- The paper introduces a novel parameterization for transferring hyperparameters from small to large MoE models with scales from 51M to 2B parameters.
- It employs a DMFT-based theoretical framework to maintain stable training dynamics across varying model configurations such as width, depth, and expert count.
- Empirical results show that increasing the number of smaller experts outperforms enlarging expert size, ensuring competitive performance against dense baselines.
Hyperparameter Transfer with Mixture-of-Expert Layers
Introduction
In this study, we propose and analyze a novel parameterization for transformer models incorporating Mixture-of-Experts (MoE) layers. These layers have become increasingly important for scaling neural networks by separating the total trainable parameter count from activated parameters during the forward pass for each token. Despite their benefits, the complexity of training sparse MoEs is heightened due to the need for tuning new parameters, such as router weights, and determining suitable architectural dimensions like the number and size of experts. We aim to address these challenges by introducing a parameterization informed by a new dynamical mean-field theory (DMFT) analysis, enabling reliable hyperparameter transfer across varying model scales from 51M to over 2B total parameters.
Methodology and Theoretical Insights
The cornerstone of our approach is a parameterization that facilitates the transfer of hyperparameters (HPs) from small to large models. This transfer is critical as directly tuning each HP at a large scale is often impractical. Our parameterization is derived based on max-update and CompleteP paradigms, ensuring that components of network pre-activations and residual blocks remain within a stable scale during training. This stability is key for successful HP transfer.
Our theoretical framework leverages DMFT to dissect the training dynamics of residual networks with MoE layers. The analysis unveils a three-level mean-field hierarchy, elucidating how residual stream neurons, expert state variables (such as router preactivations), and within-expert hidden neurons interact and evolve during training. This hierarchical understanding is crucial for parameterizing the scaling of width, depth, expert count, and expert size.
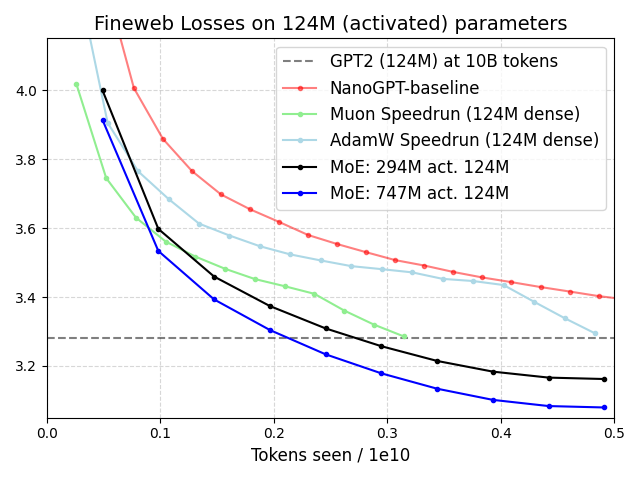
Figure 1: Matching active architecture to be GPT2-small (124M) and 500K batch size, comparison of MoE training loss on our zero-shot Adam HPs (found from tuning 38M activated base models) on FineWeb versus (dense GPT) baseline.
Empirical Validation
Empirically, we validated our parameterization across different datasets and MoE sparsity levels. Our experiments demonstrated consistent HP transfer for both initialization scale and learning rate as we scaled model dimensions like width, depth, expert count, and size while maintaining a fixed token budget of 1B. The transfer capabilities of our parameterization were tested further by scaling HPs found from smaller models to larger ones trained on significantly more tokens. This scaling not only maintained stability but also achieved competitive training loss against dense model baselines.
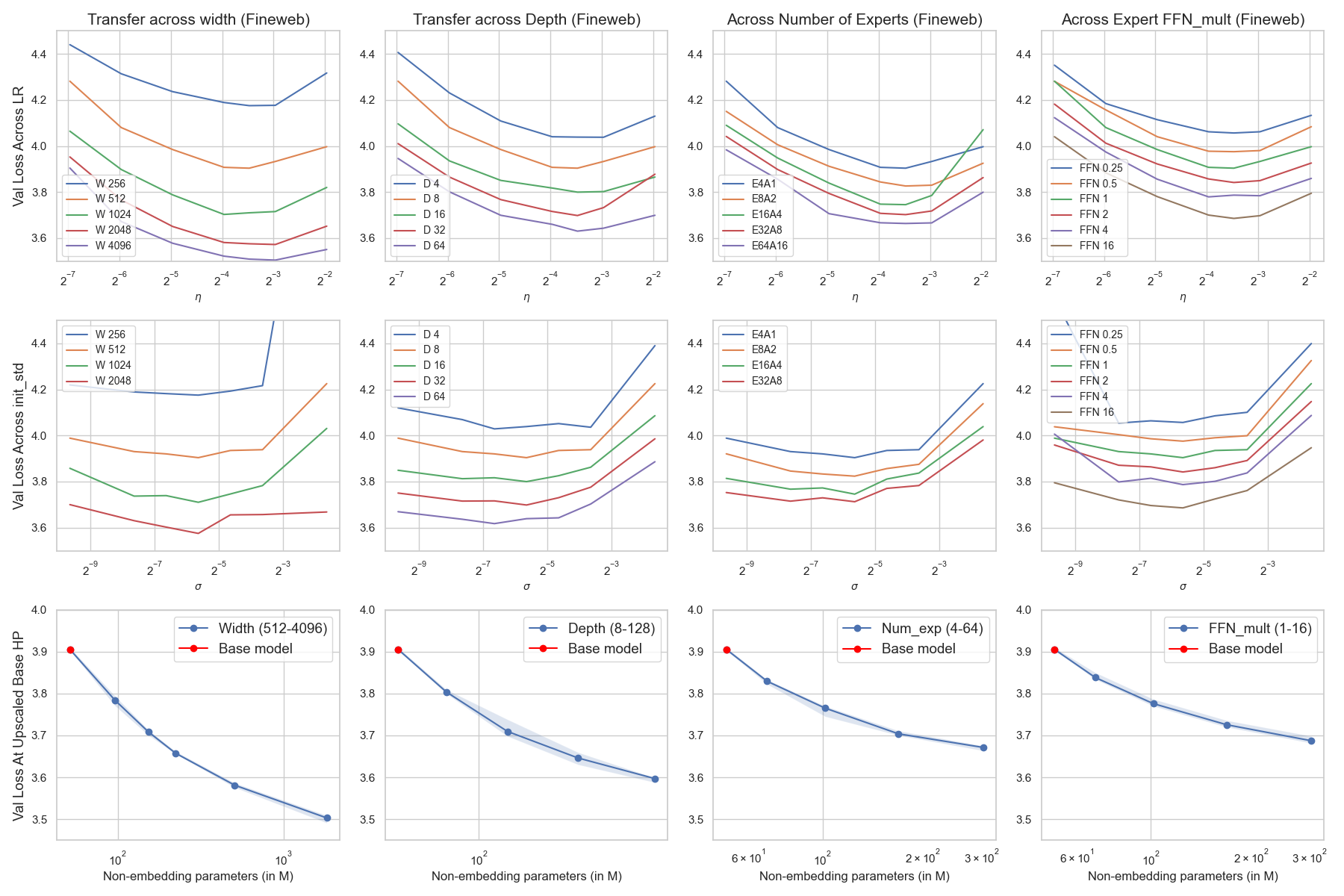
Figure 2: Global base learning rate (first row) and global base init (second row) transfer trained on 1B tokens (2000 steps) on the Fineweb dataset.
Our study provides insights into architectural configurations, specifically the trade-offs between increasing the number of experts and the size of individual experts. With our parameterization, empirical findings supported existing literature suggesting that increasing the number of smaller experts generally yields better model performance compared to enlarging expert size, even when fixing the total parameter count.
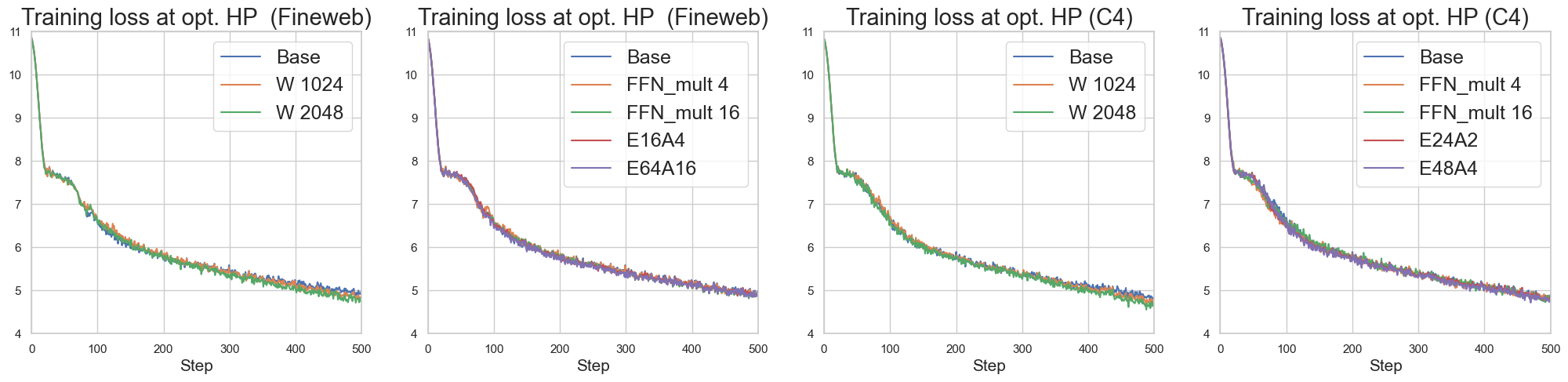
Figure 3: (Finding 1.2): Loss curve collapse (scale invariance) of model scaling dimension (in earlier steps) when scaling up the base model in different ways.
Conclusion
This work extends hyperparameter transfer techniques to sparse MoE models, grounded by a rigorous theoretical analysis via DMFT. The proposed parameterization allows for efficient scaling across multiple model dimensions, proving its effectiveness through extensive empirical validation. Future research directions include exploring hyperparameter transfer for longer training horizons and further examining the intricate interactions of batch size, Adam betas, and learning rate scheduling in large-scale pretraining scenarios. These steps will enhance the practical applicability of scaling laws in Mixture-of-Experts models.
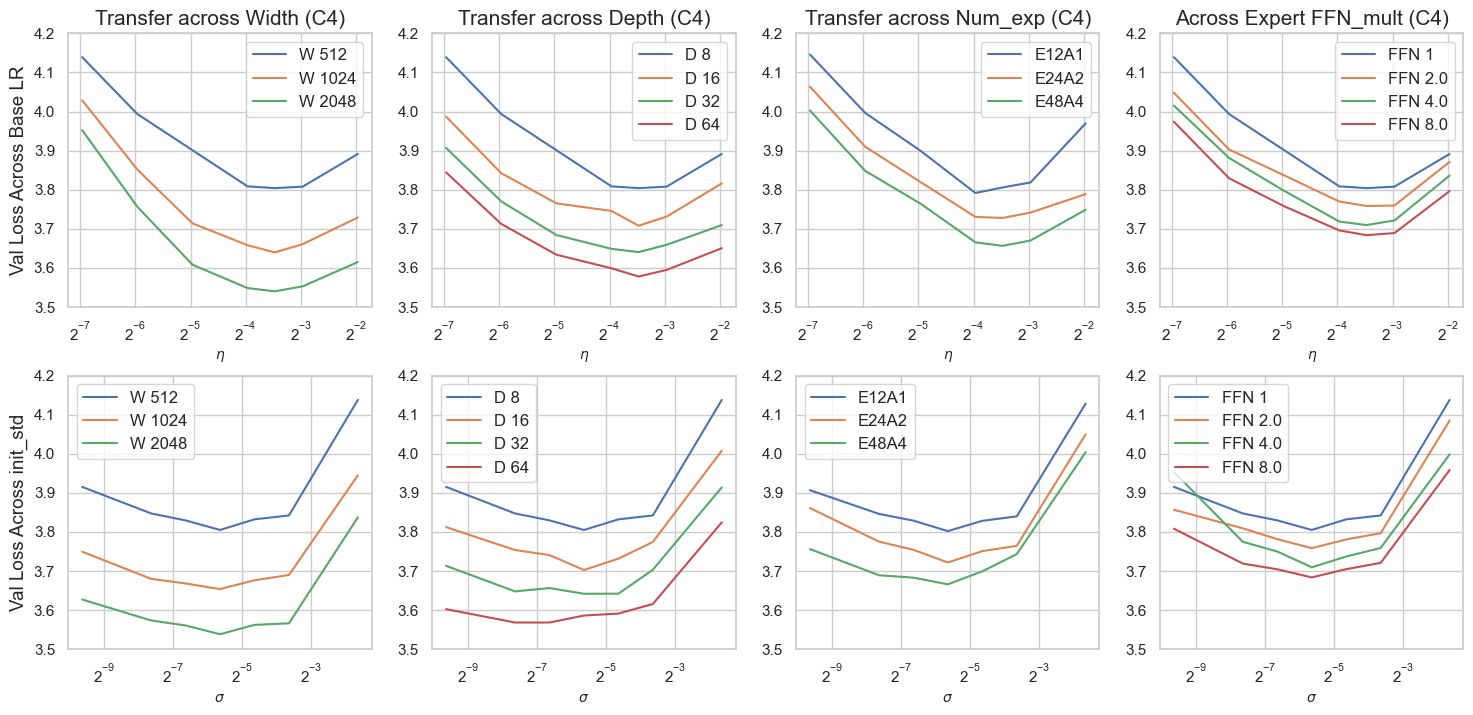
Figure 4: Fixed token transfer of global base LR (row 1) and global base init (row 2) on κ=1/12 and the C4 dataset.