- The paper introduces an efficient method that distills chain-of-thought reasoning by pruning redundant steps in small language models.
- The paper employs a three-stage pipeline—response sampling, binary cutting search, and on-policy validation—to streamline reasoning.
- The paper demonstrates a 50-70% token reduction while maintaining competitive accuracy on benchmarks such as GSM8K, MATH, and AIME.
Efficient Long CoT Reasoning in Small LLMs
Recent developments in LLMs have advanced the ability to solve complex reasoning tasks using Chain-of-Thought (CoT) prompting techniques. However, large models that excel in reasoning often generate lengthy CoT traces that include redundant steps, posing challenges for small LLMs (SLMs) given their limited capacity. This paper presents a method for distilling efficient CoT reasoning into SLMs by strategically pruning these unnecessary steps and enhancing learning through on-policy validation.
Introduction to CoT Reasoning and its Challenges
Chain-of-Thought (CoT) prompting enhances reasoning capabilities by encouraging LLMs to think step-by-step. Large models like DeepSeek-R1 demonstrate that increasing the length of CoT prompts can improve problem-solving on complex tasks. As illustrated in the redundant reasoning generated by DeepSeek-R1 (Figure 1), long CoT traces introduce a computational burden, particularly for SLMs, which struggle with overthinking and often fail to generalize effectively due to their size.

Figure 1: Illustration of redundant reasoning to a simple question by DeepSeek-R1, showing unnecessary steps in the reasoning process.
Methodology: Streamlining CoT in Small LLMs
The paper proposes a three-stage method to streamline CoT reasoning for SLMs, consisting of Response Sampling, Binary Cutting Search, and On-policy Validation.
Response Sampling
Initially, original long CoT responses are sampled from large reasoning models, capturing both intermediate reasoning 'thinking' and their corresponding conclusions.
Binary Cutting Search
Binary cutting reduces the time complexity of searching valid CoT prefixes, ensuring the shortest reasoning segment capable of leading to a correct response. This approach uses a mid-point strategy to cut reasoning traces, minimizing computational burden while maintaining logical coherence.
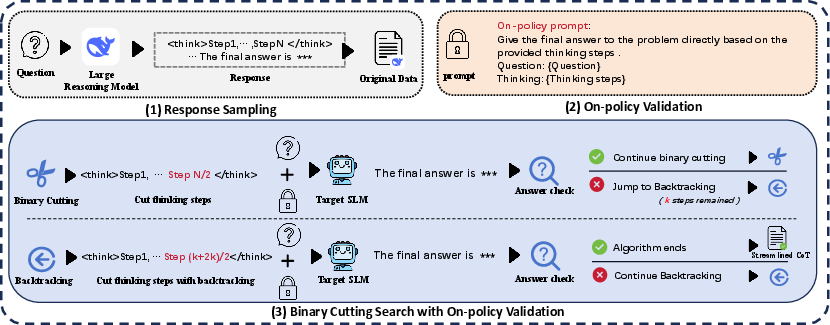
Figure 2: Overview of the proposed streamlining method, highlighting the stages of sampling, validation, and binary cutting.
On-Policy Validation
Instead of relying on external validation, the target SLM itself evaluates whether truncated CoT segments are sufficient for a correct final answer, thereby tailoring the distilled reasoning steps to the SLM's inherent capabilities.
Application of Streamlined CoT to Fine-tuning SLMs
Upon obtaining distilled reasoning data, fine-tuning is conducted through Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO). SFT leverages concise reasoning steps to enhance the generation process, while DPO further refines the model's ability to discern between efficient and redundant reasoning paths.
Experimental Results
Testing across mathematical reasoning benchmarks, such as GSM8K, MATH, and AIME, demonstrates that our streamlined approach consistently preserves reasoning efficacy while significantly reducing the average number of reasoning tokens generated. For example, our method decreased token usage by 50-70%, depending on the task, while maintaining competitive accuracy compared to full-length CoT traces.
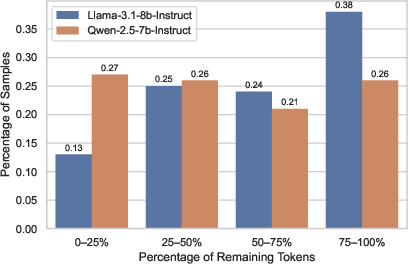
Figure 3: Distribution of remaining token ratios indicating successful reduction of redundant reasoning steps.
Case Study and Analysis
Case studies illustrate how binary cutting effectively removes redundancy while maintaining critical reasoning logic. The backtracking mechanism ensures recovery of necessary steps if overly pruned, providing a robust framework for adapting CoT traces to SLM constraints.

Figure 4: A case study showing step restoration during backtracking enhances reasoning coherence.
Conclusion
This method enhances the reasoning abilities of small models by distilling efficient long CoT data from large models, eliminating redundancies, and leveraging the target model's own inductive preferences. Such approaches offer promising pathways for efficiently integrating complex reasoning capabilities into SLMs, enabling them to perform comparably without requiring extensive computational resources. Future work may explore optimizing search algorithms and expanding applications to other model sizes and tasks.