- The paper presents the STP framework that doubles LeanWorkbook performance by implementing iterative conjecturing and proving to overcome data scarcity.
- It employs a self-play strategy where the model alternates roles between generating solvable conjectures and proving them using supervised fine-tuning on theorem-proof pairs.
- STP demonstrates state-of-the-art scalability on Lean and Isabelle through comprehensive benchmarks and ablation studies validating the impact of generated training signals.
STP: Self-play LLM Theorem Provers with Iterative Conjecturing and Proving
The paper "STP: Self-play LLM Theorem Provers with Iterative Conjecturing and Proving" presents the development of the Self-play Theorem Prover (STP), a novel approach aimed at expanding the capabilities of LLMs in the domain of formal theorem proving. This study addresses the critical challenge of limited high-quality training data in LLMs by introducing a mechanism that emulates the learning process of mathematicians, through iterative conjecturing and proving. STP significantly improves over traditional methods by doubling the best-known results on LeanWorkbook and achieving state-of-the-art performance on multiple theorem proving benchmarks.
Methodological Framework
Self-play Theorem Prover (STP)
The core contribution of the paper is the development of the STP framework, which simultaneously performs the roles of a conjecturer and a prover. Inspired by methodologies wherein mathematicians propose new equations and attempt solving them, the STP attempts to bridge the data scarcity gap in automated theorem proving.
The process begins with the conjecturer generating a new conjecture from a seed theorem and its existing proof. The prover then attempts to prove statements from both the existing dataset and the generated conjectures. The algorithm iteratively reinforces the conjecturer with conjectures that are solvable but challenging, while the prover is trained to prove these conjectures. This is visualized in Figure 1.
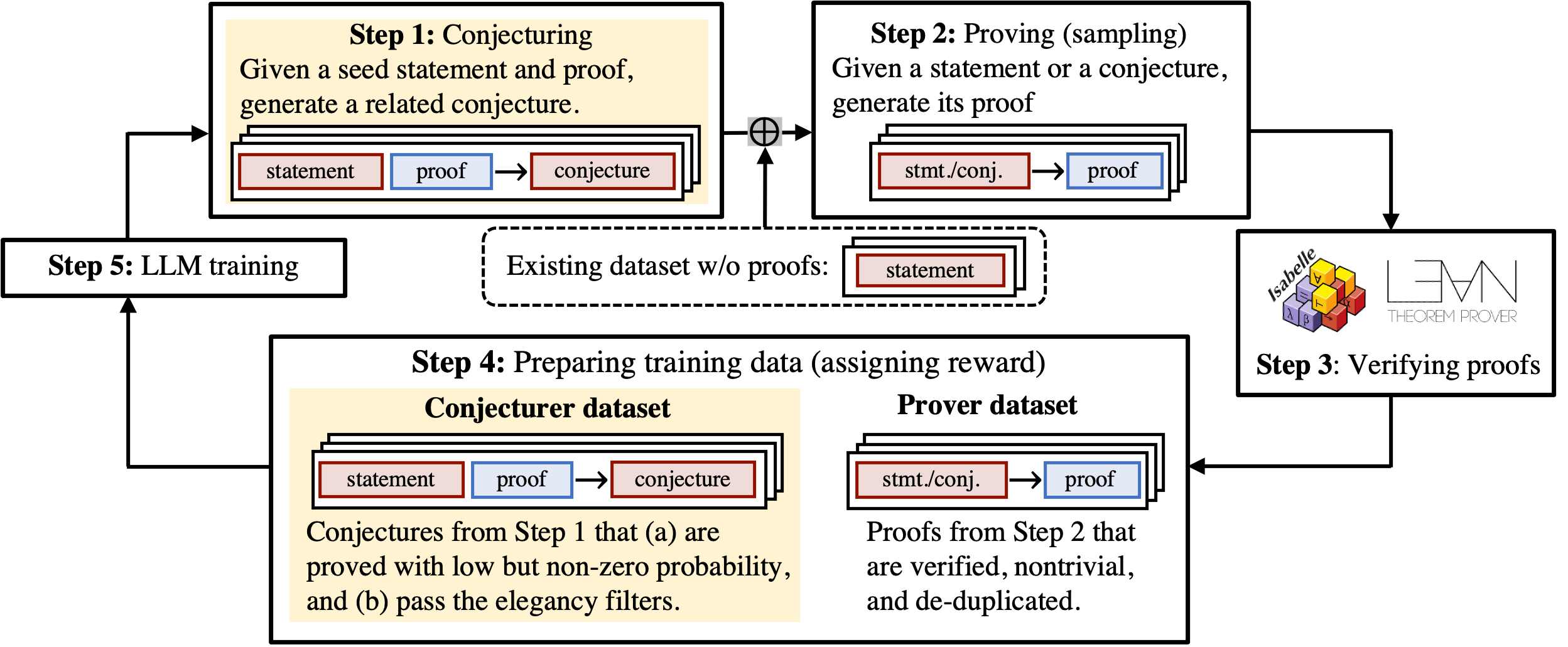
Figure 1: Self-play Theorem Prover (STP).
Execution of Self-play Training
The STP operates in a loop comprising several core steps:
- Initialization: The model is initialized with supervised fine-tuning (SFT) on an existing proof library. The data encompasses theorem-proof pairs for the prover and theorem-lemma-conjecture triplets for the conjecturer.
- Conjecture and Proof Generation: The conjecturer generates new conjectures and the prover attempts to establish proofs (Steps 1 and 2). A collection of inputs is curated from successfully proven existing theorems, and lemmas are extracted to focus conjecture generation.
- Training Signals and Rewards: The empirically successful proofs inform the training signal for the prover (Step 3). For the conjecturer, generated conjectures undergo screening based on factors such as provability, elegance, and approachability, with rewards designed to enhance diversity and challenge.
- Re-training: To combat training instabilities and ensure sustained model improvement, a final re-training stage is performed on both the given dataset and successful proofs from generated conjectures.
Comparison and Analysis
The STP's efficacy was rigorously tested using both Lean and Isabelle formal provers. The paper details the process of initial model fine-tuning, periodic refreshes to maintain training efficacy, and thoughtful management of training resources to avoid compute wastage.
The experimental results reveal that STP surpasses existing methods in scalability, reflected in the substantial performance boost on LeanWorkbook and various competitive benchmarks such as miniF2F and ProofNet.
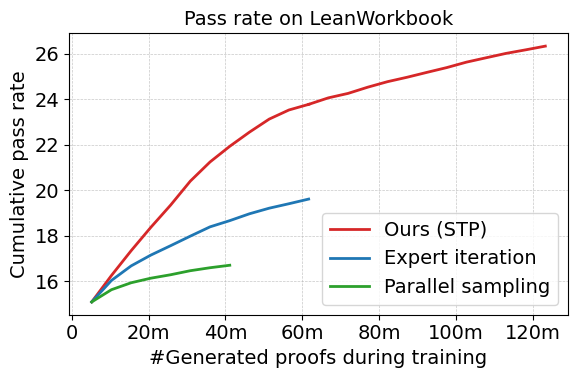
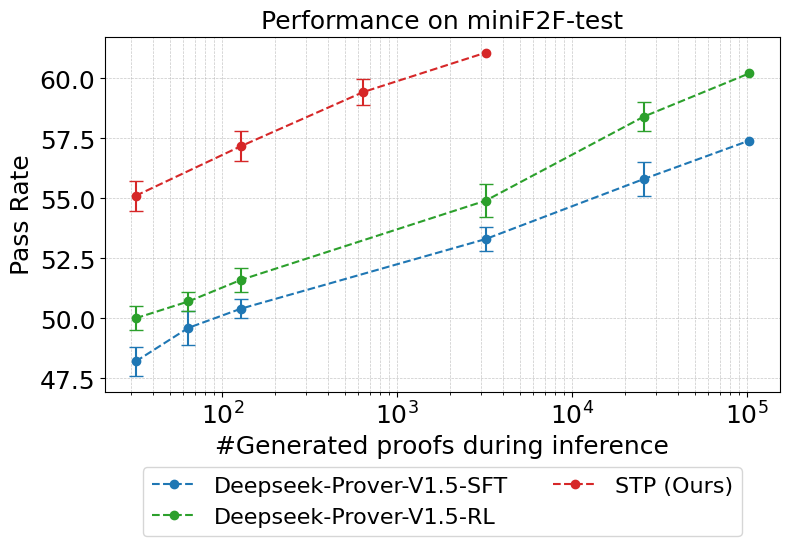
Figure 2: The cumulative pass rates of STP, expert iteration, and parallel sampling on LeanWorkbook.
Empirical Evaluations and Detailed Comparisons
Results with Lean
The STP demonstrated a cumulative pass rate of 26.3% on the LeanWorkbook dataset, outperforming previous best records achieved via expert iteration. As shown in Figure 2, STP exhibits superior scaling in performance relative to other strategies, achieving significant breakthroughs while maintaining computational efficiency.
Furthermore, when evaluated on benchmarks like miniF2F-test and Proofnet-test, STP attained outstanding scores of 61.1% (pass@3200) and 23.1% (pass@3200) respectively, reflecting improvements over previously leading models. The ablation study confirms that generated conjectures provide denser training signals, critically enhancing learning efficacy.
Results with Isabelle
During the Isabelle experiments, STP training displayed better scalability compared to the expert iteration baseline, effectively leveraging the math-focused model Llemma-7b, as illustrated in Figure 3.
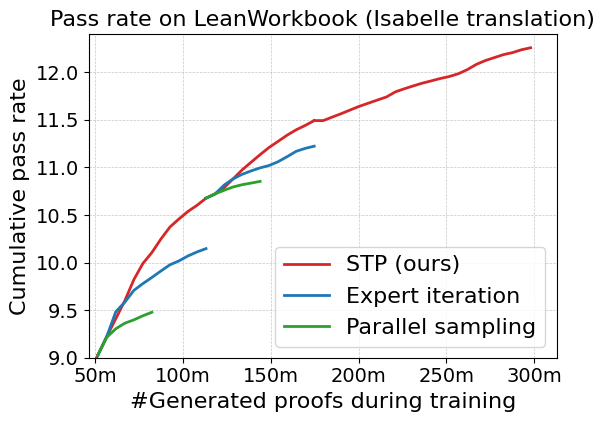
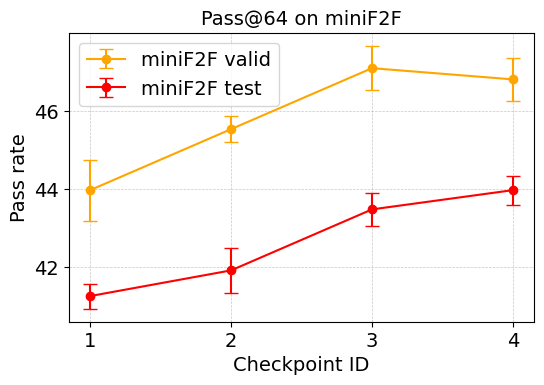
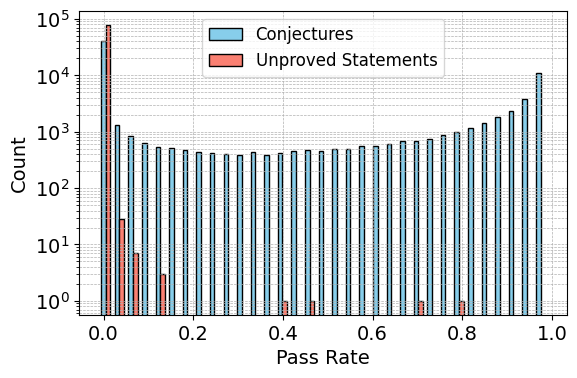
Figure 3: Left: Cumulative pass rate on LeanWorkbook (translated into Isabelle) of STP, expert iteration, and parallel sampling.
Ablation studies further validate the hypothesis that the training signals from generated conjectures were pivotal for performance gains.
Conclusion
The STP framework stands as a significant advancement in the ability of LLMs to conduct formal theorem proving in environments constrained by limited data. By mimicking a human-like iterative conjecturing and proving process, STP self-improves without the dependency on large external databases of propositions. This approach shows potential scalability across various formal proof environments and natural language-to-formal language applications, setting the stage for future developments in achieving AGI in reasoning tasks. The continued development and application of techniques like STP can have significant implications for the future of automated reasoning and formal theorem proving, paving the way for groundbreaking innovations in logical reasoning capabilities.