Exploring the Effects of Alignment on Numerical Bias in Large Language Models
Abstract: ``LLM-as-a-judge,'' which utilizes LLMs as evaluators, has proven effective in many evaluation tasks. However, evaluator LLMs exhibit numerical bias, a phenomenon where certain evaluation scores are generated disproportionately often, leading reduced evaluation performance. This study investigates the cause of this bias. Given that most evaluator LLMs are aligned through instruction tuning and preference tuning, and that prior research suggests alignment reduces output diversity, we hypothesize that numerical bias arises from alignment. To test this, we compare outputs from pre- and post-alignment LLMs, and observe that alignment indeed increases numerical bias. We also explore mitigation strategies for post-alignment LLMs, including temperature scaling, distribution calibration, and score range adjustment. Among these, score range adjustment is most effective in reducing bias and improving performance, though still heuristic. Our findings highlight the need for further work on optimal score range selection and more robust mitigation strategies.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how “alignment” (training a LLM to follow instructions and match human preferences) changes the way LLMs give numeric scores when they act as judges. The authors found that aligned models often show “numerical bias,” meaning they tend to repeat certain scores too much (like sticking to an 8 out of 10), which can make their judgments less reliable.
What are the main questions?
The paper asks two big questions:
- Does alignment cause LLMs to develop numerical bias when they score things?
- If numerical bias happens, what simple ways can reduce it and improve the model’s judging performance?
How did they study it?
To keep things clear, here’s the approach they took and what the terms mean.
What is “LLM-as-a-judge”?
Instead of using old-style metrics that compare text to a reference (like BLEU or ROUGE), “LLM-as-a-judge” asks a model to read a text and directly give a score (for quality, correctness, etc.). This can save time because you don’t need human references for every case.
What is “alignment”?
Alignment includes training methods (like instruction tuning and preference tuning) that teach the model to follow instructions and respond more like a helpful human. Think of it as teaching the model good manners and consistent habits. But alignment can also make the model’s answers less diverse—like learning to “play it safe.”
Pre-alignment vs. post-alignment models
- Pre-alignment: The model before it’s taught to follow instructions well.
- Post-alignment: The model after it’s been trained to follow instructions.
They compared these two to see how alignment changes scoring behavior.
Tasks and data (in everyday terms)
The models judged three types of tasks, all using numeric scores:
- MTQE (Machine Translation Quality Estimation): How good is a translation without comparing it to a reference?
- GECQE (Grammatical Error Correction Quality Estimation): How good is a corrected sentence—does it fix grammar well?
- LCP (Lexical Complexity Prediction): How hard a given word is to understand in a sentence.
These tasks used several language pairs (like English–German) and datasets where humans had already scored many examples.
Measuring “numerical bias” and “accuracy”
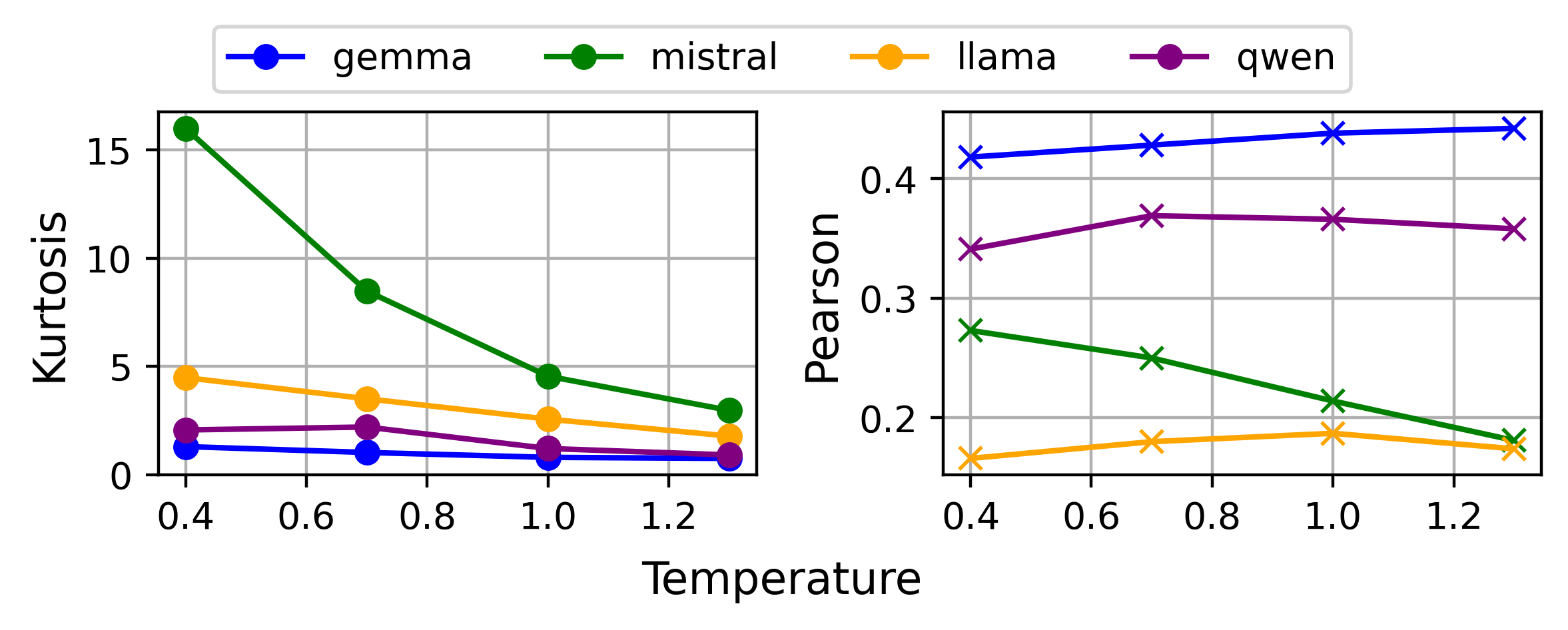
- Numerical bias: The tendency to overuse certain numbers (like mostly giving 8s or 9s). They measured this with a statistic called “kurtosis,” which (in simple terms) tells you how much scores pile up around specific values. High kurtosis = scores are sharply concentrated (strong bias).
- Accuracy of judgments: They used Pearson correlation (r) to check how well model scores match human scores. Higher r means better agreement with humans.
How did they try to reduce the bias?
They tested three simple strategies:
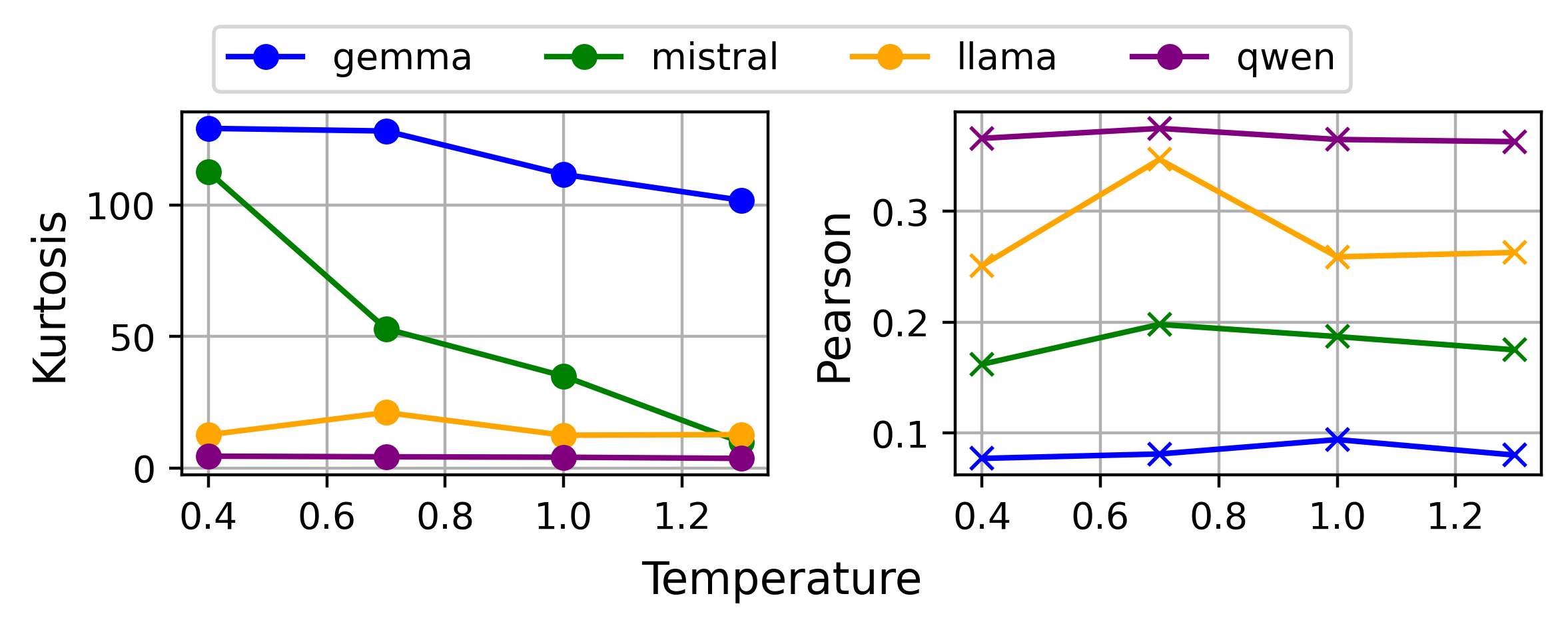
- Temperature scaling: A setting that controls how adventurous the model is when choosing the next token (including numbers). Higher temperature can spread choices out more (less sticking to one number), but too high can hurt accuracy.
- Distribution calibration: A method to adjust the model’s “favorite numbers” to better match the true distribution of scores in the data—like fixing a bathroom scale that tends to read too high for certain weights.
- Score range adjustment: Changing the scoring scale in the prompt (for example, 1–5 vs. 0–9 vs. 1–100). Different ranges can change which numbers the model picks and how biased the outputs are.
What did they find?
Here are the key results:
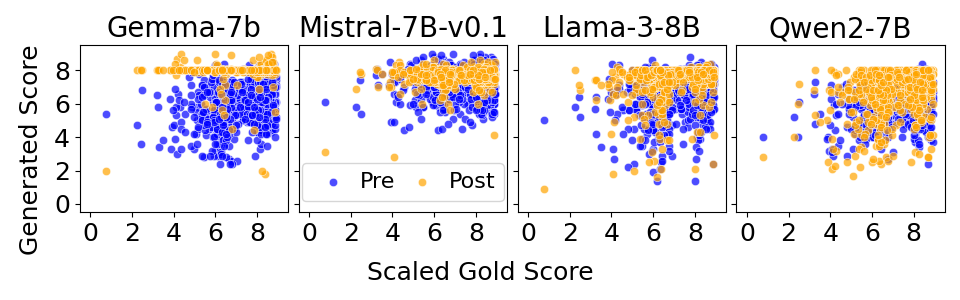
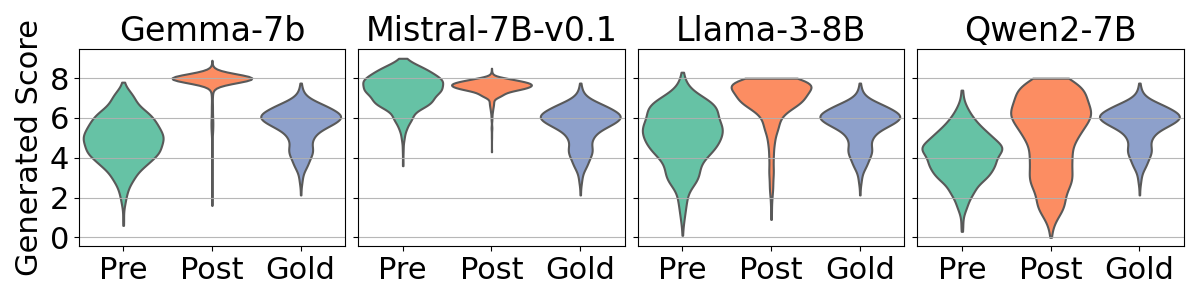
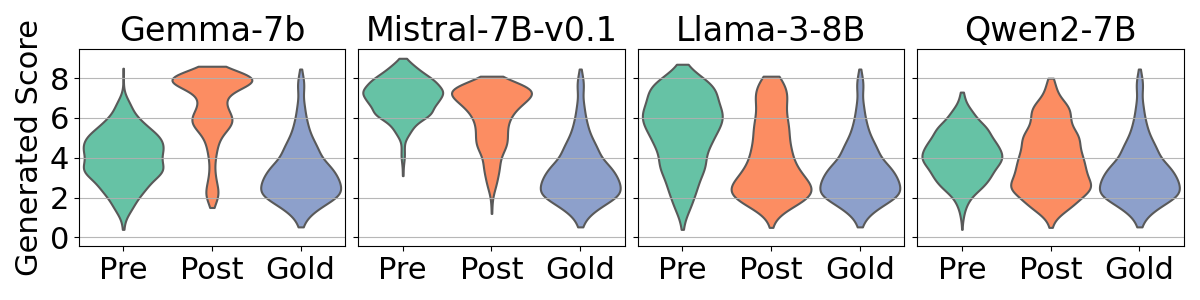
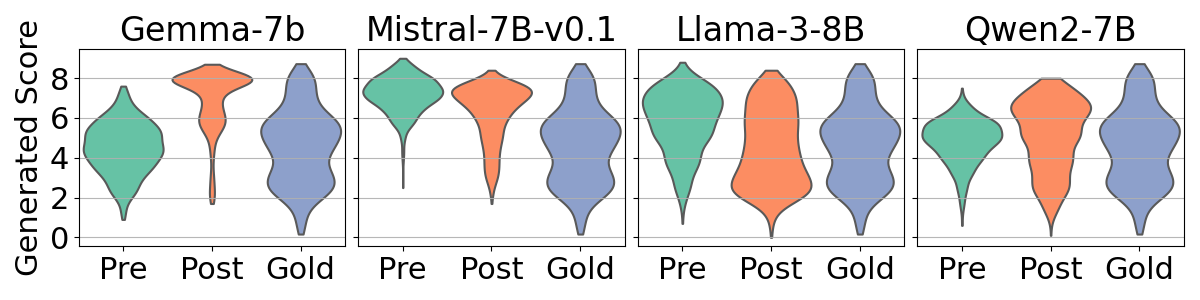
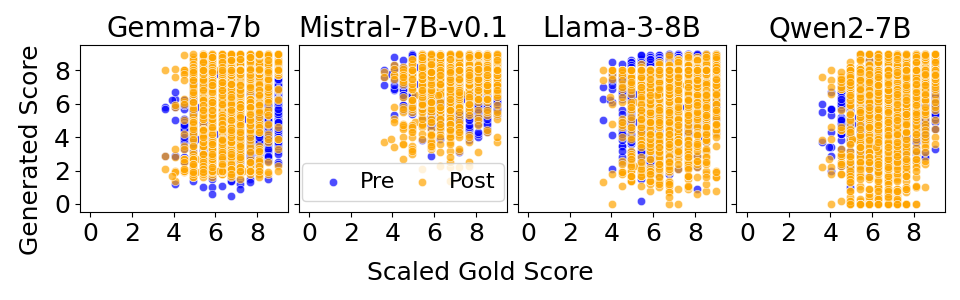
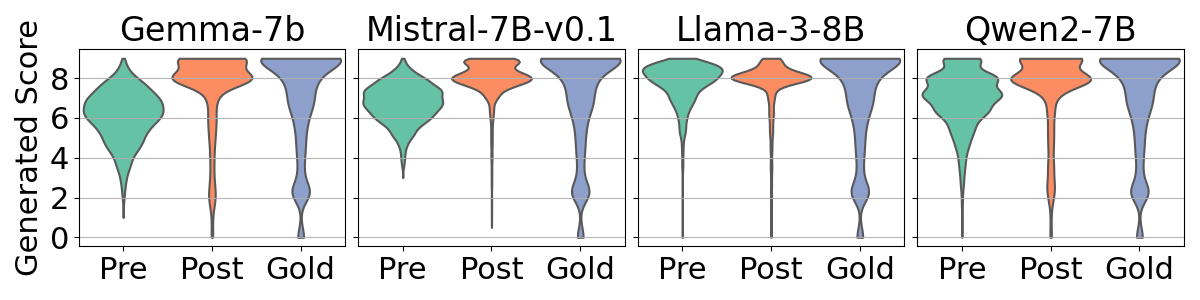
- Alignment increases numerical bias: Post-alignment models often cluster scores around specific values (frequently high scores like 8 out of 10), much more than pre-alignment models.
- Stronger bias usually means lower accuracy: Models with more concentrated score distributions tend to agree less with human scores (lower r).
- Bias varies by model and language: Some models (e.g., specific versions of Gemma or Mistral) show stronger bias than others (Llama, Qwen). High-resource languages (like English, German, Chinese—languages with more training data) tend to show stronger bias than low-resource languages (like Nepali and Sinhala).
- Mitigation helps, but not equally:
- Temperature scaling and calibration reduce bias, but don’t consistently boost accuracy.
- Score range adjustment was the most effective overall—often reducing bias and improving accuracy at the same time. However, the best range depends on the model and the task (there’s no one-size-fits-all).
Why is this important?
If LLM judges keep picking the same scores too often, they might miss real differences in quality. That can make evaluations less fair and less useful, especially when the human score distribution doesn’t match the model’s “favorite numbers.” The paper shows:
- Alignment makes models better at following instructions but can unintentionally cause them to overuse certain numbers.
- We can improve post-alignment models by dialing down this bias—especially by thoughtfully choosing the scoring range in prompts.
- Choosing evaluator models carefully (looking at both accuracy and bias) and tuning the score range can produce more trustworthy, human-like evaluations.
Simple takeaways and potential impact
- If you use LLMs as judges, watch out for numerical bias—don’t just check overall accuracy, also check how scores are distributed.
- Picking a model with lower bias and tuning the score range (like using 1–5 or 1–100 instead of 0–9 when appropriate) can lead to better, more reliable evaluations.
- Future research should find deeper fixes for bias, not just “patches,” and explore how alignment strength affects bias in different tasks and languages.
- This work can help anyone building automatic evaluation systems (for translation, grammar correction, readability, and beyond) make fairer, more accurate tools by choosing and configuring LLM judges more wisely.
Knowledge Gaps
Unresolved Knowledge Gaps and Open Questions
Below is a concise, actionable list of the key gaps, limitations, and open questions that remain after this study and that future researchers could address:
- Establish causal mechanisms linking alignment to numerical bias by running controlled alignment experiments that vary alignment method (e.g., SFT, RLHF, DPO/KTO), reward models, datasets, and alignment intensity on the same pretrained base.
- Identify the component(s) of alignment responsible for bias (e.g., reward model shaping vs. supervised instruction tuning) through ablation studies and alignment “dose–response” curves.
- Explain why specific numeric tokens (e.g., “8” on 0–9 scales) are disproportionately preferred by aligned LLMs via token-level probability analyses, logit lens diagnostics, and alignment data mining for rating-scale conventions.
- Quantify the role of tokenization and output-length constraints (e.g., max_token=5, BPE tokenization of multi-digit numbers) in amplifying numeric token concentration.
- Assess whether clipping out-of-range outputs to boundaries artificially increases kurtosis or distorts downstream correlation; compare clipping vs. rejection vs. resampling strategies.
- Develop and validate alternative bias metrics beyond kurtosis (e.g., entropy, KL divergence from gold distributions, mode frequency, Earth Mover’s Distance, calibration error) and test their robustness across datasets and scales.
- Test generalizability beyond numeric regression tasks to categorical labels, pairwise comparisons, rankings, and natural-language justifications (e.g., does bias manifest in discrete categories or pairwise preference judgments?).
- Evaluate whether producing a rationale first and then extracting a score (chain-of-thought to numeric mapping) reduces numerical bias compared to direct scoring.
- Investigate decoding-level mitigations beyond temperature (e.g., top-p/nucleus, top-k, entropy regularization, logit bias on numeric tokens, mixture-of-decoding strategies) and their trade-offs with accuracy.
- Improve calibration methods that do not rely on gold distributions (q(y)); design unsupervised or semi-supervised label-marginal estimators suitable for real-world evaluation settings without ground truth.
- Build adaptive score-range selection algorithms that choose ranges per model/task without gold data, using proxy signals (e.g., numeric-token priors, distribution spread, entropy, outlier rates).
- Explore non-linear mappings between numeric tokens and continuous scales (e.g., quantile-based remapping, isotonic regression, monotonic transformations) to compensate for skewed numeric priors.
- Extend analysis across more model sizes and families (e.g., 7B vs. 70B, closed models like GPT-4/Claude) to determine how scale, architecture, and proprietary alignment pipelines influence bias.
- Validate kurtosis–accuracy relationships across a broader set of tasks, domains, and languages, and derive practical thresholds for using bias metrics to select evaluators without gold data.
- Examine the observed stronger bias in high-resource languages by quantifying language-specific representation in alignment datasets; test whether balancing or reducing overrepresented languages reduces bias.
- Analyze numeral conventions across scripts/languages (digits vs. words for numbers, localized rating scales) and test whether enforcing numeric-word outputs or locale-specific formats changes bias patterns.
- Develop per-instance bias predictors using richer features (e.g., readability, error density, semantic similarity, translation difficulty) to flag cases likely to elicit biased scoring.
- Compare aggregation strategies for multi-sample scoring (mean vs. median vs. trimmed mean vs. Bayesian estimators) and analyze sensitivity to the number of samples per input.
- Investigate prompt design effects (e.g., framing, rubric specificity, examples) on numeric bias and derive prompt templates that reduce token-level concentration without harming instruction-following.
- Measure robustness to distribution shifts: simulate mismatches between human and model score distributions and quantify correlation degradation; propose distributional robustness objectives for evaluators.
- Test pairwise- or tournament-style evaluation frameworks (e.g., Bradley–Terry/Thurstone models) as alternatives to single-shot numeric scoring to reduce reliance on biased numeric tokens.
- Evaluate the impact of prior-evaluation context (multi-instance assessments, anchoring effects) on numeric bias and design context-isolation protocols to mitigate carry-over biases.
- Check for potential dataset contamination (training exposure) in public models and assess how familiarity with evaluation sets affects both bias and apparent accuracy.
- Create alignment objectives explicitly regularizing numeric-token diversity (e.g., penalties on overused tokens, entropy constraints) and measure their effect on both bias and evaluation fidelity.
- Provide deployment-ready guidelines: derive data-free procedures (e.g., bias-proxy checks, adaptive range selection, default decoding settings) with empirically validated thresholds for practitioners.
Glossary
- Alignment: Post-training processes that steer an LLM’s behavior to match human intentions and values (e.g., via special fine-tuning). "Evaluators are primarily post-alignment LLMs, which undergo alignment methods such as instruction tuning~\cite{wei2022finetuned} and preference tuning~\cite{NEURIPS2022-b1efde53, rafailov2023direct}."
- Beta distribution: A continuous probability distribution on [0,1], often used to model asymmetric proportions or scores. "q(y) is modeled as a Beta distribution\footnote{Due to the asymmetry of gold scores, the Beta distribution is more appropriate than the normal distribution for this tasks.} with parameters and estimated via maximum likelihood."
- BLEU: An automatic machine translation metric based on n-gram overlap with reference texts. "Traditional automatic evaluation metrics, such as BLEU \cite{papineni-etal-2002-bleu} and ROUGE \cite{lin-2004-rouge}, assess quality based on overlap with reference texts."
- Clipping: Forcing out-of-range numerical outputs into a predefined interval by replacing them with boundary values. "For numeric values outside the specified range, clipping is applied to bring them within the range by replacing them with the upper or lower boundary value."
- Direct Assessment (DA): A human evaluation protocol that assigns absolute quality scores to individual items (e.g., sentences). "we use sentence-level\footnote{It can evaluate translations with contextual awareness while also being efficient for LLM-based evaluation in terms of processing speed.} Direct Assessment (DA) \cite{fomicheva-etal-2022-mlqe} scores from the WMT 2020 Shared Task on Quality Estimation"
- Distribution calibration: Adjusting a model’s output distribution so that predicted label frequencies match a target marginal distribution. "We also explore mitigation strategies for post-alignment LLMs, including temperature scaling, distribution calibration, and score range adjustment."
- GECQE: Grammatical Error Correction Quality Estimation; reference-less evaluation of the quality of GEC system outputs. "GECQE aims to automatically evaluate the quality of GEC system outputs without reference."
- In-context predictive distribution: The model’s predicted label distribution conditioned on the prompt/context used at inference time. "Their generative calibration approach adjusts the in-context predictive distribution by recalibrating the label marginal , estimated via Monte-Carlo sampling over LLM outputs."
- Instruction tuning: Supervised fine-tuning on instruction-following datasets to improve an LLM’s ability to follow prompts. "Given that most evaluator LLMs are aligned through instruction tuning and preference tuning, and that prior research suggests alignment reduces output diversity, we hypothesize that numerical bias arises from alignment."
- Kurtosis: A statistical measure of distribution “peakedness” used here to quantify concentration indicative of numerical bias. "we visualize these distributions and measure the kurtosis of the output scores, as kurtosis serves as a metric for numerical bias"
- Label marginal p(y): The prior (marginal) distribution over labels used to recalibrate predictions. "Their generative calibration approach adjusts the in-context predictive distribution by recalibrating the label marginal , estimated via Monte-Carlo sampling over LLM outputs."
- Label shift: A distributional change where the label proportions differ between training and test/evaluation settings. "Since numerical bias can be viewed as a label shift induced by the alignment data distribution, we apply this approach to correct the distribution of numeric tokens in LLM-based evaluation."
- LCP: Lexical Complexity Prediction; predicting how complex a target word is within a sentence. "LCP automatically predicts the complexity of words in a sentence, given a sentence and a target word pair."
- LLM-as-a-judge: Using an LLM to evaluate or score outputs in place of human judges or traditional metrics. "``LLM-as-a-judge,'' which utilizes LLMs as evaluators, has proven effective in many evaluation tasks."
- Logits: Pre-softmax scores output by a model that are converted to probabilities by a normalization function. "It scales the logits before applying softmax function, influencing the probability distribution of the next token selection."
- Mode ratio: The fraction of generated scores equal to the dataset’s most frequent score, used as an instance-level bias indicator. "Thus, we use the mode ratio, the proportion of generated scores matching the data’s mode (the most frequently generated score in the dataset), as an indicator of bias strength."
- Monte-Carlo sampling: Random sampling technique used to estimate quantities like marginal distributions from model outputs. "estimated via Monte-Carlo sampling over LLM outputs."
- MTQE: Machine Translation Quality Estimation; estimating translation quality without reference translations. "MTQE aims to automatically evaluate the quality of system-generated translations without relying on reference translations."
- Numerical bias: Systematic overuse of certain numeric tokens/values leading to skewed score distributions. "evaluator LLMs exhibit numerical bias, a phenomenon where certain evaluation scores are generated disproportionately often, leading reduced evaluation performance."
- Pearson's correlation coefficient (r): A statistic measuring linear correlation between two variables (here, model and human scores). "by measuring Pearson's correlation coefficient between human scores and the model's scores."
- Perplexity: A language modeling metric reflecting how well a model predicts text; lower values indicate higher fluency/likelihood. "Except for Gemma, perplexity negatively correlates with the mode ratio, suggesting that more fluent sentences (lower perplexity) exhibit stronger numerical bias via frequent value repetition."
- Preference tuning: Optimizing an LLM to align with human preferences, often via pairwise feedback or RLHF-like methods. "Given that most evaluator LLMs are aligned through instruction tuning and preference tuning, and that prior research suggests alignment reduces output diversity, we hypothesize that numerical bias arises from alignment."
- ROUGE: An automatic evaluation metric (commonly for summarization) based on n-gram overlap with references. "Traditional automatic evaluation metrics, such as BLEU \cite{papineni-etal-2002-bleu} and ROUGE \cite{lin-2004-rouge}, assess quality based on overlap with reference texts."
- Score range adjustment: Changing the allowable score interval in prompts to influence output distributions and mitigate bias. "Adjusting the score range in the prompt mitigates numerical bias and improves evaluation accuracy."
- Softmax function: A normalization function that converts logits into a probability distribution over tokens. "It scales the logits before applying softmax function, influencing the probability distribution of the next token selection."
- Temperature scaling: Modifying the sampling temperature to control output diversity and reduce over-concentration. "We also explore mitigation strategies for post-alignment LLMs, including temperature scaling, distribution calibration, and score range adjustment."
Practical Applications
Immediate Applications
The following actionable use cases can be implemented today to improve the reliability and performance of LLM-as-a-judge systems by managing alignment-induced numerical bias.
- Bias-aware evaluator selection for LLM-as-a-judge pipelines (software, localization, research)
- Use kurtosis of score distributions (and mode ratio where available) as a proxy metric to pick evaluator models with lower numerical bias, even without gold labels.
- Tools/products/workflows: “Evaluator Selector” script that computes kurtosis per model/language and routes to the least biased model; add to CI for evaluation pipelines.
- Assumptions/dependencies: Access to candidate evaluator models and batched scoring; sufficient sample size for stable kurtosis estimates; identical prompts across models.
- Score range tuning as a first-class hyperparameter (MTQE, GECQE, LCP; localization; education tech)
- Treat the output score range (e.g., 1–5, 0–9, 1–100) as a tunable parameter in prompts to mitigate bias and improve correlation with human judgments.
- Tools/products/workflows: “ScoreRangeTuner” that grid-searches ranges per model/language/task on validation data and sets prompt defaults accordingly.
- Assumptions/dependencies: Ability to edit prompts; small validation set or reliance on kurtosis when gold scores are unavailable; consistent post-processing (clipping/averaging).
- Temperature scaling and generative calibration modules (software, evaluation ops)
- Implement temperature sweeps (e.g., 0.4, 0.7, 1.0, 1.3) and sampling-based calibration (estimate p(y) via sampling, fit q(y) as Beta) to reduce over-concentration on specific scores.
- Tools/products/workflows: A “Calibration Plug-in” with Monte Carlo sampling and Beta-fit weighting for numeric outputs; toggleable per model/task.
- Assumptions/dependencies: Ability to sample multiple outputs per item (time/cost trade-off); calibration can reduce bias but may not always improve accuracy.
- Per-language evaluator routing and configuration (localization, multilingual products)
- Configure different evaluators and settings per language pair, as alignment-induced bias varies (stronger for high-resource languages); adjust range/temperature accordingly.
- Tools/products/workflows: Routing tables mapping language→(model, score range, temperature); language-aware prompt templates.
- Assumptions/dependencies: Language metadata; monitoring to keep routes current as models evolve.
- Instance-level triage using mode ratio (content moderation, MTQE/GECQE operations)
- For each item, generate multiple scores; if many samples collapse to the dataset’s mode (high mode ratio), flag for human review or re-score with higher temperature/different range.
- Tools/products/workflows: “Bias Sentinel” that computes mode ratio per item and triggers fallback.
- Assumptions/dependencies: Multiple generations per item; clear escalation paths to human reviewers.
- Evaluation monitoring and governance dashboards (LLMOps, MLOps, compliance)
- Track kurtosis, dispersion, and (where available) correlation to gold, by model, task, and language; alert when bias crosses thresholds; version all evaluator settings (prompt, range, temperature).
- Tools/products/workflows: Dashboards in MLflow/LangSmith/Weights & Biases; scheduled reports; automatic change logs.
- Assumptions/dependencies: Centralized logging; stable metrics definitions; SLAs for bias thresholds.
- Robust reporting for research and vendor management (academia, procurement, internal policy)
- Require reporting of evaluator parameters (range, temperature), score distributions, kurtosis, and language-specific results in papers and vendor deliverables.
- Tools/products/workflows: Evaluation protocol templates; “Evaluator Report Card” including distribution plots and kurtosis.
- Assumptions/dependencies: Agreement from collaborators/vendors; minimal scripting to export metrics.
- Safer scoring in education products (education, daily life)
- For automated essay/translation feedback, prefer calibrated ranges (or categorical bands) and per-task tuning to avoid over-clustered scores that mislead learners; disclose evaluator uncertainty.
- Tools/products/workflows: “Learning Feedback Settings” that select range and temperature per assignment type; confidence indicators based on dispersion.
- Assumptions/dependencies: Institutional approval; alignment with grading policies; transparent communication to users.
- Human-in-the-loop routing for safety-critical content (healthcare documentation QA, finance compliance summaries)
- For biased evaluator outputs (high kurtosis/mode ratio), default to human auditing rather than automated acceptance.
- Tools/products/workflows: Threshold-based triage queues for clinical note quality checks or regulatory summaries.
- Assumptions/dependencies: Access to trained reviewers; data handling compliant with privacy/security constraints.
- Reproducible evaluation setups (academia, benchmarking)
- Fix and disclose temperature, sampling count, clipping rules, and score ranges to ensure comparability; incorporate bias diagnostics (kurtosis) alongside correlations.
- Tools/products/workflows: Evaluation config files and seeds; shared scripts for computing kurtosis and scatter plots.
- Assumptions/dependencies: Community adoption of reporting norms; availability of compute to replicate sampling-based steps.
Long-Term Applications
The following use cases require method development, scaling, or standardization beyond current heuristics.
- Alignment-time debiasing for numeric outputs (model providers, foundational model R&D)
- Incorporate objectives that preserve numeric token diversity during instruction/preference tuning (e.g., entropy regularization on numeric tokens, label-shift penalties).
- Tools/products/workflows: Modified RLHF/DPO curricula; diversity-aware reward models.
- Assumptions/dependencies: Access to alignment pipelines and data; ability to evaluate trade-offs with helpfulness/safety.
- Learned score-range optimizers (software tooling, AutoML for evaluation)
- Train meta-models to predict optimal score ranges per model/task/language using features like language/resource level, historical kurtosis, and validation metrics.
- Tools/products/workflows: “AutoRange” service that cold-starts with priors and adapts online.
- Assumptions/dependencies: Historical logs; sufficient variation across tasks to generalize; safe online experimentation.
- Bias-robust decoding for evaluators (software, inference research)
- Develop decoding strategies that explicitly prevent numeric mode collapse (e.g., constrained sampling over numeric spans, anti-concentration penalties).
- Tools/products/workflows: Custom decoders integrated in serving stacks.
- Assumptions/dependencies: Low-latency inference implementations; empirical validation across tasks.
- Certified multi-judge ensembles (policy, high-stakes industry)
- Use ensembles of evaluators with complementary bias profiles; aggregate via methods that penalize over-concentrated scores; certify ensembles with bias and reliability guarantees.
- Tools/products/workflows: “Judge Ensemble” orchestrators; conformity metrics; calibration across judges.
- Assumptions/dependencies: Cost budgets for multiple evaluators; governance to maintain ensemble diversity.
- Standards for evaluator bias reporting and audits (policy, standards bodies, procurement)
- Establish requirements to disclose score distributions, kurtosis, language-wise performance, and mitigation steps when LLM-as-a-judge is used in procurement and certifications.
- Tools/products/workflows: Audit checklists; ISO-like profiles for evaluator reporting.
- Assumptions/dependencies: Regulator and industry buy-in; harmonization with existing AI risk management frameworks.
- Extension beyond numeric scoring to rankings and natural-language judgments (academia, evaluation ecosystem)
- Investigate alignment-induced biases in pairwise ranking and rationale generation; create benchmarks and mitigation methods that generalize beyond numeric outputs.
- Tools/products/workflows: New datasets with human distributions for ranking/rationales; debiasing methods for non-numeric outputs.
- Assumptions/dependencies: Data collection costs; human annotation protocols.
- Language equity initiatives (localization, NGOs, public sector)
- Build datasets and mitigation strategies that target low-resource languages, measuring how alignment affects bias differently and improving evaluator reliability globally.
- Tools/products/workflows: Multilingual bias leaderboards; per-language alignment adjustments.
- Assumptions/dependencies: Community partnerships; ethical data sourcing.
- Abstention and fallback policies for evaluators (healthcare, finance, legal)
- Design evaluators that can self-assess bias (e.g., via mode ratio/kurtosis predictors) and abstain or escalate in high-risk contexts.
- Tools/products/workflows: “Evaluator Guardrails” that trigger human review or alternate evaluators.
- Assumptions/dependencies: Well-defined escalation pathways; liability frameworks for abstention.
- JudgeOps platforms (LLMOps SaaS)
- End-to-end platforms to manage evaluator selection, tuning (range/temperature), calibration, monitoring, and governance, with language-aware routing and compliance-grade reporting.
- Tools/products/workflows: Turnkey “JudgeOps” offering; APIs for integration with A/B testing and CI pipelines.
- Assumptions/dependencies: Customer data connectors; integrations with existing MLOps stacks.
- Training and certification programs for evaluator engineering (education, professional development)
- Develop curricula and certifications on LLM-as-a-judge pitfalls, bias diagnostics, and mitigation playbooks for practitioners and auditors.
- Tools/products/workflows: Courses, hands-on labs, capstone audits.
- Assumptions/dependencies: Institutional partnerships; evolving best practices.
- Regret-aware deployment policies for consumer apps (daily life, consumer tech)
- For writing assistants and review analyzers, implement policies that monitor over-concentration in user-facing scores and switch to qualitative feedback when bias spikes.
- Tools/products/workflows: UX patterns for uncertainty-aware feedback; dynamic switching between numeric and categorical outputs.
- Assumptions/dependencies: Telemetry in consumer apps; user consent and transparency.
- Research on causal drivers of alignment-induced numerical bias (academia, model labs)
- Systematically vary alignment data and methods to isolate causes (e.g., instruction styles, reward models) and design principled debiasing interventions.
- Tools/products/workflows: Controlled ablation studies; open benchmarks for numeric-bias stress tests.
- Assumptions/dependencies: Access to alignment pipelines; compute budgets; community collaboration.
Collections
Sign up for free to add this paper to one or more collections.