The Molecular Structure of Thought: Mapping the Topology of Long Chain-of-Thought Reasoning
Abstract: LLMs often fail to learn effective long chain-of-thought (Long CoT) reasoning from human or non-Long-CoT LLMs imitation. To understand this, we propose that effective and learnable Long CoT trajectories feature stable molecular-like structures in unified view, which are formed by three interaction types: Deep-Reasoning (covalent-like), Self-Reflection (hydrogen-bond-like), and Self-Exploration (van der Waals-like). Analysis of distilled trajectories reveals these structures emerge from Long CoT fine-tuning, not keyword imitation. We introduce Effective Semantic Isomers and show that only bonds promoting fast entropy convergence support stable Long CoT learning, while structural competition impairs training. Drawing on these findings, we present Mole-Syn, a distribution-transfer-graph method that guides synthesis of effective Long CoT structures, boosting performance and RL stability across benchmarks.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies how LLMs learn to think through long, multi-step problems (called Long Chain-of-Thought, or Long CoT). The authors suggest that good long reasoning isn’t just a long list of steps. Instead, it has a “molecular” structure made of three kinds of connections between steps. Using this idea, they design a method (Mole-Syn) to help smaller or cheaper models learn stable long reasoning more effectively.
Key Questions
- Why do LLMs struggle to learn long, step-by-step reasoning from human examples or weak models?
- What makes some long reasoning traces easy for LLMs to learn and others hard?
- Can we transfer the “structure” of good reasoning to cheaper models without copying every word?
How They Studied It (Methods)
The authors look at many reasoning traces (the step-by-step thoughts) from strong “teacher” models and compare them to traces from weaker models or human-written solutions. They label each step-to-step link in a solution by the behavior it expresses and study the overall pattern of these behaviors across many tasks.
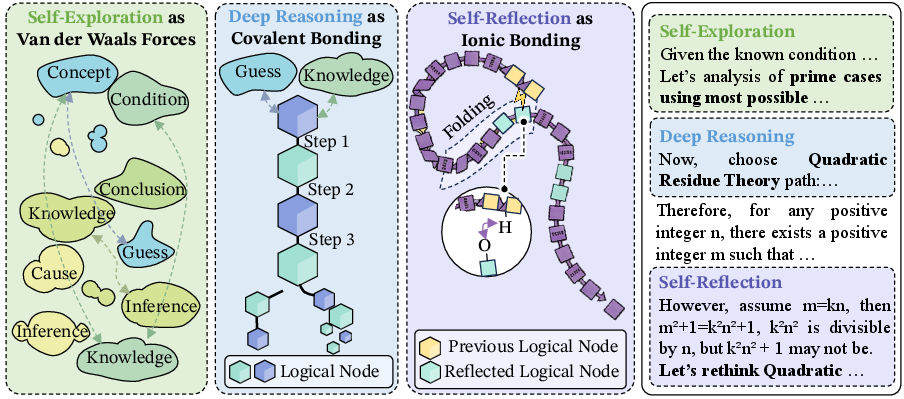
They focus on three key behaviors, explained with a friendly chemistry analogy:
- Deep-Reasoning (like covalent bonds): tightly connected, logical steps that build the main backbone of an argument.
- Self-Reflection (like hydrogen bonds): later steps that loop back to check, correct, or confirm earlier steps, keeping the whole chain stable.
- Self-Exploration (like van der Waals forces): gentle, try-and-see moves that explore new ideas or directions without committing too soon.
What they actually do:
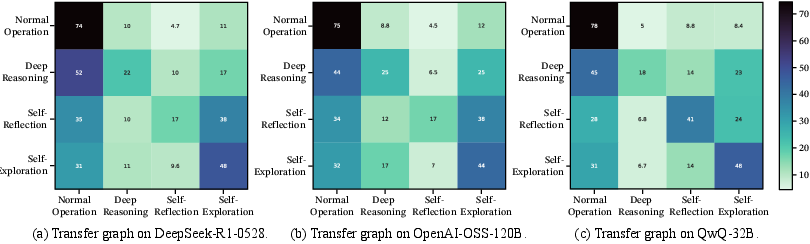
- Measure how often each behavior shows up and in what order across many problems (a “behavior transition” map).
- Test if different strong models produce similar behavior maps (they do).
- Check whether models learn the structure behind these behaviors or just copy keywords like “Wait,” “But,” or “Maybe” (they learn the structure).
- Visualize reasoning paths in a “semantic space” to see how steps cluster and “fold” back during reflection.
- Study mixing different structures and see if it helps or harms learning.
- Build Mole-Syn, which takes the behavior map from strong models and uses it to guide instruction models to generate similar structures from scratch.
A helpful analogy: Think of a solution as a “molecule” of thought. The “atoms” are ideas, and the “bonds” are the reasoning behaviors that connect those ideas. Good molecules (solutions) have the right mix and arrangement of bonds so the whole structure is strong and stable.
Main Findings
Here are the key results, explained simply:
- Strong teachers are necessary for long reasoning. Distilling (learning from) strong reasoning models works well. Distilling from weak instruction models or even from many human-written steps usually doesn’t teach stable long reasoning.
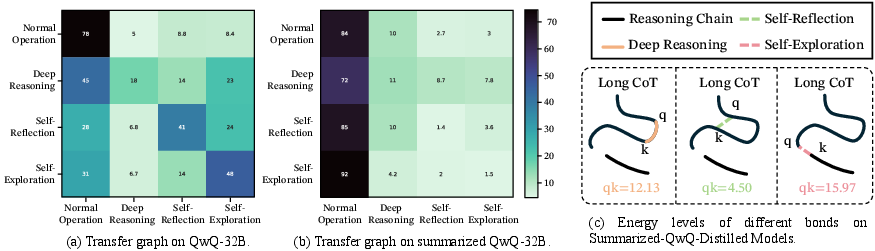
- The “molecular” structure is real and consistent. Different strong models tend to use very similar mixes and sequences of the three bonds (Deep-Reasoning, Self-Reflection, Self-Exploration). This stable pattern shows up across tasks and models.
- Models learn structure, not just words. Even if you remove or change the keywords (“Wait,” “But,” etc.), models can still learn long reasoning as long as the underlying behaviors (the bond patterns) are there. Keywords can speed things up but aren’t the essence.
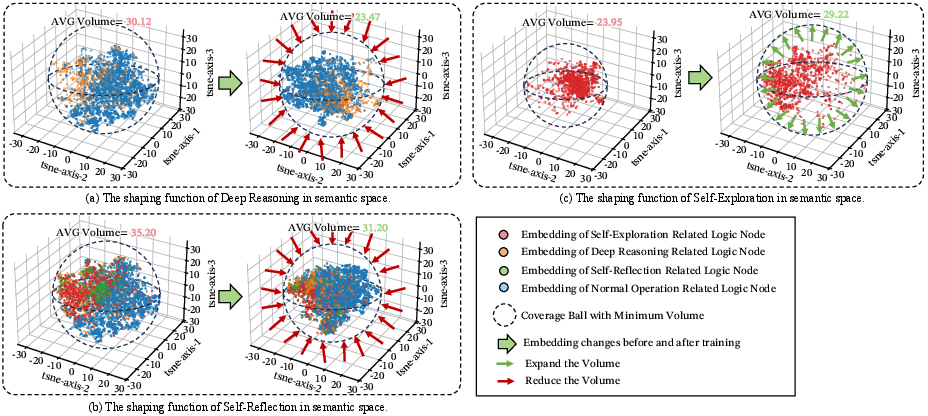
- Reasoning “folds” like a protein. In a visual semantic space:
- Deep-Reasoning bonds make tight local clusters (build the backbone).
- Self-Reflection bonds fold the chain back to earlier points (check and fix).
- Self-Exploration bonds link distant clusters softly (probe new ideas).
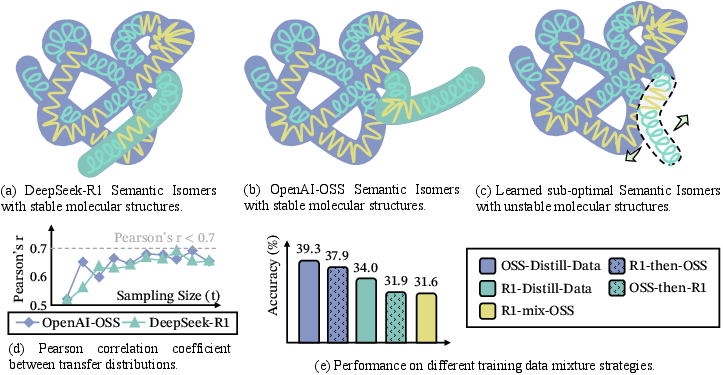
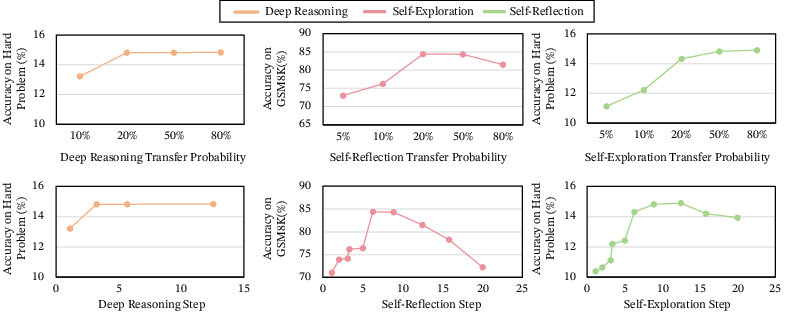
- Not all structures are equally learnable. The authors introduce “semantic isomers”: two reasoning traces that use the same ideas but connect them with different behavior mixes. Some isomers help models “settle” quickly from uncertainty to a clear answer; others slow or destabilize learning. Small structural differences can cause big performance changes.
- Mixing two stable but different structures can cause chaos. Training on two incompatible “molecules of thought” at the same time can break coherence and hurt accuracy, even if both are good on their own.
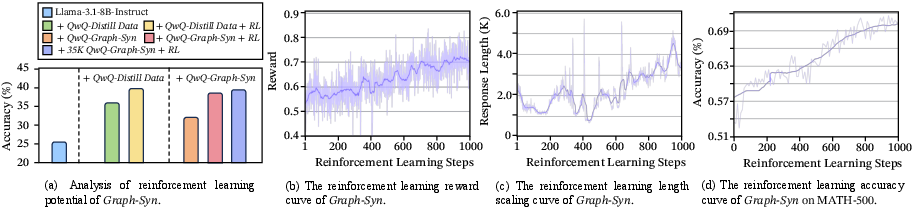
- Mole-Syn works. Instead of copying full teacher solutions, Mole-Syn transfers the behavior map (how often and when to use each bond) and uses it to guide instruction models to synthesize good long reasoning from scratch. This gets close to distillation results and makes later reinforcement learning (RL) more stable and effective.
- Summarizing or compressing thoughts can block imitation. Shortening or summarizing the teacher’s thought process disrupts the bond distribution. That makes it harder for others to copy the internal structure, which helps protect private models from being cloned.
Why These Results Matter
- For training: Focus on the structure of reasoning (the mix and order of behaviors), not just the words or format. Good long reasoning emerges from the right pattern of deep steps, checks, and exploration.
- For building cheaper models: You don’t always need full teacher solutions. You can transfer the “behavior map” and synthesize your own long reasoning paths with Mole-Syn, saving cost and improving stability.
- For safety and IP protection: Compressing or summarizing chain-of-thought can prevent others from recreating the internal reasoning structure, helping protect proprietary models.
- For better AI thinking: The three bonds play different roles:
- Deep-Reasoning builds the backbone.
- Self-Reflection stabilizes and corrects.
- Self-Exploration expands possibilities.
- Balancing them helps models move from “confused” to “confident” efficiently.
Final Takeaway
Long, reliable reasoning in LLMs isn’t about writing more steps—it’s about arranging the right kinds of steps in the right way. Treating reasoning like a molecule—with deep backbone bonds, reflective stabilizers, and gentle exploratory links—explains why some training data works and some doesn’t. Using this insight, Mole-Syn transfers the structure of good reasoning to new models, improving performance and making training more stable, while also revealing simple ways to prevent unwanted copying of a model’s internal thinking patterns.
Knowledge Gaps
Below is a single, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address.
- Behavior taxonomy is inconsistent: the paper alternates between three bonds (Deep-Reasoning, Self-Reflection, Self-Exploration) and “four behaviors” in Mole-Syn; precise definitions, boundaries, and their inclusion/exclusion (e.g., “Normal Operation”) need to be formalized and standardized for annotation and analysis.
- Automatic behavior labeling lacks validation: the paper relies on auto-labeled datasets without reporting precision/recall, inter-annotator agreement, robustness to domain shifts, or calibration against human labels; a thorough labeling audit is missing.
- Causal claims versus correlation: improvements are attributed to bond distributions based on high Pearson correlations, but there is no causal test via controlled interventions (e.g., targeted suppression/augmentation of specific bonds, attention head ablations, or constrained decoding that enforces behavior transitions).
- Attention-as-energy mapping is under-justified: the Boltzmann analogy (E ↔ −q·k) is asserted without formal derivations or tests across layers/heads; missing perturbation studies to demonstrate that modulating “energy” changes behavior probabilities as predicted.
- Embedding topology evidence is fragile: reliance on t-SNE projections for “logical folding” is known to distort geometry; the analysis lacks robust, model-agnostic topology (e.g., UMAP stability, geodesic metrics, persistent homology) and cross-embedding replication.
- Entropy convergence is under-specified: definitions of “entropy” (token-level, step-level, distributional over behaviors) and its measurement pipeline are unclear; thresholds for “fast convergence” and its relation to task success/generalization are not formalized.
- Semantic isomer divergence metrics are undefined: the paper references closeness in (P, π) under a “suitable divergence” without specifying the metric, thresholds for compatibility, or a reproducible procedure to estimate and compare isomers.
- Compatibility criteria for mixing teacher structures are missing: while mixing near-correlated isomers can degrade performance, there is no algorithmic method to detect incompatibility, align distributions, or safely blend structures; thresholds that predict chaos are not identified.
- Transfer-graph sample complexity lacks theory: stability claims (≥2000 samples → r > 0.9) are empirical and task/model-specific; formal sample complexity bounds, confidence intervals, and sensitivity to teacher model selection are absent.
- Mole-Syn pipeline details are incomplete: the construction of the behavior transition graph (data sources, smoothing/regularization, handling of rare transitions), and how random walks avoid degenerate/invalid trajectories need specification.
- Quality assurance of synthesized trajectories is unclear: the paper does not detail how correctness of final answers is enforced, how erroneous reasoning traces are filtered, or whether verifiers/checkers are integrated in Mole-Syn generation.
- RL evaluation lacks transparency: missing RL algorithm details (e.g., PPO/GRPO settings), training budgets, seeds, variance across runs, and statistical significance; no analysis of sample efficiency or sensitivity to reward shaping and decoding strategies.
- Narrow evaluation scope: benchmarks are math-centric; there is no assessment on diverse tasks (commonsense, coding, scientific reasoning, planning), multilingual settings, or multimodal reasoning—limiting claims of generality.
- Limited model coverage: tests focus on a small set of backbones (e.g., Llama-3.1-8B, Qwen2.5-32B); scaling laws across sizes/architectures (70B+, mixture-of-experts, transformer variants) and open/closed models remain unexplored.
- Human-trace experiments are underpowered: the number, diversity, and quality controls of human rationales (and their structural distributions) are not reported; reasons for failure (e.g., structural mismatch vs. annotation style) are unresolved.
- ICL distillation setup lacks generality: demonstration selection criteria for achieving high distributional correlation are not formalized; reproducibility across instruction models, tasks, and prompt formats remains uncertain.
- “Normal Operation” role is unclear: mentioned as “stable local bonds,” but its quantitative contribution, prevalence, and interaction with the three major bonds in structure learning are not analyzed.
- Defense via summarization is not quantified: no systematic trade-off curve between token compression and distillation resistance; minimum compression thresholds and generalization across teacher types (R1/QwQ/OSS/Gemini/Claude) are not established.
- Reproducibility and data transparency gaps: full datasets, code, behavior labeling pipelines, and transition graphs are not made available; without them, independent verification of structural metrics and Mole-Syn is difficult.
- Safety and reliability are unassessed: Mole-Syn may synthesize plausible but incorrect long traces; there is no measurement of hallucination rates, error propagation, or fail-safe mechanisms (e.g., verifiers, self-correction loops).
- Interpretability link to network components is thin: sparse auto-encoder features are reported, but there is no mapping from behaviors to specific attention heads/MLP neurons and no interventions showing behavior control via component-level edits.
- Decoding dependence is ignored: analyses fix temperature (T=0.6), but do not examine how behavior distributions and entropy dynamics vary with decoding parameters (temperature/top-p/beam), length penalties, or step tokens.
- Markovian transition assumption untested: the behavior transition graph implies a (near) time-homogeneous Markov process; long-range dependencies and higher-order effects are not modeled or evaluated.
- Tool-use and external feedback are excluded: how calculators, retrieval, or verifier agents alter bond distributions and “molecular” structure is not studied; integration pathways to augment Mole-Syn with tools remain open.
- Efficiency comparisons are missing: the cost-benefit of Mole-Syn versus direct distillation (compute, time, data size) is not quantified; ablations on dataset size (e.g., 5k/10k/40k) and diminishing returns are not provided.
- Failure modes lack granularity: the paper reports aggregate performance drops when mixing isomers or compressing traces but does not provide task-level case studies diagnosing where and why structures fail.
- Ethical/legal aspects of distillation are unexamined: while defenses are discussed, the paper does not address consent, licensing, or compliance when estimating behavior graphs from proprietary models’ outputs.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s findings on Long CoT “molecular” structure (deep-reasoning, self-reflection, self-exploration bonds), semantic isomers, and the Mole-Syn synthesis method.
- Industry (Software/AI/LLMOps): Structure-aware Long CoT data synthesis
- What: Use Mole-Syn to generate training datasets that match a target behavior-transition graph (distribution over deep-reasoning, reflection, exploration) without copying teacher text. Integrate into SFT and RL pipelines to improve stability and performance.
- Tools/products/workflows:
- Mole-Syn library/API for dataset generation from behavior-transition graphs
- “Structure-first” distillation pipelines that learn a transition graph, then synthesize trajectories via instruction LLMs
- Assumptions/dependencies: Requires accurate behavior labeling and a reliable estimate of the target transition graph (≥2k samples recommended for stability); validated primarily on math/reasoning domains; long context windows and compute budgets needed.
- Industry (LLMOps/Model Training): CoT Structure Profiler for data/model audits
- What: Profile datasets and models by estimating behavior marginals and transition matrices; measure Pearson correlations between sources to predict merge risks; monitor “attention-energy” signatures per bond type.
- Tools/products/workflows:
- CoT Structure Profiler (bond distribution dashboard, compatibility score, attention-energy histograms)
- Training-gate rule: only merge datasets with structure correlation above a threshold and no known structural conflicts
- Assumptions/dependencies: Requires behavior annotators (automatic or manual) and reliable structure metrics; correlation alone may be insufficient—conflict tests are recommended.
- Industry (RLHF/RLAIF): Stable RL bootstrapping with Mole-Syn initialization
- What: Initialize RL models with Mole-Syn SFT weights to reduce instability and enable steadier, longer-horizon improvements.
- Tools/products/workflows:
- RL initialization recipe: pretrain on Mole-Syn data → reward modeling → RL fine-tuning
- Assumptions/dependencies: RL benefits shown in reasoning tasks; reward models must not fight the learned structure (monitor entropy convergence dynamics).
- Industry (Prompting/ProdOps): ICL demonstration selection by structure matching
- What: For instruction LLMs, choose few-shot demonstrations whose behavior-transition distributions match the target use case; avoid random ICL that misaligns structure.
- Tools/products/workflows:
- Demo Selector that scores candidates by transition-graph similarity and selects a compatible “semantic isomer”
- Assumptions/dependencies: Requires a reference transition profile; effect size depends on model capacity and task.
- Industry (Product/Safety): Bond-aware agent frameworks
- What: Implement agent loops that explicitly schedule exploration → deep reasoning → reflection cycles; enforce reflection to “fold back” before finalization.
- Tools/products/workflows:
- Reflection Manager module that checks long-range consistency before emitting final answers
- Exploration budget controller tuned to avoid fragmentation
- Assumptions/dependencies: Needs behavior detectors to trigger the right phase; tuning task-dependent.
- Industry (IP Protection): Structure-preserving redaction via controlled summarization/compression
- What: Reduce the risk of unauthorized distillation by summarizing or compressing rationales to disrupt bond distributions while preserving user-facing quality.
- Tools/products/workflows:
- Reasoning Structure Firewall that perturbs/removes structural cues in disclosed traces
- Release policies that cap rationale length and reflective content
- Assumptions/dependencies: Must balance utility and protection; too much compression can degrade product quality.
- Academia (ML Research): Benchmarks and metrics for structural reasoning
- What: Publish datasets with behavior labels; evaluate models via structure metrics (transition graphs, entropy convergence profiles) alongside accuracy.
- Tools/products/workflows:
- Open-source annotators for behavior tagging
- Structure-based generalization tests (isomer swaps, conflict-fusion experiments)
- Assumptions/dependencies: Labeling noise must be quantified; cross-domain validity yet to be established.
- Academia/Education: Structure-informed curriculum for reasoning models and learners
- What: Design training/teaching sequences that alternate exploration and reflection and densify deep reasoning at the right pace.
- Tools/products/workflows:
- “Molecular” syllabus (explore → backbone → reflect) for AI tutors and student-facing problem sets
- Assumptions/dependencies: Human learning parallels are plausible but not causally established; requires classroom validation.
- Safety/Policy: Model cards with structural disclosures
- What: Include high-level Long CoT structure stats (bond ratios, transition heatmaps, entropy-convergence patterns) in model cards to aid procurement, risk assessment, and interoperability.
- Tools/products/workflows:
- Structure Disclosure Template and minimum reporting standards
- Assumptions/dependencies: Providers must be willing to disclose aggregate statistics; no standardized thresholds yet.
- Healthcare/Finance (Decision Support): Reflection-gated outputs for safety-critical steps
- What: Require explicit reflection bonds (consistency checks) before final recommendations; audit logs show folding back to earlier premises.
- Tools/products/workflows:
- Reflection Gate that blocks finalization until reflection criteria are met
- “Folding map” visualization for compliance review
- Assumptions/dependencies: Domain adaptation needed; requires data governance to log and review intermediate reasoning responsibly.
- Robotics/Planning/Operations: Long-horizon planners with bond schedules
- What: Plan-generation systems that interleave low-commitment exploration with periodic reflection to stabilize plans and prevent drift.
- Tools/products/workflows:
- Planner controllers with tunable exploration/reflect cycles
- Assumptions/dependencies: Needs integration with non-language planners and environment feedback loops.
Long-Term Applications
These opportunities will likely require additional research, scaling, or standardization before broad deployment.
- Industry Standards: Structure Compatibility Index and merge protocols
- What: Define a sector-wide index for “isomer compatibility” to decide whether datasets/models can be safely merged without inducing structural chaos.
- Tools/products/workflows:
- Standards body specifications; certification tests for dataset/model compatibility
- Assumptions/dependencies: Agreement on metrics; cross-domain validation; incentives for adoption.
- Foundation Model Training: Structure-aware pretraining objectives
- What: Pretrain models to internalize target bond distributions (e.g., alternation patterns, entropy-convergence profiles) rather than only token statistics.
- Tools/products/workflows:
- Pretraining losses that reward desired transition graphs and metacognitive oscillation profiles
- Assumptions/dependencies: Requires scalable self-supervision signals; risk of overfitting to specific structures.
- Cross-Domain Isomer Libraries and Switchers
- What: Maintain libraries of domain-specific structure profiles (e.g., clinical reasoning vs. legal analysis) and dynamically switch or blend compatible isomers at runtime.
- Tools/products/workflows:
- Isomer Router that detects task/domain and selects a compatible structure profile
- Assumptions/dependencies: Robust domain detectors; methods to avoid structural conflicts when blending.
- Explainability Dashboards: “Molecular map” visual analytics for end-users
- What: Visualize reasoning as folded trajectories in semantic space; show where reflection bonded back and where exploration bridged clusters.
- Tools/products/workflows:
- 3D folding viewers; bond-energy/attention overlays; entropy timelines
- Assumptions/dependencies: Reliable low-dimensional embeddings and behavior tagging; human factors research for usability.
- Policy/Governance: Structure-based IP and provenance frameworks
- What: Use structural similarity (not text match) to assess unlawful distillation or trade-secret misappropriation; set disclosure norms balancing safety and IP.
- Tools/products/workflows:
- Forensic tools to compare transition graphs between models
- Assumptions/dependencies: Legal acceptance of structural metrics as evidence; false positive/negative rates must be characterized.
- Education at Scale: AI tutors that teach “folding” as a meta-skill
- What: Tutors that cultivate balanced exploration and reflection in students; assess a learner’s bond profile and adapt instruction.
- Tools/products/workflows:
- Learner Structure Profiler; adaptive curricula that shape student reasoning bonds
- Assumptions/dependencies: Longitudinal studies needed to demonstrate transfer to human outcomes.
- Multi-Agent Systems: Structure-matched collaboration
- What: Compose teams of agents whose reasoning structures are compatible (minimizing interference) and complementary (coverage vs. stability).
- Tools/products/workflows:
- Team formation algorithms that optimize structural compatibility scores
- Assumptions/dependencies: Robust measures of inter-agent structural interference; task-specific tuning.
- Data Governance & Watermarking: Structure watermarks and drift detection
- What: Embed subtle, benign alterations to bond distributions as provenance signals; detect unauthorized cloning via structure drift.
- Tools/products/workflows:
- Structure Watermarker; Drift Detector for public outputs and third-party models
- Assumptions/dependencies: Watermarks must be hard to remove and not harm quality; detection must scale.
- Safety-First Controllers: Entropy-convergence regulators
- What: Controllers that monitor metacognitive oscillation and enforce convergence before high-stakes actions; suspend outputs if convergence patterns are anomalous.
- Tools/products/workflows:
- Entropy/Information-flow monitors with policy hooks
- Assumptions/dependencies: Reliable online estimation; calibrated thresholds per domain.
- Cross-Modal Planning (Robotics/Autonomy): Bond-aware long-horizon planning
- What: Extend structure patterns (explore→reason→reflect) to multi-modal planners (language+vision+control) for robust long missions.
- Tools/products/workflows:
- Cross-modal behavior detectors; reflection checkpoints aligned with environment telemetry
- Assumptions/dependencies: Requires stable alignment across modalities; expensive evaluation in the real world.
Notes on Feasibility and Dependencies (Global)
- Behavior labeling quality is critical; automated taggers introduce noise—human-in-the-loop verification may be required for high-stakes use.
- Current evidence is strongest in math/logic benchmarks; transferring to domains like medicine, law, or software engineering needs careful validation and possibly domain-specific isomer profiles.
- Structural similarity (correlation > 0.9) does not guarantee compatibility; conflict testing should precede dataset/model merging.
- Long-context capability and compute budgets are practical constraints; performance and RL stability gains assume adequate sequence length.
- IP-protection via summarization depends on preserving user utility while sufficiently perturbing structure; tuning and red-teaming are necessary.
Glossary
- Abductive and inductive moves: Heuristic reasoning strategies that propose plausible hypotheses (abduction) and generalize from observations (induction). "it supports abductive and inductive moves by enabling low-commitment associations in semantic space"
- Allotropic variants: Alternative structural configurations of the same underlying elements, here referring to different but effective distributions of reasoning behaviors. "multiple effective “allotropic” variants of reasoning keys can exist."
- Behavior-directed graph: A graph where edges are annotated with behavior types to model transitions in reasoning steps. "We formalize a Long CoT trace as a behavior-directed graph "
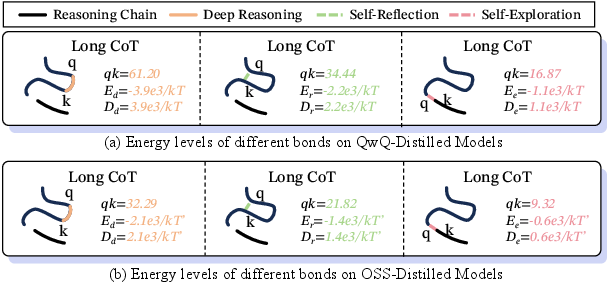
- Boltzmann distribution: A probability distribution over states based on their energy, common in statistical physics and used here by analogy. "In physical chemistry, the behavior probability with energy level at temperature follows the Boltzmann distribution:"
- Chain-of-Thought (CoT): Explicit step-by-step rationales produced by LLMs to solve problems. "explicit chain-of-thought (CoT) rationales"
- Cold-start: The challenge of initializing a model to perform a new capability without extensive prior specialized training data. "they struggle to cold-start from instruction-tuned or base models into Long CoT models requiring extended multi-step reasoning"
- Cross-coder sparse auto-encoder: A sparse autoencoder trained across hidden states from two models to identify shared latent features. "we train a cross-coder sparse auto-encoder that jointly models hidden states from the base model and the Think-SFT model"
- Covalent bonds: Strong, stabilizing connections used as an analogy for tightly coupled deductive steps. "Deep reasoning forms the bone of the thought process, analogous to covalent bonds defining a molecule's primary chain."
- Deep Reasoning: Strong, logically dependent inference that builds and maintains the core reasoning backbone. "Deep reasoning forms the bone of the thought process, analogous to covalent bonds defining a molecule's primary chain."
- Distillation: Training a student model to imitate outputs or behaviors of a teacher model. "Only distillation from strong reasoning LLMs works."
- Distribution-transfer graph: A graph-based representation used to transfer behavior distributions from a teacher to a student model. "we present Mole-Syn, a distribution-transfer-graph method that guides synthesis of effective Long CoT structures"
- Entropy convergence: The rapid reduction of uncertainty during reasoning, leading to stable solutions. "only bonds promoting fast entropy convergence support stable Long CoT learning"
- Folding funnel: A conceptual landscape in protein folding (used by analogy) depicting descent toward a low-energy native state. "LLM searches for an optimal semantic configuration parallels a protein’s descent along a folding funnel toward a low-energy native state"
- Gibbs–Boltzmann distribution: The exponential family distribution relating energy to probability, applied to attention weights by reparameterization. "attention weights form a Gibbs–Boltzmann distribution over negative logits."
- Hydrogen Bonding: Stabilizing, long-range corrective links used as an analogy for self-reflection across distant reasoning steps. "Self-Reflection drives strong folding to previous steps by Hydrogen Bonding."
- Hydrophobic core: The stabilizing central region in folded proteins (used by analogy) representing consolidated, consistent logic. "it consolidates the hydrophobic core and suppresses inconsistent branches"
- In-context learning (ICL): Learning to perform tasks by conditioning on examples in the prompt without parameter updates. "we investigate three data sources: distillation from strong reasoning LLMs, distillation from weak instruction LLMs with in-context learning (ICL), and fine-tuning on human reasoning traces."
- Logical folding: The non-linear reorganization of reasoning steps into a stable topology via reflective links. "Verification of the “logical folding” structure on embeddings from Qwen2.5-32B-Instruct"
- Long-horizon reasoning: Reasoning over extended sequences of steps with stability across distant dependencies. "examine how their global molecular-like structure ensures long-horizon reasoning stability."
- Macromolecular structure: A large-scale, multi-bond organization used as an analogy for global reasoning topology. "forming a stable macromolecular structure with mutually supportive components from a global perspective."
- Marginal distribution: The distribution over behavior types irrespective of transitions, estimated from a corpus. "and the marginal distribution $\pi_{\mathcal{C}(b)$."
- Metacognitive oscillation: Alternation between exploratory and convergent reasoning phases during problem solving. "We identify the core rationale for this difference as a "metacognitive oscillation" in LLMs."
- Mole-Syn: A synthesis framework that transfers behavior-transition structures to instruction models without copying surface text. "we propose a synthetic framework, Mole-Syn, that views targeted reasoning traces as macromolecular structures"
- Negative logits: The negated pre-softmax scores used to interpret attention as a Boltzmann-like distribution over states. "attention weights form a Gibbs–Boltzmann distribution over negative logits."
- Pearson correlation coefficient: A measure of linear correlation used to assess stability of transfer graphs across models and samples. "Pearson correlation coefficients across models are all greater than 0.9 (p<0.001)"
- Phase space: An abstract space where dynamics (e.g., information changes) are analyzed over trajectories. "we compared the reasoning dynamics of R1 models with human cognition in an information phase space"
- Random walk: A stochastic process over graph transitions used to synthesize reasoning trajectories. "This method is a random walk on a transition probability graph"
- Reinforcement learning (RL): Optimization via trial-and-error feedback to improve policies or behaviors over time. "We further evaluate Mole-Syn-initialized LLMs' potential in reinforcement learning (RL)."
- Semantic isomers: Distinct reasoning trajectories that solve the same task with similar semantics but different behavior distributions. "We introduce Effective Semantic Isomers"
- Sparse auto-encoder: An autoencoder with sparsity constraints that isolates interpretable latent features. "the sparse auto-encoder analysis shows that Long CoT behavior in the SFT model is concentrated"
- Supervised fine-tuning (SFT): Gradient-based training on labeled data to adapt pre-trained models to specific tasks. "the sparse auto-encoder analysis shows that Long CoT behavior in the SFT model is concentrated"
- t-SNE: A non-linear dimensionality reduction technique used to visualize high-dimensional embeddings. "t-SNE-based low-dimensional representations"
- Transfer graph: A graph summarizing behavior transitions learned across models, used to compare structural stability. "Transfer graph on three different models."
- Transition probability graph: A graph where edges encode probabilities of transitioning between reasoning behaviors. "a transition probability graph in Figure~\ref{fig:transfer} composed of 4 reasoning behaviors"
- Van der Waals Forces: Weak, transient interactions used as an analogy for low-commitment exploratory links between distant reasoning clusters. "Self-Exploration gently links different long-distance clusters by Van der Waals Forces."
Collections
Sign up for free to add this paper to one or more collections.