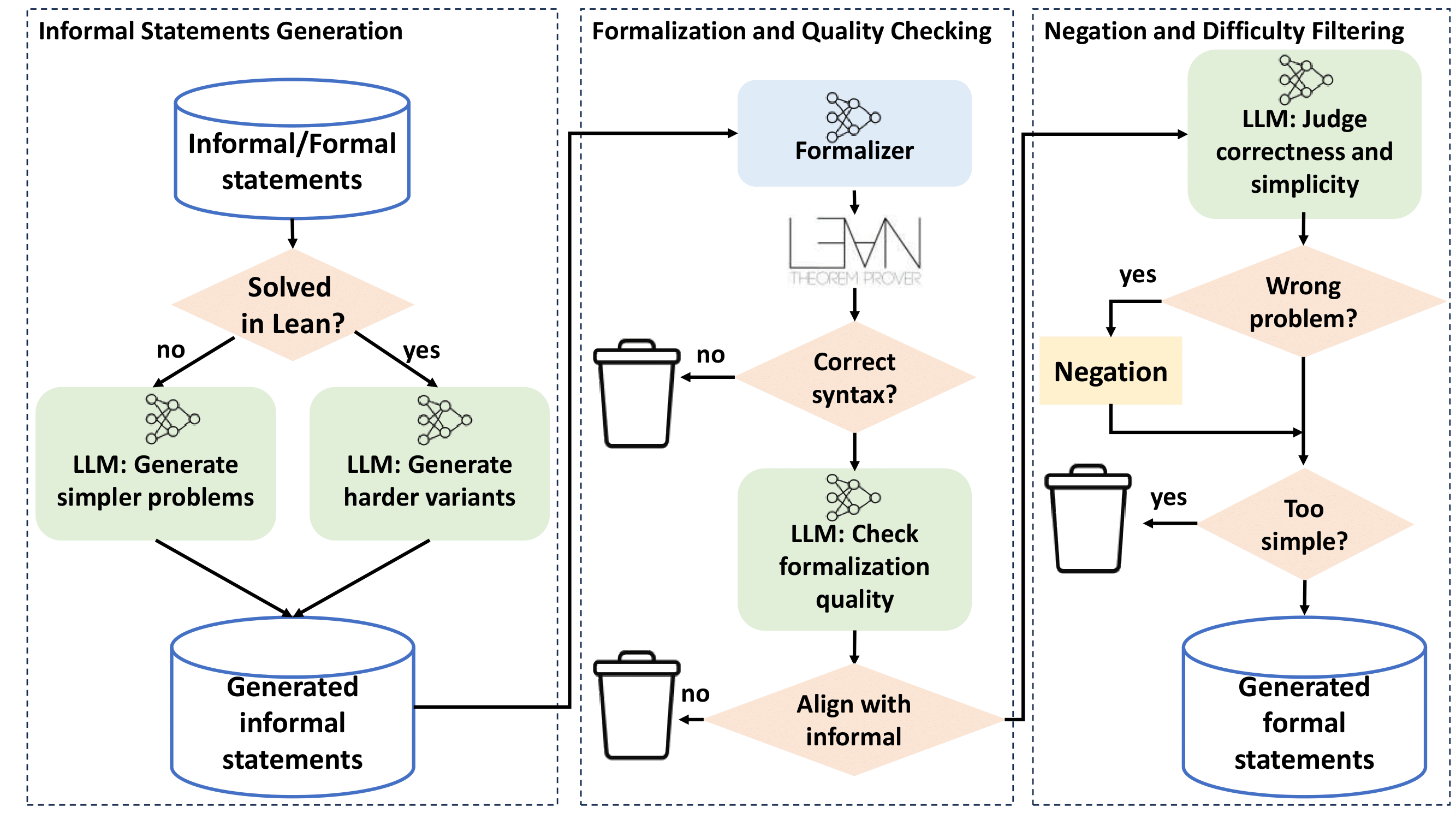
Figure 1: The informal-based scaffolded data synthesis pipeline, comprising statement generation, formalization and quality checking, and negation/difficulty filtering.
Model Averaging
To counteract diversity collapse in later training stages, model averaging is applied after both SFT and RL. The final model parameters are computed as (1−α)θ0+αθ, where θ0 is the base model and θ is the fine-tuned model. Empirical results show that this technique improves pass@N metrics by enhancing output diversity, especially in the context of self-correction.
Training Pipeline
The overall workflow consists of sequential SFT, scaffolded data synthesis, RL, and model averaging. The process is multi-stage:
- Initial SFT on a dataset generated by DeepSeek-Prover-V2.
- Annotation and incorporation of self-correction data.
- Scaffolded data synthesis to further expand the training set.
- RL with a hybrid GRPO-based algorithm, optimizing for both whole-proof generation and self-correction.
- Model averaging at each stage to maximize diversity and generalization.
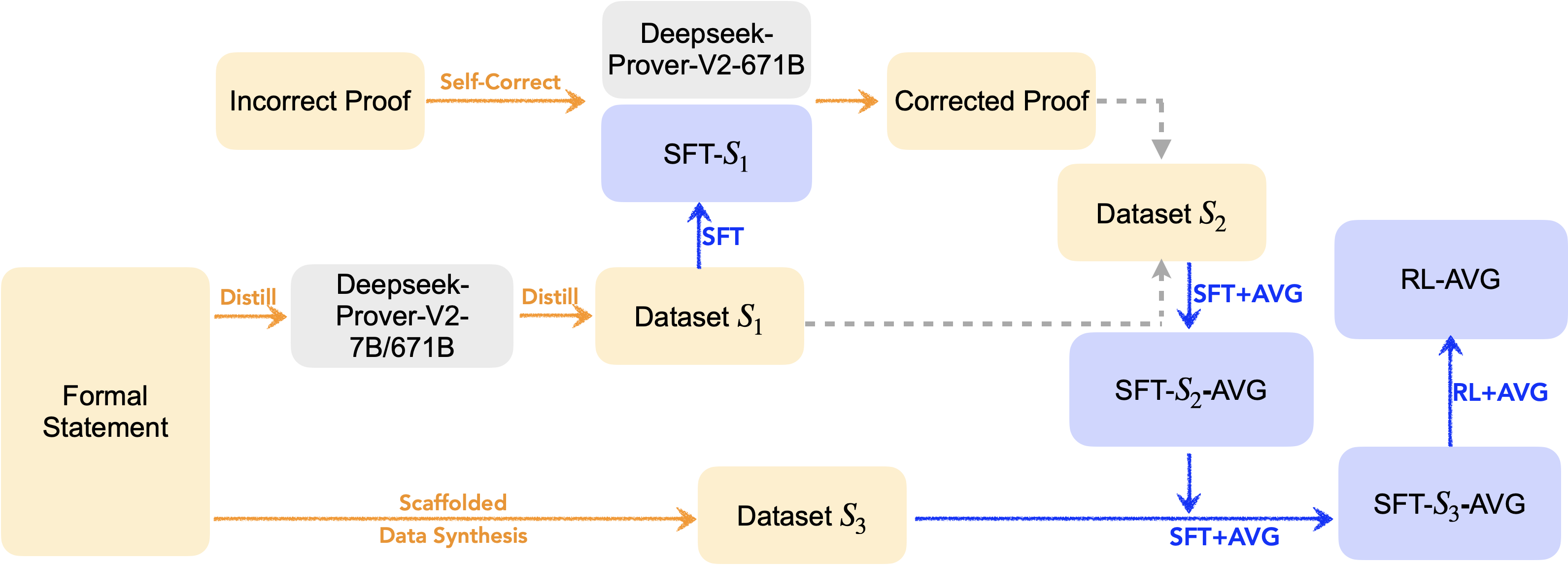
Figure 2: The complete model training workflow, including SFT, scaffolded data synthesis, RL, and model averaging.
Empirical Results
Goedel-Prover-V2-32B achieves 88.1% pass@32 on MiniF2F, rising to 90.4% with self-correction, outperforming DeepSeek-Prover-V2-671B (82.4%) and Kimina-Prover-72B (84.0%) at a fraction of the parameter count. The 8B variant matches or exceeds the performance of much larger models. On PutnamBench, the 32B model solves 86 problems under pass@184 with self-correction, compared to DeepSeek-Prover-V2's 47 solves under pass@1024.
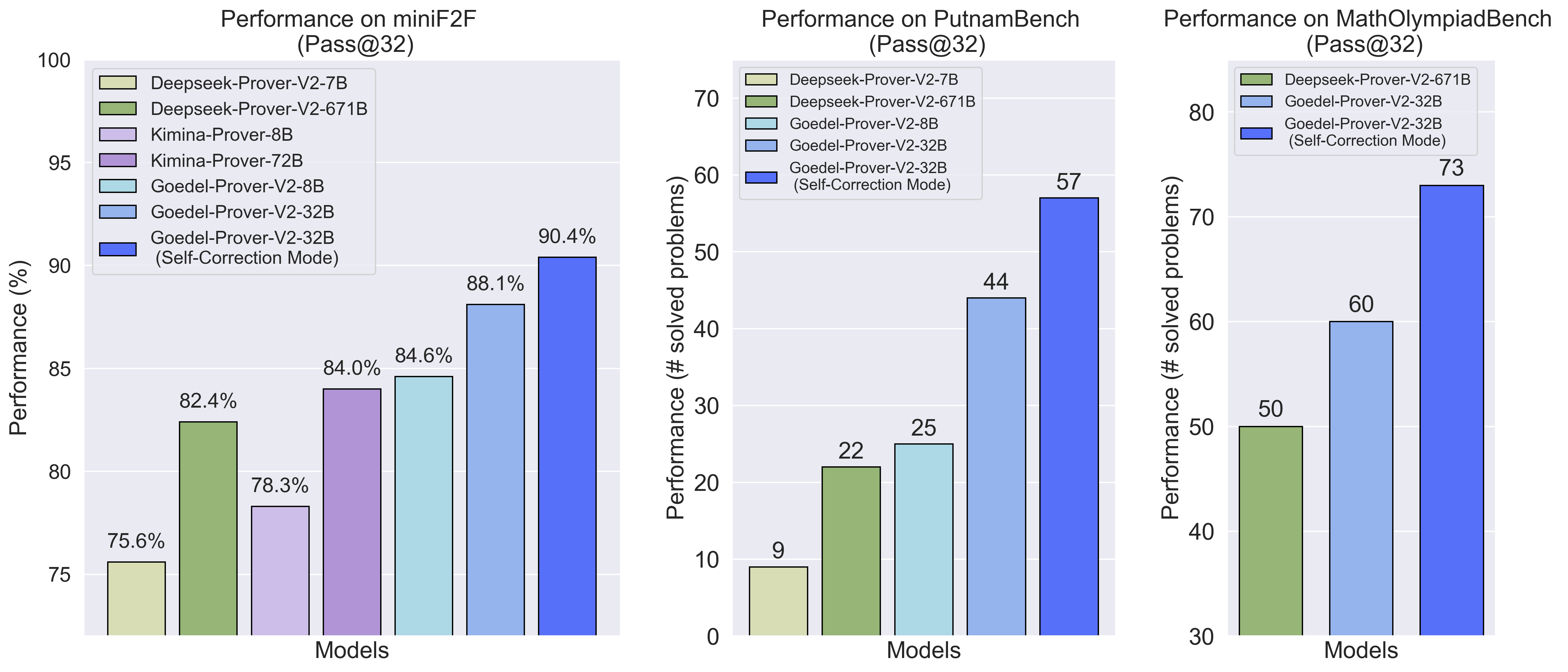
Figure 3: Performance of Goedel-Prover-V2 on different benchmarks under pass@32.
Sample Efficiency and Scaling
Goedel-Prover-V2 demonstrates strong sample efficiency, achieving high pass@N with minimal inference overhead. Scaling analysis shows that performance gains persist across increasing inference budgets, with self-correction providing consistent improvements. Extended context and additional revision iterations further boost accuracy, with pass@32 reaching 92.7% on MiniF2F using a 128k token context and 5 rounds of revision.
RL and Model Averaging Effects
Systematic evaluation of RL steps and model averaging ratios reveals that pass@1 increases with RL progression, while pass@N is maximized at an optimal averaging coefficient. Correction settings benefit more from RL and averaging, indicating that self-correction is particularly effective when combined with diverse model outputs.
Data Curation and Benchmarking
The formalization pipeline is rigorously validated, outperforming previous autoformalizers in both syntactic and semantic fidelity. MathOlympiadBench is introduced as a new benchmark, with careful human verification to ensure alignment between informal and formal statements. Distributional analysis confirms broad coverage across mathematical domains.

Figure 4: Distribution of problems in MathOlympiadBench by category.
Theoretical and Practical Implications
The results demonstrate that formal theorem proving can be advanced without reliance on massive models or proprietary infrastructure. The integration of verifier-guided self-correction with long CoT reasoning establishes a scalable paradigm for formal mathematics, enabling efficient, high-accuracy proof synthesis. The scaffolded data synthesis pipeline provides a blueprint for curriculum learning in formal domains, and model averaging offers a practical solution to diversity collapse in RL and SFT.
Future Directions
Potential avenues for further research include:
- Extending self-correction to multi-turn RL and tool-use frameworks for even greater sample efficiency.
- Exploring retrieval-augmented generation and hybrid proof search strategies to further improve correctness and generalization.
- Applying the scaffolded synthesis and self-correction framework to other formal systems (e.g., Coq, Isabelle).
- Investigating amortized inference-time repair strategies to optimize compute-resource scaling.
Conclusion
Goedel-Prover-V2 sets a new standard for open-source formal theorem proving, achieving state-of-the-art results with modest model sizes and compute budgets. The combination of scaffolded data synthesis, verifier-guided self-correction, and model averaging enables efficient, high-accuracy proof generation. The open release of models, code, and data is poised to accelerate progress in formal reasoning and provide a robust platform for future innovation in AI-driven mathematics.