- The paper proposes DeepEra, a logic-aware evidence reranker that overcomes semantically similar but irrelevant contexts (SSLI) in scientific QA.
- It employs a three-stage process—intention recognition, LLM-based relevance assessment, and evidence filtering—to ensure data-driven answer grounding.
- DeepEra shows significant gains with a HitRate@1 of 66.6 and reduced inference time, demonstrating enhanced retrieval robustness and answer quality.
DeepEra: Robust Evidence Reranking for Scientific Retrieval-Augmented QA
The exponential growth of scientific literature has necessitated reliable question answering (QA) systems that integrate current knowledge with deep reasoning capabilities. Retrieval-Augmented Generation (RAG) frameworks, which combine neural retrievers with LLMs, have become foundational for scientific QA. However, these frameworks remain significantly vulnerable to semantically similar but logically irrelevant contexts (SSLI), which degrade factuality and propagate hallucinations in generated answers. Prior rerankers—whether dense, sparse, or LLM-based—primarily rely on surface-level semantic similarity, insufficient for ensuring evidence grounding in scientific tasks.
SSLI: Limitations of Current Retrieval and Reranking Paradigms
Current embedding-based retrieval models, such as Qwen3-Embedding-8B, BGE-M3, E5-Mistral-7B-Instruct, and GTE-Large-v1.5, fail to discriminate logical relevance when faced with contextually similar distractors, as empirically validated through substantial drops in both the Noise Robustness Score and Context Discrimination Rate. These models retrieve passages whose semantic resemblance to the query does not equate to actual evidentiary support, thereby amplifying the risk of erroneous generation.
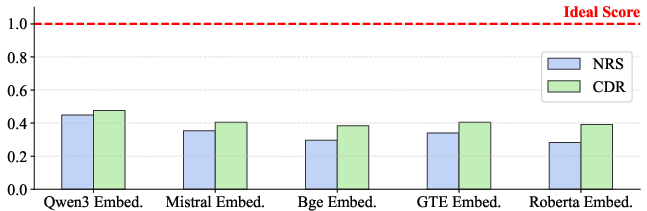
Figure 1: Embedding models exhibit significant vulnerability to SSLI distractors, underscoring their inability to robustly filter logically irrelevant contexts.
Dataset Construction: SciRAG-SSLI
To systematically evaluate logical robustness, the authors introduce SciRAG-SSLI—a 300K-instance benchmark derived from 10M scientific articles. The pipeline involves collecting abstracts, clustering them, extracting structured information (methods, results, significance), and generating QA pairs. For each question, LLM-guided prompts create SSLI contexts, producing semantically coherent but logically inconsistent distractors that challenge evidence discrimination.
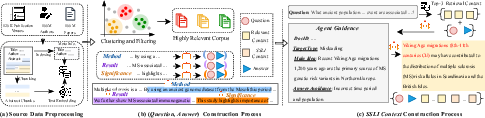
Figure 2: The multi-stage construction of SciRAG-SSLI ensures the injection of realistic, targeted SSLI distractors to reflect scientific QA requirements.
DeepEra Architecture
DeepEra is proposed as an agentic reranker designed to transcend surface-level similarity with explicit logical reasoning about evidence relevance. It operates in three sequential stages:
- Intention Recognition: An LLM parses each query into a structured representation: domain/topic, entity type, intent, and expected answer type, guiding downstream relevance assessment.
- LLM-Based Relevance Assessment: Candidate passages are scored against the structured query using strict criteria for mechanistic or causal relevance. Only passages offering direct, data-driven, or structural answers are prioritized.
- Evidence Filtering and Summarization: Passages crossing a relevance threshold are summarized for compactness and redundancy reduction, producing a concise, trustworthy set of contexts for answer generation.
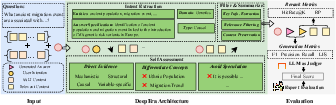
Figure 3: DeepEra's pipeline explicitly models user intent and evidence relevance to enhance reliability in scientific QA.
Quantitative Analysis: Comparative Evaluation
DeepEra achieves strong numerical gains versus prior rerankers across SSLI and Base modes:
- Retrieval Robustness: On the SSLI setting, DeepEra attains up to 8% relative improvement in HitRate@1 and RP, outperforming strong baselines (e.g., BGE, Jina) and maintaining superior ability to rank gold contexts despite distractor noise (HitRate@1 of 66.6, RP of 71.96).
- Answer Generation Quality: F1, precision, and LLM-derived Logic Fidelity Score substantiates DeepEra's ability to promote both completeness and logical correctness (e.g., F1 of 43.38, LFS of 3.94 for the hard SSLI subset).
Contextual Relevance Visualization
Visualization of context/question relevance pre- and post-reranking reveals DeepEra's capacity to filter misleading SSLI passages. Where baselines (e.g., MXBAI) misrank distractors, DeepEra persistently elevates correctly grounded evidence into the top ranks, minimizing propagation of noise.

Figure 4: DeepEra improves discrimination between relevant and SSLI distractor passages, sustaining robustness across diverse tasks.
Ablation and Parameterization
Ablation studies confirm the critical impact of evidence filtering (largest performance drop when omitted) and supporting roles of intention recognition and summarization. Parameter analysis of Top-K reranking indicates optimal QA performance at K=5 with evidence filtering, whereas increasing K further introduces detrimental redundancy.
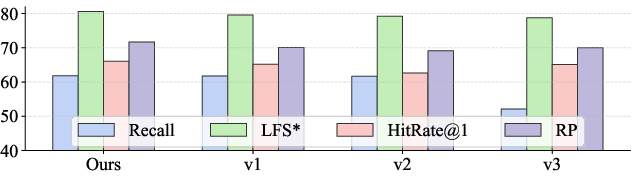
Figure 5: Evidence filtering is central to DeepEra's performance, as verified by ablation experiments.
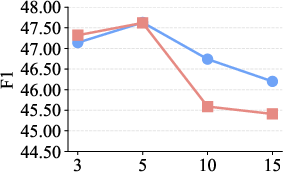
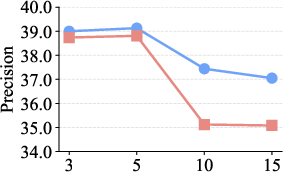
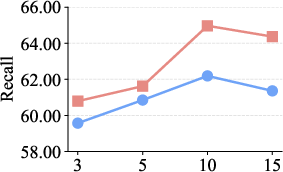
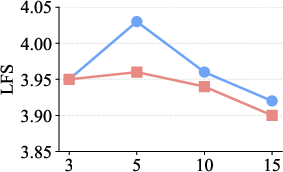
Figure 6: Top-K parameter optimization demonstrates superior metrics for DeepEra when evidence filtering and concise selection are enforced.
Efficiency
DeepEra outperforms competitive LLM-based rerankers (e.g., RankGPT) in inference speed, requiring only 7.9 seconds per query (vs. 30 seconds for RankGPT), demonstrating practical scalability for scientific information systems.
Theoretical and Practical Implications
DeepEra's integration of structured intent and logic-aware evidence evaluation fills the recognized gap in agentic RAG systems by enabling systematic, interpretable evidence selection. This advances scientific QA by:
- Ensuring downstream LLMs generate factually grounded and contextually relevant answers.
- Providing a reusable pipeline for building logically robust retrieval/QA systems across heterogeneous scientific domains.
- Setting a new standard for evaluation with SSLI-specific benchmarks, fostering research into logical grounding and adversarial robustness in retrieval-augmented models.
Future research directions include the extension of DeepEra to multi-modal scientific QA, incorporation of external tool invocation in the reranking flow, and the refinement of SSLI distractor generation for finer granularity in adversarial benchmarking.
Conclusion
DeepEra introduces reliable, logic-driven evidence reranking in scientific Retrieval-Augmented Generation, overcoming the limitations of semantic-only similarity measures endemic to current models. Through a modular agentic pipeline and a comprehensive SSLI benchmark, DeepEra substantiates robust improvements in both retrieval accuracy and answer generation fidelity, with clear implications for scalable, trustworthy scientific QA systems.