- The paper introduces ProofSeek, a framework that leverages supervised and reinforcement learning to automate the generation and verification of formal proofs.
- It integrates natural language autoformalization and heuristic proof augmentation to structure proofs for formal software verification.
- Experiments on miniF2F and policy datasets demonstrate ProofSeek’s efficiency in handling complex LLM-generated code verification tasks.
Introduction
The paper "Neural Theorem Proving: Generating and Structuring Proofs for Formal Verification" introduces the ProofSeek framework, designed to automate the process of generating and verifying proofs for formal software verification. Given the recent advances in LLMs, formal theorem proving has gained renewed attention due to its ability to enhance interpretability and verification, particularly for LLM-generated code. The task remains challenging due to the complexity inherent in modeling computer programs as formal mathematical statements.
ProofSeek addresses the shortcomings of previous proof generation paradigms—whole proof generators and proof step generators—by bridging gaps through its three-component framework. These components include generating natural language statements, utilizing an LLM for formal proof generation, and employing heuristics from ProofAug to construct final proofs which are amenable to validation by systems such as Isabelle. A critical innovation of this work is its two-stage fine-tuning approach, leveraging both SFT-based and RL-based training to enhance the model's ability to generate syntactically impeccable and verifiable proofs.
Background
Formal theorem proving, operating at the intersection of mathematics and computer science, translates computer program correctness into formal language. Though powerful, traditional formal verification is tedious and demands significant domain expertise. Automated theorem proving through machine learning has primarily focused on premise selection and proof search. However, LLMs have catalyzed fresh approaches to proof synthesis.
Neural theorem proving leverages LLMs alongside symbolic proof assistants. The paper outlines two central methodologies: single-pass and proof-step. Both have limitations regarding scalability and lemma utilization. Reinforcement learning emerges as a promising strategy, enhancing proof generation models by exploiting reward mechanisms that encourage logical consistency and success.
Method
ProofSeek Framework:
ProofSeek integrates the principles of DSP workflow and ProofAug's construction method. It is structured into two components: fine-tuning a LLM (Figure 1(a)) and proof generation/verification (Figure 1(b)). Fine-tuning involves two main stages:
- Supervised Fine-Tuning (SFT): Training involves statement-proof pairs, leveraging LoRA for parameter-efficient model adaptation.
- Reinforcement Learning (RL): Using GRPO, ProofSeek optimizes output generation through relative ranking, further validating via PISA.
The autoformalization phase converts natural language problems into formal statements, critical for consistent proof generation. Proof construction then employs ProofAug strategies such as effective recursive proving and heuristic tactics to iteratively achieve verified proofs.
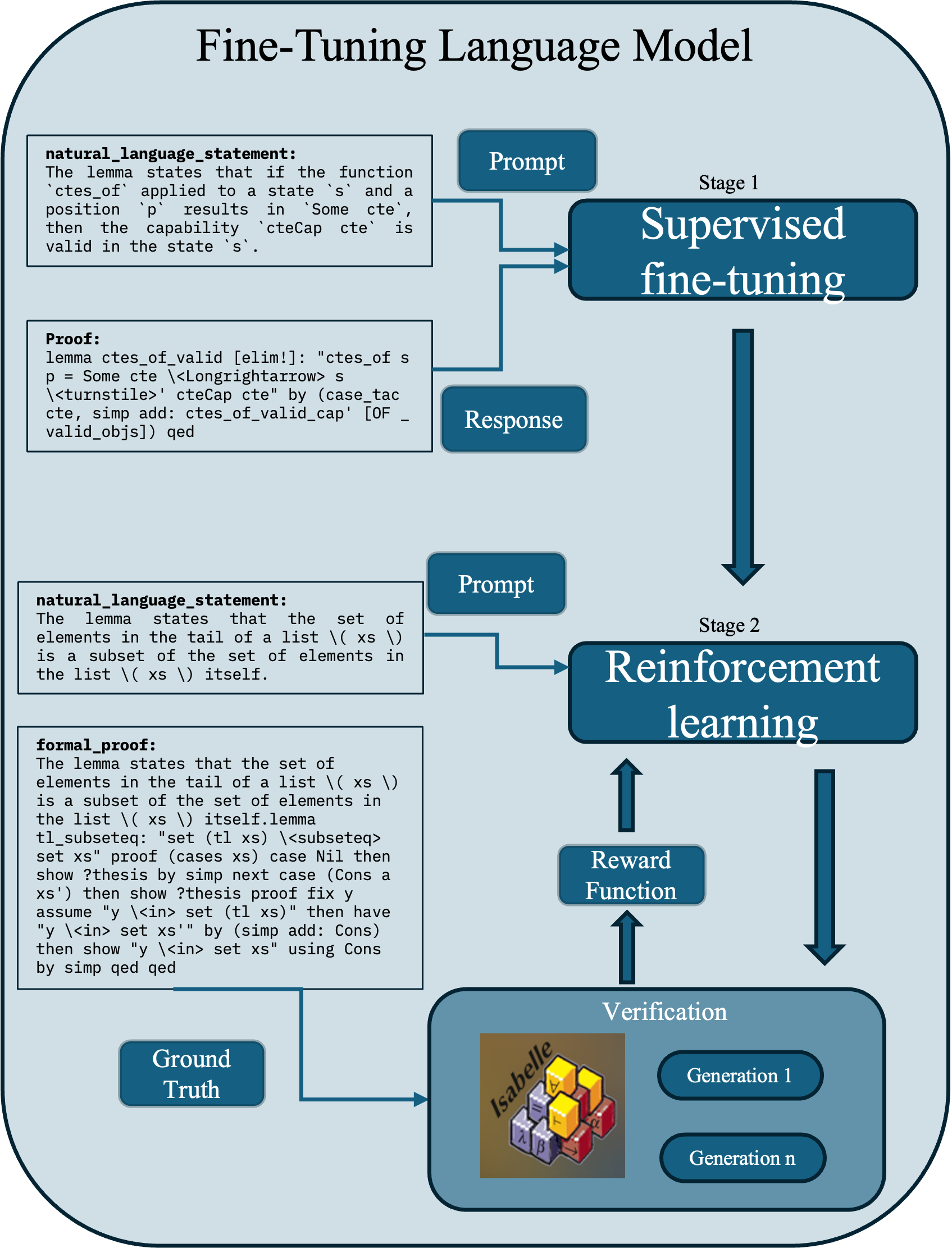
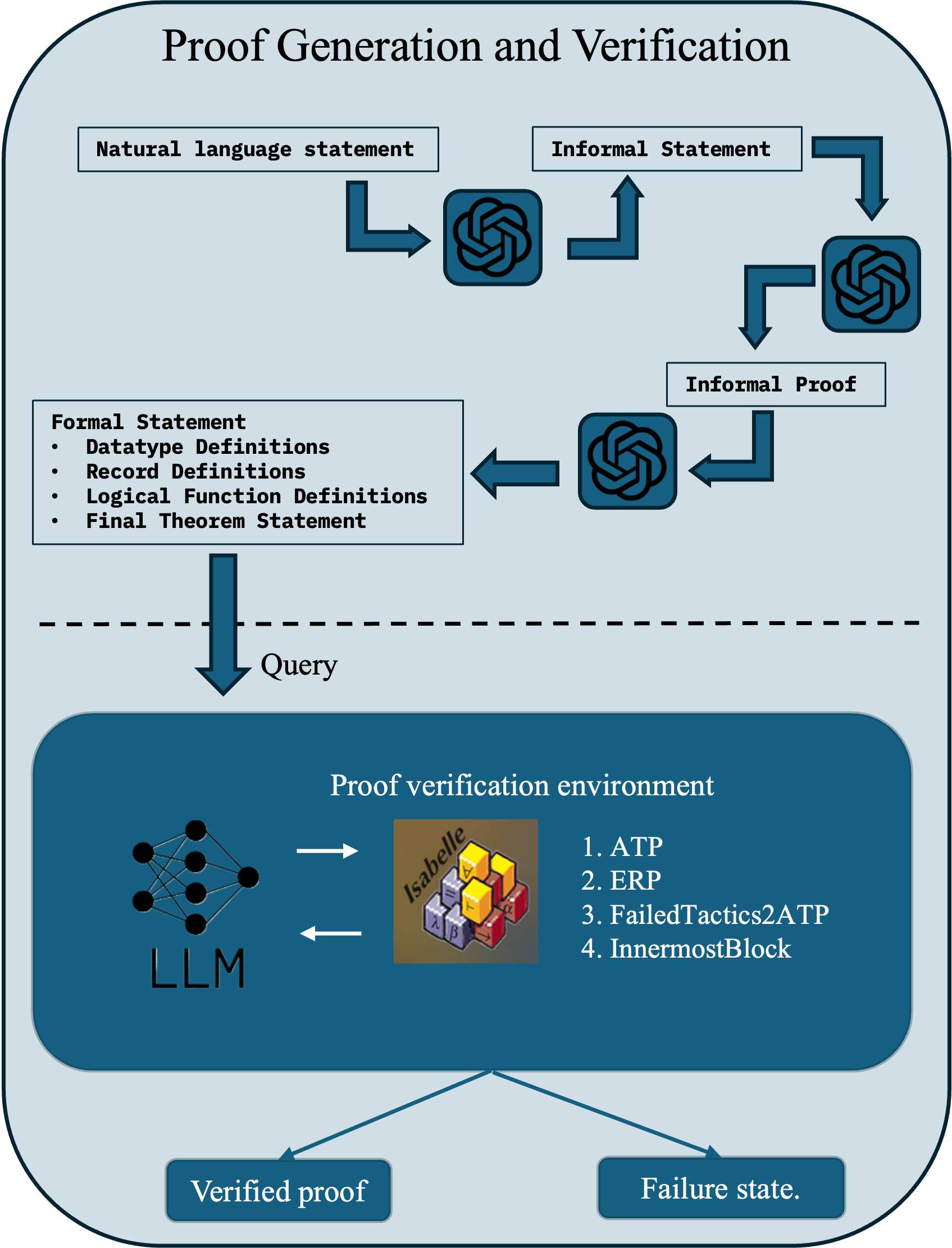
Figure 1: The two core components within the ProofSeek framework: (a) the fine-tuning LLM module, (b) the proof generation and verification module
Experiments
ProofSeek is evaluated using the miniF2F-test dataset and the Quacky dataset for AWS S3 bucket policies. These experiments demonstrate ProofSeek’s capability to effectively autoformalize and generate proofs in unseen domains, achieving comparable success rates to other approaches but with enhanced computational efficiency. Notably, ProofSeek exhibits superior performance when verifying structured policy codes generated by LLMs, highlighting its practical applicability.
Conclusion
ProofSeek extends the capabilities of neural theorem proving by offering a generalized framework capable of addressing computational and verification challenges through effective integration of LLMs and symbolic reasoning. Despite trailing SOTA benchmarks slightly, its utility in real-world applications is clear, paving the way for future exploration into model reliability, consistency, and further integration of symbolic reasoning systems such as knowledge graphs.