- The paper demonstrates that reducing block sizes below a certain threshold can increase quantization error, challenging conventional assumptions.
- It develops a probabilistic framework that decouples per-block and global errors, validated by experiments on various LLM benchmarks.
- The study proposes a UE5M3 format that repurposes the unused sign bit in FP8 scaling to extend dynamic range and restore error monotonicity.
Limits and Error Dynamics of Finer-Grained Microscaling Quantization in LLMs
Problem Statement and Motivation
The paper "Is Finer Better? The Limits of Microscaling Formats in LLMs" (2601.19026) systematically investigates the error behavior and practical limitations of microscaling quantization in LLMs, as the block size of quantization is reduced and scale precision is lowered. By decoupling the impact of low-bit quantization on model quality into per-block and global effects, the authors identify a counter-intuitive regime: block-wise quantization error increases when block sizes are reduced below a model- and format-dependent threshold. This challenges the prevailing assumption that smaller blocks decrease quantization error due to finer locality.
Microscaling formats—used widely in AI hardware for their efficiency—supposedly benefit from decreasing the block size, enabling lower error at reduced precision. Commercial accelerators have recently advanced aggressive quantization strategies, supporting domain-specific low-precision floating point (e.g., FP4, FP8) and block-based scaling factors. However, as model weights (and activations) become increasingly narrow, the fundamental error tradeoffs between block size, scaling factor precision, and the distributional properties of tensors enter uncharted territory. The main results of the paper directly address this gap, providing experimental and theoretical analysis of the observed anomalies.
Empirical Observation and Quantization Anomaly
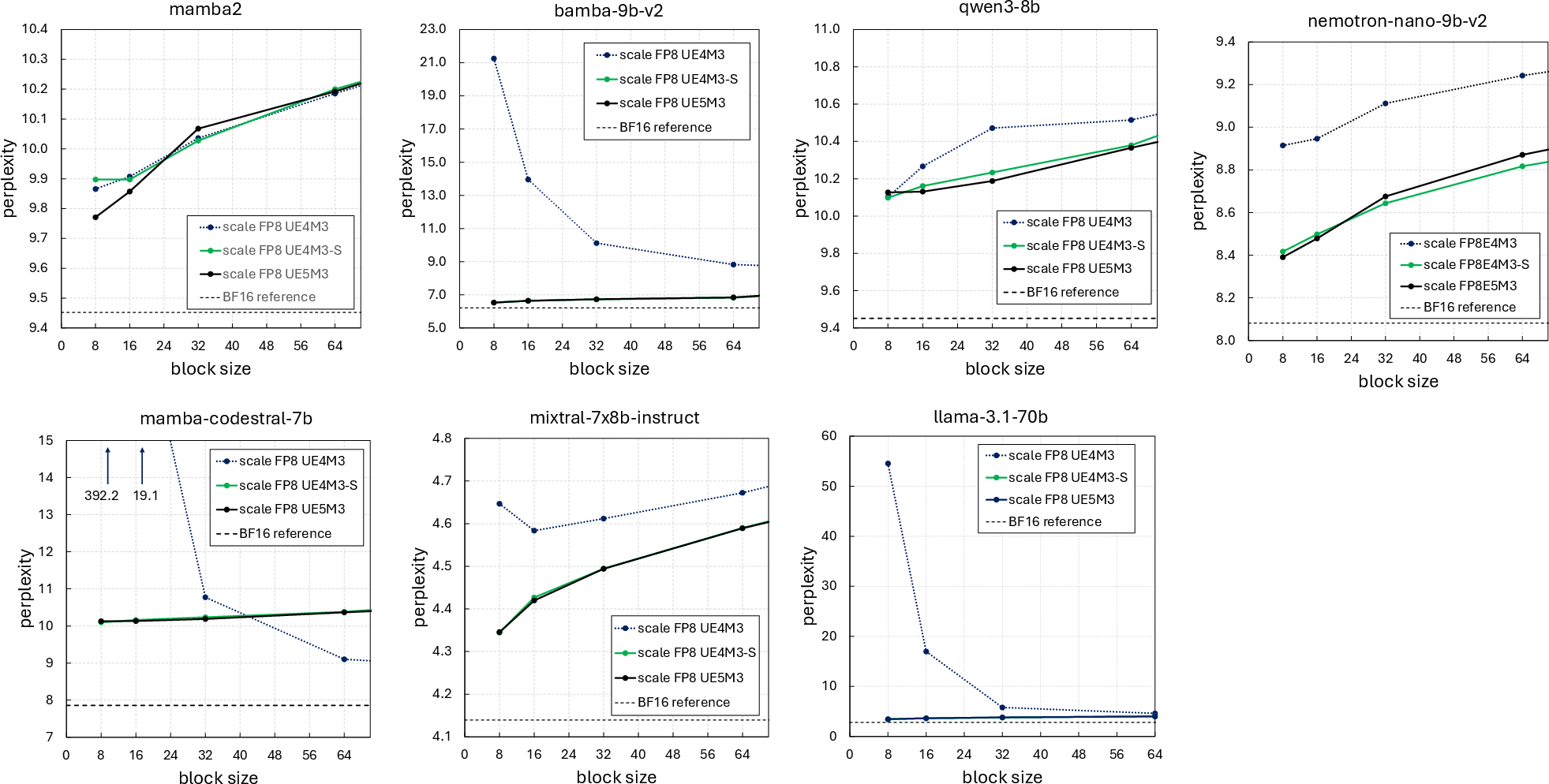
In empirical evaluations across LLMs (including several 8–9B parameter transformer models and variants with distinct distributional properties), the expected decrease in quantization error and perplexity with reduced block size is validated for high-precision (BF16) block scales. However, when employing hardware-targeted FP8 scaling (notably unsigned E4M3, or UE4M3), a reversal is observed: decreasing the block size below a threshold increases the perplexity gap, sometimes termed "perplexity inversion".
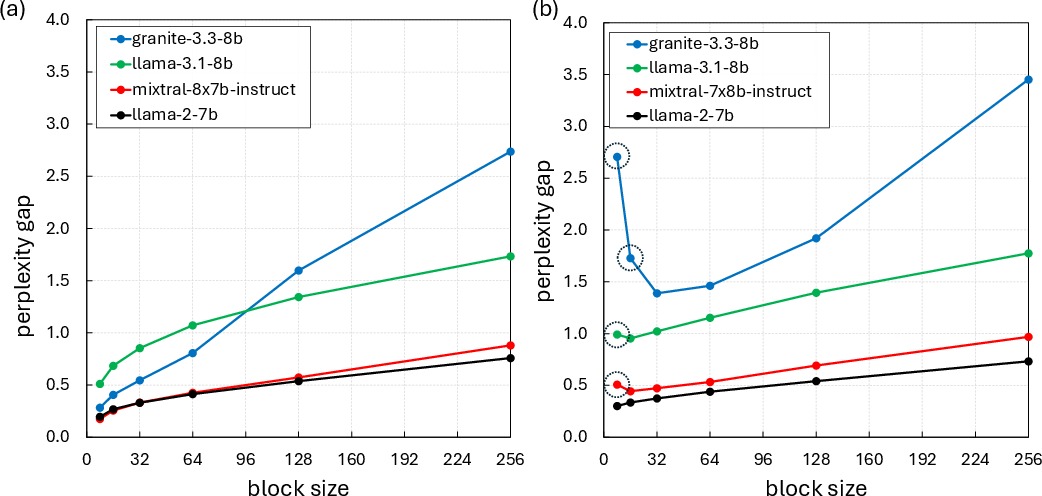
Figure 1: FP4 microscaling quantization with BF16 scales shows monotonic perplexity improvement as block size decreases, while the UE4M3 scale induces non-monotonicity with substantial inversion at small block sizes.
Detailed per-block MSE analysis shows that blocks within certain weight tensors (those with lower σ) exhibit higher errors at block size 8 versus 16, not explained by classical quantization error models. This non-monotonicity and model-dependent variation is absent when high-precision (unquantized, e.g., BF16) scales are utilized—it is fundamentally a product of scale quantization.
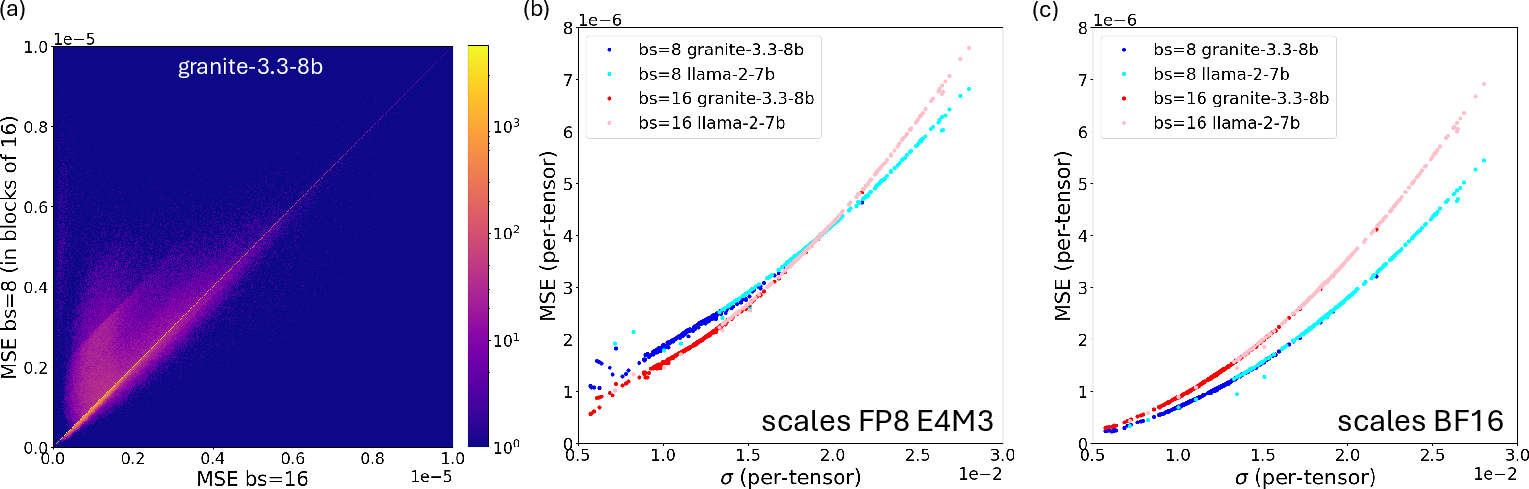
Figure 2: (a) Per-block MSE comparison for block sizes 8 vs 16 shows a prevalence of higher error with smaller blocks. (b/c) Per-tensor MSE vs standard deviation σ of weight tensors, FP8 UE4M3 scales emphasize the error crossover; BF16 scales do not.
Theoretical Framework and Error Source Decoupling
The authors develop a probabilistic framework for quantization error in block-wise formats, covering both floating-point and integer element types, with exact and quantized scaling factors. The framework roots in evaluating the MSE as a function of:
- Distributional width of tensor blocks (σ)
- Block size N
- Scaling factor quantization (precision and dynamic range)
Crucially, the analysis distinguishes between:
(1) Error for non-max elements (xi=xmax),
(2) Error for scale-setting element (xi=xmax, which is zero only with infinite-precision scale),
(3) Error when the maximum is so small that all elements round to zero due to limited scale dynamic range.
Across models and synthetic data, the error behavior is dominated by (1) for wide distributions, but as σ shrinks, (2) and (3) become significant—especially so at smaller block sizes, where the probability of small xmax increases. The result is a crossover point where reducing block size actually increases error for narrow distributions.
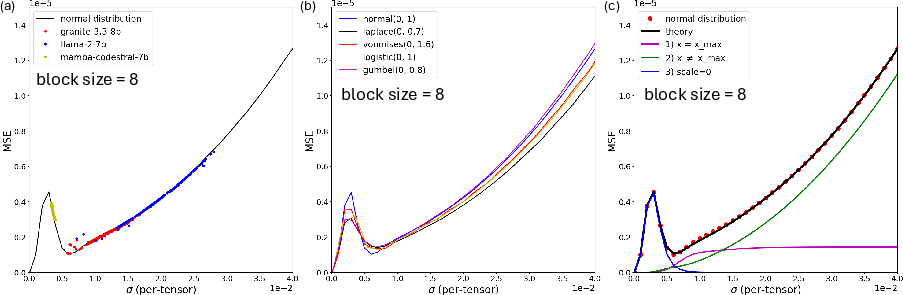
Figure 3: (a) MSE-σ dependency of pretrained model weights matches theoretical predictions based on the normal distribution. (c) Decomposition shows which error sources dominate across σ.
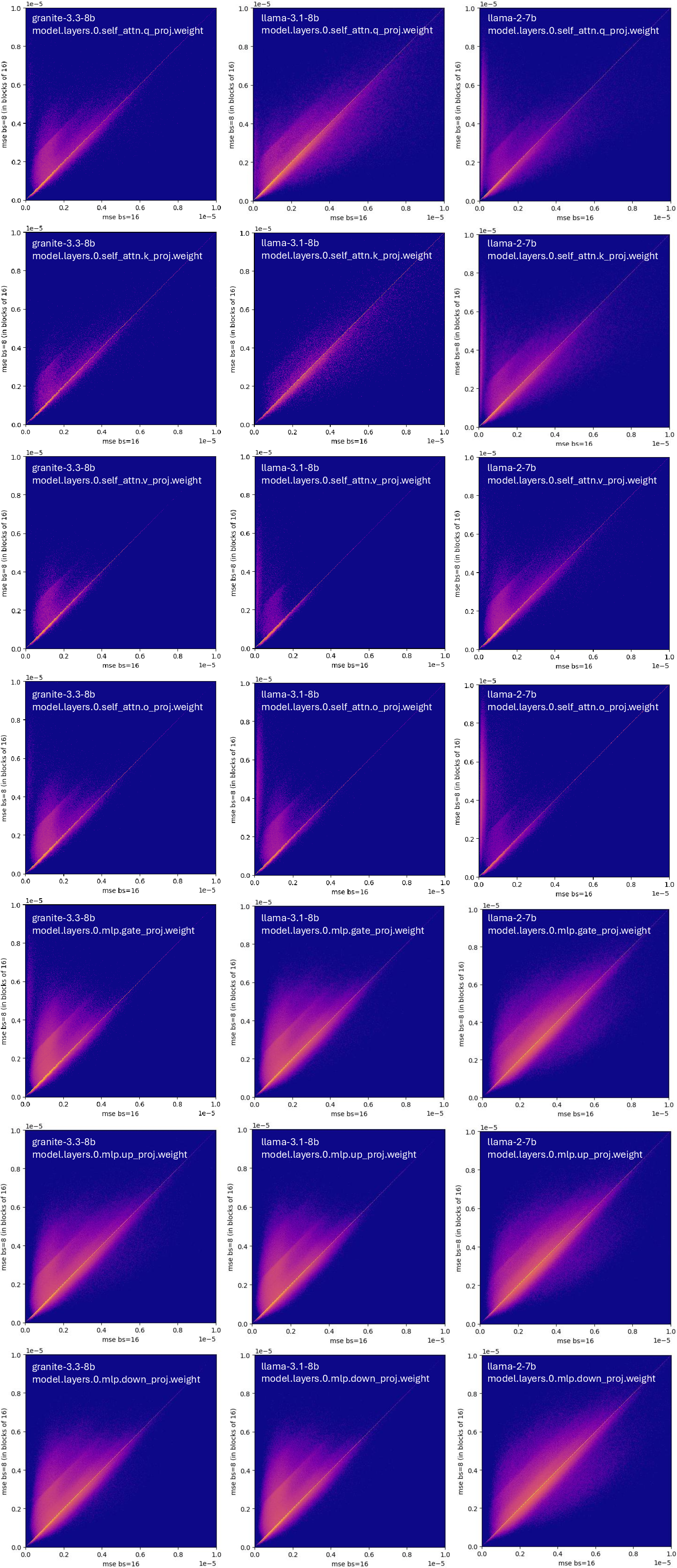
Figure 4: Comparison of block-wise MSE for block sizes 8 vs 16; majority of points above diagonal reflects higher error for smaller blocks.
The identification of non-monotonic scaling error has both theoretical and hardware implications:
Hardware-Friendly Solution: Extended Scale Dynamic Range
Based on the theoretical analysis, the authors propose to repurpose the unused sign bit in FP8 UE4M3 scaling to create an unsigned E5M3 (UE5M3) format—doubling the exponent width and thus drastically increasing the representable dynamic range. This modification allows blocks, including those with very small xmax, to select finer scales, mitigating both the rounding-to-zero and the non-max element error sources.
UE5M3 can be implemented with minimal hardware changes (increased exponent adder width, no added mantissa complexity), as demonstrated through synthesis of a PE array at advanced process nodes. Compared to per-tensor scaling, UE5M3 preserves error monotonicity without the need for global scaling, avoids outlier vulnerability, and yields strong perplexity/accuracy parity with the BF16 baseline across several benchmarks.
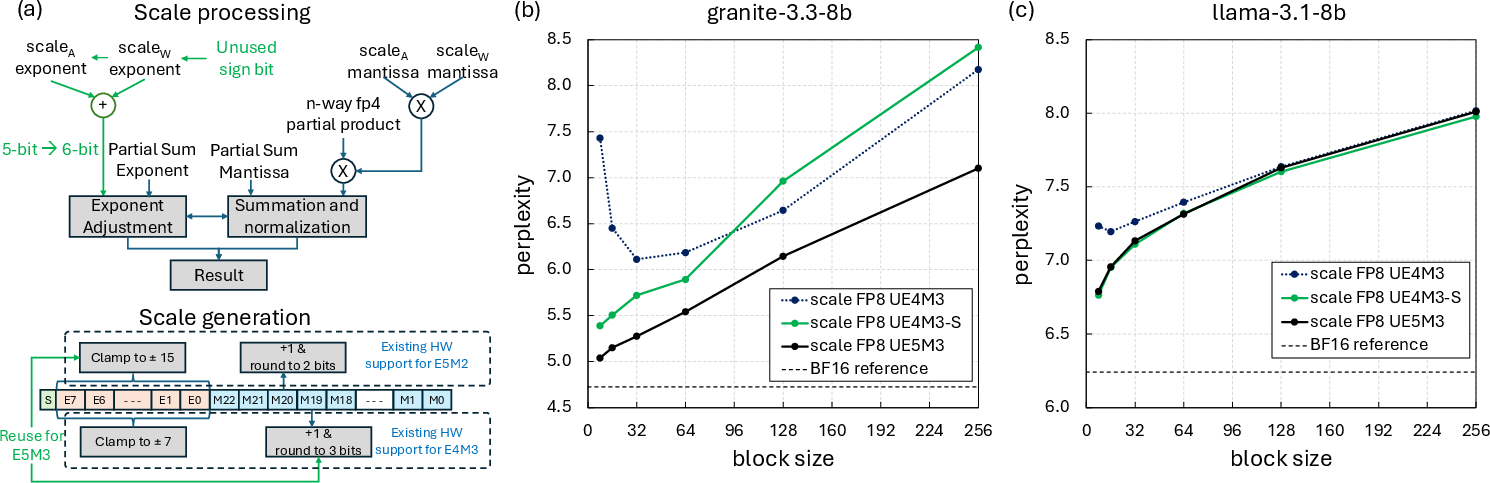
Figure 6: (a) Hardware block diagram for integrating UE5M3 scaling. (b) Perplexity vs block size, showing elimination of inversion with UE5M3.
Future Directions
The results suggest multiple avenues for further research:
- Generalization to other ultra-low precision formats, including INT4, FP6, and dynamic/learned scaling variants.
- Adaptive block size or block partitioning based on distributional statistics at quantization time.
- Layer- or tensor-type specific quantization strategies, considering their empirical tendency to exhibit narrow or heavy-tailed distributions.
- Exploration of stochastically or deterministically mixed scaling policies, blending UE5M3 with classic per-channel or per-tensor scaling in deployment.
Conclusion
This paper provides a rigorous explanation for the observed quantization anomaly in block-wise microscaling, precisely connecting the phenomenon to scale quantization and tensor distribution width. The theoretical framework presented closely matches empirical model behavior and enables principled decisions about format and block size in next-generation LLM deployment. The introduction and hardware proof-of-concept of UE5M3 scaling offers a practical solution, reconciling both efficiency and accuracy requirements for sub-8-bit quantization in large-scale inference and training accelerators.