Quartet II: Accurate LLM Pre-Training in NVFP4 by Improved Unbiased Gradient Estimation
Abstract: The NVFP4 lower-precision format, supported in hardware by NVIDIA Blackwell GPUs, promises to allow, for the first time, end-to-end fully-quantized pre-training of massive models such as LLMs. Yet, existing quantized training methods still sacrifice some of the representation capacity of this format in favor of more accurate unbiased quantized gradient estimation by stochastic rounding (SR), losing noticeable accuracy relative to standard FP16 and FP8 training. In this paper, improve the state of the art for quantized training in NVFP4 via a novel unbiased quantization routine for micro-scaled formats, called MS-EDEN, that has more than 2x lower quantization error than SR. We integrate it into a novel fully-NVFP4 quantization scheme for linear layers, called Quartet II. We show analytically that Quartet II achieves consistently better gradient estimation across all major matrix multiplications, both on the forward and on the backward passes. In addition, our proposal synergizes well with recent training improvements aimed specifically at NVFP4. We further validate Quartet II on end-to-end LLM training with up to 1.9B parameters on 38B tokens. We provide kernels for execution on NVIDIA Blackwell GPUs with up to 4.2x speedup over BF16. Our code is available at https://github.com/IST-DASLab/Quartet-II .



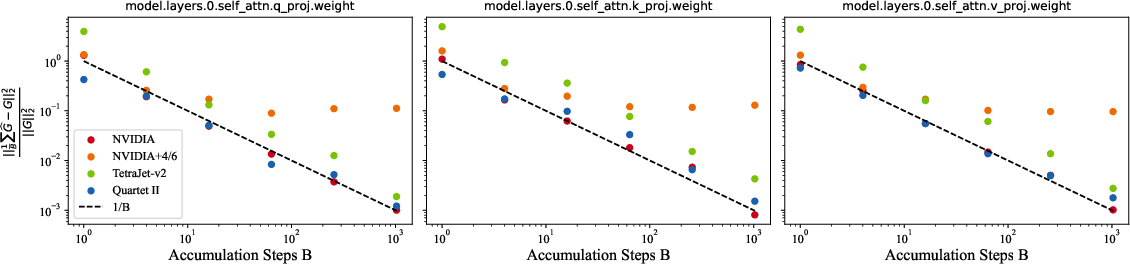
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about training LLMs faster and more cheaply by using very small numbers (only 4 bits) to represent most of the math, without hurting learning quality. The authors introduce a new method called MS-EDEN and a full training recipe called Quartet II that together make 4-bit training more accurate and stable. They also show it runs efficiently on NVIDIA’s latest Blackwell GPUs.
Think of it like compressing photos: smaller files save space and load faster, but you don’t want them to get too blurry. The paper shows how to compress the “numbers” used during training so they stay sharp enough to learn well.
Key Objectives
Here are the main questions the paper aims to answer:
- Can we train big models mostly in a 4-bit format (called NVFP4) and still reach the accuracy of higher-precision formats like FP16 or FP8?
- How can we keep the “gradients” (the signals the model uses to learn) accurate when we use such tiny numbers?
- Is there a better alternative to the common approach (stochastic rounding) that keeps gradients “unbiased” without adding too much noise?
- Can this improved approach work end-to-end (forward and backward passes) on real LLMs and run fast on modern GPUs?
How They Did It (Methods in Simple Terms)
First, some quick definitions in everyday language:
- Forward pass: The model makes predictions. Think: “try answer.”
- Backward pass: The model figures out how to improve. Think: “learn from mistakes.”
- Gradients: Directions telling the model how to change. Think: “move this way to do better.”
- Quantization: Storing numbers with fewer bits to save memory and compute. Think: “compressing numbers.”
- NVFP4: A special 4-bit format on NVIDIA Blackwell GPUs. It stores each small group of numbers with a shared “scale” (like a local zoom level) so they fit into 4 bits, plus one overall scale for the whole tensor. This keeps a good range while being very compact.
- Unbiased gradient estimate: On average, the estimate isn’t systematically too big or too small. Think: “no tilt—fair on average.”
- Stochastic rounding (SR): When a number sits between two 4-bit levels, flip a fair coin to round up or down. This keeps the average honest, but can add a lot of noise.
- Randomized rotations (RHT): Shuffle and mix values in a structured way so big spikes get spread out. Think: “blend the data so outliers don’t break the compression.”
What’s new:
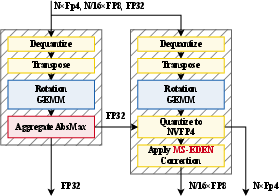
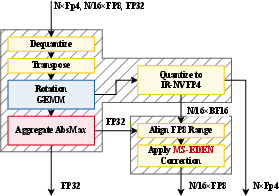
- MS-EDEN (MicroScaling EDEN)
- Idea: Keep the randomness off the tiny 4-bit values and instead put it on the 8-bit scales that group them. The 4-bit values use normal round-to-nearest, while the 8-bit scales are adjusted (using stochastic rounding) to correct small biases.
- Why it helps: Rounding each tiny 4-bit number randomly (SR) adds a lot of noise. Rounding fewer, larger 8-bit scales adds much less noise while still keeping things unbiased overall.
- It also uses randomized rotations along the “inner” dimension of matrix multiplications (the big multiplies that dominate training) to smooth outliers before quantizing.
- Quartet II training recipe
- Forward pass: Use round-to-nearest (RTN) in NVFP4 with standard per-16-element scales, plus a smart “Four-over-Six” scale choice (the method picks between two scale settings—4.0 or 6.0—to reduce error). This is like choosing the best zoom level per small block to keep numbers sharp.
- Backward pass: Re-quantize the tensors with MS-EDEN. Apply the same randomized rotation to both inputs of a matrix multiply so the rotations cancel out after multiplication, ensuring the gradients remain unbiased without extra steps.
- GPU kernels
- The authors built specialized CUDA kernels for Blackwell GPUs to make this run fast, and added a neat trick (“post hoc range alignment”) to reduce memory traffic when re-quantizing scales, which boosts speed.
Main Findings and Why They Matter
The paper reports several key results:
- Lower error than SR: MS-EDEN cuts quantization error by more than 2× compared to stochastic rounding (on typical data), while keeping gradients unbiased. Less noise means more reliable learning.
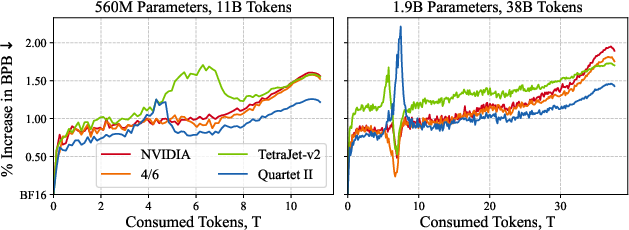
- Better training quality: In end-to-end LLM pre-training (up to 1.9B parameters on 38B tokens), Quartet II consistently improves validation loss compared to leading NVFP4-recipe baselines from industry (e.g., NVIDIA’s) and papers.
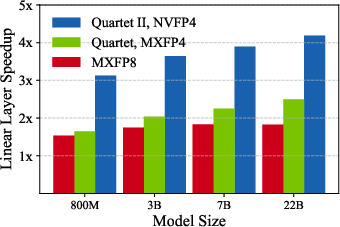
- Faster training: Their kernels achieve up to 4.2× speedup over BF16 for linear layers on Blackwell GPUs. In real training, they report more than 2.4× higher throughput for a 1B model, which can save a lot of time and money.
- Strong theory + practical design: They provide analytic arguments showing improved gradient estimates in the major matrix multiplications, and their design works within NVFP4’s hardware constraints (4-bit values, 8-bit group scales, one global scale).
Why it matters: Training massive models is expensive and energy-heavy. If we can run most of the math in 4 bits without losing accuracy, we can train more models, more cheaply, and more sustainably—while keeping quality high.
Implications and Impact
- Cheaper, faster LLM training: More than 2× training speedups can significantly cut costs and carbon footprint for large projects.
- Better stability at 4 bits: MS-EDEN shows that you don’t have to choose between unbiased gradients and high noise—the scales-based correction is a sweet spot.
- Practical for industry: Quartet II fits current GPU hardware and offers open-source kernels, making adoption easier.
- Future directions: Similar ideas (moving randomness to where it hurts less, using smart rotations, scale choices like “Four-over-Six”) may further improve other low-precision formats and training workflows.
In short, this work makes 4-bit training more accurate and more practical, bringing us closer to fast, fully low-precision pre-training of LLMs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances NVFP4 training with MS-EDEN and Quartet II, but it leaves several important aspects unaddressed. Future work could target the following concrete gaps:
- Finite-dimensional guarantees: provide non-asymptotic unbiasedness error bounds for MS-EDEN as a function of rotation group size, dimension, and data distribution (beyond asymptotic arguments and empirical checks).
- Rotation group sizing: systematically study how RHT group size (e.g., 64/128/256) affects MSE, bias, throughput, and stability; identify optimal per-layer/group-size schedules.
- Seed management: assess how per-step/per-layer rotation and rounding seed policies affect variance, convergence, and reproducibility.
- Clipping factor selection: analyze and tune the
sclipping parameter used in MS-EDEN with RTN, including its impact on bias/MSE and robustness across layers and training phases. - Post hoc range alignment correctness: quantify any residual bias introduced by the ER-NVFP4 “post hoc” scale realignment; prove that stochastic rounding of FP8 scales fully preserves unbiasedness under this implementation.
- Forward-pass bias: characterize how the biased “4/6” grid selection in the forward pass impacts optimization dynamics and generalization (even if forward bias is often acceptable for QAT).
- Distributional robustness: evaluate MS-EDEN on heavy-tailed and highly skewed activation/gradient distributions (beyond MSE), using real trace statistics from large LLMs.
- Large-scale stability: validate training stability at larger scales (≥7B parameters) and longer runs (≥1T tokens), including loss spikes, drift, and recovery relative to FP8/BF16.
- Architectural breadth: test applicability beyond Llama-like models—e.g., long-context LLMs, MoE, vision transformers, diffusion models, and multimodal architectures.
- Non-linear and non-linear-layer paths: specify and evaluate precision/quantization for layer norm, softmax, normalization layers, positional encodings (e.g., RoPE), and MLP activations under NVFP4.
- Optimizer/state precision: document and ablate the precisions of optimizer states (e.g., Adam moments), master weights, and gradient accumulators; assess feasibility and impact of migrating these to NVFP4.
- Backward weight re-quantization overheads: provide a detailed cost-benefit analysis (compute, bandwidth, latency) of re-quantizing weights in the backward pass versus reuse, under MS-EDEN and SR.
- Outlier mechanisms: explore compatibility and performance of MS-EDEN with outlier-channel handling and intermediate FP32 scales (omitted here for practicality), to fairly benchmark against full TetraJet-v2 functionality.
- Rotation variants: investigate cheaper or sparse randomized rotations (e.g., SRHT variants, butterfly, learned or block-diagonal transforms) to reduce overhead while maintaining unbiasedness.
- Distributed training interplay: study integration with ZeRO, tensor/pipeline parallelism, and gradient all-reduce compression; assess whether MS-EDEN interacts with communication quantization or synchronization noise.
- Hardware portability: benchmark and validate kernels on data-center Blackwell (e.g., B200), prior NVIDIA generations (A/H), and AMD MI-series; assess reliance on FP8-scale stochastic rounding support.
- Energy and cost metrics: report power consumption, energy-per-token, and total cost-of-training improvements, not just kernel/linear-layer speedups.
- End-to-end throughput: provide comprehensive end-to-end training speedups across model sizes and pipelines (beyond isolated linear-layer and a single 1B-scale case).
- Memory footprint: quantify extra memory for storing FP4+FP8+FP32 scales, saved tensors for re-quantization, and rotation metadata; evaluate trade-offs with activation checkpointing.
- Long-context and shape edge cases: evaluate correctness and performance when inner dimensions are not multiples of 128/16, with dynamic sequence lengths and varying batch shapes.
- Learned or adaptive scaling: explore learned scale selection (beyond fixed “4/6”), block-wise or per-channel adaptive scaling, and their unbiasedness-preserving variants for backward.
- Convergence theory: establish SGD convergence rates and variance bounds with MS-EDEN under realistic smooth/non-smooth losses and non-Gaussian noise.
- Generalization and downstream tasks: broaden evaluation beyond C4/Nanochat to diverse corpora, multilingual settings, and rigorous downstream benchmarks (reasoning, math, code), isolating pretrain vs. finetune effects.
- Fairness of baselines: re-evaluate comparisons after implementing competitor features (e.g., TetraJet-v2 outlier channels/intermediate scales) to ensure apples-to-apples accuracy and speed comparisons.
- Reproducibility across stacks: document determinism across different drivers, CUDA/cuBLAS versions, and kernel implementations; provide seeding guidelines to replicate results precisely.
- Extension to other formats: adapt and test MS-EDEN for MXFP4 and INT4 microscaling formats, and evaluate whether similar variance/bias gains hold under their grids and ranges.
Glossary
- AbsMax: The absolute maximum value used to align quantization scales for a tensor. "a pre-computed AbsMax"
- BF16: A 16-bit floating-point format (8 exponent bits, 7 mantissa bits) commonly used for mixed-precision training. "relative to BF16 pre-training"
- BPB (bits-per-byte): A loss metric in language modeling indicating average bits needed to encode each byte of text. "bits-per-byte (BPB)"
- E2M1: A 4-bit floating-point format with 2 exponent bits and 1 mantissa bit. "E2M1 floating point format"
- E4M3: An 8-bit floating-point format with 4 exponent bits and 3 mantissa bits, used for NVFP4 group scales. "one E4M3 scale per 16 values"
- E8M3: A floating-point format with 8 exponent bits and 3 mantissa bits, used as an extended-range proxy for FP8 in BF16. "round scales to E8M3"
- EDEN: An unbiased quantization method combining randomized rotations with corrective rescaling to reduce variance. "One such method is EDEN"
- ER-NVFP4: Extended-range NVFP4 using FP4 values with E8M3 pseudo-scales prior to final alignment to NVFP4. "extended-range NVFP4 (ER-NVFP4)"
- FP16: A 16-bit floating-point format for training and inference in deep learning. "FP16 and FP8 training"
- FP4: A 4-bit floating-point format used in microscaling schemes for high-throughput training. "FP4 stochastic rounding (SR)"
- FP8: An 8-bit floating-point format often used for mixed-precision training and as NVFP4 scale storage. "FP8 scales"
- Four Over Six (4/6): A scale selection heuristic choosing between 4.0 and 6.0 grid maxima per block to minimize MSE. "Four Over Six (``4/6'')"
- GEMM: General Matrix Multiply; the dense matrix multiplication primitive central to neural network training. "dense matrix multiplications (GEMMs)"
- MS-EDEN: A microscaling variant of EDEN that shifts stochasticity to FP8 micro-scales to achieve unbiased gradients with lower error. "called MS-EDEN"
- Muon optimizer: A modern adaptive optimizer used as an alternative to Adam in large-scale training. "utilizes the Muon optimizer"
- MXFP4: A microscaling FP4 format with per-block scales, similar in concept to NVFP4. "MXFP4 microscaling floating point formats"
- NVFP4: NVIDIA’s microscaling FP4 format with FP4 elements, FP8 group scales, and a per-tensor FP32 scale for range extension. "The NVFP4 lower-precision format"
- QK-normalization: A normalization technique applied to query-key vectors in attention to improve stability. "QK-normalization"
- QuTLASS: A low-precision GEMM library/tooling for NVIDIA GPUs targeting quantized tensor-core execution. "we use QuTLASS"
- Randomized Hadamard Transform (RHT): A structured orthogonal rotation with randomization used to smooth distributions before quantization. "Randomized Hadamard Transform (RHT)"
- ReLU2: An activation function variant where outputs are squared after ReLU, improving certain training dynamics. "ReLU MLP activations"
- Round-to-Nearest (RTN): Deterministic quantization that rounds values to the nearest representable level in the target format. "round-to-nearest (RTN) quantization"
- Square-block quantization: Quantization using a single scale per square block (e.g., 16×16) to reuse weights without re-quantization. "square block quantization"
- Stochastic rounding (SR): Probabilistic rounding that preserves the input in expectation to produce unbiased quantized estimates. "stochastic rounding (SR)"
- Tensor cores: Specialized matrix-math units in NVIDIA GPUs accelerating mixed-precision GEMMs. "using tensor cores on Blackwell NVIDIA GPUs"
- TetraJet-v2: An NVFP4 training recipe adding corrections and heuristics (e.g., outlier handling) over NVIDIA’s baseline. "TetraJet-v2 was proposed"
- WSD LR schedule: A specific learning-rate scheduling strategy employed in Nanochat training. "with WSD LR schedule"
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now using the paper’s methods (MS-EDEN and the Quartet II NVFP4 training scheme), together with likely sectors, tools/workflows, and key dependencies.
- Sector: Software/AI, Cloud Providers
- Use case: Cut LLM pre-training cost and time by switching linear layers to NVFP4 with Quartet II (4.2× faster linear layers; >2× overall throughput vs BF16 reported for 1B-scale training).
- Tools/workflows: Integrate the authors’ CUDA kernels and computation graph into PyTorch training stacks; use QuTLASS for matmuls; apply “4/6” forward scaling and MS-EDEN on backward pass; keep other components (e.g., norms/softmax) as in existing recipes.
- Assumptions/dependencies: Access to NVIDIA Blackwell GPUs (e.g., RTX 5090, GB200) with NVFP4 tensor cores; ability to modify training code; careful seed management for RHT; weight re-quantization enabled on backward pass.
- Sector: Healthcare (on‑prem R&D), Finance (risk/compliance models)
- Use case: On‑prem domain LLM pre-training/fine-tuning under privacy constraints at lower cost/energy by adopting fully NVFP4 linear layers with unbiased gradients.
- Tools/workflows: Deploy Quartet II kernels on secure Blackwell servers; run domain data; maintain standard optimizers; monitor training loss convergence with MS-EDEN.
- Assumptions/dependencies: Blackwell hardware in secure facilities; compliance approvals; staff able to operate low‑precision kernels; validation for domain‑specific outliers.
- Sector: Academia/Education
- Use case: Democratize research by pre-training 100M–2B models on prosumer Blackwell GPUs (e.g., RTX 5090) using the open-source Quartet II implementation, reducing compute budget.
- Tools/workflows: Course labs and research groups adopt Quartet II modules; standard Llama-style pre-training pipelines with unchanged hyperparameters; track loss vs BF16 baselines.
- Assumptions/dependencies: Availability of compatible GPUs; willingness to accept new kernels; reproducibility via fixed RHT seeds; training stability beyond toy setups validated in the paper up to 1.9B/38B tokens.
- Sector: MLOps/Engineering
- Use case: Productionize low-precision training by adding a “quantized linear layer” path in pre-training workflows with automatic fallbacks and monitoring.
- Tools/workflows: Pipeline flag to enable Quartet II layers; telemetry on quantization MSE, loss gap, gradient variance; roll-back to FP8/BF16 on anomaly detection; CI perf tests.
- Assumptions/dependencies: Observability/metrics integration; robust random seed management; training infrastructure that supports mixed precision components.
- Sector: Energy/Sustainability, Corporate CSR
- Use case: Reduce training energy per token and report improved carbon intensity using NVFP4 linear layers without sacrificing optimization stability (unbiased MS-EDEN gradients).
- Tools/workflows: Integrate energy meters/carbon calculators into training runs; attribute savings to NVFP4 adoption; include in ESG disclosures.
- Assumptions/dependencies: Accurate power metering; controlled comparisons vs BF16/FP8; same data and hyperparameters.
- Sector: Cloud & Managed AI Services
- Use case: Offer “NVFP4-optimized training” SKUs as a managed service leveraging Quartet II kernels to attract cost-sensitive enterprise workloads.
- Tools/workflows: AMIs or Docker images preloaded with the authors’ kernels; reference recipes; SLAs specifying expected speedups and accuracy envelope.
- Assumptions/dependencies: Sufficient supply of Blackwell instances; support for Triton/CUDA toolchains; customer readiness to adopt NVFP4.
- Sector: SMB/Startups, EdTech
- Use case: Faster low-budget fine-tunes (adapters/LoRA or full linear layers) using NVFP4 training for faster iteration cycles and more experiments per dollar.
- Tools/workflows: Replace linear layers in fine-tuning code with Quartet II modules; verify validation loss parity to FP8/BF16; use consumer Blackwell GPUs where possible.
- Assumptions/dependencies: Fine-tuning tasks dominated by GEMMs; stable convergence at target scales; limited engineering bandwidth for new kernels.
- Sector: Software/Inference (select deployments using NVFP4 matmuls)
- Use case: Lower inference latency or memory for NVFP4-capable inference paths by applying the paper’s “4/6” forward pass scaling to reduce activation/weight quantization MSE.
- Tools/workflows: NVFP4 inference kernels; use “4/6” grid selection during offline quantization/calibration; measure perplexity/accuracy impacts.
- Assumptions/dependencies: Platform supports NVFP4 inference (hardware drivers/runtimes); model architecture amenable to NVFP4 forward pass; acceptance of deterministic scaling.
- Sector: Open-Source Tools/Frameworks
- Use case: Add an “MS-EDEN quantizer” module and “Quartet II linear layer” to libraries (e.g., xFormers, Transformer Engine forks) as drop-in building blocks.
- Tools/workflows: Package kernels; Python bindings; examples for Llama-style models; unit tests verifying unbiasedness and MSE improvements.
- Assumptions/dependencies: Community maintainers adopt and review; licensing compatibility; CI across GPU SKUs.
- Sector: HPC/Research Ops
- Use case: Faster ablation studies and hyperparameter sweeps by training more model variants per GPU-hour with stable low-precision training.
- Tools/workflows: Integrate Quartet II into internal research stacks; bake into AutoML sweep controllers; track time-to-result reductions.
- Assumptions/dependencies: Stable behavior across diverse model widths/depths; cluster schedulers that handle new kernels/drivers.
Long-Term Applications
These opportunities require further research, ecosystem maturation, or broader hardware and software support.
- Sector: AI Labs, Foundation Model Providers
- Use case: Trillion-token, 10B–100B+ LLM pre-training primarily in NVFP4 with MS-EDEN across more components (beyond linear layers), achieving near FP8/FP16 quality at substantially lower cost.
- Tools/workflows: Extend unbiased microscaling quantization to attention, norms, and optimizer states; system-level optimizations for memory/throughput.
- Assumptions/dependencies: Empirical stability at very large scales; kernel coverage for all critical ops; new failure modes characterized.
- Sector: Hardware (NVIDIA, AMD, AI ASICs)
- Use case: Native hardware support for stochastic micro-scale updates (e.g., FP8 scale SR) and rotation-friendly tensor operations to eliminate software overhead.
- Tools/workflows: ISA extensions for per-block stochastic scaling; fused RHT matmuls; hardware-level bias-correction primitives.
- Assumptions/dependencies: Vendor roadmaps; standards alignment; silicon area/power trade-offs.
- Sector: Frameworks (PyTorch, JAX, TensorFlow), NVIDIA Transformer Engine
- Use case: First-class integration of MS-EDEN and NVFP4 training graphs—including autotuned rotation group sizes, grid-factor selection, and post hoc range alignment—in mainstream frameworks.
- Tools/workflows: Backend lowering for NVFP4; graph rewrites; quantization-aware optimizers and profilers; unified APIs.
- Assumptions/dependencies: Community demand; maintenance capacity; stability across versions/hardware.
- Sector: Cross-Vendor Ecosystem
- Use case: Vendor-agnostic microscaling unbiased quantization (MS-EDEN variants) for AMD and other accelerators, enabling broader low-precision training.
- Tools/workflows: ROCm-compatible kernels; common quantization spec; test suites for unbiasedness and MSE.
- Assumptions/dependencies: Equivalent microscaling formats; compiler/runtime readiness; investment from vendors.
- Sector: Distributed Training/HPC Networking
- Use case: Apply MS-EDEN-style unbiased quantization to gradient communication (all-reduce) to lower bandwidth without degrading convergence in large clusters.
- Tools/workflows: Integrate with NCCL/UCX; per-bucket rotations and scale SR; end-to-end convergence benchmarks.
- Assumptions/dependencies: Compatibility with ZeRO/tensor/pipeline parallel schemes; stable variance at extreme scales; fault tolerance with randomized rotations.
- Sector: Robotics/Autonomy, Edge AI
- Use case: On-device continual learning or policy/model updates using NVFP4 training for language-conditioned control or perception-LLMs.
- Tools/workflows: Compact models trained incrementally in NVFP4; rotation-friendly kernels for small batch sizes; energy-aware scheduling.
- Assumptions/dependencies: NVFP4-capable edge hardware; memory- and thermally-constrained environments; stability for non-stationary data.
- Sector: Vision/Multimodal Media, Generative Imaging/Speech
- Use case: Extend unbiased microscaling FP4 training to diffusion/vision/speech models to reduce training cost for multimodal foundation models.
- Tools/workflows: Adapt rotations/scale selection to convolutional and attention-heavy multimodal stacks; evaluate task metrics (FID, WER, etc.).
- Assumptions/dependencies: Quantization-friendly distributions in non-text modalities; op coverage for convs/FFT-heavy layers.
- Sector: AutoML/Compiler Tooling
- Use case: Automated selection of grid clipping factor s, rotation group size, and scale policies (“4/6” variants) to optimize speed-accuracy for each layer/model.
- Tools/workflows: Compiler passes that rewrite graphs into NVFP4 forms; profilers that search quantization configs; cost models.
- Assumptions/dependencies: Reliable metrics for trade-offs; standardized APIs to control hardware kernels; reproducible benchmarking.
- Sector: Policy/Regulatory, Sustainability Standards
- Use case: Incorporate low-precision training (e.g., NVFP4 with unbiased gradients) into procurement and sustainability guidelines for public and private AI training.
- Tools/workflows: Benchmarked energy-per-token reporting; compliance checklists; incentives for low-precision adoption in grants/contracts.
- Assumptions/dependencies: Consensus on measurement methodology; stable best practices; sector-specific risk assessments.
- Sector: Commercial Platforms/Products
- Use case: “NVFP4-first” foundation model platforms (training + fine-tune) marketed as lower-cost, lower-carbon alternatives; domain-specific LLM builders for healthcare/finance/legal.
- Tools/workflows: Managed pipelines embedding Quartet II; SLAs for quality relative to FP8/FP16; dashboards for quantization health.
- Assumptions/dependencies: Customer trust in low-precision quality; integration with data governance/PII handling; long-term support and updates.
Notes on Key Assumptions and Dependencies
- Hardware availability: Practical deployment hinges on access to NVIDIA Blackwell GPUs with NVFP4 tensor cores; benefits may not transfer to prior generations without NVFP4 support.
- Kernel maturity: The reported speedups rely on custom kernels (e.g., post hoc range alignment) and QuTLASS; production robustness requires upstreaming and maintenance.
- Training stability at scale: The paper validates up to ~1.9B parameters and 38B tokens; extension to tens of billions of parameters and trillion-token runs requires further evidence and potentially more guardrails.
- Algorithmic constraints: MS-EDEN requires randomized rotations along the inner GEMM dimension and weight re-quantization on the backward pass. Rotation group sizes must align with microscale groups (e.g., 16 within 128), and RHT seeds must match across operands.
- Correctness caveat: “4/6” grid selection is used only in the forward pass (deterministic) because applying it to backward pass would break unbiasedness; pipelines must enforce this separation.
- Data distributions: Extreme outlier patterns can stress FP4 formats; forward-pass scale selection and rotation-based smoothing reduce but may not eliminate such risks; monitoring and selective higher precision may still be needed in rare layers.
- Ecosystem readiness: Broad adoption benefits from integration into mainstream frameworks (Transformer Engine, PyTorch) and cloud offerings; until then, organizations must manage custom builds and updates.
Collections
Sign up for free to add this paper to one or more collections.