- The paper introduces Controllable Code Completion (CCC) and the C³-Bench benchmark to measure instruction adherence in code LLMs.
- It employs metrics like Pass@1, Instruction-Following Rate, and Edit Similarity to assess both functional and controllability performance.
- Instruction tuning with synthetic pairs significantly improves model performance, addressing gaps in instruction-following capabilities.
Evaluating and Achieving Controllable Code Completion in Code LLMs
Motivation for Controllable Code Completion
The proliferation of code-centric LLMs (Code LLMs) has triggered notable improvements in automated code completion solutions, supporting diverse developer workflows. However, prevailing evaluation methodologies primarily emphasize functional correctness, typically assessed via similarity metrics or unit tests, while neglecting the models' capacity for nuanced instruction adherence—a critical real-world requirement. This disconnect has resulted in systematic overestimation of code LLM capabilities in production scenarios.
To bridge this evaluative gap, the paper introduces the concept of Controllable Code Completion (CCC), expanding the code completion task to explicitly incorporate fine-grained, user-supplied instructions that guide the completion process. CCC enables precise assessment of models' ability to heed specific implementation directives, such as algorithmic strategies, architectural organization, or block-level code scale, beyond passing unit tests.
C3-Bench: Benchmark Design and Construction
The authors present C3-Bench, an instruction-guided code completion benchmark engineered to evaluate both functional correctness and controllability of completions. C3-Bench comprises 2,195 Python CCC test instances, partitioned into:
1. Implementation-Control Completion (ICC):
Tasks require completion of the middle code segment per detailed implementation requirements (structural specification, algorithmic approach, control-flow, or parameter management), sampled from common software engineering demands.
2. Scale-Control Completion (SCC):
Tasks demand completion of code segments of precisely specified scope (line span, multi-line sequence, or statement block), forming a rigorous test for scale adherence.
Automation and quality control are enforced throughout benchmark construction. Middle code extraction leverages AST parsing and tree manipulation to access semantically coherent blocks from HumanEval and SAFIM datasets. Multiple implementations are generated via advanced LLMs, thoroughly validated against unit tests and expert consistency checks. Instruction generation employs both manual curation and LLM assistance, with explicit validation by senior developers and automated systems.
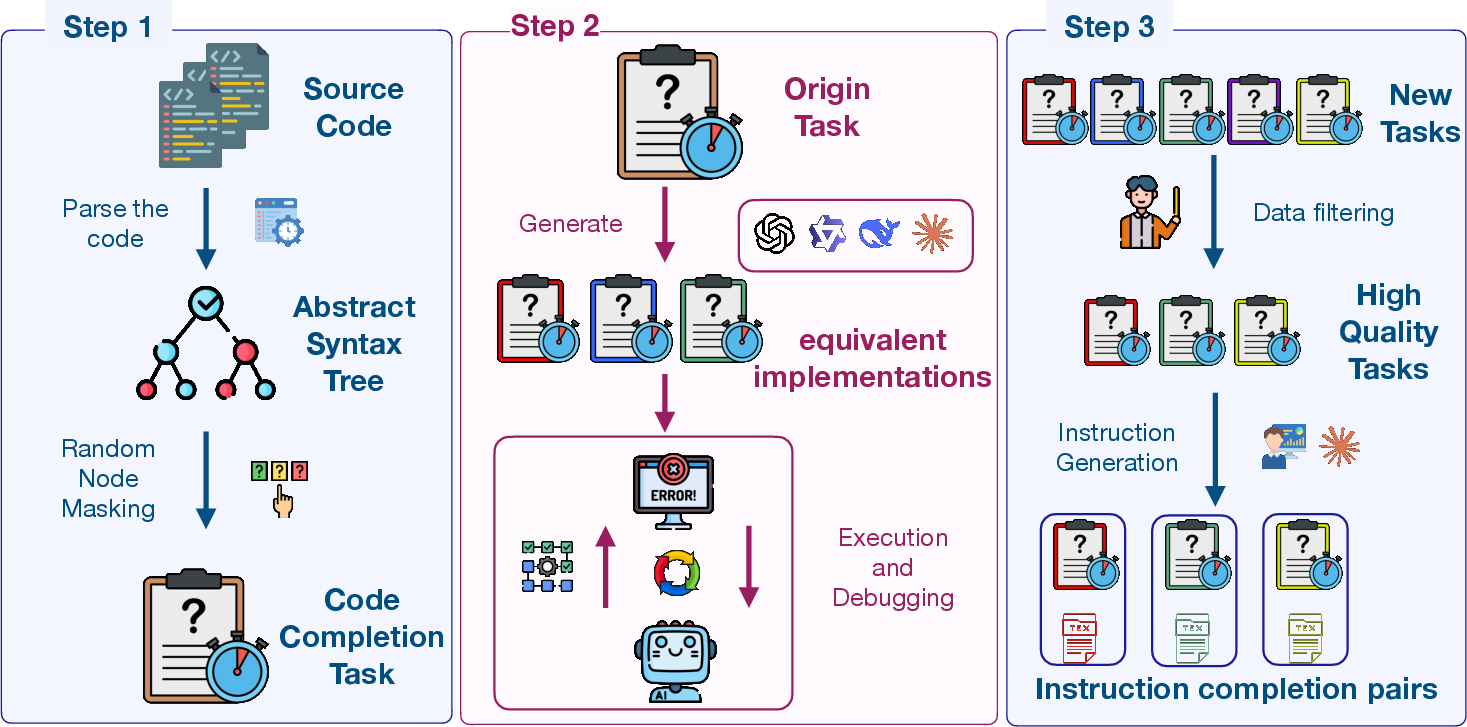
Figure 1: Overview of the construction pipeline of C3-Bench.
Evaluation Metrics for Controllability
C3-Bench incorporates three principal metrics:
- Pass@1: Execution-based correctness via unit tests for ICC tasks.
- Instruction-Following Rate (IF): Measures adherence to specified requirements; assessed semantically for ICC using LLM-based automated judging and structurally for SCC via AST analysis.
- Edit Similarity (ES): Token-level static analysis to preliminarily evaluate generation quality.
Extensive validation of the LLM-judging framework reveals 98% agreement with expert evaluations, evidencing reliable automated assessment of instruction adherence.
Data Synthesis and Model Enhancement
To ameliorate the paucity of instruction-completion training pairs for open-source models, the authors devise an automated synthesis pipeline leveraging Qwen2.5-Coder-32B-Instruct, capable of producing large-scale pairs from unsupervised GitHub repositories, bootstrapped from manually curated seeds. This corpus enables supervised fine-tuning to enhance instruction-following abilities.
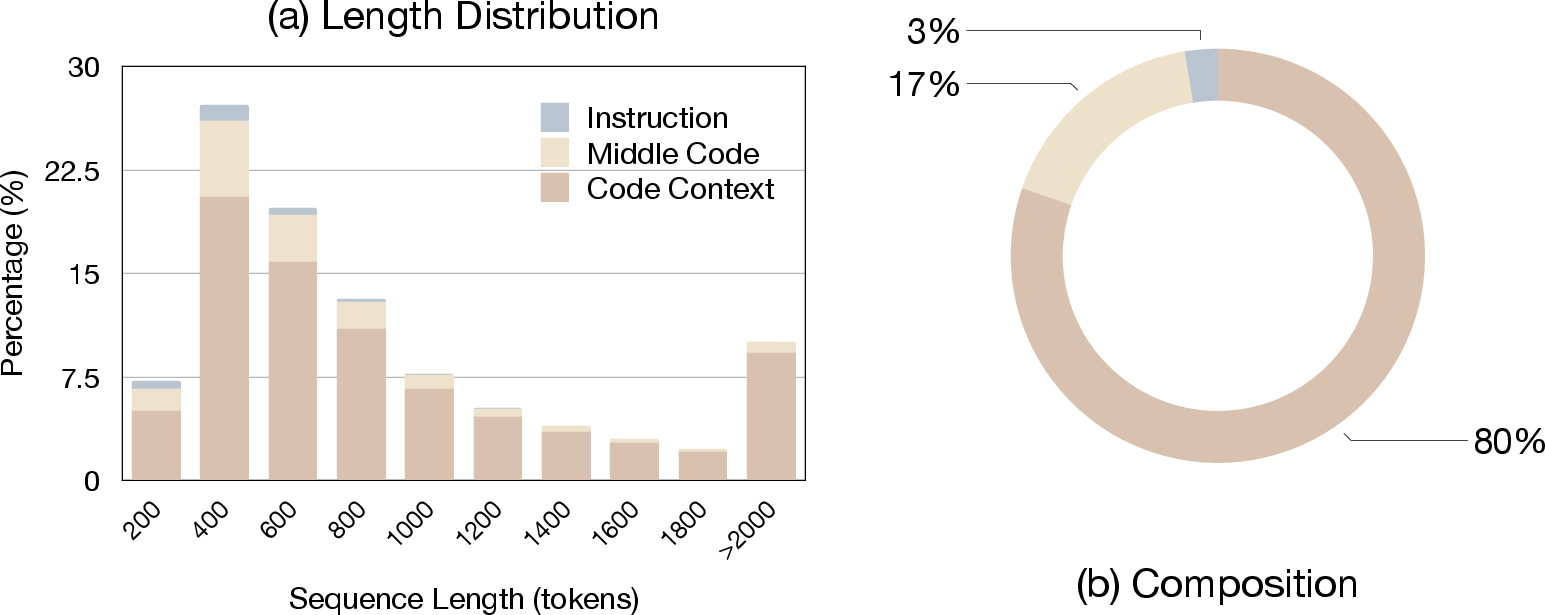
Figure 2: Training dataset analysis showing (a) sequence length distribution and (b) average component composition (Context Code, Middle Code, and Instruction).
Resulting models, Qwen2.5-Coder-C3 (1.5B and 32B variants), are trained with strict decontamination strategies to preclude benchmark data leakage.
Empirical Findings and Analysis
Comprehensive benchmarking across 40+ models—including leading proprietary (GPT series, Claude, Gemini, o1-series) and open-source code-specialized LLMs (Qwen, DeepSeek, StarCoder, CodeStral)—exposes several key phenomena:
Ablation Study on Instruction Guidance
Removing instructions from query prompts causes significant degradation in IF, whereas execution-based correctness (Pass@1) remains largely stable. The pronounced drop in IF unambiguously demonstrates the necessity of explicit instruction for true controllability in code completion.
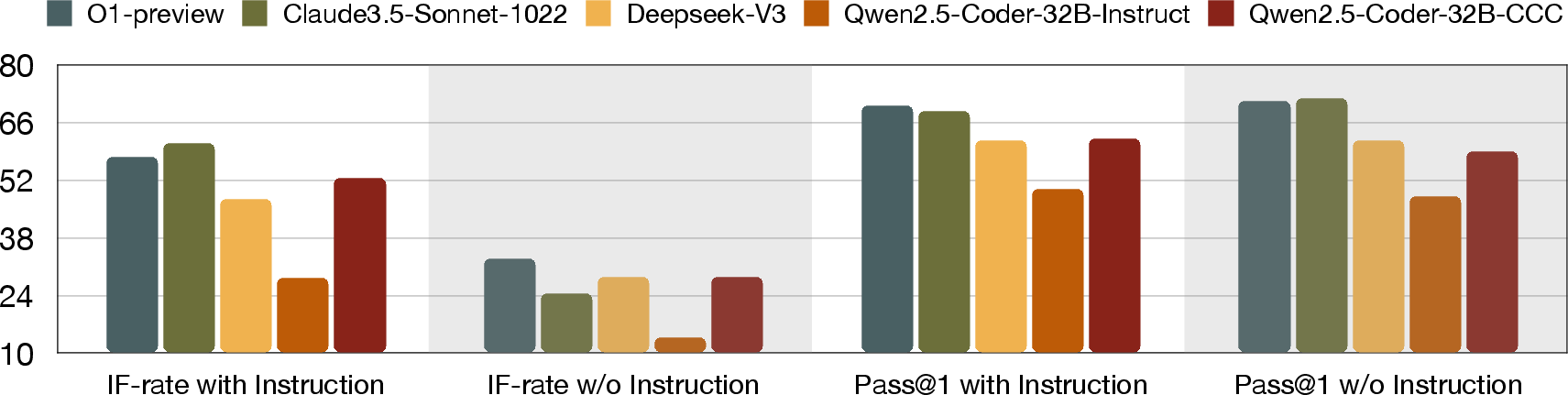
Figure 4: Impact of instruction guidance on model performance. Pass@1 and IF-rate metrics are compared across models under two conditions: with instructions and without instructions.
Task-level Insights
- Differentiated model behavior: Models vary in their ability to follow implementation versus scale-control instructions. Top proprietary models exhibit robust ICC adherence but often struggle with strict SCC constraints, suggesting deficiencies in training objectives or token-level modeling of code scale.
- Ranking correlations: C3-Bench results are strongly correlated with models' performance on tasks requiring deep context understanding (ExecRepoBench) and human preference evaluations (Chatbot Arena), indicating that instruction-following ability is integral to advanced code comprehension.
Technical Implications
The research decisively demonstrates that traditional code completion evaluation metrics are insufficient for gauging instruction adherence. Instruction-guided benchmarks are essential to ascertain the practical effectiveness and controllability of code LLMs in production systems. The data synthesis approach for scalable instruction-completion pair generation offers a tractable strategy for enhancing open-source LLM performance in controllable completion.
Moreover, the work highlights three crucial challenges for future research:
- Extension to multi-language and repository-level code contexts, increasing the generalizability of benchmarks.
- Refinement of base model capabilities, especially for ICC tasks where bottlenecks in semantic understanding undermine improvements.
- Development of lightweight, generalizable benchmarks and automated evaluators that are agnostic to infrastructure constraints.
Conclusion
C3-Bench establishes a rigorous, instruction-guided evaluation protocol for Code LLMs, revealing significant gaps in instruction-following capabilities and providing actionable strategies to enhance model controllability. The research substantiates that true code intelligence in LLMs must be measured not purely by functional correctness, but also by precise adherence to user intentions and requirements. The implications for AI development are clear: the next era of code LLM research must systematically integrate instruction-following evaluation and enhancement to realize robust, reliable, and user-aligned code generation systems.