- The paper demonstrates that LLMs encode abstract structural information during training, with noticeable improvements in downstream performance around step 64k.
- It employs a controlled dataset of linguistic transformations and fine-tuning with LoRA adapters, revealing limitations in generating exact unseen sequences.
- Ablation studies highlight that MLP blocks contribute more significantly than attention mechanisms, underscoring their role in syntactic transformation success.
This essay provides a detailed summary of the paper titled "On the Emergence and Test-Time Use of Structural Information in LLMs" (2601.17869). The paper investigates the mechanisms through which LLMs learn and utilize structural information, focusing on abstract structures derived from linguistic transformations within a controlled synthetic dataset.
Introduction: The Role of Structural Learning
The paper aligns with the notion that structural information underpins responsive, adaptive systems, a concept echoed by \cite{guo2025physics}. Within LLMs, understanding how abstract structures are learned and applied at test time is crucial for advancing their capacity to generate new knowledge not present in their training data. The authors design an experiment with custom linguistic structures based on Transformational Grammar (TG), exploring if and how LLMs can comprehend and compose structural information. TG, as proposed by \cite{chomsky57syntactic}, serves as a synthetic framework to study this phenomenon.
Dataset Design
The authors introduce a natural language dataset centered around linguistic structural transformations, facilitating controlled evaluations of the emergence of structural information during training. The dataset features ten distinct transformation types such as passivization, raising, and question formation. These transformations are grouped into five broader syntactic categories, enabling precise monitoring of learning progression and structural composition (Table \ref{tab:transformations}). The dataset was compiled using DeepSeek-V3, incorporating varied vocabulary for enhanced generalization \cite{deepseekai2025deepseekv3technicalreport}.
Experiments and Results
Emergence of Structures
This section examines how and when grammatical structures are encoded within LM sentence representations.
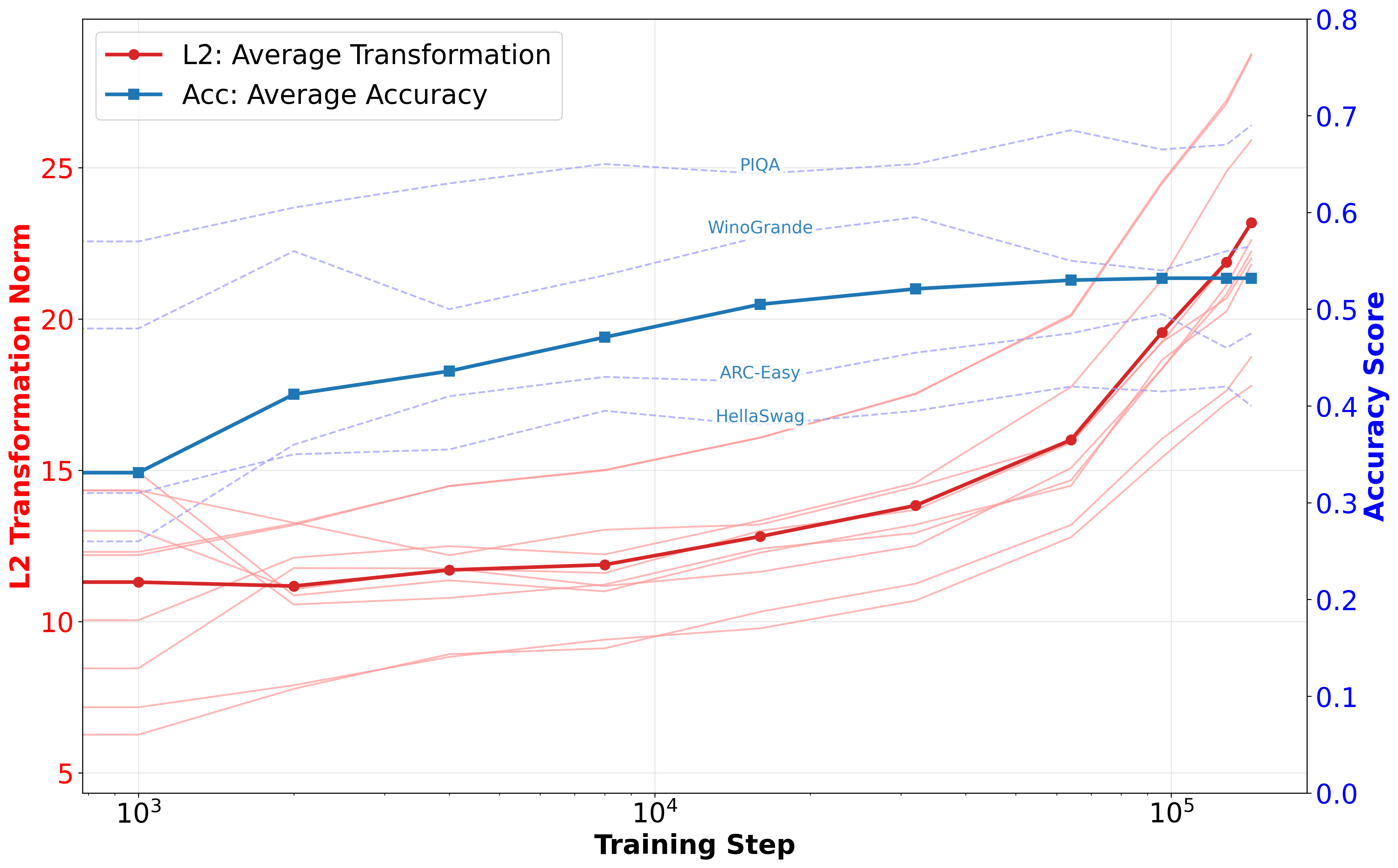
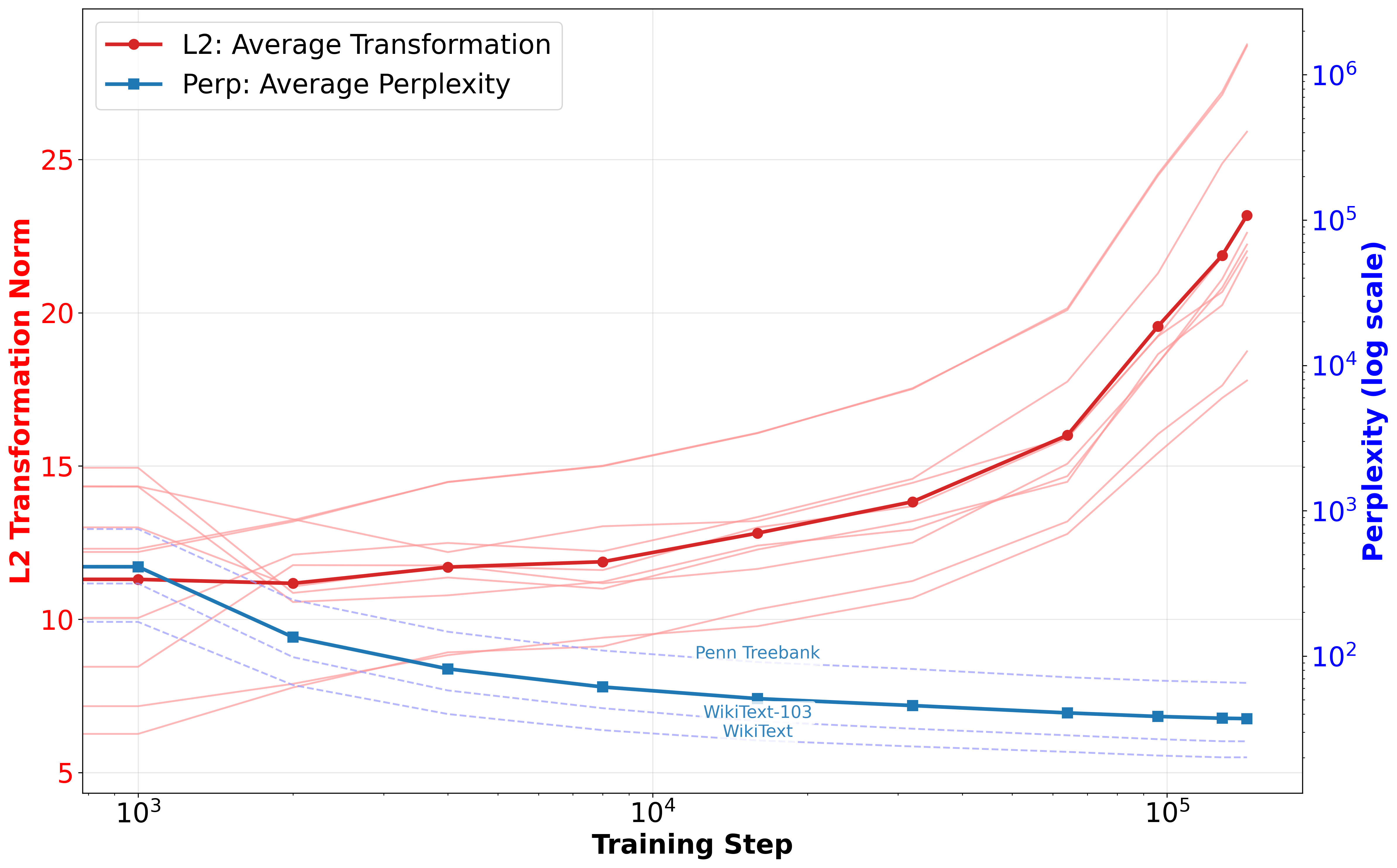
Figure 1: L2 transformation norms and performance of Pythia-410M during training.
The analysis computes an ℓ2 distance metric to track changes in sentence representations post-transformation. This metric facilitates clustering through techniques like K-means and visualizations via PCA and t-SNE, revealing distinct patterns as training progresses. Structural sensitivity becomes pronounced at approximately step 64k, corresponding with improved downstream task accuracy and reduced perplexity (Figure 1). These findings indicate that structural information may be crucial for complex reasoning tasks, potentially marking a phase transition to enhanced linguistic competence.
Structural Compositional Generalization
Here, the focus shifts to evaluating the model's ability to generate multiple-step transformations after fine-tuning with LLaMA3-8B models employing LoRA adapters \cite{hu2022lora}. Despite full parameter fine-tuning leading to overfitting, LoRA-based approaches demonstrated improved partial match accuracy during nested transformations, although exact sequence generation remains limited. This suggests the necessity of explicit intermediate steps for effective compositional generalization.
Evaluation of out-of-distribution (OOD) tasks further highlights the generalization gap across transformation complexities and sequences (Table \ref{tab:finetuning_comparison}). These observations correlate with \cite{ontanon2022making} regarding challenges in model generalization and emphasize the potential for incremental improvements through enhanced intermediate representations.
Ablation Studies on Attention Heads and MLPs
Ablation studies leveraging causal intervention highlight the contribution of network components, particularly emphasizing MLP blocks over attention mechanisms, with MLPs accounting for a greater proportion of syntactic transformation success.
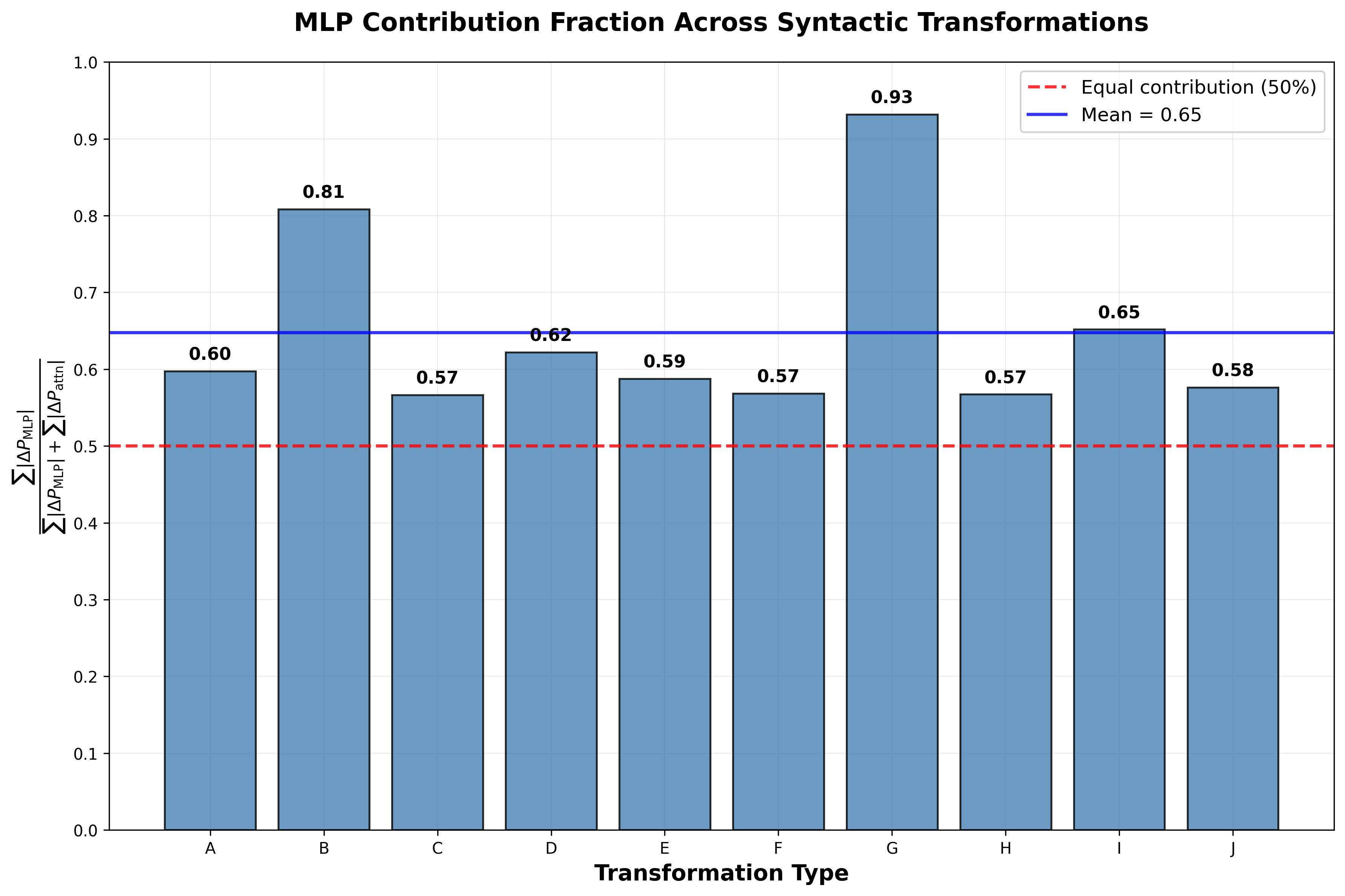
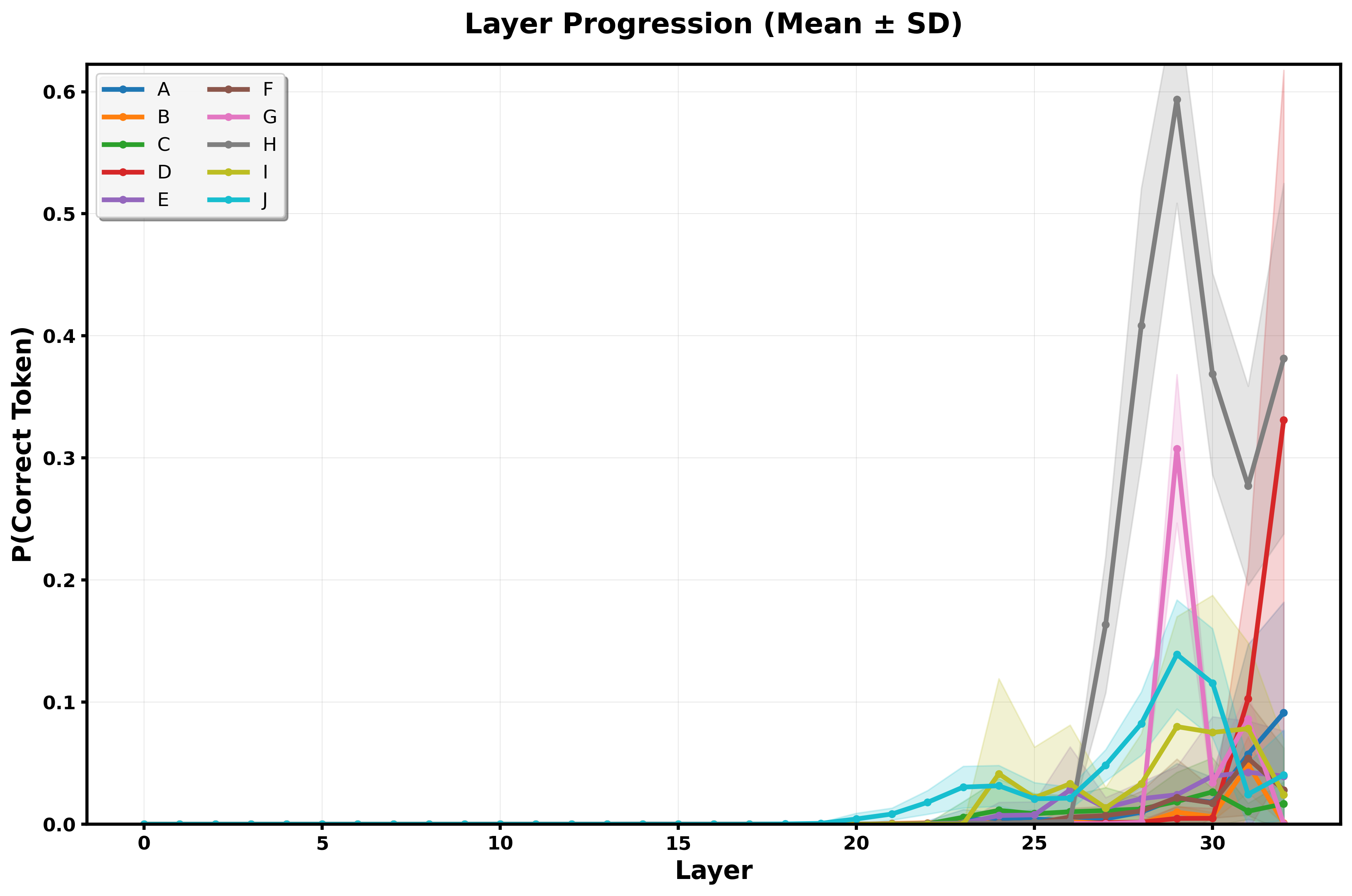
Figure 2: Relative ablation effect of MLP and attention components.
Layer-wise analysis reveals a concentration of contribution in later network stages, specifically layers 24-32, in predicting correct syntactic tokens. Probes constructed using Linear Discriminant Analysis (LDA) further depict distinct separation between transformation types, aligning with the linear representation hypothesis \cite{park2024lrh}.
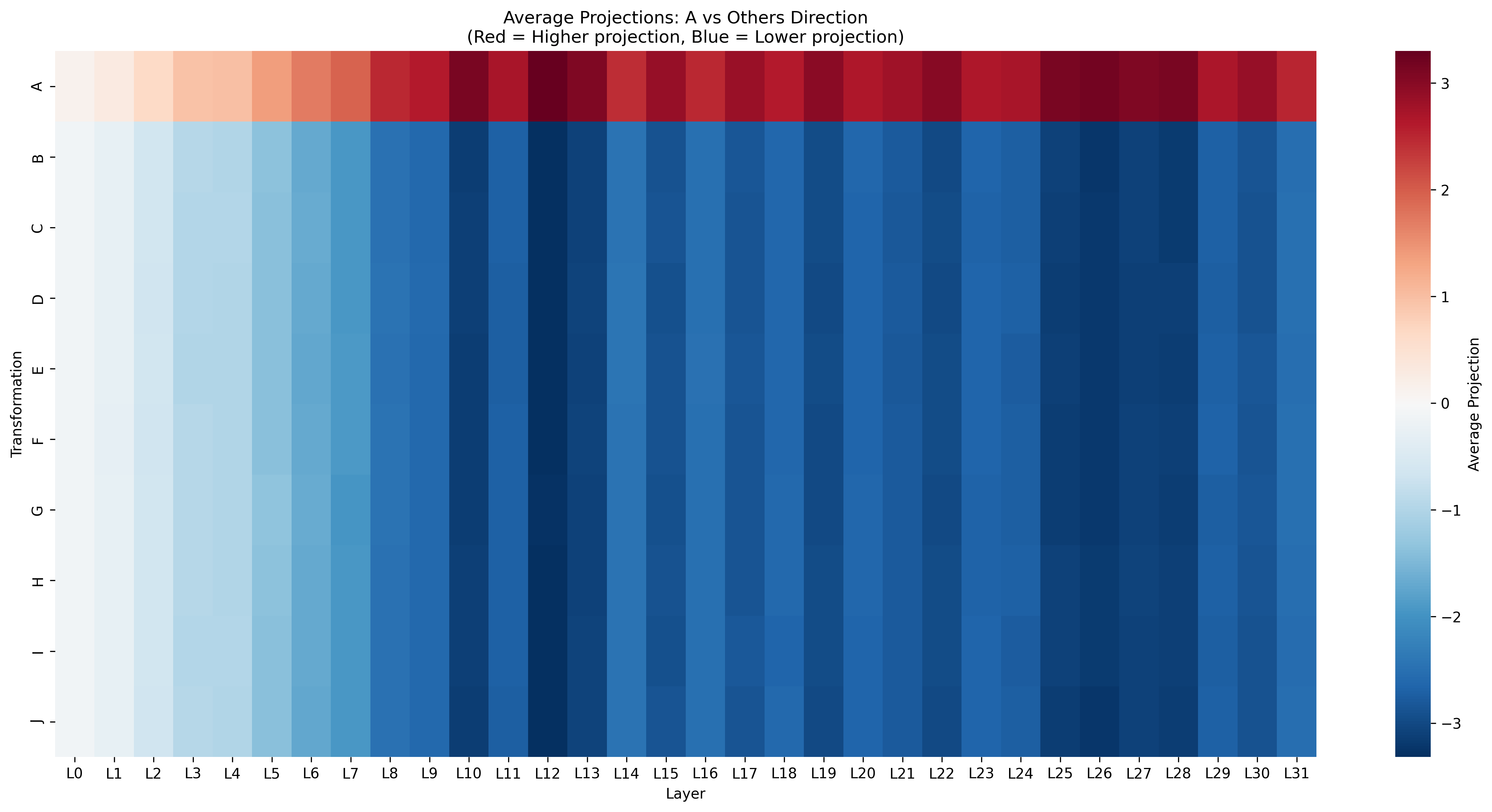
Figure 3: Heatmap of transformation projections showcasing representation quality across layers.
Conclusion
The paper elucidates how LLMs manifest sensitivity to syntactic transformations during training and explore their ability for compositional synthesis at test time. Although improvement is seen through LoRA fine-tuning, current architectures under scrutiny remain restricted in generating unseen transformation sequences without explicit intermediate guidance. Future considerations include larger model capacities and finer-grained operation decomposition for enhanced generalizability.
The findings necessitate persistent research in mechanistic interpretability and causality to deepen understanding and applications of LLMs in generating novel knowledge. Challenges remain in achieving transformation consistency across languages and scaling effectively for larger semantic tasks.