- The paper introduces AACR-Bench, a benchmark that improves defect coverage by 285% through AI-assisted and expert-verified annotations.
- It demonstrates the value of repository-level context and multilingual evaluation for enhancing the performance of LLM-based code review systems.
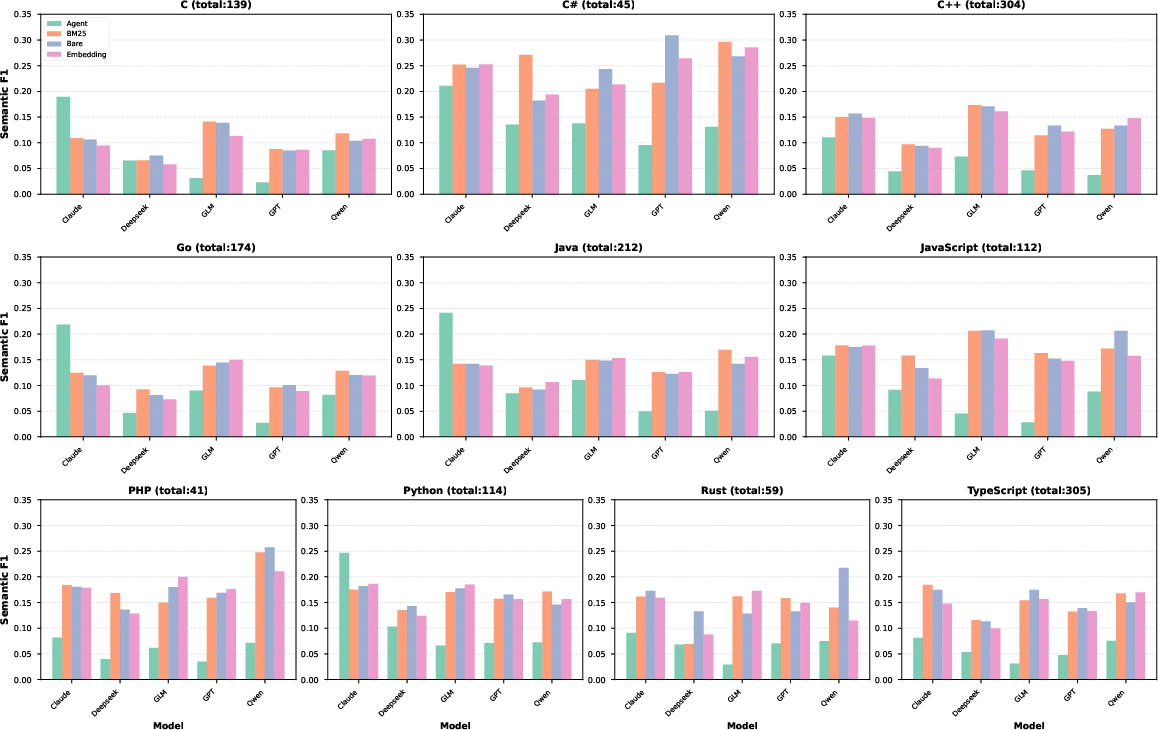
- The benchmark reveals significant language-specific performance variances, emphasizing the need for precise context retrieval and adaptation.
Evaluating Automatic Code Review with AACR-Bench
AACR-Bench represents a novel approach to assessing automatic code review systems, emphasizing the importance of repository-level context and multilingual support. By addressing the limitations of existing benchmarks, AACR-Bench provides an enriched dataset that enhances defect coverage and context awareness, ultimately improving the evaluation of LLMs in Automated Code Review (ACR) tasks.
Introduction
The increasing adoption of LLMs for ACR has highlighted the need for robust evaluation benchmarks capable of accurately assessing their performance. Previous benchmarks have been limited by their lack of support for multiple programming languages and repository-level context, as well as by their reliance on noisy, incomplete ground truth derived from real-world Pull Requests (PRs). AACR-Bench addresses these deficiencies through an "AI-assisted, Expert-verified" annotation pipeline that significantly increases defect coverage, enabling more rigorous evaluations of LLMs.
Construction and Features of AACR-Bench
Multilingual and Context-Aware Benchmark
AACR-Bench is characterized by its support for ten mainstream programming languages and its repository-level context awareness, offering a more realistic and comprehensive environment for evaluating ACR systems.
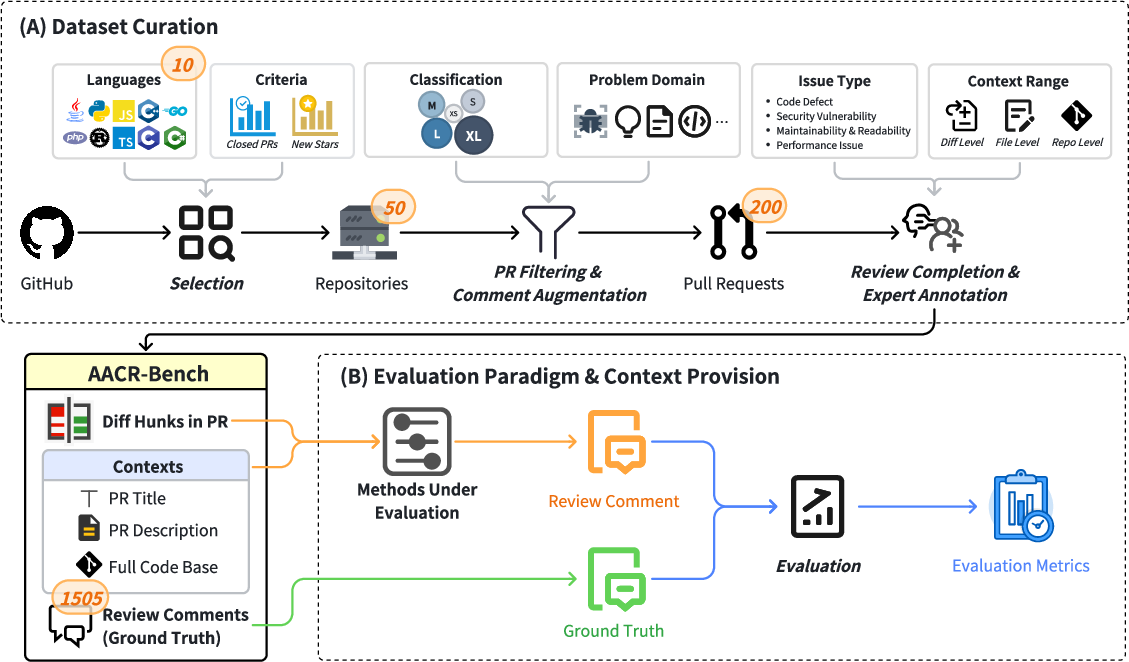
Figure 1: Overview of AACR-Bench. AACR-Bench contains 200 PRs and 1,505 fine-grained review comments extracted and curated from 50 popular repositories, covering 10 mainstream programming languages.
AACR-Bench encompasses 200 PRs and 1,505 review comments, sourced from 50 popular repositories. This benchmark features cross-file and cross-language context, addressing the limitations of previous datasets that have been restricted to specific languages or isolated code fragments.
Advanced Annotation Pipeline
The dataset has been curated using a hybrid approach that involves both AI-assisted and expert-verified annotations, yielding a 285% increase in defect coverage compared to traditional datasets. This process involves the meticulous review and annotation of comments generated by two ACR systems powered by six different LLMs.
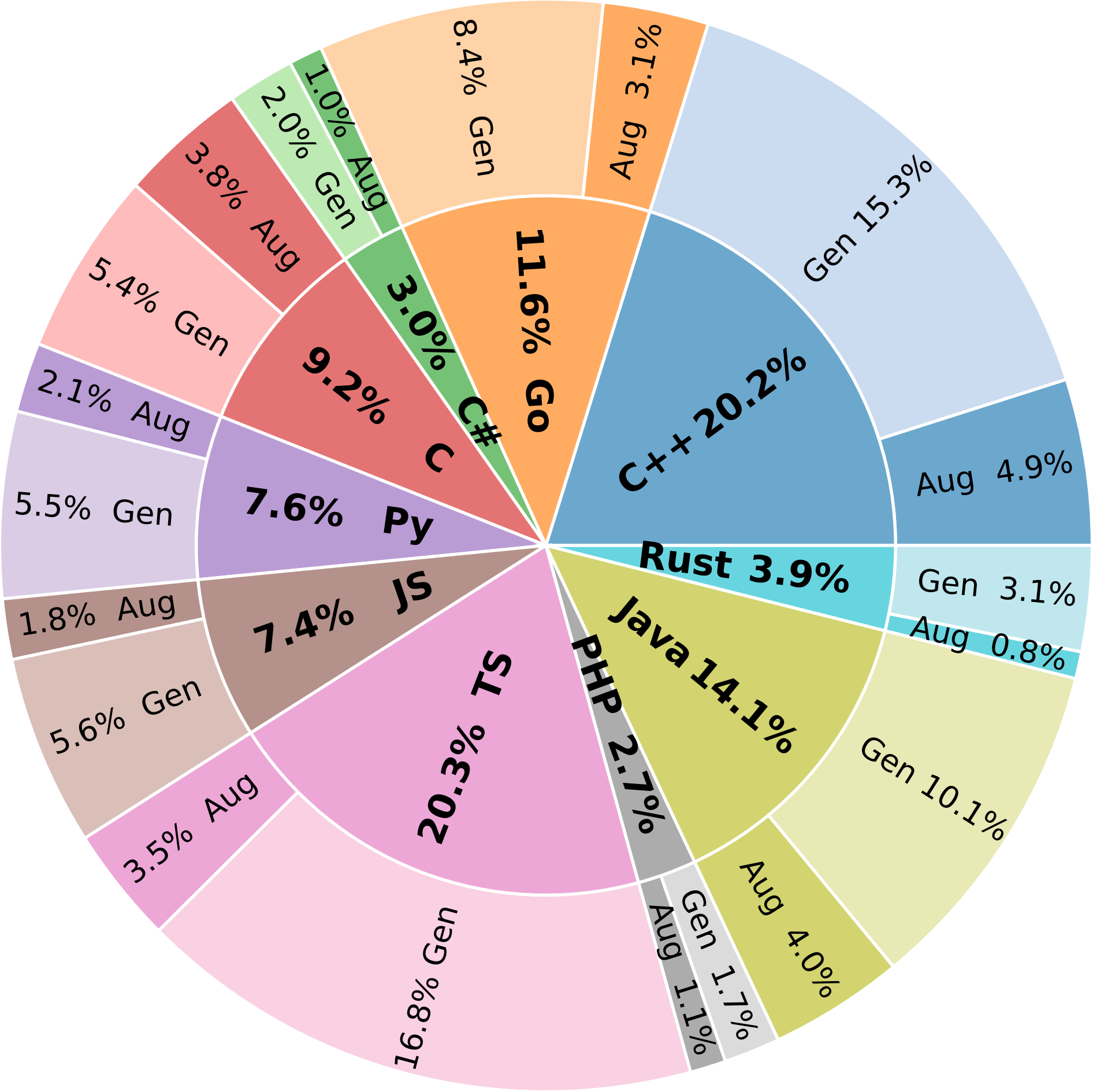
Figure 2: Distribution of Review Comments in AACR-Bench. TS, JS, and Py stand for TypeScript, JavaScript, and Python, respectively. "Aug" denotes comments augmented from original PR reviews, while "Gen" denotes comments generated by the 6 LLMs.
Comparative Analysis with Existing Benchmarks
AACR-Bench offers significant improvements over existing benchmarks by providing repository-level context in a multi-language evaluation environment. Unlike previous benchmarks, AACR-Bench incorporates hybrid model-augmented human reviews, verified through human expert annotation, ensuring comprehensive defect coverage and reliable evaluation.
Experimental Insights
The evaluation of mainstream LLMs and ACR methods on AACR-Bench has revealed important insights:
Conclusion
AACR-Bench sets a new standard for evaluating ACR systems by emphasizing the importance of comprehensive defect coverage and repository-level context. This benchmark provides insights that are crucial for the development of next-generation LLM-based ACR systems, identifying key challenges such as precision-recall trade-offs, context adaptation, and language-specific biases. Future work will focus on expanding the dataset and improving ground truth accuracy through advanced semi-automated methods. AACR-Bench is a vital resource for researchers and developers aiming to optimize the application of LLMs in code review scenarios, driving advancements in AI-assisted software engineering.