Knowledge Graphs are Implicit Reward Models: Path-Derived Signals Enable Compositional Reasoning
Abstract: LLMs have achieved near-expert performance in structured reasoning domains like mathematics and programming, yet their ability to perform compositional multi-hop reasoning in specialized scientific fields remains limited. We propose a bottom-up learning paradigm in which models are grounded in axiomatic domain facts and compose them to solve complex, unseen tasks. To this end, we present a post-training pipeline, based on a combination of supervised fine-tuning and reinforcement learning (RL), in which knowledge graphs act as implicit reward models. By deriving novel reward signals from knowledge graph paths, we provide verifiable, scalable, and grounded supervision that encourages models to compose intermediate axioms rather than optimize only final answers during RL. We validate this approach in the medical domain, training a 14B model on short-hop reasoning paths (1-3 hops) and evaluating its zero-shot generalization to complex multi-hop queries (4-5 hops). Our experiments show that path-derived rewards act as a "compositional bridge", enabling our model to significantly outperform much larger models and frontier systems like GPT-5.2 and Gemini 3 Pro, on the most difficult reasoning tasks. Furthermore, we demonstrate the robustness of our approach to adversarial perturbations against option-shuffling stress tests. This work suggests that grounding the reasoning process in structured knowledge is a scalable and efficient path toward intelligent reasoning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about teaching AI models to “think in steps” using solid, checkable facts. The authors show how a model can learn to solve complex problems by combining small, true facts—especially in medicine—rather than just guessing a final answer. They do this by using a knowledge graph (a big map of facts and how they connect) to score the model’s reasoning, not only its final choice. Their key idea: knowledge graphs can act like “reward coaches,” giving points when the model uses the right facts in the right order.
The big questions the researchers asked
- How can we help AI models do multi-step, “connect-the-dots” reasoning in scientific fields, like medicine, where small mistakes can be dangerous?
- Can we train a model using short, simple fact chains so it generalizes to longer, more complicated ones it hasn’t seen before?
- Is there a way to give the model useful feedback at scale without needing humans to label every step?
- Will this approach be robust (hard to trick) and competitive with much larger models?
How they approached the problem
Think of this like teaching a student to solve a mystery using a map of clues:
- A knowledge graph is the map. It stores facts as simple triples: head → relation → tail, like “Fever → is_symptom_of → Flu.” A chain of these triples is a “path” (like following connected clues).
- “Hops” are the steps in a path. A 3-hop question needs three connected facts to reach an answer.
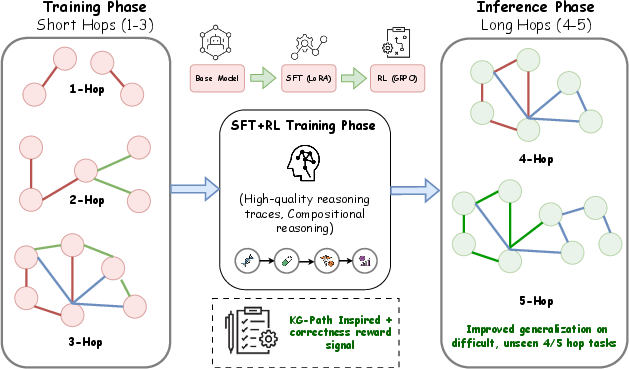
- They trained a 14-billion-parameter model in two steps:
- Supervised Fine-Tuning (SFT): They first taught the model lots of short, correct reasoning examples, using a lightweight method called LoRA (think: adding small “adapters” instead of changing everything).
- Reinforcement Learning (RL): Then they coached the model to improve by giving it rewards (points) based on how well its reasoning used the right facts. They used GRPO, a training method that nudges the model towards better behavior based on group-level scores.
To make the rewards useful and fair, they tried different signals and kept the ones that really encouraged step-by-step thinking:
- Binary correctness: a small positive point for the right final answer, a bigger negative point for a wrong one (this pushes the model to avoid mistakes).
- Path alignment: extra points when the model’s explanation mentions the correct entities from the graph path, like correctly naming “symptom → disease → treatment” in order. This checks the process, not just the final pick.
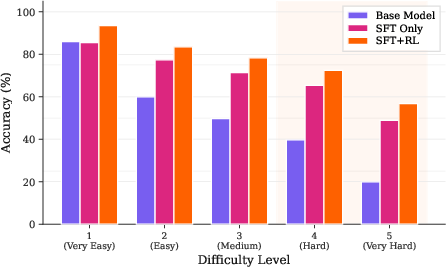
They used a medical knowledge graph (UMLS) and tested on ICD-Bench, which has multiple-choice questions across medical categories with difficulty levels and different hop lengths.
What they found and why it matters
Here are the main takeaways in simple terms:
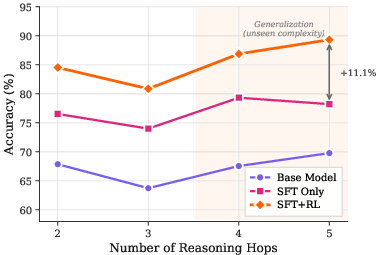
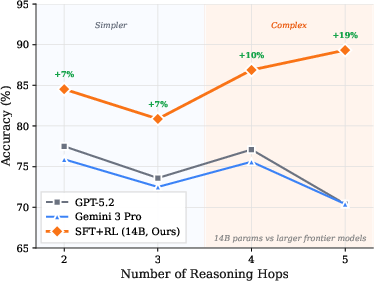
- Training on short paths teaches “how to think”: The model was trained on 1–3-hop paths but performed better than baselines on unseen 4–5-hop questions. In other words, it learned the skill of building longer reasoning chains from shorter ones.
- Rewards that check the process matter: The best results came from combining “final answer correctness” with “path alignment” rewards. Rewarding long explanations alone didn’t help and could be gamed; copying expert style (similarity) wasn’t as effective as using the right facts.
- RL alone wasn’t enough: Starting RL from a base model didn’t consistently beat SFT. Warming up with SFT gave the model the basic facts; RL then taught it to connect those facts well.
- Strong on hard problems: The model’s biggest gains were on the toughest questions (longer hop chains and higher difficulty). It kept high accuracy even when options were shuffled (so it wasn’t relying on option position or tricks).
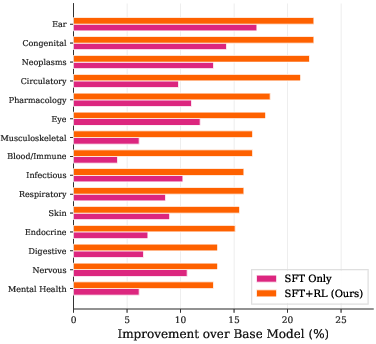
- Competitive with big models: Despite being smaller, the model often beat much larger, well-known systems on complex, multi-hop medical reasoning. That suggests smart training can sometimes beat raw size.
Why this is important
- Safer, more reliable reasoning: In fields like medicine, it’s not enough to sound confident; models must show the right chain of evidence. This approach rewards that—step by step.
- Scalable supervision without tons of human labels: Using a knowledge graph as a “reward coach” means you can score millions of reasoning chains automatically and consistently.
- Small models can out-reason big ones: With good data and smart rewards, smaller models can solve harder problems more reliably, which is cheaper and more practical.
- Works beyond medicine: Any area with a structured knowledge graph—like chemistry, law, or biology—could use this method to build models that reason from first principles, not just patterns.
In short, grounding AI in true, checkable facts and rewarding the path it takes to reach an answer is a powerful way to build models that think more like careful problem-solvers, not just good guessers.
Knowledge Gaps
Below is a concise list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future research:
- Benchmarking transparency: The comparisons to GPT-5.2, Gemini 3 Pro, and QwQ-Med-3 lack full reproducibility details (prompt templates, sampling settings, system prompts, API versions, context windows, n-samples, majority vote specifics), preventing rigorous third-party verification.
- Statistical rigor: Reported gains do not include confidence intervals, significance tests, multiple seeds, or variance across runs; robustness to random initialization and sampling stochasticity remains unquantified.
- Reward scaling anomaly: With α=0.1, β=1, and R_max=1.5, an incorrect answer can still yield a positive total reward (up to +0.5), potentially incentivizing plausible but wrong reasoning. A principled calibration of reward weights to prevent net-positive rewards on incorrect completions is needed.
- Entity-only alignment: The path alignment reward uses entity token coverage and ignores relations, directionality, and causal structure. It remains unclear whether the model composes the correct relations or merely name-drops entities.
- Order and causality: The reward does not enforce step order or causal dependencies along the KG path. Sequence-aware and relation-aware alignment (e.g., ordered path matching, alignment cost, or graph-edit distance) is not explored.
- Multi-path validity: Many medical queries can be solved by multiple legitimate KG paths. The reward assumes a single “ground-truth” path, risking penalization of alternative correct chains. Methods to support multi-path rewards are not investigated.
- Synonyms and concept normalization: Token-based matching may miss valid synonyms or concept variants (e.g., abbreviations, lexical differences). The paper does not evaluate entity linking or ontology-normalized matching to reduce false negatives/positives.
- KG quality and coverage: The approach presumes UMLS completeness and correctness. The effects of missing, conflicting, or outdated KG facts on training and evaluation are not quantified; mechanisms for handling KG noise and updates are unspecified.
- Distribution shift and out-of-KG reasoning: The pipeline is untested on tasks requiring entities or relations absent from the KG, leaving unknown how the model behaves when necessary facts are missing or uncertain.
- Upper limits of compositional length: Training covers 1–3 hops and evaluation 2–5 hops; there is no analysis beyond 5 hops or of failure modes as path length increases (e.g., compounding errors, memory limits).
- Process-level evaluation: Beyond token coverage, there is no independent assessment of reasoning trace faithfulness (human or expert review, causal consistency checks, step verification) to ensure explanations reflect the model’s actual reasoning.
- Reward hacking diagnostics: While repetition penalties are introduced, systematic detection and analysis of reward exploitation (e.g., gratuitous entity insertion, template boilerplate) are absent.
- RL hyperparameter sensitivity: GRPO settings, group sizes, sampling budgets, learning rates, and reward normalization choices are not thoroughly ablated; stability regions and failure modes are unclear.
- RL-only capacity and scaling: The conclusion that “RL alone is insufficient” is based on limited budgets and vanilla configurations; whether stronger RL (e.g., actor-critic, off-policy, curriculum RL, longer budgets) could match or exceed SFT+RL is not resolved.
- Compute and efficiency: Training time, GPU hours, memory footprints, and cost vs. performance trade-offs are not reported; sample efficiency of the path-derived reward remains unquantified.
- Test-time compute policy: Apart from majority voting in one comparison, the paper does not specify test-time sampling strategies (n, temperature) across all experiments; effects of test-time compute on robustness and accuracy are not analyzed.
- MCQ format limitations: The evaluation relies on multiple-choice questions, which may enable elimination heuristics and overestimate reasoning quality; performance on open-ended, free-text clinical cases is unknown.
- Robustness breadth: Option shuffling is the only format perturbation studied. Harder stressors (shuffling correct option position, paraphrased prompts, adversarial distractors, contradictory evidence, long-context noise) are not evaluated.
- Pretraining contamination: Despite train-test separation at path/entity levels, potential overlap of UMLS facts in model pretraining could inflate zero-shot performance; contamination audits are not presented.
- Error analysis: The paper lacks qualitative failure analysis (e.g., typical error types by hop length, category, relation type), limiting insight into current weaknesses and prioritization for future fixes.
- ICD-10 coverage metrics: Node/relation coverage statistics and their correlation with performance across categories are not reported; it remains unclear which coverage thresholds are necessary for generalization.
- Generality to other domains: The claim of domain-agnostic applicability is not empirically validated; portability to KGs in chemistry, law, finance, or engineering (with different schemas and noise profiles) is untested.
- Handling uncertainty: Medical reasoning often involves ambiguity. The pipeline does not model or reward calibrated uncertainty, abstention, or confidence expression; links to uncertainty-aware rewards remain unexplored.
- Relation-type weighting: All relations are implicitly treated equally in path alignment. Exploring relation-specific weights (e.g., stronger signals for causal/mechanistic edges) could improve reasoning fidelity; this is not investigated.
- Multi-lingual and cross-lingual robustness: The method’s reliance on English token matching and UMLS concepts leaves open questions about applicability in non-English settings and multilingual KGs.
- Tool use and structured traversal: The approach does not integrate explicit graph traversal or planning tools (e.g., MCTS, symbolic executors) at inference; whether such integration improves faithfulness and long-horizon reasoning is unknown.
- Safety and clinical validity: There is no assessment of potential harms from incorrect reasoning, misdiagnosis, or outdated KG facts; safety audits, calibration, and human-in-the-loop safeguards are not discussed.
- Dataset provenance and LLM-generated artifacts: The training/test questions and reasoning traces are LLM-generated; the impact of stylistic artifacts and distribution biases on generalization to human-authored clinical materials is not measured.
- Release and replicability: Code, data, prompts, and trained checkpoints are not stated as publicly available; without these, community replication and extension are hindered.
- Transfer protocol clarity: The statement that insights “transfer effectively from 8B to 14B” lacks detail on the transfer mechanism (retraining vs. weight initialization, hyperparameter changes), leaving open questions about scalability and porting best practices.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed with today’s tools, given a suitable domain knowledge graph (KG), entity linking, and modest SFT+RL compute.
- Healthcare — KG-grounded clinical decision support
- What: Suggest differentials, tests, drug choices, and contraindications with a step-by-step rationale aligned to UMLS paths.
- Product/workflow: “Path-backed CDS” EHR sidebar that shows the triples/hops supporting each recommendation.
- Assumptions/dependencies: High-quality and current medical KG (e.g., UMLS + drug–disease–interaction extensions), reliable clinical NER/entity linking, human-in-the-loop review; not for autonomous use without regulatory clearance.
- Healthcare — ICD-10 coding and audit
- What: Map notes to ICD-10 codes with KG-aligned reasoning chains that justify code selection and support audits.
- Product/workflow: “Coder cockpit” that highlights the specific path (e.g., symptom → disease → code) used; batch audit reports with path coverage metrics.
- Assumptions/dependencies: Coverage and correctness of ICD-10 mappings in KG; PHI-safe data pipelines; institutional acceptance of machine-generated rationales.
- Healthcare — Pharmacovigilance and safety signal triage
- What: Prioritize adverse event reports by composing drug–mechanism–effect relations; reduce hallucinated causal links.
- Product/workflow: Safety triage console ranking cases by path evidence score (R_path) and showing supporting triples.
- Assumptions/dependencies: Drug safety KG (e.g., SIDER/FAERS-integrated), good synonym/alias handling, clinician oversight.
- Healthcare and Education — Medical tutoring and assessments
- What: Generate multi-hop MCQs and explanations with controllable difficulty (1–5 hops), and grade student rationales by path coverage.
- Product/workflow: “Compositional curriculum generator” and “path-aligned grader” for medical schools and CME.
- Assumptions/dependencies: KG coverage across target specialties; guardrails to avoid leakage of test content; bias/coverage checks.
- Software/ML — RL post-training without human preferences
- What: Replace/augment RLHF with KG-derived “verifiable rewards” (R_bin + R_path) for domain LLMs.
- Product/workflow: KG-RLVR training recipe (SFT via LoRA + GRPO with path-alignment reward), CI pipeline to re-train as KG updates.
- Assumptions/dependencies: Domain KG, chain-of-thought enabled during training, stable GRPO configuration; monitoring for repetition/reward hacking.
- Enterprise Knowledge — Multi-hop QA over internal KGs
- What: Answer policy/procedure/product questions with evidence chains over an enterprise KG (e.g., org → system → control → requirement).
- Product/workflow: “Compositional QA agent” that returns the answer plus the traversed graph path and node snippets.
- Assumptions/dependencies: Well-curated enterprise KG; entity linking from unstructured docs to KG nodes; access controls.
- Finance — AML/fraud analyst assist
- What: Explain suspicious activity by composing transaction–entity–jurisdiction relations and providing auditable reasoning chains.
- Product/workflow: Investigator assistant that ranks cases by path evidence and highlights multi-hop money flows.
- Assumptions/dependencies: High-fidelity transaction KG; strict privacy/sovereignty controls; human adjudication.
- Legal/Policy — Regulation and compliance assistants
- What: Grounded answers that connect obligations → controls → exceptions via a regulation/caselaw KG with cited hops.
- Product/workflow: Compliance navigator that shows the governing path (statute → rule → guidance → precedent).
- Assumptions/dependencies: Up-to-date legal KG; rigorous citation canonicalization; jurisdictional scoping.
- Evaluation and QA — Robustness and audit tooling
- What: Test suites for format robustness (e.g., option-shuffling), hop-length stratified reporting, and path-coverage dashboards.
- Product/workflow: “PathScore” verifier and robustness harness integrated into model QA/MLOps.
- Assumptions/dependencies: Access to evaluation KGs; standardized entity canonicalization; governance for model logging and trace storage.
Long-Term Applications
These use cases need further research, scaling, integration, or regulatory work before broad deployment.
- Healthcare — Real-time, regulation-grade clinical decision support
- What: On-the-fly treatment planning and risk prediction with verified KG-backed chains, integrated into clinician workflow.
- Product/workflow: FDA/CE-marked CDS with uncertainty calibration, counterfactual paths, and automatic provenance logging.
- Assumptions/dependencies: Prospective clinical validation, post-market surveillance, robust coverage of guidelines in KG, safety cases.
- Science and R&D — Autonomous hypothesis generation and experiment planning
- What: Compose biochemical/chemical pathways (e.g., reaction rules, targets, phenotypes) to propose testable hypotheses and experiment sequences.
- Product/workflow: “KG-guided discovery engine” combining lab ontologies with LLM reasoning and lab automation.
- Assumptions/dependencies: High-fidelity KGs (e.g., ChEBI/Reactome), integration with ELN/LIMS, closed-loop data-to-KG updates.
- Law — Grounded drafting and argumentation assistants
- What: Compose multi-hop legal arguments that are verifiably tied to statutes, regulations, and precedents; generate and check citations.
- Product/workflow: Litigation and regulatory drafting copilots with path-aligned argument graphs and counter-argument exploration.
- Assumptions/dependencies: Comprehensive legal KGs, jurisdiction/version tracking, judicial acceptance of AI-produced rationale trails.
- Finance and Risk — Compositional risk engines
- What: Multi-hop reasoning over counterparty, supply-chain, ESG, and macro links to explain portfolio risks and scenario propagation.
- Product/workflow: “Explainable risk copilot” that surfaces KG paths driving risk scores and suggests mitigation actions.
- Assumptions/dependencies: Multi-source KG fusion, timeliness of data, governance for model risk management.
- Public Policy — Benefit eligibility and policy impact reasoning
- What: Compose eligibility rules and inter-program dependencies to give citizens explainable determinations and simulate policy changes.
- Product/workflow: Government digital assistants with path-backed determinations and appeal-ready evidence chains.
- Assumptions/dependencies: Machine-readable policy KGs, legal review, transparency mandates.
- Robotics and Planning — KG-rewarded task planning
- What: Use environment/object KGs as verifiable reward models to train planners that compose sub-tasks and constraints.
- Product/workflow: “KG-MPC” hybrid where text plans are verified against object-relationship KGs; training-time path rewards.
- Assumptions/dependencies: Reliable mapping from physical states to KG nodes, multi-modal grounding, sim-to-real transfer.
- Energy/Industrial — Root-cause analysis over asset KGs
- What: Diagnose grid or plant faults via multi-hop composition (sensor → component → subsystem → failure mode) with verifiable paths.
- Product/workflow: Operator assistant that proposes causes/fixes and shows KG paths and historic evidence.
- Assumptions/dependencies: Accurate asset and failure-mode KGs, streaming-to-KG entity linking, safety certification.
- Education (STEM at scale) — Adaptive compositional curricula
- What: Personalized pathways that gradually increase hop length and grade student reasoning by path alignment in domains like org. chemistry or physics.
- Product/workflow: LMS plugins that generate tasks and give path-specific feedback; instructor analytics by hop/difficulty.
- Assumptions/dependencies: Domain KGs with pedagogy-aware structure, fairness and bias controls.
- National/Enterprise KG infrastructure and governance
- What: Sustained investment to maintain, version, and expand KGs (coverage, canonicalization, provenance) as critical AI infrastructure.
- Product/workflow: KGOps (schema governance, continuous curation), KG–LLM co-training loops, standards for path-based evaluation.
- Assumptions/dependencies: Funding, inter-agency/industry collaboration, open standards, privacy-preserving entity linking.
- Continual learning and on-device specialists
- What: Lightweight LoRA/RL updates as KGs evolve; domain specialists running on edge with verifiable reasoning.
- Product/workflow: Incremental KG-RLVR updates, telemetry-driven reward shaping, red-team stress suites.
- Assumptions/dependencies: Efficient training pipelines, on-device security, robust mitigation of reward hacking.
Notes on feasibility and transferability across all applications:
- Core dependencies: a well-curated, up-to-date domain KG; accurate entity linking/canonicalization; access to chain-of-thought for training; stable GRPO/SFT stacks.
- Risk considerations: KG incompleteness or bias will steer rewards; reasoning-trace exposure may create privacy/IP risks; regulatory constraints (especially in healthcare/finance/law) demand human oversight and auditability.
- Generalization limits: Demonstrated gains to 4–5 hops; performance beyond that, under distribution shift, or against sophisticated adversaries, requires further validation and potentially richer path-reward designs (e.g., relation-level matching, paraphrase-robust entity normalization).
Glossary
- Axiomatic triples: Structured facts in a knowledge graph represented as (head, relation, tail) that serve as building blocks for reasoning. "axiomatic triples "
- Chain-of-thought: The intermediate reasoning trace generated by a model before the final answer. "chain-of-thought"
- Compositional reasoning: The ability to combine multiple axiomatic facts across steps to solve complex problems. "it requires compositional reasoning: the ability to reliably combine axiomatic facts for complex multi-hop problem solving"
- Direct Preference Optimization (DPO): A post-training method that optimizes models to match preferences directly without explicit reward modeling. "direct preference optimization \cite{Rafailov2023DirectModel}"
- Distillation-based reward: A training signal that scores outputs by similarity to expert-produced reasoning traces. "A distillation-based reward that measures the Jaccard similarity between the model output and an expert reasoning trace"
- Group Relative Policy Optimization (GRPO): A PPO-like RL algorithm that estimates advantages at the group level and omits the critic. "Group Relative Policy Optimization (GRPO)"
- ICD-10: The World Health Organization’s standardized coding system for diseases and health conditions. "ICD-10 category breakdowns"
- ICD-Bench: A held-out benchmark of medical multi-hop reasoning questions used for evaluation. "we use ICD-Bench, a non-overlapping test set of 3,675 questions"
- Jaccard similarity: A set-based metric measuring the overlap between two sets, used to compare reasoning traces. "Jaccard similarity"
- Knowledge graphs (KGs): Structured representations of entities and relations that encode domain knowledge for grounding and verification. "Knowledge graphs (KGs)"
- Link prediction: A KG task that infers missing triples or entities by reasoning over graph structure. "(link prediction)"
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning method that adapts models via low-rank updates. "Low-Rank Adaptation (LoRA)"
- Majority voting: An aggregation method that selects the most frequent answer across multiple samples. "majority-voting () metric"
- Multi-hop reasoning: Reasoning that requires traversing multiple linked steps (hops) in a knowledge graph to reach a conclusion. "compositional multi-hop reasoning"
- Negative sampling reinforcement: A training strategy that penalizes incorrect generations more heavily to encourage exploration of correct trajectories. "negative sampling reinforcement"
- Ontology: A formal representation of concepts and their relationships in a domain, often encoded in KGs. "medical ontology"
- Option shuffling: A robustness stress test that randomizes the order of distractor choices to detect positional biases. "option shuffling"
- Path alignment: Rewarding model reasoning that matches entities along a ground-truth KG path. "Path Alignment"
- Post-training: Additional training stages (e.g., SFT and RL) applied after pretraining to refine capabilities. "post-training pipeline"
- Proximal policy optimization: An on-policy RL method that stabilizes updates via a clipped objective. "a popular proximal policy optimization-like optimizer"
- Process supervision: Training that rewards intermediate reasoning steps rather than only final answers. "Whereas process supervision (rewarding intermediate steps) has shown promise in mathematics and logic"
- Reinforcement Learning (RL): A learning paradigm where models optimize behavior via reward signals. "reinforcement learning (RL)"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL pipeline that uses grounded, automatically verifiable reward signals. "Reinforcement Learning with Verifiable Rewards (RLVR) Pipeline"
- Repetition penalty: A penalty in the reward function that discourages repetitive text to prevent reward exploitation. "repetition penalty"
- Retrieval-augmented generation: A method where models retrieve external knowledge to inform generation. "retrieval-augmented generation systems"
- Reward hacking: Exploiting imperfections in the reward function to achieve high scores without genuine reasoning. "reward hacking"
- Reward model: A learned or implicit model that scores outputs to provide feedback for RL training. "reward models"
- Reward shaping: Modifying or augmenting reward signals to improve learning dynamics and guide behavior. "reward shaping"
- Stochastic policy: A probabilistic mapping from inputs to a distribution over outputs (actions). "stochastic policy "
- Trajectory: The full sequence of generated tokens treated as a single unit for reward assignment in RL. "single trajectory"
- Unified Medical Language System (UMLS): A comprehensive biomedical knowledge base used to construct the medical KG. "Unified Medical Language System (UMLS)"
Collections
Sign up for free to add this paper to one or more collections.