- The paper introduces a robust statistical inference framework for EBMs using Boulevard regularization to reformulate boosting as kernel ridge regression.
- It derives central limit theorems for feature-wise effects, enabling accurate computation of confidence and prediction intervals.
- Empirical results on UCI datasets validate the method's stability, minimax-optimal MSE rates, and superior resistance to overfitting.
Statistical Inference and Uncertainty Quantification for Explainable Boosting Machines
Introduction and Motivation
Explainable Boosting Machines (EBMs) have emerged as “glass-box” models that provide a middle ground between purely interpretable linear models and highly performant black-box tree ensembles. EBMs learn Generalized Additive Models (GAMs) where each feature’s contribution is captured as an independent, potentially nonlinear univariate function via boosting trees. The interpretability is derived from the additive decomposition which isolates each feature’s marginal effect. However, traditional EBMs primarily yield point estimates, lacking robust statistical inference on learned functions. Bootstrapping is commonly used for uncertainty quantification, yet it is computationally inefficient and offers limited theoretical guarantees.
This work introduces a rigorous statistical inference framework for EBMs, leveraging recent advancements in the asymptotic theory of gradient boosting. The key innovation is integrating Boulevard regularization—a moving average over tree updates—which reformulates the boosting procedure to converge to kernel ridge regression. This enables the derivation of asymptotic normality for both predictions and feature-wise effects, yielding minimax-optimal mean squared errors and theoretically sound confidence and prediction intervals.
Boulevard Regularization and Asymptotic Theory
Traditional gradient boosting aggregates trees additively, which complicates theoretical analysis. Boulevard regularization replaces the sum with a moving average:
f^b←bb−1fb−1+bλtb
where tb is the next tree and λ is the learning rate. In the infinite boosting limit, this procedure converges to kernel ridge regression. For EBMs, this approach is further specialized to yield feature-wise kernel ridge regression, each component capturing the effect of a single feature.
The authors derive central limit theorems for several algorithmic variants—parallelized, sequential (random cyclic), and backfitting-like EBMs—showing asymptotic normality of predictions and feature-wise learned functions. Importantly, the kernel formulation allows bypassing the curse of dimensionality for additive models: for p features and n samples,
MSE=O(pn−2/3)
for Lipschitz GAMs, matching the minimax-optimal rate for univariate nonparametric regression (2601.18857).
Feature-wise Statistical Inference: Confidence and Prediction Intervals
A central contribution is the construction of feature-specific confidence intervals and response prediction intervals based on the derived asymptotic normality. The confidence intervals are computed for each f(k)(x), and prediction intervals for the overall response, with interval widths quantifiable via kernel weights obtained during training.

Figure 1: Feature-wise confidence intervals generated by the proposed method, visualizing uncertainty around centered feature effects for the UCI Obesity dataset.
This approach is computationally scalable: by working in histogram bin-space (leveraging the discrete leaf structure of tree splits), interval width calculations become independent of sample size n, depending only on p and the maximal number of bins m (typically bounded at 255 or 511).
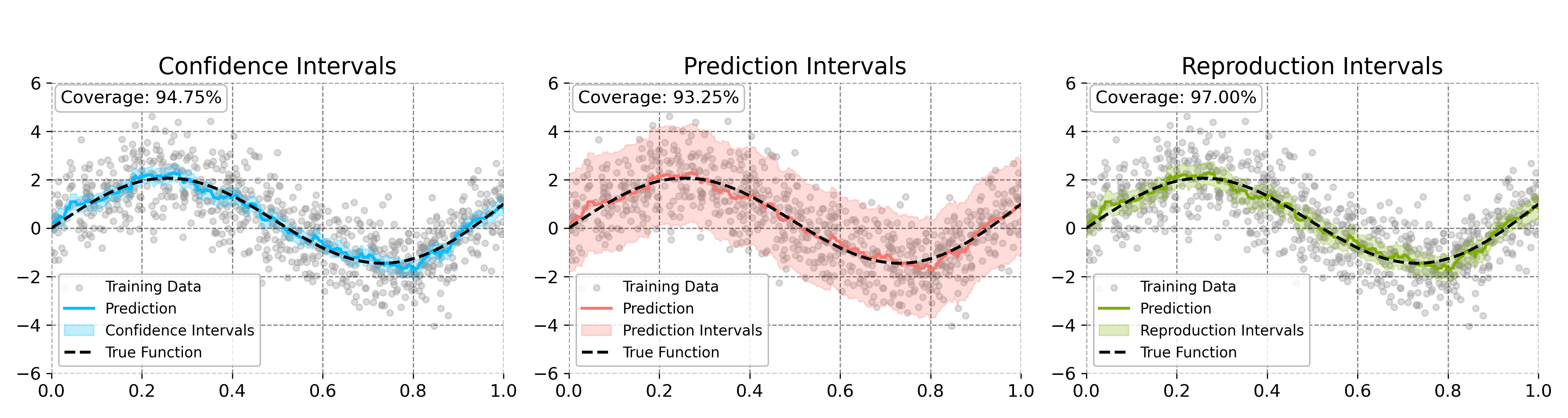
Figure 2: Confidence and prediction intervals on a synthetic 1D nonlinear function, illustrating interval coverage and shape.
Coverage rates and interval widths are empirically validated to consistently match nominal values across synthetic and real datasets. The approach provides feature-wise (per-component) inference, an advance over previous kernel ridge regression and boosting asymptotics which typically address only aggregate predictions (2601.18857).
Algorithms: Parallelization and Identifiability
Three primary algorithmic configurations are proposed:
- Parallelized Boosting with Boulevard Regularization: All features updated synchronously, requiring either small ($1/p$) learning rates or strong feature kernel orthogonality assumptions for provable convergence.
- Random Cyclic/Sequential Updates: Only one feature updated per round; easier theoretical analysis but reduced parallel efficiency.
- Backfitting-like Leave-One-Out Approach: Tree fitting for each feature excludes contributions from that feature in the residual, yielding unbiased per-component estimates but increasing computational complexity for interval calculations.
Each algorithm is analyzed for asymptotic behavior and statistical efficiency. The parallelized algorithm is shown to attain minimax-optimal rates without dimensionality penalties, contingent on identifiability properties ensured by the EBM structure and histogram trees.
Empirical Evaluation
Extensive experiments demonstrate the empirical validity of the derived inference procedures:
- Predictive Accuracy: The proposed algorithms match or exceed EBM’s performance on real UCI datasets (Wine Quality, Obesity, Air Quality) while outperforming linear models and resisting overfitting more robustly than standard gradient boosting under suboptimal hyperparameter regimes.
- Overfitting Resistance: Boulevard regularization is naturally resistant to overfitting without the need for early stopping, enabling stable performance even when hyperparameters are not tuned.
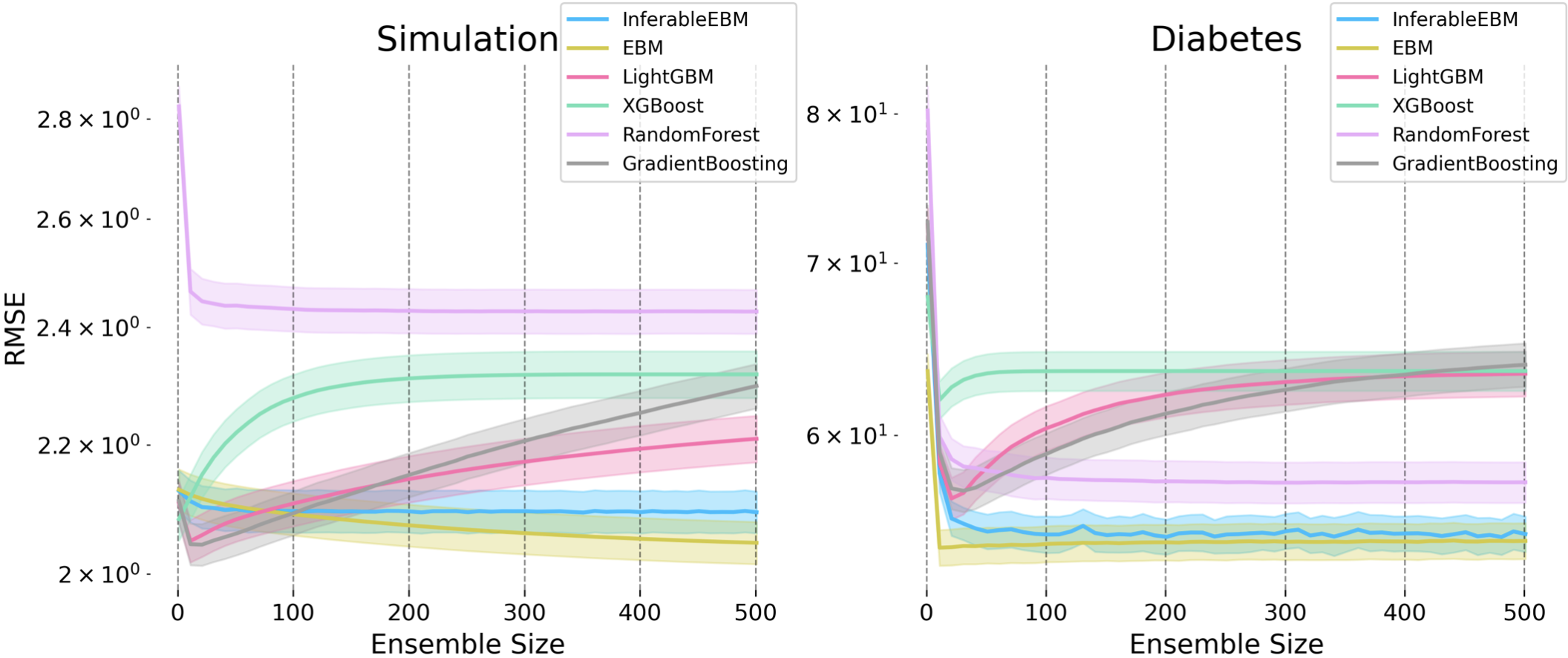
Figure 3: RMSE trajectories for Algorithm 1 and baselines, showing stability and resistance to overfitting across multiple trials.
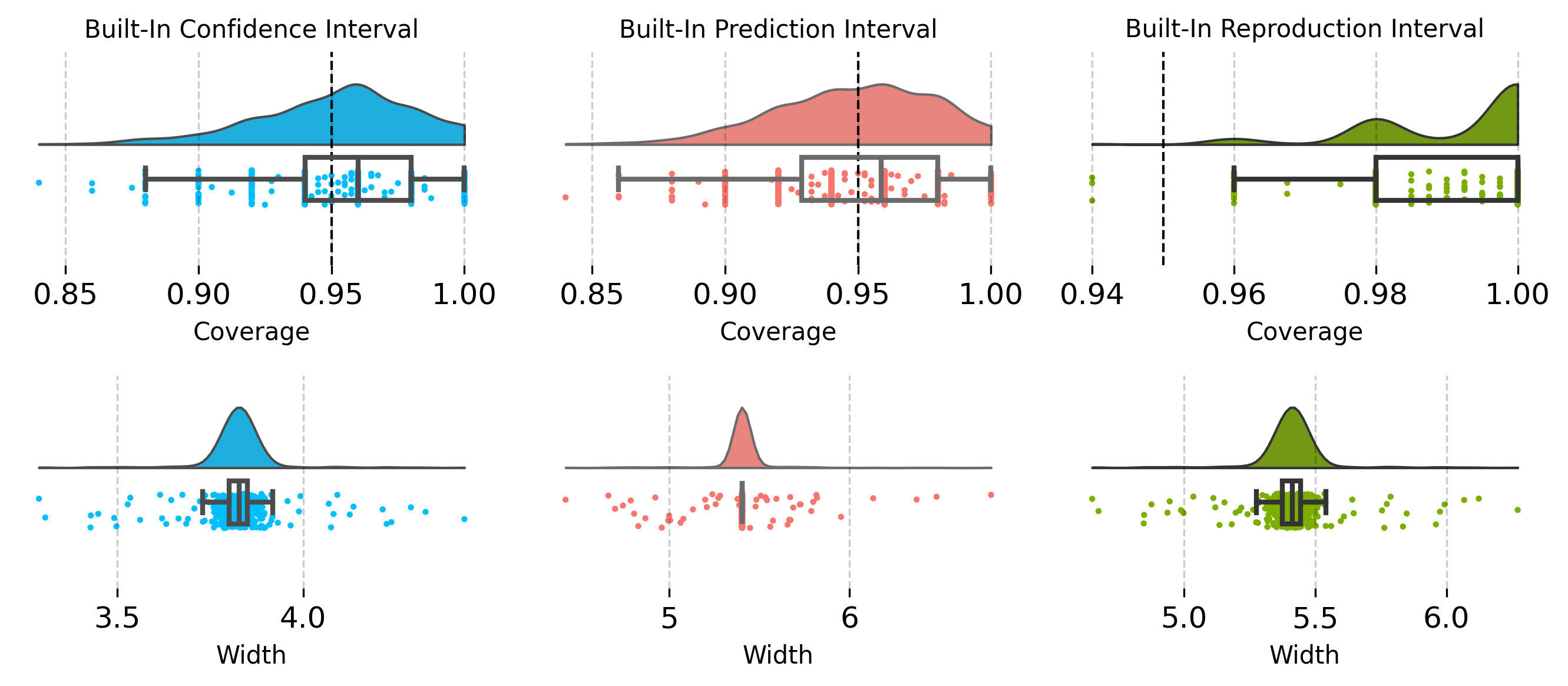
Figure 4: Coverage and width statistics for intervals over multiple runs, validating nominal coverage levels for both confidence and prediction intervals.
Qualitative analyses corroborate the ability to reliably identify important features and marginal effects with rigorous uncertainty bounds, supporting downstream statistical inference tasks such as variable importance testing.
Theoretical Implications and Extensions
The convergence to kernel ridge regression and the associated central limit theorems for each feature effect mark a significant step in the theoretical understanding of boosting-based additive models. The methods provide strong guarantees on both prediction quality and uncertainty quantification, facilitating model reliability assessments and interpretability in applied contexts.
Potential extensions include more complex additive structures (e.g., structured interaction terms), adaptation to discrete outcomes, and adaptation to non-constant variance settings (heteroscedasticity). The kernel formulation offers a basis for model comparison, jackknife-based analysis, and integration with other learners (2601.18857).
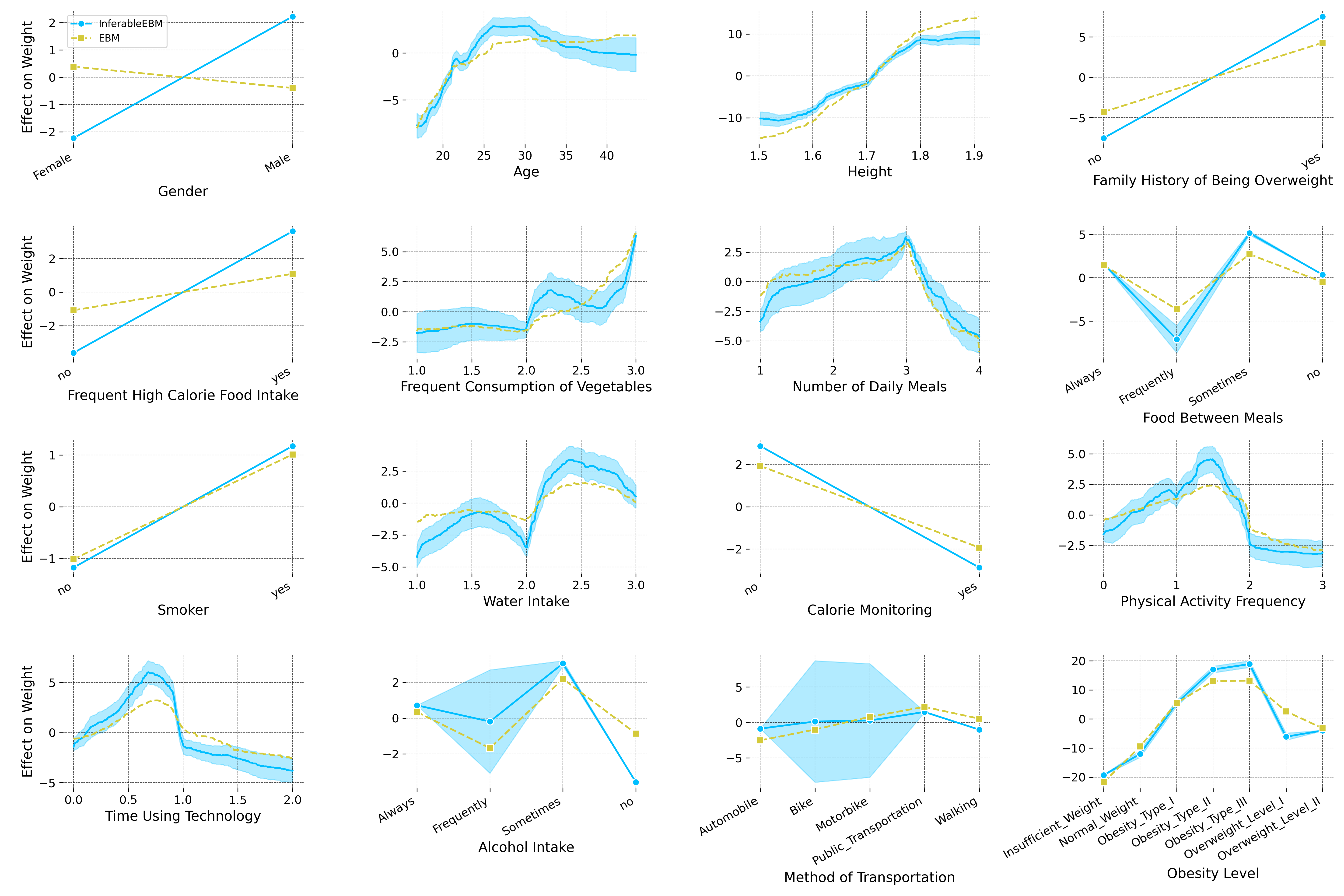
Figure 5: Full set of estimated feature effects on the Obesity dataset, displaying confidence intervals for each covariate’s effect and highlighting interpretability and feature-wise inference capabilities.
Conclusion
The presented framework establishes frequentist inference tools for EBMs, providing theoretically founded and computationally efficient confidence and prediction intervals for additive tree-based models. By leveraging Boulevard regularization within a specialized boosting context, this work eliminates reliance on bootstrapping for uncertainty quantification, yields interpretable feature-wise inference, and achieves minimax-optimal learning rates for additive models. These results offer practical and theoretical advances for interpretable machine learning, with broad applicability in settings where both performance and trustworthiness are required.
Reference:
Statistical Inference for Explainable Boosting Machines (2601.18857)