Gained in Translation: Privileged Pairwise Judges Enhance Multilingual Reasoning
Abstract: When asked a question in a language less seen in its training data, current reasoning LLMs (RLMs) often exhibit dramatically lower performance than when asked the same question in English. In response, we introduce \texttt{SP3F} (Self-Play with Privileged Pairwise Feedback), a two-stage framework for enhancing multilingual reasoning without \textit{any} data in the target language(s). First, we supervise fine-tune (SFT) on translated versions of English question-answer pairs to raise base model correctness. Second, we perform RL with feedback from a pairwise judge in a self-play fashion, with the judge receiving the English reference response as \textit{privileged information}. Thus, even when none of the model's responses are completely correct, the privileged pairwise judge can still tell which response is better. End-to-end, \texttt{SP3F} greatly improves base model performance, even outperforming fully post-trained models on multiple math and non-math tasks with less than of the training data across the single-language, multilingual, and generalization to unseen language settings.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping AI LLMs think and solve problems well in many different languages, not just English. The authors introduce a training method called SP3F (Self-Play with Privileged Pairwise Feedback) that boosts reasoning skills in languages where there isn’t much training data (like Swahili or Bengali). The key trick: use English solutions as a “secret answer key” to guide a judge that compares the model’s responses in other languages, so the model gets useful feedback even when it’s not fully correct yet.
What questions does the paper ask?
- Why do AI models do much worse when you ask them questions in non-English languages?
- How can we teach an AI to reason well in those languages without collecting lots of new data in each language?
- Can a special “judge” that sees the English answer help train the model to reason better in other languages?
- Will this approach work across many languages, and even on languages the model wasn’t trained on?
How does the method work?
The training happens in two stages. Think of it like sports practice, then scrimmage games with a referee:
- Supervised practice (SFT):
- The model practices by reading problems and good solutions that were originally in English.
- These English problems and solutions are translated into the target languages (like Indonesian or Hindi) using a translator tool.
- The model learns to produce step-by-step reasoning in the target language by copying these translated “good examples.”
- Analogy: it’s like learning by studying worked examples in your native language, even if those examples came from an English textbook.
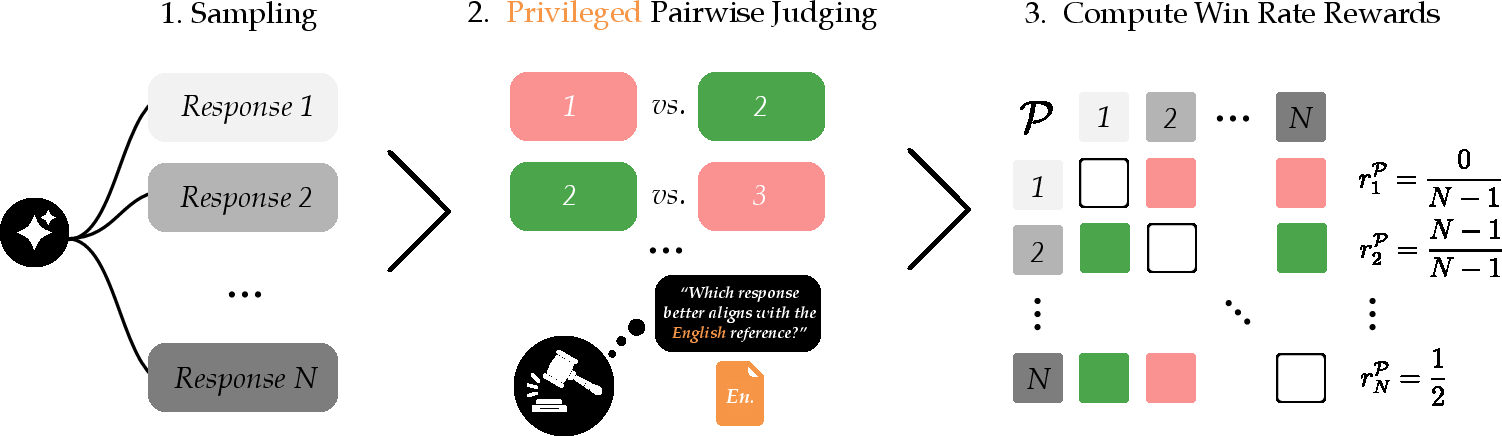
- Self-play with a privileged judge (RL):
- The model now generates several different answers to the same problem in the target language.
- A “judge” AI compares pairs of these answers and decides which one is better.
- The judge gets “privileged” information: it can see the original English reference solution (the answer key), even though the model cannot.
- Because the judge can compare each non-English answer to the trusted English solution, it can still pick the best attempt, even if none are perfect.
- The model earns reward points for:
- Getting the final answer right (accuracy),
- Using the expected format (like putting the final result in a box),
- Responding mostly in the target language (language fidelity),
- Winning more pairwise matchups (the judge prefers it more often than other samples).
- Analogy: the model plays mini-matches against its own answers. The referee has the answer key in English and awards points to the attempt that’s closest to correct. The model learns to make better attempts over time.
Two extra ideas make this robust:
- Pairwise comparisons and win-rate: instead of trying to assign a single “score” to each answer, the judge just decides which of two answers is better, many times. The model’s reward is how often its answer “wins.” This helps when judges are inconsistent.
- Privileged information: giving the judge the English answer improves judging quality, especially in lower-resource languages, and helps the judge recognize good reasoning steps even when the final answer is wrong.
What did they test, and what did they find?
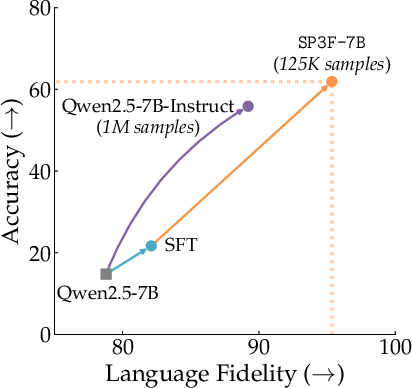
They trained a 7-billion-parameter model (SP3F-7B) using this method and compared it to a strong baseline model (Qwen2.5-7B-Instruct) that was trained on a much bigger dataset.
Tasks:
- In-domain math tasks (the training used math problems):
- MGSM: simple multilingual math word problems.
- MT-Math100: more demanding math, translated into multiple languages.
- Out-of-domain non-math tasks (to test generalization):
- Belebele: reading comprehension across many languages.
- Global MMLU Lite: general knowledge questions.
Key results (accuracy and answering in the right language):
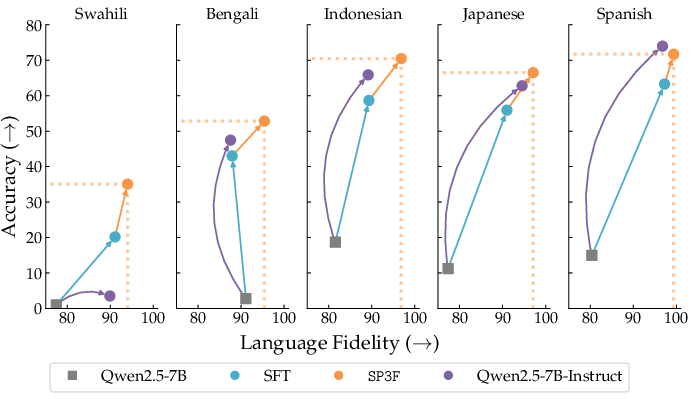
- SP3F-7B beat the baseline across math and non-math tasks in many languages.
- It did this with about 1/8 the amount of training data (about 125k examples vs. 1,000,000).
- Improvements were especially large in lower-resource languages (like Swahili, Bengali, Indonesian).
- It also generalized to languages it wasn’t trained on, improving average accuracy by about +18% on reading comprehension (Belebele) and +3.4% on math (MT-Math100) compared to the baseline.
Why these results matter:
- The privileged judge made better decisions and was more consistent.
- It helped the model improve its step-by-step thinking in the target language, not just the final answer.
- The method is data-efficient, since it relies on English solutions and machine translation rather than collecting new target-language datasets.
Why is this important?
- Fair access: AI that reasons well in many languages can help more people, especially those who don’t primarily use English.
- Data efficiency: You don’t need to gather tons of new data in every language; you can use English solutions and translation plus a smart judge.
- Better reasoning: The model gets guidance on its thinking steps, not just whether the final answer is right. This helps learning early on when the model often gets answers wrong.
- Robust judging: Pairwise comparisons and the English “answer key” make the judge more reliable, even across different languages.
What could this change in the future?
- Smarter multilingual helpers: AI assistants could become better at math, reading comprehension, and general knowledge in many languages, including those with less online data.
- Broader applications: The “privileged judge” idea could be used beyond languages—for example, in science or coding—where a trusted reference can help guide learning.
- More inclusive AI training: Since this method doesn’t depend on huge target-language datasets, it could quickly improve performance in new or underrepresented languages.
- Better generalization: Training with pairwise judges and verifiable rewards may build models that transfer their skills to new tasks and languages more reliably.
Overall, the paper shows a clever way to “borrow strength” from English solutions to teach AI models to reason well in other languages, efficiently and effectively.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, rendered as concrete items to guide future research.
- Data quality and translation fidelity:
- The SFT stage relies on machine-translated queries and responses (GPT‑5‑Nano) across 18 languages with no reported quality checks beyond a single Indonesian MGSM subset; quantify translation error rates and their impact on downstream training.
- Assess whether translation artifacts (idiom literalization, syntactic calques, tokenization issues in non-Latin scripts, RTL layout) bias learning, and develop robust preprocessing/filters.
- Evaluate how noisy or misaligned English reference responses (teacher errors or domain drift) propagate through privileged judging and RL.
- Judge reliability and biases:
- The privileged judge is GPT‑4o‑mini (closed model); measure judge accuracy/calibration per language and task, and compare against open judges to improve reproducibility.
- Beyond positional bias (mitigated by averaging), analyze and correct length bias, verbosity bias, and formatting bias in pairwise judgments.
- Provide formal quantification of how reductions in intransitivity (PNT metric) correlate with policy improvements; is reduced intransitivity necessary/sufficient?
- Establish statistical confidence in judge comparisons (e.g., bootstrap over pairwise outcomes) and link judge uncertainty to RL objective weighting.
- Investigate failure modes where “closest to English reference” pushes literal translation over correct reasoning or culturally appropriate expression in the target language.
- Reward design and generalization:
- The language fidelity reward uses a binary 70% threshold via lingua; test alternative detectors, thresholds, and code-switch-aware metrics, especially for morphologically rich and low-resource languages.
- The formatting reward (\boxed{}) is math-centric; define task-specific verifiable rewards for non-math tasks and measure sensitivity to formatting choices.
- Explore process-level/verifier rewards that grade intermediate CoT steps (e.g., step consistency checks) to reduce reliance on sparse end-answer rewards.
- Systematically ablate the weights among the four reward components (accuracy, formatting, language, judge win-rate) to understand trade-offs and avoid mode selection.
- Scope and evaluation coverage:
- Training data is math-heavy (DeepScaleR); quantify how SP3F scales to other reasoning domains (code, formal logic, scientific QA), and whether privileged judging remains beneficial.
- Out-of-domain performance shows mixed results relative to RLVR; identify causes (overfitting to math-style CoT? reward misalignment?) and test regularization strategies.
- Unseen language evaluation covers only eight languages and limited typological diversity; extend to scripts/languages not represented (e.g., Arabic, Thai, Khmer, Amharic, Burmese, Lao).
- Report confidence intervals/statistical significance for accuracy and language fidelity across tasks and languages to substantiate improvements.
- Computational efficiency and scalability:
- Pairwise judging incurs O(N2) comparisons per prompt (N=8 yields 28 pairs); profile end-to-end compute and propose scalable approximations (e.g., tournament brackets, subset sampling, learned Bradley–Terry models).
- Analyze sensitivity of results to N (number of samples per prompt), batch size, and training steps; provide guidance for compute-constrained settings.
- Compare overall training compute (SFT+RL+judging) against the baseline (1M example post-training) to validate the “1/8 data” claim in terms of actual FLOPs and wall-clock.
- Multilingual training strategy:
- The multilingual mixture is equal-proportion across 18 languages; study curriculum/weighting strategies (e.g., temperature sampling, resource-aware weighting) and their effect on low-resource gains and high-resource retention.
- Examine language interference and catastrophic forgetting (e.g., English and high-resource languages) after SP3F; report pre/post performance in English and other major languages.
- Test whether privileged information from languages other than English (e.g., high-resource hinge languages like Spanish, Mandarin) works equally well or reduces judge bias.
- Robustness and safety:
- Evaluate robustness to adversarial prompts (orthographic noise, mixed scripts, code-switching) and to domain shifts (colloquial vs. formal registers).
- Assess safety/cultural appropriateness in multilingual outputs and whether “closest to English reference” induces cultural bias or suppresses local varieties.
- Investigate reward hacking beyond language fidelity (e.g., short answers, boilerplate CoT) and introduce detectors/penalties.
- Methodological ablations and generality:
- Provide ablations on the necessity of SFT before RL (e.g., RL from base with privileged judge), and quantify cold-start dynamics at very low base accuracies.
- Test SP3F across different base models and sizes (e.g., Llama, Mistral, Gemma) to establish generality and identify architecture-specific interactions.
- Compare privileged pairwise judging to alternative supervision (e.g., reference-based edit distance on CoT, semantic alignment via embeddings, monolingual judges with translation adapters).
- Data leakage and licensing:
- Check for overlap between DeepScaleR training items and evaluation sets (MGSM, MT‑Math100, Belebele, Global MMLU Lite) to rule out leakage.
- Document licensing and translation provenance for the 18-language corpus and the new MGSM Indonesian set; ensure reproducibility of the exact data mixture.
- Theoretical grounding:
- Formalize the sample-complexity benefits claimed for privileged verifiers in the LLM setting (beyond footnote intuition) and derive conditions under which pairwise self-play with privileged info guarantees improvement.
- Model how translation errors and judge inconsistencies affect the learned policy (e.g., bounds under noisy rewards and intransitive preferences).
- Practical deployment considerations:
- Measure latency and cost of inference-time pairwise judging in real systems; propose amortization strategies (e.g., distilled judges, student reward models) without losing privileged benefits.
- Explore whether the trained models can serve as efficient self-judges in target languages after distillation from the privileged judge.
These items aim to pinpoint actionable directions to strengthen the method’s validity, scalability, and applicability across languages, domains, and real-world constraints.
Practical Applications
Immediate Applications
Below is a focused set of applications that can be deployed now or with modest engineering effort, leveraging SP3F’s two-stage training (SFT-on-translations + RL with verifiable rewards and privileged pairwise judges) and its demonstrated gains in multilingual reasoning, especially for lower-resource languages.
- Multilingual customer support copilots with improved reasoning
- Sectors: software, telecom, e-commerce, public services
- Tools/Products/Workflows: fine-tune existing assistants with SP3F; enforce “language fidelity” to ensure replies are in the customer’s language; inference-time pairwise judging to pick the best response; fallback to “translate-test” when needed.
- Assumptions/Dependencies: availability of English reference answers for common workflows; reliable translation to target languages; judge LLM and language classifier; compute for RL/self-play.
- Low-resource language math tutoring and homework help (Indonesian, Swahili, Bengali, etc.)
- Sectors: education
- Tools/Products/Workflows: deploy SP3F-trained math tutor that provides step-by-step CoT in the student’s language; use privileged judges to grade reasoning chains against canonical English solutions, even if the final answer is wrong.
- Assumptions/Dependencies: curated English canonical solutions; safety guardrails for pedagogy; domain verifiers for math (format/answer correctness).
- Translation QA and dataset curation using privileged pairwise judges
- Sectors: software localization, data operations, academia
- Tools/Products/Workflows: pairwise judge compares bilingual responses to English references to detect semantic drift; reduce intransitive/noisy judgments; batch-level win-rate scoring for quality assurance.
- Assumptions/Dependencies: English references of sufficient quality; judge access (e.g., GPT-4o-mini or equivalent); control for positional bias during judging.
- Multilingual FAQ and forms assistants for government and NGOs
- Sectors: policy, public sector, social services
- Tools/Products/Workflows: SP3F pipeline to fine-tune assistants on multilingual public information; language-fidelity reward to keep output in the target language; inference-time judge ranking to ensure coherent reasoning in local languages.
- Assumptions/Dependencies: English authoritative references for policies and procedures; translation coverage; funding/compute; compliance review.
- Cross-lingual compliance and policy checkers (assistive, not authoritative)
- Sectors: finance, insurance, HR/compliance
- Tools/Products/Workflows: assistants reason over multilingual documents and align to English policy references; pairwise judges prioritize outputs that adhere to the reference policy language.
- Assumptions/Dependencies: non-legal advisory positioning; domain-specific verifiable rewards (e.g., checklist completion); careful review to prevent overreliance on LLM judgments.
- Internal documentation and product localization with reasoning consistency
- Sectors: software, hardware manufacturing, consumer electronics
- Tools/Products/Workflows: SP3F-tuned models ensure localized instructions maintain logical steps (CoT) and correct outcomes; privileged judge detects reasoning mismatches vs English source.
- Assumptions/Dependencies: English source-of-truth; translation service; judge reliability; alignment review for safety-critical docs.
- Model evaluation harnesses using privileged pairwise judges
- Sectors: AI tooling, MLOps
- Tools/Products/Workflows: integrate privileged pairwise judges to build robust, transitivity-aware evaluation suites; use empirical win-rates as a training or gating signal for deployments.
- Assumptions/Dependencies: judge API and cost; mitigation of positional bias; tracking language fidelity thresholds and their impact on accuracy.
- Data-efficient multilingual post-training for enterprise LLMs
- Sectors: software/AI platforms
- Tools/Products/Workflows: adopt SP3F to reach strong multilingual reasoning with ~1/8 the data; reuse English references for SFT and RL; DR.GRPO-compatible self-play loops in Verl or similar frameworks.
- Assumptions/Dependencies: teacher model to produce English references; pipeline integration; compute budgets; licensing for base models and judges.
Long-Term Applications
These applications likely require further research, scaling, domain adaptation (especially verifiable rewards outside math), safety reviews, or ecosystem standardization before broad deployment.
- Equitable multilingual clinical reasoning and triage assistants
- Sectors: healthcare
- Tools/Products/Workflows: SP3F-like training with domain verifiers (medical factuality, guideline adherence) and privileged canonical pathways; pairwise judges reduce noisy judgments and cold-starts.
- Assumptions/Dependencies: stringent clinical validation; regulated deployment; robust domain verifiable rewards; data privacy; multilingual clinical corpora and references.
- Multilingual legal analysis and drafting support
- Sectors: legal, public policy
- Tools/Products/Workflows: privileged judges compare outputs to authoritative English legal templates; verifiable rewards adapted to legal correctness and citation integrity; cross-lingual consistency checks.
- Assumptions/Dependencies: domain-specific verifiers; oversight by professionals; risk management; quality bilingual references; jurisdictional nuances.
- Standardized “Privileged Judge” services and protocols
- Sectors: AI platforms, evaluation benchmarks
- Tools/Products/Workflows: hosted or on-device pairwise judge services; APIs for privileged judging; benchmarks that measure transitivity, language fidelity, and cold-start mitigation.
- Assumptions/Dependencies: cost-effective judge inference; improved non-transitivity handling; open standards; governance to avoid reward hacking.
- Comprehensive multilingual educational platforms (beyond math)
- Sectors: education
- Tools/Products/Workflows: science, history, and literacy tutors with domain-specific verifiers; privileged references from vetted curricula; longitudinal tracking of reasoning quality across languages.
- Assumptions/Dependencies: curriculum-aligned references; safety and bias audits; pedagogical research on CoT presentation.
- Multilingual scientific literature review assistants
- Sectors: academia, R&D
- Tools/Products/Workflows: privilege English abstracts or canonical reviews to evaluate foreign-language reasoning; pairwise judges for consistency and factual alignment; domain verifiers (claim verification).
- Assumptions/Dependencies: high-quality translations; citation-aware verifiable rewards; cross-lingual retrieval integration.
- Cross-border policy harmonization and regulatory assistants
- Sectors: government, international organizations
- Tools/Products/Workflows: privilege English treaty/regulatory references to align multilingual reasoning; pairwise judging to reduce intransitive preference pitfalls; transparent evaluation pipelines.
- Assumptions/Dependencies: authoritative references and multilingual legal corpora; stakeholder oversight; interpretability tooling.
- Enterprise-scale training cost reduction and continual multilingual expansion
- Sectors: software/AI platforms
- Tools/Products/Workflows: institutionalize SP3F to onboard new languages with minimal data; continual learning with English references; adaptive judges tuned per domain.
- Assumptions/Dependencies: translation systems for new languages; monitoring for language fidelity vs accuracy trade-offs; scalable RL infrastructure.
- Domain-specific verifiable rewards beyond math (code, structured data, business rules)
- Sectors: software engineering, analytics, operations
- Tools/Products/Workflows: verifiers for code correctness, schema constraints, KPI calculations; privileged references (canonical solutions/specifications) to strengthen judge reliability.
- Assumptions/Dependencies: robust, tamper-resistant verifiers; careful reward design to prevent gaming; dataset creation.
- Inference-time pairwise self-play selection with privileged references
- Sectors: AI application delivery
- Tools/Products/Workflows: sample N responses, use pairwise judges with references to select the best output per query; caching and budget-aware judging; dynamic language fidelity control.
- Assumptions/Dependencies: latency and cost tolerance; scalable judging microservices; privacy-sensitive handling of references.
- Privileged-judge paradigms for non-language domains (planning, robotics, CAD)
- Sectors: robotics, industrial design
- Tools/Products/Workflows: apply the principle of privileged pairwise judges (with ground-truth plans/specs) to supervise complex behaviors where scalar rewards are sparse or noisy.
- Assumptions/Dependencies: access to privileged data in simulations or specs; safe sim-to-real transfer; domain-aligned pairwise tasks; rigorous evaluation.
Notes on general assumptions and dependencies:
- English reference responses are pivotal; availability and quality determine downstream performance.
- Translation quality into target languages (and back) affects both SFT and judge reliability.
- Verifiable rewards must be adapted per domain; math-style correctness/formatting won’t generalize as-is.
- LLM-as-judge reliability, cost, positional bias, and intransitivity management are critical; privileged information helps but does not eliminate these challenges.
- Compute budgets and access to base models/judges (licensing) are practical constraints.
- Language fidelity thresholds can trade off against accuracy; careful tuning and guardrails are needed.
- Ethical, cultural, and regulatory considerations grow with deployment in sensitive sectors (healthcare, legal, public policy).
Glossary
- Batch-level judge feedback term: A component of the RL reward that aggregates pairwise comparisons within a batch to score responses. "with rewards given via a composition of four terms: three verifiable binary indicators, and one batch-level judge feedback term."
- Chain-of-thought (CoT): The step-by-step reasoning text produced by an LLM before the final answer. "data (e.g., chains of thought, CoTs) that is primarily in English"
- Cold start problem: Difficulty initiating effective learning when correct outputs are rare or training data is scarce. "Put together, we face a cold start problem we can't easily offline fine-tune our way out of."
- DR.GRPO: A variant of the GRPO reinforcement learning algorithm used for post-training LLMs. "We use the DR.GRPO \citep{liu2025understandingr1zeroliketrainingcritical} variant of GRPO \citep{shao2024deepseekmathpushinglimitsmathematical}."
- Empirical win rate: The fraction of pairwise comparisons a response wins against others, used as a reward signal. "assign each response a score equal to its empirical win rate."
- GRPO: A policy-gradient RL algorithm applied to LLM training. "We use the DR.GRPO \citep{liu2025understandingr1zeroliketrainingcritical} variant of GRPO \citep{shao2024deepseekmathpushinglimitsmathematical}."
- In-domain: Tasks aligned with the training domain of the model. "As seen in \autoref{tab:all_tasks}, SP3F-7B consistently out-performs Qwen2.5-7B-Instruct on both in-domain math tasks and out-of-domain not math tasks."
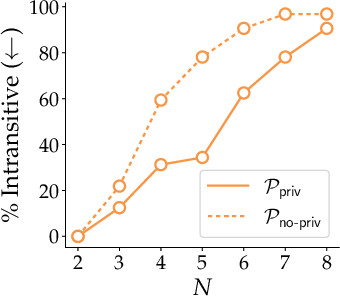
- Intransitive preferences: Cyclic judgments where A is preferred to B, B to C, and C to A, breaking consistent ranking. "LLMs often exhibit intransitive (i.e., cyclic) preferences where they might rank , , and "
- Language classifier: An automated tool to detect the language composition of generated text. "We use an automated language classifier to check what fraction of the response is in the target language."
- Language fidelity: The extent to which a model’s response is produced in the target language. "both in terms of accuracy and language fidelity (did the model answer in the target language?)."
- LLM judge: A LLM used to evaluate and compare generated responses, providing preference feedback. "we propose using an LLM judge for supervision on the CoT ."
- Mode selection: A tendency of RL training to overcommit to a narrow subset of behaviors or outputs. "these RL algorithms are particularly prone to mode selection \citep{shao2025spuriousrewardsrethinkingtraining, oertell2025heuristics}, underscoring the need for a preliminary SFT step."
- Multilingual training: Training across multiple languages to improve generalization and performance. "Finally, to take advantage of the repeatedly observed benefits of multilingual training \citep{yong2025crosslingualreasoningtesttimescaling,shi2022languagemodelsmultilingualchainofthought,muennighoff2023crosslingualgeneralizationmultitaskfinetuning}, we apply the above pipeline with data from 18 different languages (see \autoref{tab:language_list} for full list)."
- Next-token prediction loss: The standard likelihood objective for supervised fine-tuning in LLMs. "maximize likelihood via a standard next-token prediction loss:"
- On-policy: An RL training regime where updates are made using data generated by the current policy. "We opt for GRPO-style policy gradients in our work due to their relative simplicity and on-policy nature, which fits in cleanly to the self-play algorithmic template \citep{swamy2024minimaximalistapproachreinforcementlearning}."
- Online RL: Applying reinforcement learning during generation to improve the model’s policy through interaction. "aiding in downstream mode selection via online RL \cite{yue2025doesreinforcementlearningreally} in the next stage."
- Oracle: A reference evaluator used as an authoritative source for comparing models or responses. "use $\mathcal{P}_{\mathsf{no-priv}$ as an oracle to perform model-to-model comparisons."
- Pairwise judge: An evaluator that compares two responses at a time and selects the better one. "we perform RL with feedback from a pairwise judge in a self-play fashion \cite{swamy2024minimaximalistapproachreinforcementlearning}"
- Pairwise preferences: Judgments defined over pairs of items (responses) rather than absolute scores. "we adopt a self-play style approach that optimizes pairwise preferences directly"
- Policy: A mapping from inputs to probability distributions over outputs in reinforcement learning. "We search over policies $\pi \in \Pi \subseteq {\mathcal{X} \to \Delta(\mathcal{Y})}."
- Policy gradient techniques: RL methods that optimize policies by estimating gradients of expected rewards. "A wide spectrum of policy optimization algorithms have been proposed, from off-policy regression-based losses \citep{rafailov2023direct, gao2024rebel, azar2024general, gao2024regressing}, to policy gradient techniques \citep{ahmadian2024back, shao2024deepseekmathpushinglimitsmathematical, liu2025understandingr1zeroliketrainingcritical}."
- Positional bias: Systematic preference influenced by the order in which options are presented. "To account for the positional bias of pairwise judges \citep{zheng2023judgingllmasajudgemtbenchchatbot, qin2024large}, we perform the standard averaging of judge preferences across both input orderings:"
- Privileged information: Additional information available to the evaluator (not the generator) that aids more accurate judgment. "we provide the English reference response as privileged information \cite{vapnik2009new} to the judge"
- PNT metric: A measure used to quantify non-transitivity in preferences. "We report the PNT metric proposed by \citet{xu2025investigatingnontransitivityllmasajudge}."
- Reward hacking: Exploiting the reward function to achieve high scores via unintended behaviors. "helped avoid ``reward-hacking'' \citep{hadfield2017inverse}"
- Reward modeling: Learning a function that maps outputs to scalar rewards consistent with preferences. "making standard reward modeling fundamentally misspecified."
- RLHF: Reinforcement Learning from Human Feedback, a framework for post-training LLMs. "Popularized by RLHF~\citep{ouyang2022traininglanguagemodelsfollow}, reinforcement learning techniques have gained wide adoption in LLM post-training."
- RLVR: Reinforcement Learning with Verifiable Rewards, an RL setup emphasizing automatically checkable signals. "By comparing the +RLVR and SP3F-7B rows of \autoref{tab:all_tasks}, we can more precisely identify the benefits of judge feedback."
- Sample complexity: The amount of data needed to learn an effective model or component. "we have reduced the sample complexity of learning a verifier."
- Scalar reward function: A single numerical score intended to reflect preferences or performance. "Such intransitivity means no scalar reward function can faithfully represent the judge's preferences"
- Self-play: Training by comparing multiple generated responses against each other within the model’s own outputs. "in a self-play fashion \cite{swamy2024minimaximalistapproachreinforcementlearning}"
- Self-Translate Test: An evaluation technique where the model translates the prompt into English and then answers. "Specifically, we use Self-Translate Test~\cite{etxaniz2023multilinguallanguagemodelsthink} where the translation are done using the model itself."
- SP3F: The proposed framework “Self-Play with Privileged Pairwise Feedback” for multilingual reasoning. "We propose SP3F: Self-Play with Privileged Pairwise Feedback: a method for training multilingual reasoning models without any data in the target language(s)."
- Teacher model: A stronger model that provides reference answers used for supervision or judgment. "can be relatively easily generated by a teacher model (e.g., o1 \citep{jaech2024openai}, R1 \cite{deepseekai2025deepseekr1incentivizingreasoningcapability})."
- Total orderings: A global, consistent ranking of items without cycles. "provide more consistent global rankings (i.e., total orderings) over responses."
- Translate-Test: A baseline where prompts are translated to English before being answered by the model. "In addition, we compare against Translate-Test~\cite{ponti2021modellinglatenttranslationscrosslingual, artetxe2023revisitingmachinetranslationcrosslingual}, where the query is translated into English before being solved by the model."
- Verifiable rewards: Automatically checkable signals (e.g., correctness, format, language) used for RL supervision. "we perform RL (GRPO, \citet{shao2024deepseekmathpushinglimitsmathematical}) with feedback from verifiable rewards \cite{lambert2025tulu3pushingfrontiers} and a pairwise judge."
- Win rate: The proportion of pairwise comparisons a response wins, used as the RL reward. "use the average win-rate of each response against the other samples as the reward for RL"
Collections
Sign up for free to add this paper to one or more collections.