FARE: Fast-Slow Agentic Robotic Exploration
Abstract: This work advances autonomous robot exploration by integrating agent-level semantic reasoning with fast local control. We introduce FARE, a hierarchical autonomous exploration framework that integrates a LLM for global reasoning with a reinforcement learning (RL) policy for local decision making. FARE follows a fast-slow thinking paradigm. The slow-thinking LLM module interprets a concise textual description of the unknown environment and synthesizes an agent-level exploration strategy, which is then grounded into a sequence of global waypoints through a topological graph. To further improve reasoning efficiency, this module employs a modularity-based pruning mechanism that reduces redundant graph structures. The fast-thinking RL module executes exploration by reacting to local observations while being guided by the LLM-generated global waypoints. The RL policy is additionally shaped by a reward term that encourages adherence to the global waypoints, enabling coherent and robust closed-loop behavior. This architecture decouples semantic reasoning from geometric decision, allowing each module to operate in its appropriate temporal and spatial scale. In challenging simulated environments, our results show that FARE achieves substantial improvements in exploration efficiency over state-of-the-art baselines. We further deploy FARE on hardware and validate it in complex, large scale $200m\times130m$ building environment.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “FARE: Fast-Slow Agentic Robotic Exploration”
Overview
This paper introduces FARE, a new way for robots to explore unknown places (like buildings, forests, or warehouses) quickly and smartly. FARE combines two kinds of thinking:
- Slow thinking: like a coach who plans the big picture
- Fast thinking: like a player who reacts quickly on the field
The “coach” is a LLM that reasons globally about the map. The “player” is a reinforcement learning (RL) policy that makes quick, safe moves using the robot’s sensors. Together, they help the robot explore more efficiently and with fewer wasted trips.
What problems is the paper trying to solve?
The authors ask: How can a robot explore a brand-new place faster and with fewer unnecessary moves?
In simple terms, they focus on two issues:
- Most planners either use fixed rules that don’t adapt well to different environments (like wide-open warehouses vs. messy forests), or they learn only short-term benefits and miss the big picture.
- Robots need to balance long-term strategy (where to go overall) with short-term actions (how to move right now) without getting stuck or backtracking too much.
How does FARE work?
FARE splits the job into two parts—global strategy and local action—and gives each the right tools and speed.
Key terms in simple words
- LiDAR: a sensor that “sees” by sending out laser beams to measure distances.
- Frontier: the boundary between what the robot has already seen and what is still unknown.
- Waypoint: a target location the robot moves to next.
- Graph: like a city map made of “nodes” (places) connected by “edges” (paths).
- Community detection: grouping nearby places into “neighborhoods” so the robot can plan at a higher level.
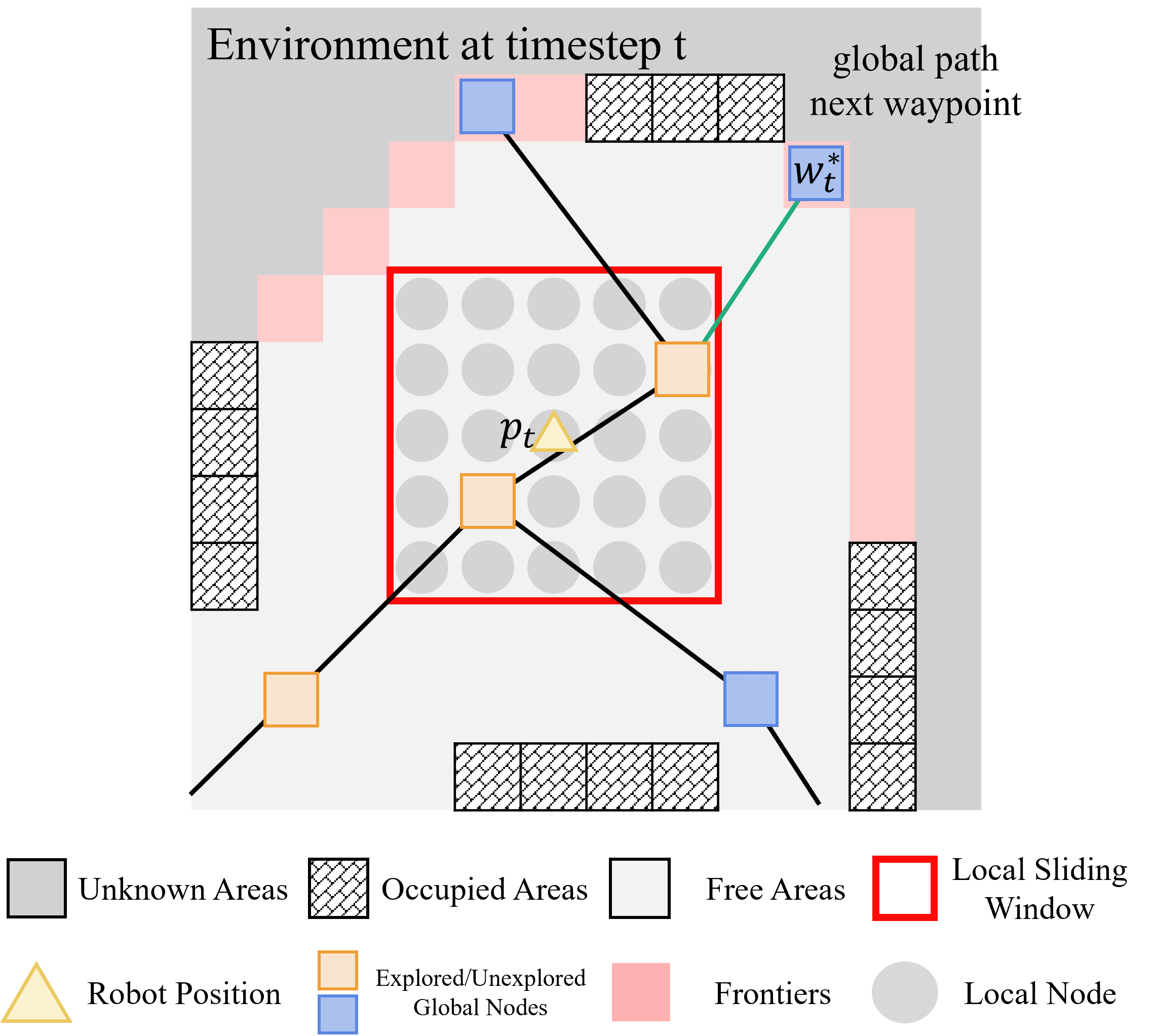
1) Building two levels of maps (graphs)
- Local graph (near the robot): Dense, detailed, and used for quick decisions.
- Global graph (farther away): Smaller and simpler. The robot groups the map into “neighborhoods” using a method called modularity-based community detection. Then it keeps only the most important neighborhoods (pruning) so the global reasoning stays fast and focused. Think of it like reducing a big city map to just the major districts and highways.
2) Slow-thinking “coach” (LLM) for global strategy
- Input: A short text about the environment (for example, “warehouse with narrow aisles”).
- The LLM uses this description plus the simplified global graph to come up with a plan (a sequence of global waypoints). For example, in a messy forest it might prefer safer paths; in a warehouse it might prioritize clearing perimeter aisles first.
- This global plan updates as the robot discovers more of the map.
3) Fast-thinking “player” (RL policy) for local moves
- The RL policy looks at the local graph (what’s near the robot), frontiers (edges of the unknown), and the next global waypoint.
- It chooses the next small step (waypoint) that is safe and useful.
- Training includes a special reward that gently pushes the policy to follow the coach’s guidance (global waypoints). Think of it like a small penalty for straying too far from the plan, which keeps the robot efficient without making it rigid.
What did they find?
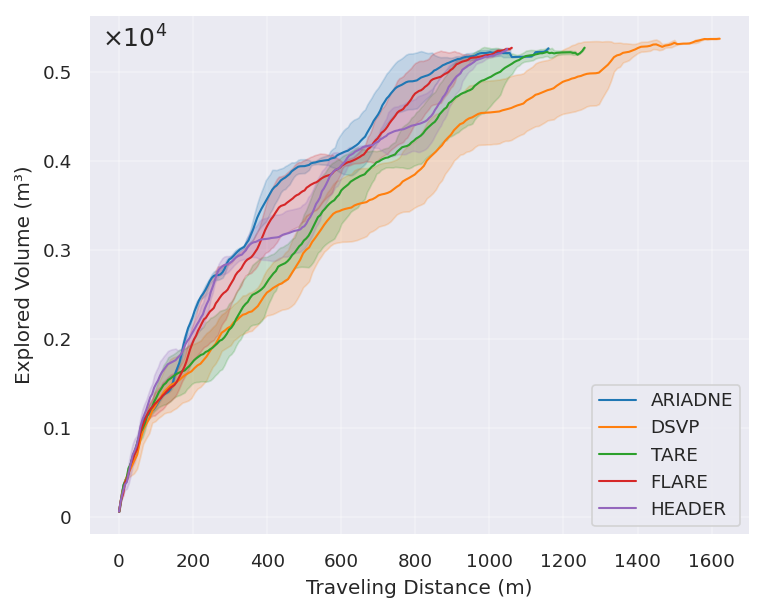
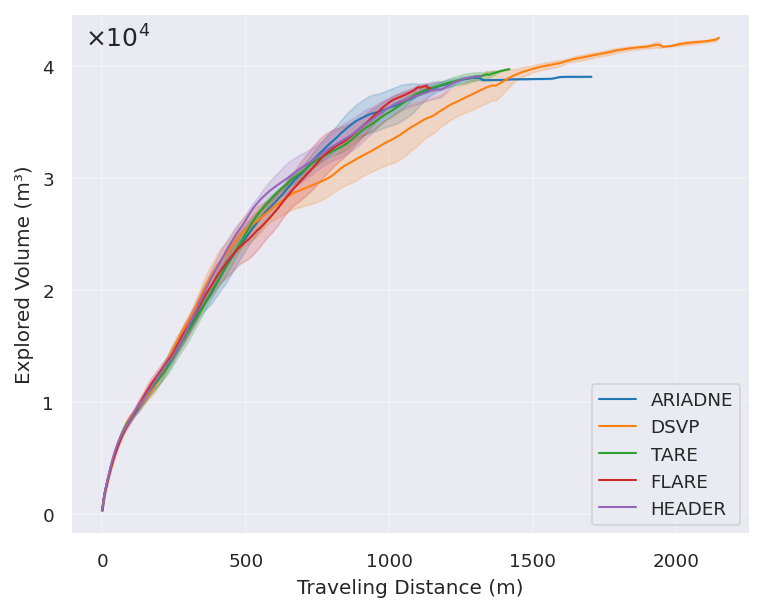
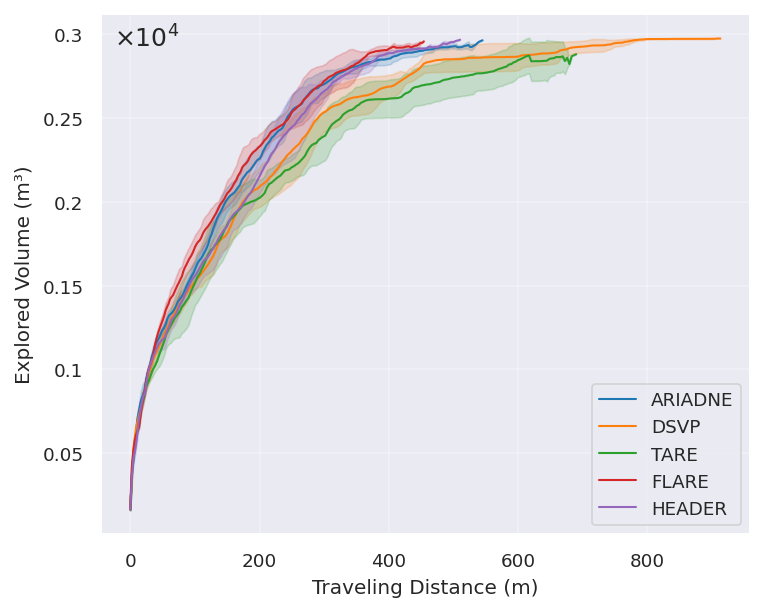
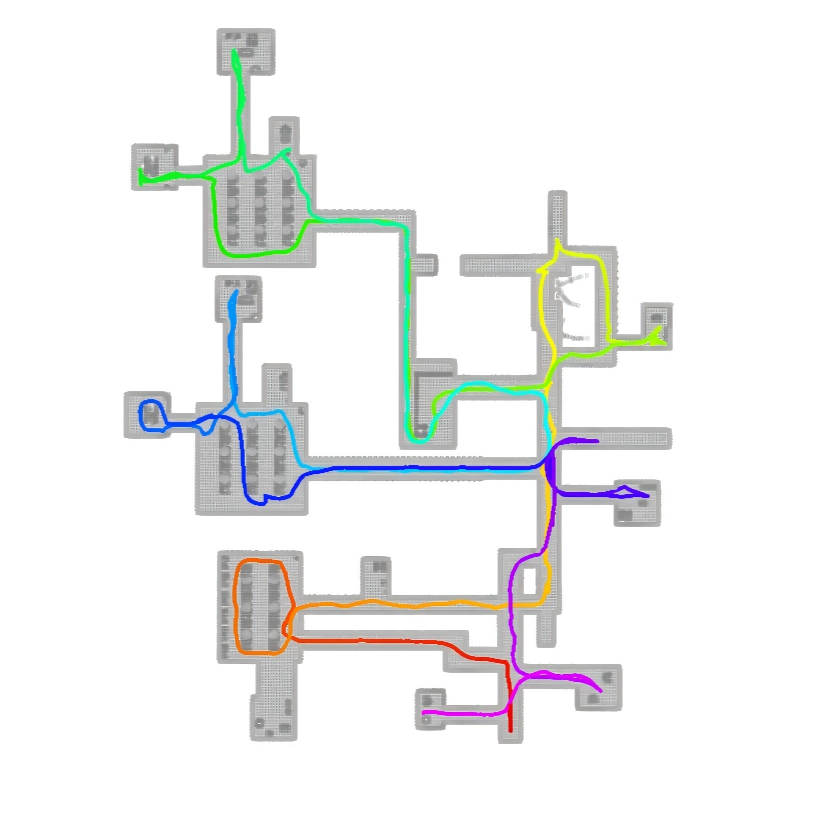
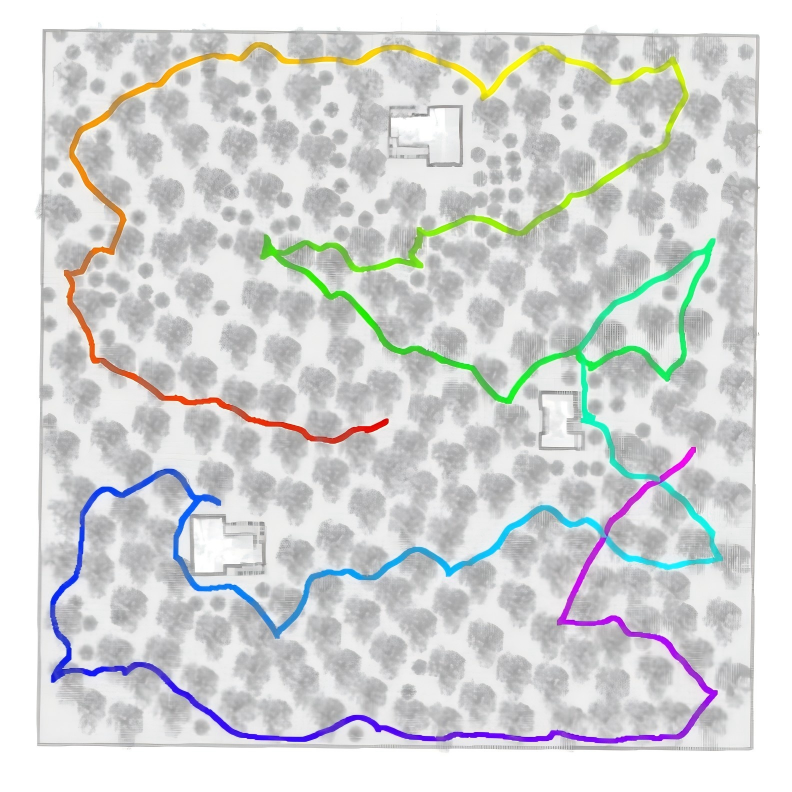
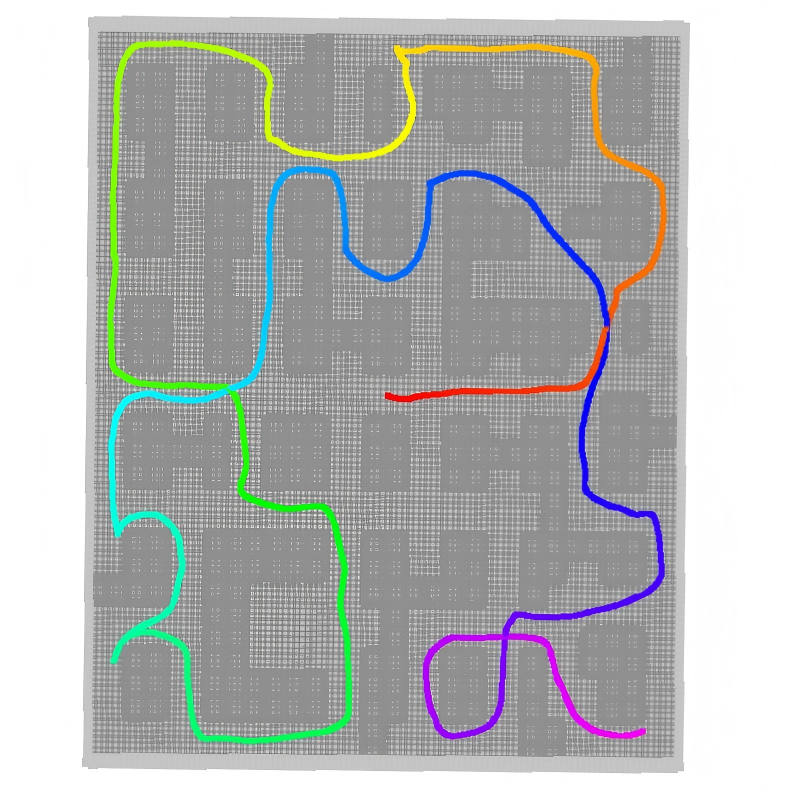
In simulations and real tests, FARE explored faster and with shorter paths than other strong methods:
- In forest and warehouse-like environments, FARE clearly traveled less distance and finished earlier than the others.
- In indoor office-like spaces (where long-range structure matters less), FARE performed similarly to the best methods.
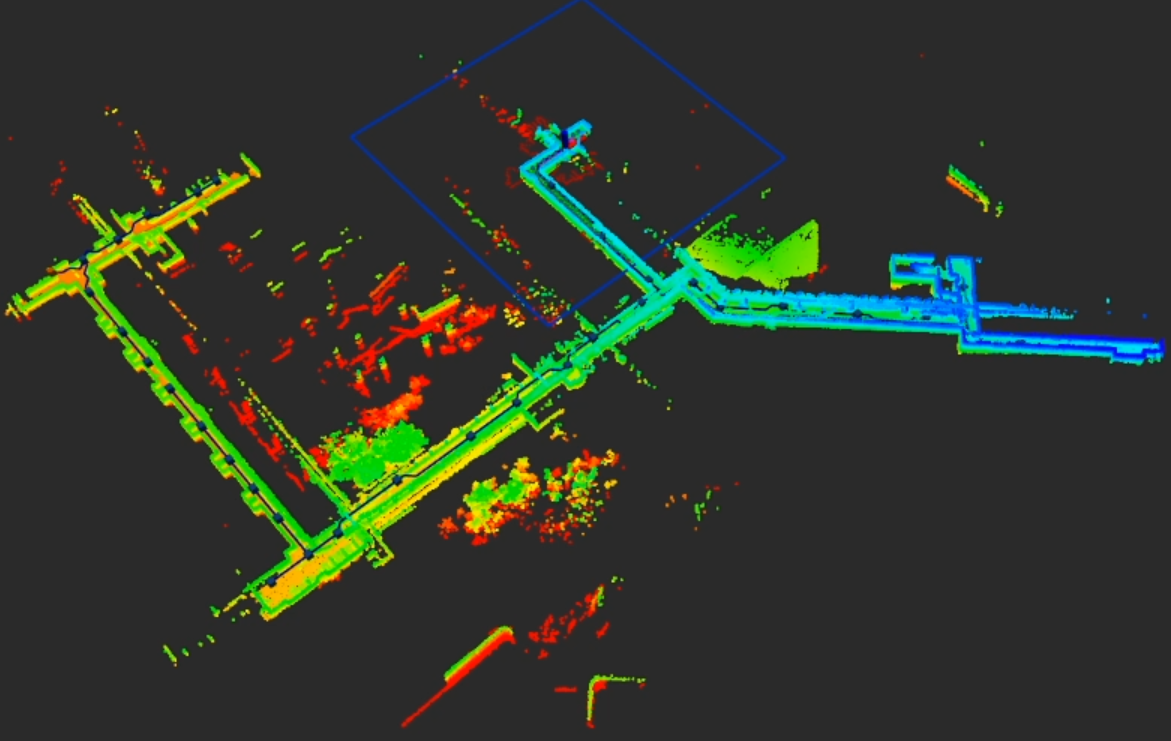
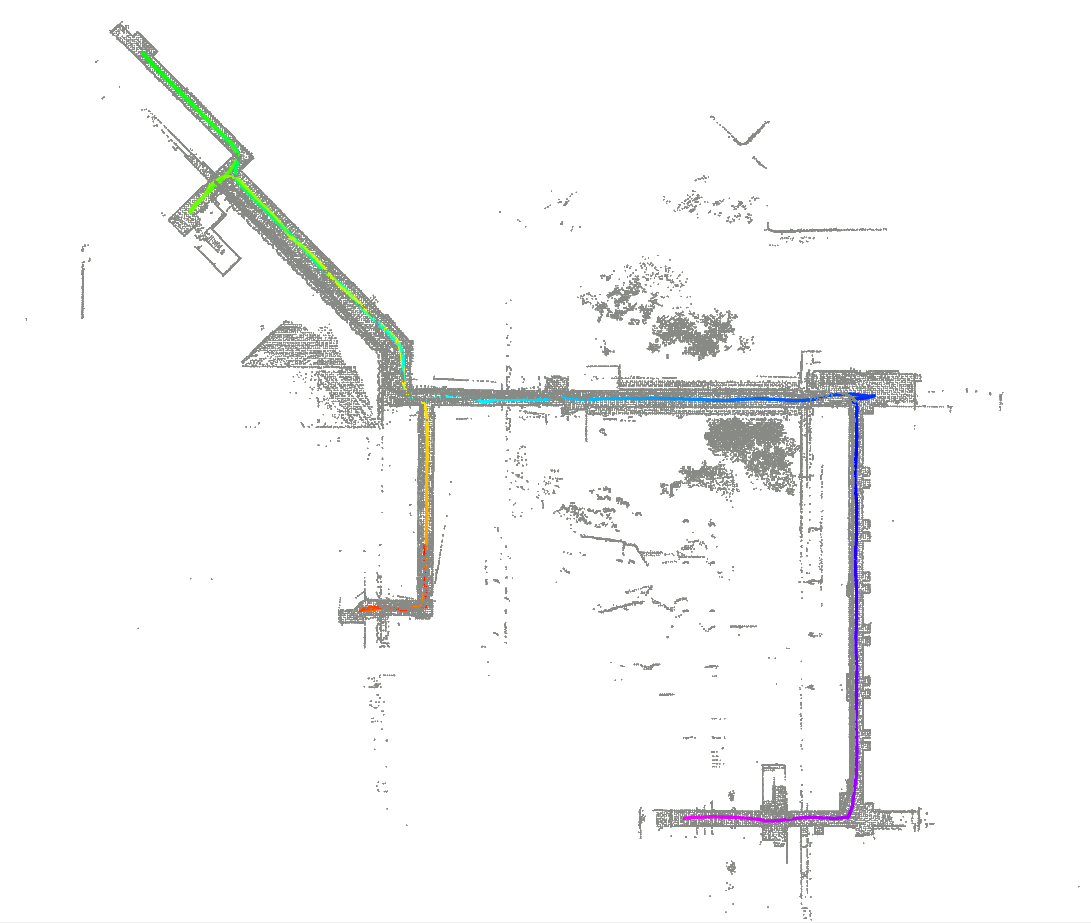
- They also ran FARE on a real wheeled robot in a large building (about 200 m by 130 m), and it completed exploration stably—showing the method works outside simulation.
Why this matters:
- Shorter paths mean saving battery and time.
- Better planning reduces backtracking and missed corners or edges.
- Adapting the strategy to the environment helps the robot avoid common traps (like getting stuck in dead ends or repeatedly revisiting the same places).
Why is this approach different?
Here are the main ideas that make FARE stand out:
- It separates “what to do overall” (global strategy using the LLM) from “how to move right now” (local RL).
- It uses a compact global graph built from important “neighborhoods,” so the LLM can reason efficiently.
- It blends long-term guidance with short-term flexibility, so the robot doesn’t ignore useful nearby opportunities.
What could this change in the real world?
FARE could improve tasks like:
- Search and rescue: covering unknown areas faster and more safely.
- Warehouse logistics: mapping and inspecting aisles efficiently.
- Environmental monitoring: exploring forests, caves, or industrial sites with fewer wasted trips.
Looking ahead, the authors suggest:
- Multi-robot teamwork, where several robots share plans and coordinate.
- Richer perception (like vision) to handle sudden changes.
- Extending to full 3D exploration for drones or multi-level buildings.
In short, FARE shows that combining a “thinking coach” (LLM) with a “reactive player” (RL) helps robots explore smarter, finish faster, and waste less movement—especially in complex, real-world environments.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, rendered to guide concrete follow-up research.
- Reliance on manual environment descriptions: The slow-thinking module requires a concise human-written environment description; there is no mechanism to automatically infer, validate, or update this description from onboard sensing, nor an analysis of how mischaracterizations affect performance.
- Ambiguity in strategy instantiation: The paper defines a schema of strategy dimensions (spatial, efficiency, safety, task) but does not specify the mapping from environment characteristics to concrete planner parameters (e.g., how “backtrack tolerance” or “boundary-first” is numerically realized, weighted, or tuned), making replication and extension difficult.
- Unspecified LLM graph encoding and prompting: The exact textual/verbalization format used to feed the pruned global belief graph to the LLM, prompt design, token budgeting, and memory management are not described, limiting reproducibility and preventing sensitivity analysis to representation choices.
- Lack of LLM ablation and robustness analysis: There is no comparison across LLMs (size, architecture, inference precision/quantization), no latency or energy profiling on the Jetson AGX Orin, and no evaluation of failure modes (e.g., hallucinated guidance, inconsistent reasoning) or safe fallbacks when the LLM produces poor global plans.
- Unclear slow–fast interaction schedule: The frequency, triggers, and criteria for updating global guidance (e.g., after specific map changes or time intervals) are not specified; the impact of replan cadence on performance and compute load remains unquantified.
- Global graph pruning choices are ad hoc: The modularity-based pruning ignores edge weights/directions, uses “top-k communities” without a principled selection method for k, and offers no guarantees on coverage completeness or connectivity preservation; sensitivity studies and alternatives (e.g., weighted modularity, flow-based pruning) are missing.
- Incremental update mechanism for global graph: How the global belief graph and its communities are updated under partial observability, sensor noise, and evolving topology is not specified; the cost and stability of repeated community detection online remain unexamined.
- Instruction-following reward lacks justification and tuning analysis: The normalization constant for deviation (4·Δnode·√2), the reward weight relative to other terms, and the policy’s behavior when global guidance is wrong or stale are not theoretically justified; no ablation isolates the contribution of this reward to performance or failure avoidance.
- RL training details and generalization: Key training aspects (e.g., training environments/distributions, episode curriculum, optimizer, hyperparameters, regularization, reward composition beyond rdev) are not reported; there is no analysis of sample efficiency, out-of-distribution generalization, or catastrophic forgetting across environment types.
- Coverage completeness metrics omitted: While distance and time are reported, coverage (e.g., fraction of unknown explored, revisit rate, frontier closure statistics) is not quantified; thus it is unclear whether shorter trajectories compromise completeness or map quality.
- Statistical rigor and significance: Results report mean ± std over 10 runs but lack statistical tests (e.g., confidence intervals, paired tests) and effect-size analyses, making it hard to assess significance and robustness of improvements.
- Hardware validation lacks comparative baselines: Real-world tests demonstrate feasibility but do not compare FARE against baselines on the same site; runtime breakdowns (LLM inference time, graph construction time, RL policy time), compute budgets, and latency under motion are not reported.
- Robustness to SLAM errors and sensor noise: The approach assumes reliable LiDAR-based SLAM; there is no sensitivity analysis to localization drift, mapping artifacts, degraded LiDAR returns, or occlusions and how these affect graph construction, LLM reasoning, and policy execution.
- Dynamic environments and moving obstacles: The framework is evaluated in static settings; adaptation to dynamic changes (moving people, rearranged obstacles), detection of scene-type transitions, and safe re-planning under non-stationarity remain open.
- 2D assumption and multi-floor/3D generalization: The method operates on 2D occupancy grids; extensions to full 3D environments (multi-floor buildings, stairs, UAVs, subterranean settings) and the implications for global graph construction and LLM reasoning are unaddressed.
- Safety guarantees and risk handling: Beyond conservative clearance in the strategy schema, there are no formal safety guarantees, verification methods, or recovery protocols when global guidance conflicts with local safety constraints.
- Parameter adaptation online: FARE only adjusts Δnode per environment offline; there is no method to adapt representation granularities (Δmap, Δnode), community-pruning parameters, or reward weights online based on observed performance or environment changes.
- Completeness of global waypoint generation: The LLM outputs a path “to an unexplored node,” but there is no mechanism to ensure systematic coverage (e.g., preventing starvation of difficult regions or guaranteeing eventual exploration of all communities/frontiers).
- Communication and scalability for multi-robot: The proposed future extension to multi-robot exploration lacks a plan for inter-agent global reasoning, communication constraints, conflict resolution, and division-of-labor policies at scale.
- Energy and resource profiling: There is no analysis of onboard compute/energy trade-offs between LLM reasoning, graph updates, and RL policy execution, nor strategies to manage battery and thermal constraints during long missions.
- Prompt drift and strategy updates: How the environment-conditioned strategy is revised as the map evolves (e.g., detecting that “warehouse-like aisles” turn into “open hall”) is not defined; risks of prompt drift or inconsistent strategy over time are unexplored.
- Reproducibility and code/data: The paper does not indicate code, prompts, or dataset release; without these artifacts, replicating LLM behavior, graph construction details, and training procedures is infeasible.
- Fairness of baseline tuning: Baselines reportedly require multiple parameter tunings while FARE adjusts a single parameter; the fairness of tuning effort and whether baselines were tuned equivalently for each environment remains unclear.
- Failure-case characterization: There is no analysis of scenarios where FARE underperforms (e.g., highly symmetric spaces, deceptive connectivity) or qualitative diagnostics explaining when slow-thinking guidance misleads the fast policy.
- Integration with richer semantics: While future work mentions semantics, the current framework does not exploit visual or semantic cues (doors, signage, room types) to refine strategy, nor does it address how semantic uncertainty would be incorporated into graph reasoning.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now by leveraging FARE’s fast–slow architecture (LLM-enabled global reasoning with modularity-based graph pruning + RL-based local control with instruction following), validated in simulation and a large real-world building.
- Warehouse layout mapping and aisle coverage optimization (logistics, robotics)
- Use case: Rapid creation/update of occupancy maps and aisle coverage plans in warehouses with reconfigurable racks and narrow passages.
- Tools/workflows: ROS-integrated “FARE Planner” with OctoMap; operator inputs a short warehouse description to auto-generate global waypoints; local RL policy handles sensor-driven navigation.
- Assumptions/dependencies: Reliable LiDAR/SLAM; safe operation policies in human-in-the-loop environments; sufficient onboard or edge compute for LLM (e.g., Jetson AGX Orin or networked inference); basic parameter tuning (node resolution).
- Facility commissioning and digital twin/BIM refresh after renovations (AEC, facility management, energy)
- Use case: Efficient post-renovation scans to update BIM/digital twins and detect layout changes affecting airflow, egress routing, and maintenance pathways.
- Tools/workflows: “Exploration orchestration pipeline” connecting FARE to mapping backends (OctoMap); standardized “environment strategy prompts” authored by commissioning engineers; automatic global waypoint sequencing via pruned community graphs.
- Assumptions/dependencies: Access clearance; SLAM robustness across multi-room corridors; LLM inference latency acceptable; alignment between occupancy maps and BIM schemas.
- Security patrol startup in unfamiliar or reconfigured spaces (security robotics)
- Use case: Quickly establishing reliable patrol routes in newly configured buildings or after events; reducing backtracking and blind spots.
- Tools/workflows: Patrol planner with FARE-generated global routes; local RL policy to adapt in real time to blocked corridors or changed interiors.
- Assumptions/dependencies: Safety certification and local regulations; perception robustness in low-light; verified egress maintenance awareness within the strategy settings.
- Campus/office coverage for maintenance, cleaning, and inspections (service robotics)
- Use case: Faster initial coverage mapping for routine tasks (cleaning, inspection) in large buildings; early completion of corners/perimeter areas to minimize revisits.
- Tools/workflows: ROS “Waypoint Guidance API”; operation console where facility staff enter a brief environment description; frequent replanning at 1 Hz as in the hardware trial.
- Assumptions/dependencies: Stable odometry and collision avoidance; manageable pedestrian traffic; battery planning for longer missions.
- Forestry and outdoor site mapping with natural obstacles (environmental monitoring, agriculture)
- Use case: Efficient trail and perimeter coverage in forested areas with irregular obstacles; balanced depth–breadth exploration guided by environment-conditioned strategies.
- Tools/workflows: Edge LLM inference or hybrid cloud; LiDAR or multi-sensor SLAM; modularity-based pruning to reduce global reasoning complexity.
- Assumptions/dependencies: Terrain traversability; sensor robustness to vegetation/occlusions; domain-appropriate environment descriptions (e.g., “natural obstacles, uneven terrain”).
- Academic deployment for benchmarking and reproducible research (academia)
- Use case: A testbed to study long-horizon credit assignment and hierarchical exploration; comparison against frontier-based and RL baselines.
- Tools/workflows: ROS package integration; “Strategy Prompt Template” library; graph pruning SDK for community detection/modularity scoring; reproducible Gazebo environments (indoor, forest, warehouse).
- Assumptions/dependencies: GPU/edge compute for LLM; access to Qwen- or similar LLMs; standard SLAM implementations (e.g., FastLIO2).
- Faster home mapping for high-end consumer robots (daily life)
- Use case: Speeding up initial mapping for premium vacuums or home service robots in cluttered apartments.
- Tools/workflows: Lightweight LLM variants or cloud inference; simple environment descriptions (“narrow corridors, multiple rooms, moderate clutter”).
- Assumptions/dependencies: Compute/bandwidth constraints; privacy-compliant cloud usage; consumer-grade sensors with adequate fidelity.
Long-Term Applications
Below are applications that benefit from FARE’s core ideas but require further research, scaling, safety validations, or new modules (e.g., vision semantics, multi-agent coordination, 3D action spaces).
- Multi-robot coordinated exploration with LLM-mediated global planning (public safety, search & rescue, industrial surveying)
- Use case: Teams of robots dividing coverage and dynamically reassigning areas to minimize overlaps and idle time in large, unknown environments (e.g., disaster sites, mines).
- Tools/workflows: “Mission Commander LLM” producing shared global waypoints and role assignments; inter-agent communication and conflict-resolution layer; extended instruction-following rewards across agents.
- Assumptions/dependencies: Reliable multi-hop communication; time-sync and localization; safety policies for multi-robot interactions; robust failure handling.
- Semantics-aware exploration with online vision and environment change detection (construction progress tracking, facility operations)
- Use case: Prioritizing areas based on semantic cues (e.g., hazardous zones, critical assets) and detecting dynamic changes (temporary barriers, reconfigured rooms).
- Tools/workflows: Vision-semantic module fused into the global graph; LLM interprets semantic descriptions (“prioritize equipment rooms”; “avoid wet floors”) to adjust strategy axes; continuous update of global waypoints.
- Assumptions/dependencies: High-quality perception datasets; reliable semantic segmentation/recognition; calibration and alignment between semantic layers and occupancy maps.
- 3D exploration in multi-level and subterranean environments (energy, mining, infrastructure)
- Use case: Efficient mapping of vertical shafts, basements, tunnels, and multi-level structures with 6-DoF motion and 3D global graphs.
- Tools/workflows: 3D occupancy grids/octrees; 3D modularity-based community detection; 3D RL policies with instruction-following in volumetric space.
- Assumptions/dependencies: 3D SLAM under challenging conditions; specialized sensors (multi-echo LiDAR); enhanced safety measures; rigorous risk assessment for confined spaces.
- Autonomous inspection and asset management driven by strategy prompts (manufacturing, utilities)
- Use case: Exploration evolves into routine inspection routes that adapt to equipment priorities (“object detection first”, “conservative clearance”); reduced human planning overhead.
- Tools/workflows: “Exploration Strategy Studio” for non-experts to author task-oriented prompts; integration with CMMS/asset databases; automatic waypoint generation aligned with inspection policies.
- Assumptions/dependencies: Interoperability with enterprise systems; clear safety envelopes; updated asset registries and map synchronization.
- On-the-fly mapping for last-mile delivery and micro-fulfillment hubs (logistics)
- Use case: Rapid, localized mapping when operating in pop-up hubs or unfamiliar interior spaces; minimizing detours to achieve time targets.
- Tools/workflows: Lightweight FARE deployments with quantized LLMs; configurable “time-limited completion” strategies; edge/cloud fallback for global reasoning.
- Assumptions/dependencies: SLA constraints; variable connectivity; streamlined safety certification for temporary sites.
- Edge-optimized LLMs and graph adapters for onboard reasoning (software, robotics platforms)
- Use case: Smaller or domain-tuned LLMs (with GNN adapters) performing fast graph reasoning and strategy instantiation on limited hardware.
- Tools/workflows: Model distillation, quantization, and adapter training pipelines; standardized graph verbalizers; hardware acceleration profiles (e.g., Orin).
- Assumptions/dependencies: Availability of high-quality instruction-tuning data; robust graph–text schemas; continual evaluation for hallucination/error modes.
- Policy, governance, and auditability of LLM-guided autonomy (policy, compliance)
- Use case: Standards for logging strategy prompts and LLM decisions; human override protocols; risk assessment tied to environment characteristics (dead-end probability, backtracking necessity).
- Tools/workflows: Prompt template repositories; mission loggers for LLM outputs and waypoint decisions; audit dashboards for safety incidents and detours.
- Assumptions/dependencies: Regulatory frameworks for AI-on-robots; privacy/data handling rules; stakeholder training for safe deployments.
- Education and workforce training on hierarchical autonomy (academia, professional development)
- Use case: Curricula and simulators teaching fast–slow thinking in robotics; labs focusing on decoupled semantic reasoning and geometric decision-making.
- Tools/workflows: Open-source course kits; Gazebo/ROS scenarios with FARE modules; assessment rubrics emphasizing long-horizon planning and local reactivity.
- Assumptions/dependencies: Access to compute and sensors in teaching labs; maintainable open-source code; alignment with institutional safety policies.
Each application above draws directly on FARE’s core innovations: environment-conditioned strategy generation via LLMs, modularity-based graph pruning for tractable global reasoning, and an RL policy shaped to follow global waypoints while reacting to local observations. Feasibility depends on robust SLAM, reliable sensing, appropriate compute for LLM inference, manageable prompt engineering, and adherence to safety/regulatory constraints in the target deployment domain.
Glossary
- adjacency-based mask matrix: A matrix used to mask out non-adjacent node pairs when computing attention over a graph. "subject to edge constraints indicated by an adjacency-based mask matrix :"
- agent-level semantic reasoning: High-level reasoning about exploration strategy at the agent level using semantic (language-based) information. "integrating agent-level semantic reasoning with fast local control."
- attention-based encoder and decoder: Neural modules that use attention mechanisms to encode and decode graph-structured inputs. "Our policy network comprises attention-based encoder and decoder modules tailored to graph-structured inputs."
- closed-loop behavior: Behavior where actions are continuously informed by feedback, ensuring stability and coherence. "enabling coherent and robust closed-loop behavior."
- community-aware pruning: A technique that prunes graph structures by considering community properties to aid long-range reasoning. "Recent methods incorporate guided graph traversal, community-aware pruning, and explicitly structured reasoning steps"
- community detection: Identifying groups of nodes in a graph that are more densely connected internally than externally. "We construct the global belief graph $G_{\text{global}$ by jointly performing community detection and modularity-based pruning on the collision-free graph ."
- dense rewards: Frequent reward signals that provide immediate feedback to guide reinforcement learning. "Existing methods address this issue by introducing dense rewards that provide immediate feedback proportional to newly observed information"
- fast–slow thinking paradigm: A framework that separates slow, global reasoning from fast, local decision-making. "FARE follows a fast-slow thinking paradigm."
- fast-thinking RL module: The local, reactive reinforcement learning component that follows global guidance to execute exploration. "The fast-thinking RL module executes exploration by reacting to local observations while being guided by the LLM-generated global waypoints."
- frontier-based planners: Exploration methods that select targets at the boundary between known and unknown map regions. "Conventional planners are predominantly frontier-based, selecting exploration targets at the boundary between known and unknown regions,"
- global belief graph: A sparse, high-level graph representing distant regions used for global reasoning. "Given the pruned global belief graph $G_{\text{global}$, a textual strategy prompt and the episode memory "
- global waypoints: High-level navigation goals computed to guide long-range exploration. "which is then grounded into a sequence of global waypoints through a topological graph."
- graph modularity: A measure of the strength of division of a graph into communities. "where the graph modularity is defined as"
- graph rarefaction strategy: A method to sparsify graphs to improve scalability while retaining key structure. "ARiADNE is implemented with the same graph rarefaction strategy as in~\cite{cao2024deep}"
- guidepost: A binary node attribute indicating whether a location lies on the globally guided path. "guidepost (a binary signal that denotes whether the location of the node is in the global paths)"
- hierarchical autonomous exploration framework: A multi-level system that separates global reasoning from local control for exploration. "We introduce FARE, a hierarchical autonomous exploration framework that integrates a LLM for global reasoning with a reinforcement learning (RL) policy for local decision making."
- hierarchical robot belief graph: A multi-resolution graph representation of the robot’s environment and beliefs. "we construct a hierarchical robot belief graph through the community-based method proposed in~\cite{cao2025header}."
- instruction following reward: A reward term that penalizes deviation from globally guided waypoints to align local actions with long-horizon guidance. "The instruction following reward is then defined as an exponential penalty on the normalized deviation,"
- LiDAR odometry: Estimation of a robot’s motion using LiDAR sensor data. "With the reliability of modern LiDAR odometry and SLAM (Simultaneous Localization and Mapping),"
- LLM-based graph reasoning: Using LLMs to perform structured reasoning over graph representations. "LLM-based graph reasoning has advanced substantially in recent years,"
- makespan: Total completion time of an exploration mission. "FARE achieves a clear reduction in travel distance and makespan,"
- modularity-based pruning: Removing parts of a graph based on community modularity contributions to simplify reasoning. "this module employs a modularity-based pruning mechanism that reduces redundant graph structures."
- modularity contribution: The amount a community adds to overall graph modularity, used to select informative communities. "select a subset of structurally informative communities according to their modularity contribution,"
- occupancy grid: A map representation where each cell indicates whether space is free or occupied. "commonly encoded as an occupancy grid or voxel map."
- omnidirectional LiDAR: A LiDAR sensor that captures 360-degree measurements around the robot. "the robot acquires observations using an omnidirectional LiDAR with sensing range ,"
- partially observable Markov decision process (POMDP): A decision-making framework where the agent has incomplete information about the state. "learning-based methods formulate exploration as a partially observable Markov decision process and use RL to learn policies"
- pruned global belief graph: A globally scoped graph reduced via pruning to retain only structurally salient communities. "Given the pruned global belief graph $G_{\text{global}$, a textual strategy prompt and the episode memory "
- reinforcement learning (RL) policy: A learned mapping from observations to actions optimized via rewards. "reinforcement learning (RL) policy for local decision making."
- scaled dot-product attention: An attention mechanism computing compatibility via scaled dot products of queries and keys. "The scaled dot-product attention scores are then computed between pairs of nodes as $u_{ij} = \frac{\mathbf{q}_i^\top \mathbf{k}_j}{\sqrt{d_f}$"
- Simultaneous Localization and Mapping (SLAM): Techniques that build a map of an environment while tracking the agent’s pose. "SLAM (Simultaneous Localization and Mapping)"
- slow-thinking LLM module: The global reasoning component using a LLM to synthesize long-horizon guidance. "The slow-thinking LLM module interprets a concise textual description of the unknown environment and synthesizes an agent-level exploration strategy,"
- topological graph: A graph capturing connectivity and structure used to derive global navigation guidance. "a sequence of global waypoints through a topological graph."
- utility value: A node’s score indicating potential information gain (e.g., observable frontiers) from that viewpoint. "Each node is assigned a utility value , defined as the number of observable frontiers within sensor range."
- viewpoint selection: Choosing candidate positions from which to observe and explore the environment. "viewpoint selection problem,"
- voxel map: A 3D grid-based map using volumetric pixels (voxels) to represent occupancy. "commonly encoded as an occupancy grid or voxel map."
Collections
Sign up for free to add this paper to one or more collections.

