- The paper introduces a novel subgoal decomposition strategy employing reinforcement learning to enhance formal theorem proving.
- It unifies informal natural language reasoning with formal Lean 4 proof generation, reducing computational load with smaller models.
- It achieves state-of-the-art results on benchmarks like MiniF2F and ProofNet, efficiently solving competition and textbook problems.
Introduction
"DeepSeek-Prover-V2" introduces an evolution in neural theorem proving by integrating advanced reinforcement learning techniques coupled with subgoal decomposition strategies for improving mathematical reasoning capabilities. The work focuses on addressing the challenges of formal theorem proving by bridging informal natural language reasoning with formal logical structures in Lean 4.
Methodology
Recursive Proof Search via Subgoal Decomposition
DeepSeek-Prover-V2 builds on the foundation of decomposing the proof of complex theorems into smaller, manageable subgoals, a technique inspired by human mathematical problem-solving strategies. The methodology involves utilizing DeepSeek-V3 to generate natural language proof sketches that are simultaneously translated into formal Lean statements containing subgoals.

Figure 1: Overview of the cold-start data collection process employed by DeepSeek-Prover-V2.
The subgoal decomposition process leverages recursive solving, allowing the smaller 7B model to handle each subgoal efficiently. This approach reduces the computational burden typically associated with theorem proving in more extensive models.
DeepSeek-Prover-V2 seeks to unify informal mathematical reasoning and formal modeling by synthesizing cold-start data. The subgoals resolved by smaller models are appended to informal reasoning chains of DeepSeek-V3, creating high-quality data for formal reasoning tasks. This synthesized data acts as a crucial bridge connecting informal reasoning capabilities with formal logical rigor, enabling effective training and improving theorem proving performance.
Two-Stage Training Pipeline
The model training is divided into two distinct stages:
- Non-Chain-of-Thought (non-CoT) Mode: This stage focuses on generating concise Lean proof codes rapidly without exploring intermediate reasoning steps.
- Chain-of-Thought (CoT) Mode: This stage integrates reinforcement learning to encourage the articulation of intermediate reasoning steps before constructing final proofs, enhancing transparency and logical robustness.
Experimental Results
DeepSeek-Prover-V2 establishes state-of-the-art performance across several formal theorem proving benchmarks, such as MiniF2F, ProofNet, PutnamBench, and FormalMATH. Notably, the model demonstrates superior generalization capabilities from high school-level problems to undergraduate-level mathematical challenges.
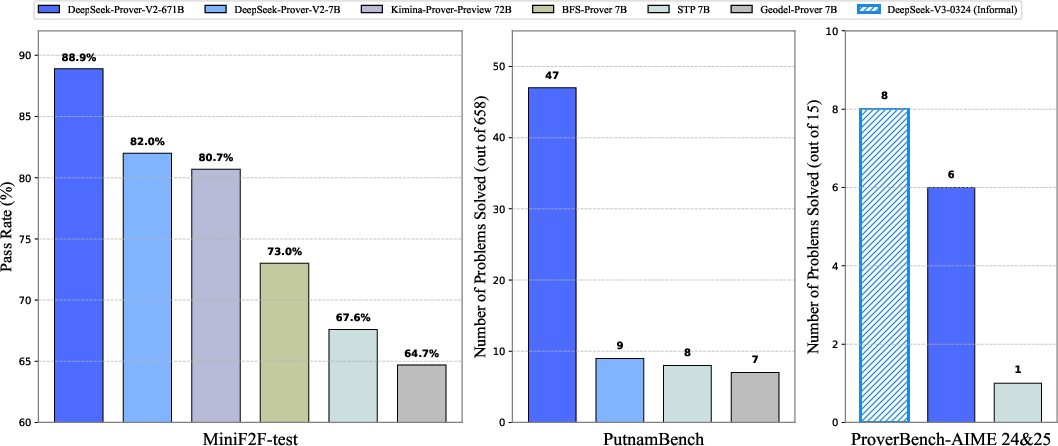
Figure 2: Benchmark performance of DeepSeek-Prover-V2.
The evaluation results underscore significant gains in proving challenging problems via subgoal-guided curriculum learning. The CoT mode, in particular, shows marked improvements, confirming the efficacy of incorporating intermediate reasoning steps even in formal theorem proving contexts.
Handling Combinatorial and Textbook Problems
DeepSeek-Prover-V2's performance on CombiBench and ProverBench highlights its strong adaptability in tackling diverse problem domains. By formalizing AIME problems and curated textbook examples, the model effectively addresses competition-level topics while demonstrating robust performance in algebra, analysis, and other sophisticated mathematical fields.
Conclusion
DeepSeek-Prover-V2 represents a significant advancement in the domain of neural theorem proving, showcasing the power of subgoal decomposition and reinforcement learning in formal mathematical reasoning tasks. The study illustrates how informal reasoning models, when integrated with formal theorem provers, can provide substantial benefits in solving both elementary and advanced mathematical problems. Future work will explore extending these capabilities further, aiming to address even more complex challenges like International Mathematical Olympiad-level problems.