Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders
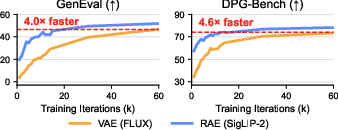
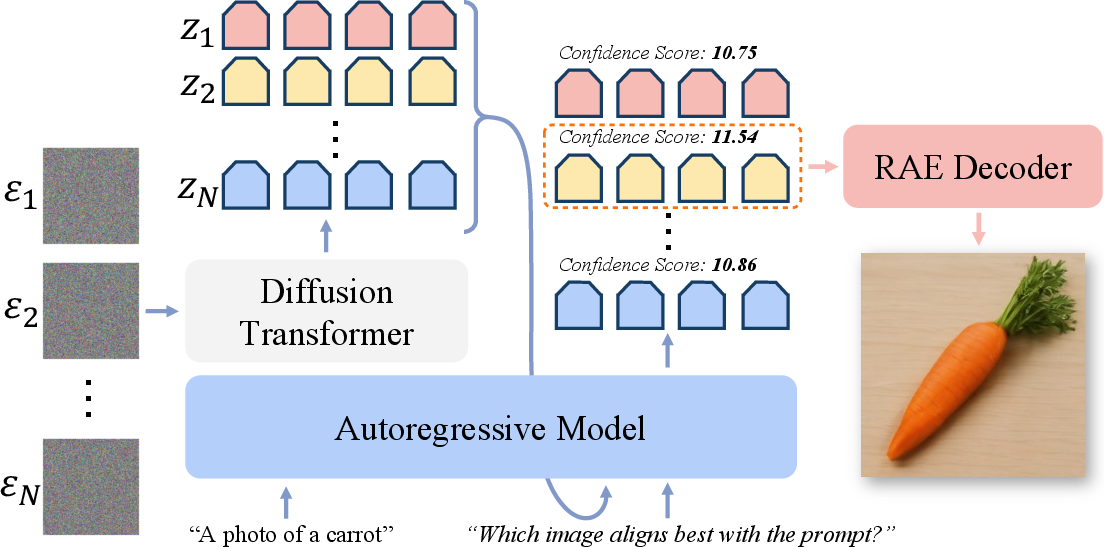
Abstract: Representation Autoencoders (RAEs) have shown distinct advantages in diffusion modeling on ImageNet by training in high-dimensional semantic latent spaces. In this work, we investigate whether this framework can scale to large-scale, freeform text-to-image (T2I) generation. We first scale RAE decoders on the frozen representation encoder (SigLIP-2) beyond ImageNet by training on web, synthetic, and text-rendering data, finding that while scale improves general fidelity, targeted data composition is essential for specific domains like text. We then rigorously stress-test the RAE design choices originally proposed for ImageNet. Our analysis reveals that scaling simplifies the framework: while dimension-dependent noise scheduling remains critical, architectural complexities such as wide diffusion heads and noise-augmented decoding offer negligible benefits at scale Building on this simplified framework, we conduct a controlled comparison of RAE against the state-of-the-art FLUX VAE across diffusion transformer scales from 0.5B to 9.8B parameters. RAEs consistently outperform VAEs during pretraining across all model scales. Further, during finetuning on high-quality datasets, VAE-based models catastrophically overfit after 64 epochs, while RAE models remain stable through 256 epochs and achieve consistently better performance. Across all experiments, RAE-based diffusion models demonstrate faster convergence and better generation quality, establishing RAEs as a simpler and stronger foundation than VAEs for large-scale T2I generation. Additionally, because both visual understanding and generation can operate in a shared representation space, the multimodal model can directly reason over generated latents, opening new possibilities for unified models.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.