- The paper presents the integration of proof assistant feedback via reinforcement learning with a novel Monte-Carlo Tree Search variant (RMaxTS) to optimize proof search.
- It employs a multi-stage training approach including pre-training, supervised fine-tuning, and GRPO-based reinforcement learning to enhance formal proof generation in Lean 4.
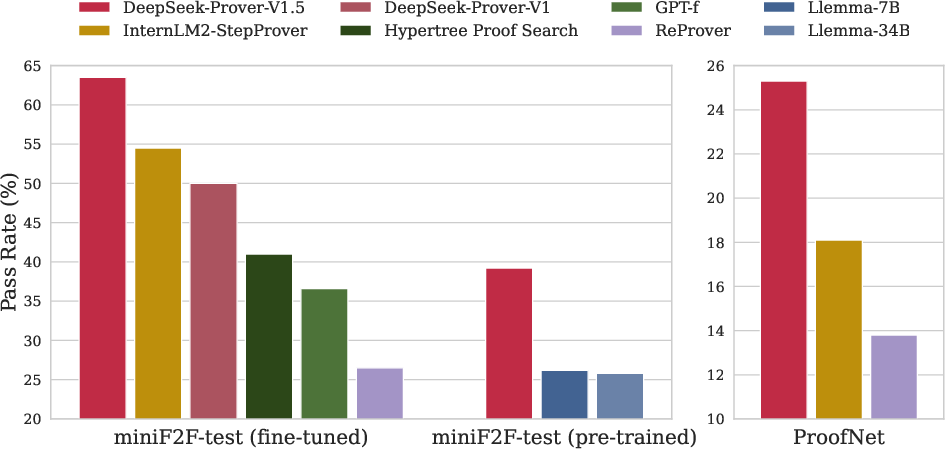
- Benchmark evaluations on miniF2F and ProofNet demonstrate state-of-the-art performance, with pass rate improvements up to 25.3% over previous models.
DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search
The paper presents DeepSeek-Prover-V1.5, an advanced open-source LLM aimed at optimizing theorem proving capabilities in formal mathematical languages, specifically within the Lean 4 environment. The model builds on its predecessor, DeepSeek-Prover-V1, by integrating enhanced training methodologies such as pre-training, supervised fine-tuning, and reinforcement learning from proof assistant feedback (RLPAF). Notably, the introduction of RMaxTS—a Monte-Carlo tree search variant with intrinsic-reward-driven exploration—distinguishes DeepSeek-Prover-V1.5 by significantly increasing the diversity and efficiency of proof search paths.
Training and Reinforcement Learning Framework
DeepSeek-Prover-V1.5's training involves a multi-stage approach:
- Pre-Training: The model is pre-trained on the DeepSeekMath-Base, enhanced with high-quality mathematical datasets focusing on formal languages like Lean, Isabelle, and Metamath, to bolster its mathematical reasoning and formal proof generation capabilities.
- Supervised Fine-Tuning: Utilizes an improved dataset augmented with Lean 4 proof codes and interspersed natural language explanations, fostering alignment between formal proofs and human reasoning processes. This stage introduces the truncate-and-resume mechanism, which is pivotal for the tree search within whole-proof generation.
- Reinforcement Learning: The GRPO algorithm is employed for RLPAF, leveraging proof assistant feedback for optimizing proof generation performance. This reinforcement learning phase refines the model by aligning its generated proofs with formal verification through binary reward signals derived from the Lean prover.
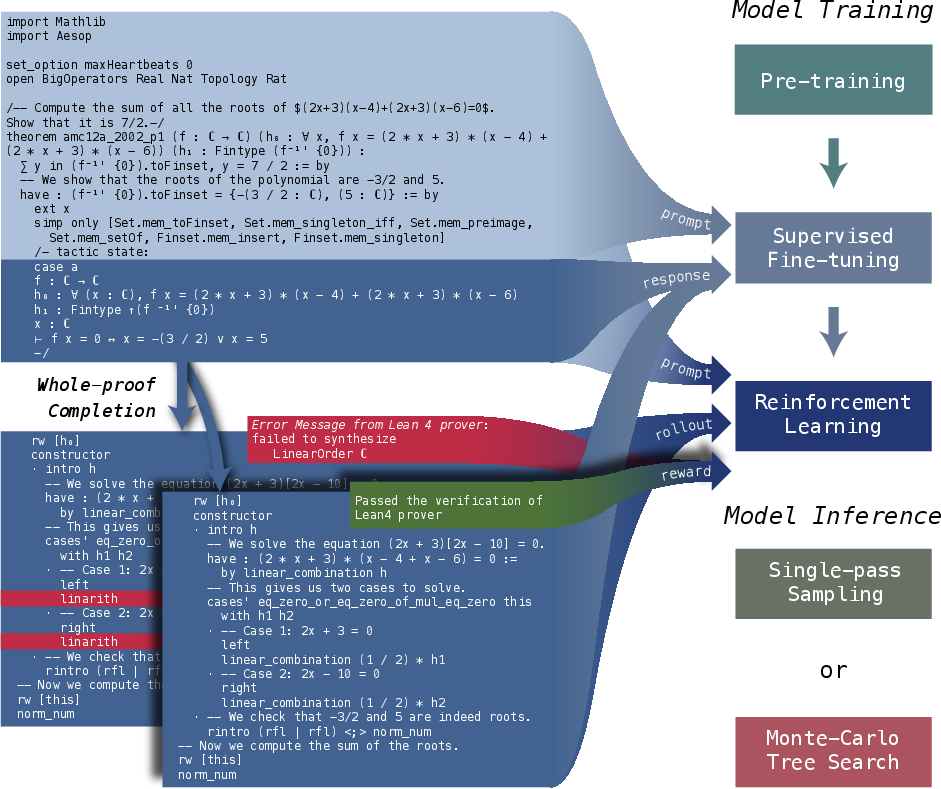
Figure 1: Overall Framework. DeepSeek-Prover-V1.5 is trained through pre-training, supervised fine-tuning, and reinforcement learning with verification results used as rewards.
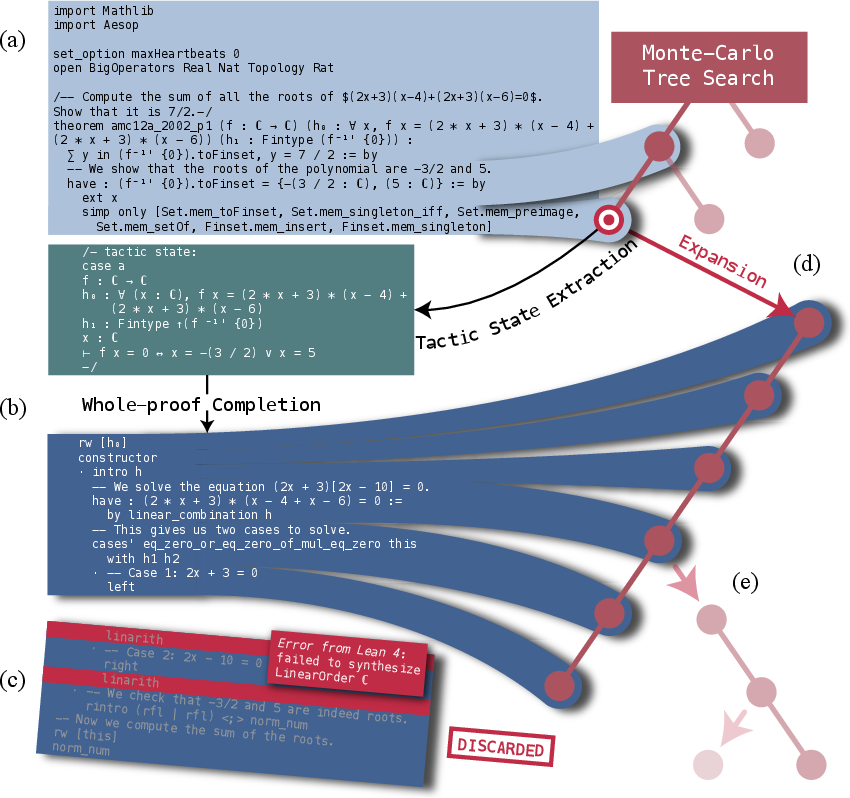
Monte-Carlo Tree Search with RMaxTS
The paper introduces a novel proof search tree method, combining whole-proof generation and proof-step generation into a unified framework via a truncate-and-resume mechanism. This is achieved by:
The model achieved state-of-the-art results on challenging theorem-proving benchmarks such as miniF2F and ProofNet.
Conclusion and Future Work
DeepSeek-Prover-V1.5 sets a new standard in formal theorem proving, demonstrating superior performance through integrated reinforcement learning and tree search techniques. Future directions include enhancing the critic model for better temporal credit assignment, which could vastly improve efficiency in large-scale theorem proving tasks. The continued development within this field is aimed at further bridging the gap between formal verification requirements and the inherently human-centric nature of mathematical problem-solving.