- The paper proposes a knowledge distillation framework, Shallow-π, that reduces transformer layers from 18 to 6 while preserving policy fidelity.
- It integrates task, output, and attention loss functions to jointly compress both the VLM backbone and action head, resulting in over 2× latency reduction.
- Experimental results demonstrate near-teacher performance on LIBERO and robust real-world robotic manipulation compared to alternative compression methods.
Shallow-π: Knowledge Distillation for Flow-based VLAs
Introduction
"Shallow-π: Knowledge Distillation for Flow-based VLAs" (2601.20262) rigorously addresses the challenge of high inference latency in flow-based Vision-Language-Action (VLA) models deployed for robotic manipulation, especially in real-time, on-device settings. Flow-based VLAs, such as π, GR00T, and CogACT, leverage diffusion transformers as action heads, resulting in substantial sequential transformer computation that constrains real-time applicability, particularly for edge devices. The core contribution of the paper is a systematic knowledge distillation framework—Shallow-π—that aggressively reduces transformer depth in both the VLM backbone and the action head, compressing 18 layers to as few as 6, while maintaining policy fidelity across diverse robotic domains.
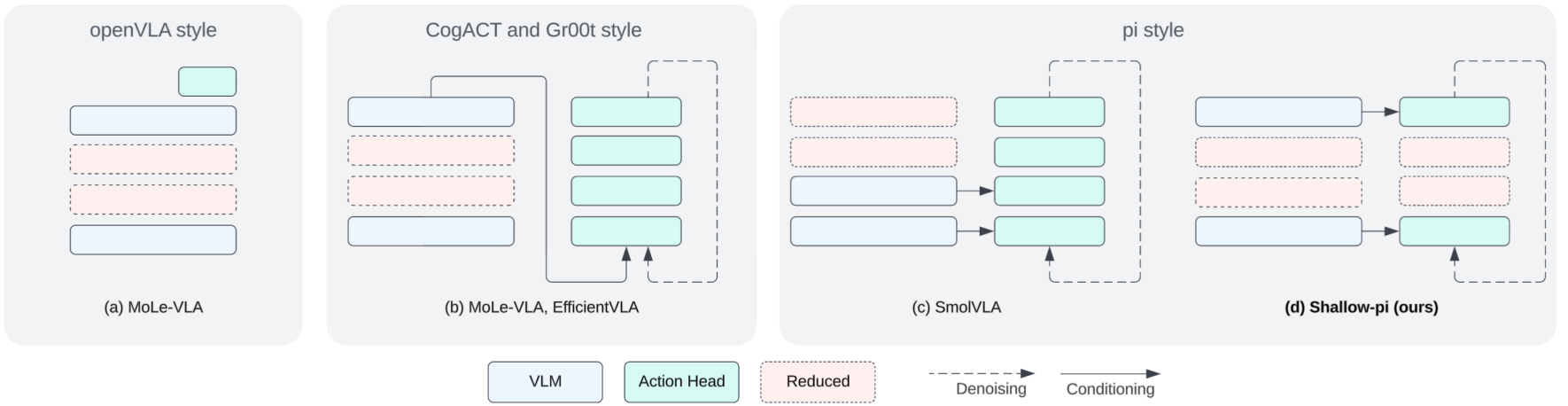
Figure 1: Comparison of layer reduction strategies in VLAs; Shallow-π simultaneously distills both backbone and action head, distinct from prior approaches focusing on backbone-only or dynamic inference skipping.
Technical Approach
Motivation and Analysis of Layer Reduction
The authors critically examine prior acceleration methods for VLAs, including token pruning, diffusion step reduction, layer-skipping via dynamic routing, and backbone size reduction. While token-level parallelization enables visual token pruning to yield modest latency benefits, transformer layers in the backbone and action head remain a major computational bottleneck due to their sequential execution. Empirical profiling demonstrates the dominant impact of reducing transformer depth compared to visual token count on wall-clock inference time for both high-end (H100) and edge (Jetson Orin) hardware.
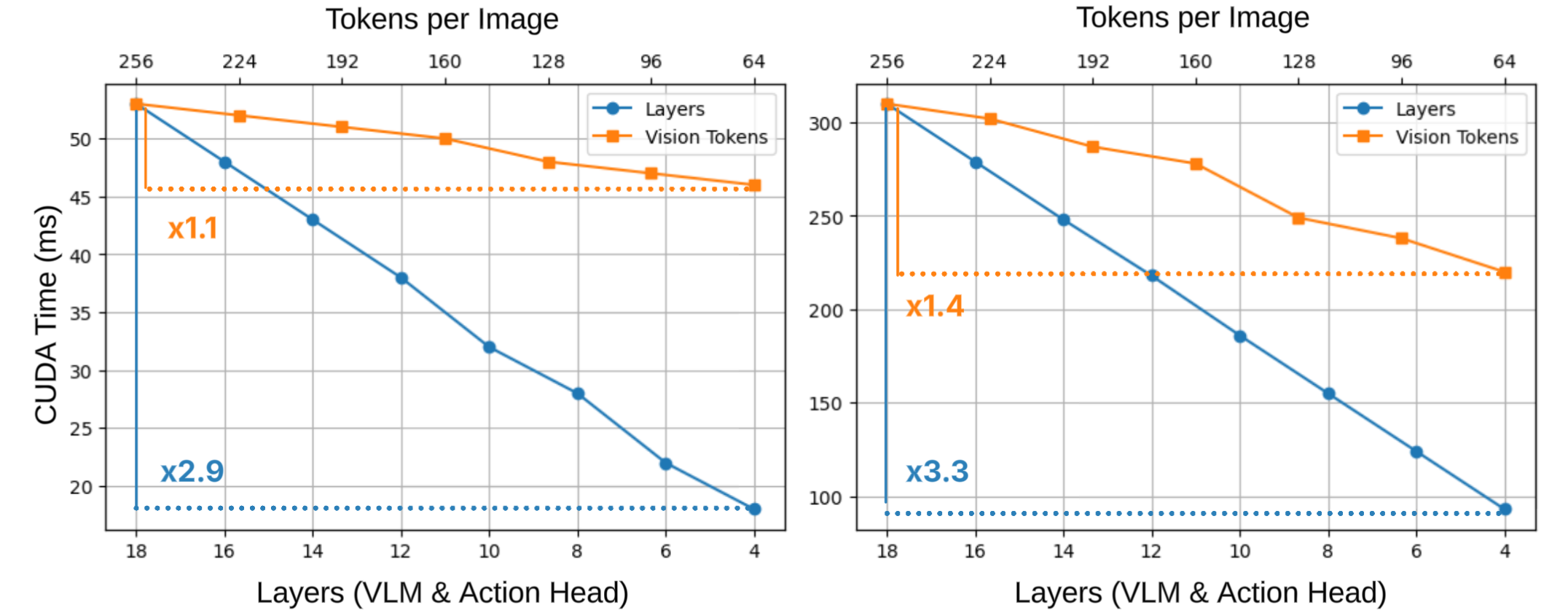
Figure 2: Layer reduction leads to a more significant latency decrease than token count reduction, particularly on modern accelerators.
Layer-skipping methods, rooted in feature similarity or conditional routers, are shown via layer sensitivity analysis to be fundamentally limited in flow-based VLAs: per-layer functional significance varies with diffusion timestep τ, and layer importance is poorly captured by feature similarity, precluding straightforward depth reduction without severe drops in success rate.
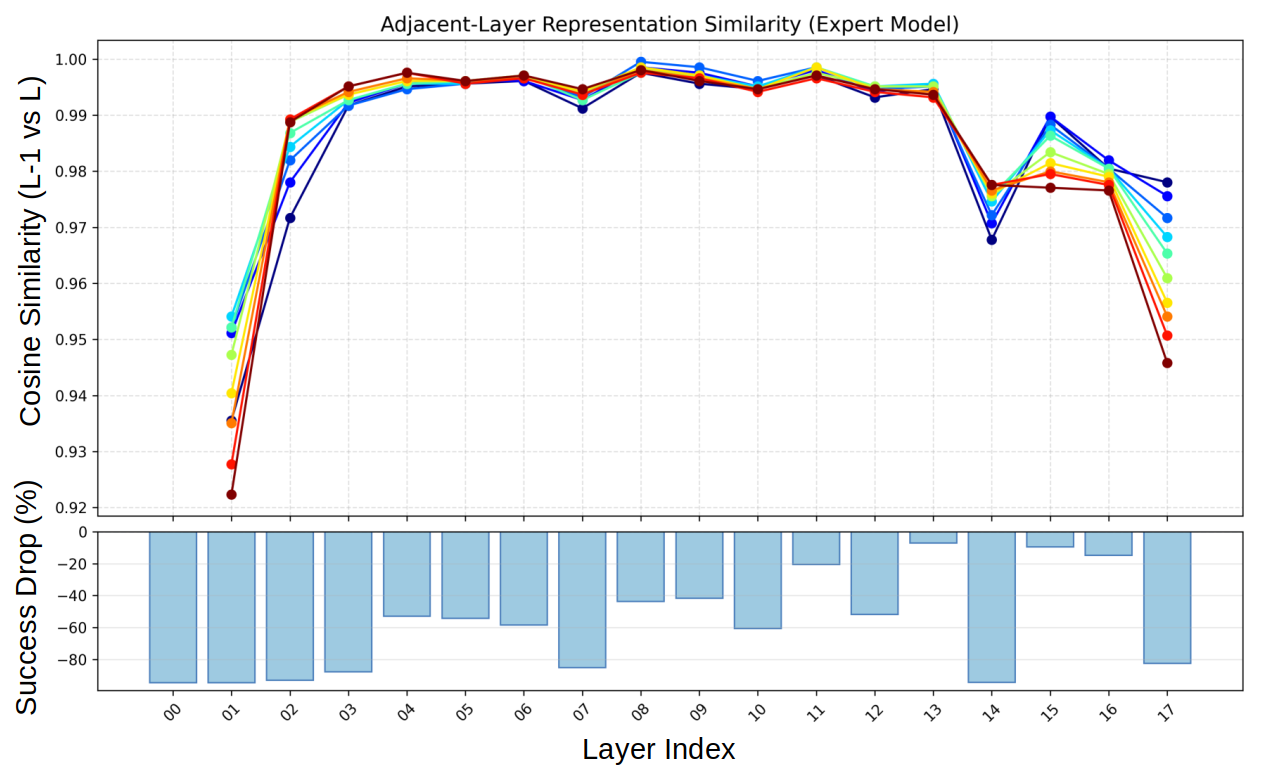
Figure 3: (Top) Feature similarity between transformer layers fluctuates with noise level τ; (Bottom) Skipping layers based on sensitivity or similarity leads to non-trivial success rate drops.
Knowledge Distillation Framework
Shallow-π's framework performs joint layer reduction for both VLM and the action diffusion head through teacher-student distillation. The student is initialized by uniform sub-sampling (TinyBERT-style) of layers from the teacher. Three loss terms are formulated:
- Task loss (Ltask): Standard flow matching objective for ground-truth action velocity.
- Knowledge distillation loss (Lkd): Direct supervision to match the teacher policy on denoising output.
- Attention distillation loss (Lattn): KL alignment of action-to-vision-language cross-attention at an intermediate layer, tailored for π-like VLA architectures where multimodal conditioning is injected layerwise in the action head.
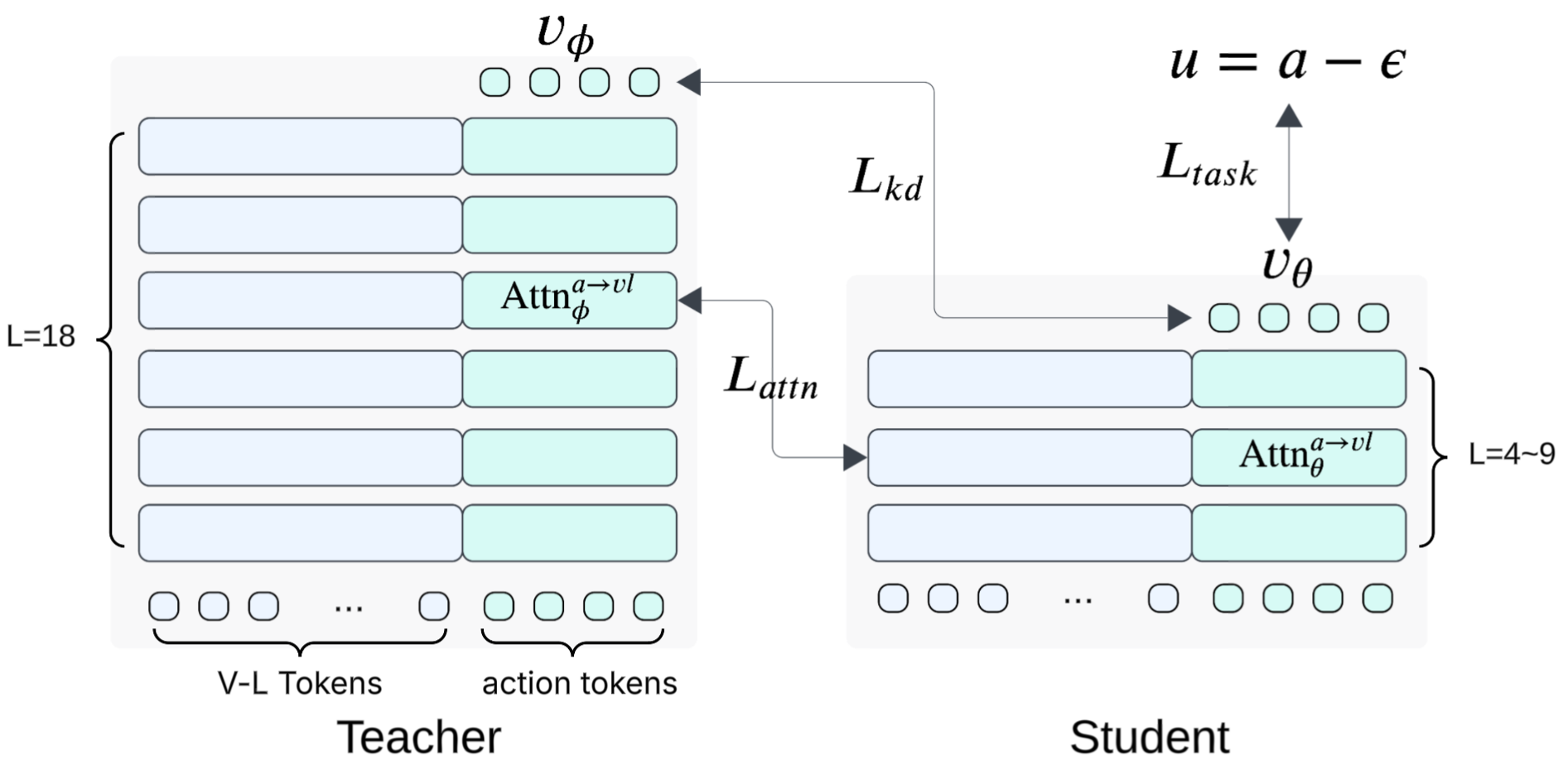
Figure 4: Overview of Shallow-π distillation; student is trained via task, output, and intermediate attention alignment.
Ablations evidence the necessity of all three components, with attention distillation applied exclusively to action tokens at an intermediate layer being both stable and optimal—distilling backbone token attention or applying at early/final layers degrades performance.
Limitation of Layer Skipping and Dynamic Routing
Empirical experiments corroborate that both static and dynamic layer-skipping—by feature similarity or learned routing—fail to robustly compress π architectures without catastrophic loss. Distillation permits aggressive structural model reduction while preserving requisite inter-layer feature transfer for denoising across diffusion steps.
Experimental Results
Simulation (LIBERO)
In large-scale evaluations on the LIBERO benchmark, Shallow-π with 6 layers achieves near-teacher performance, showing less than 1% absolute success rate drop, but over 2× latency reduction compared to baseline π/π0.5 models. Compared to alternative compression approaches, such as SmolVLA (small backbone trained from scratch) and token reduction (e.g., CogVLA, LightVLA), Shallow-π's method provides superior accuracy-computation trade-offs, and compressing both backbone and action head yields dividends in end-to-end deployment latency.
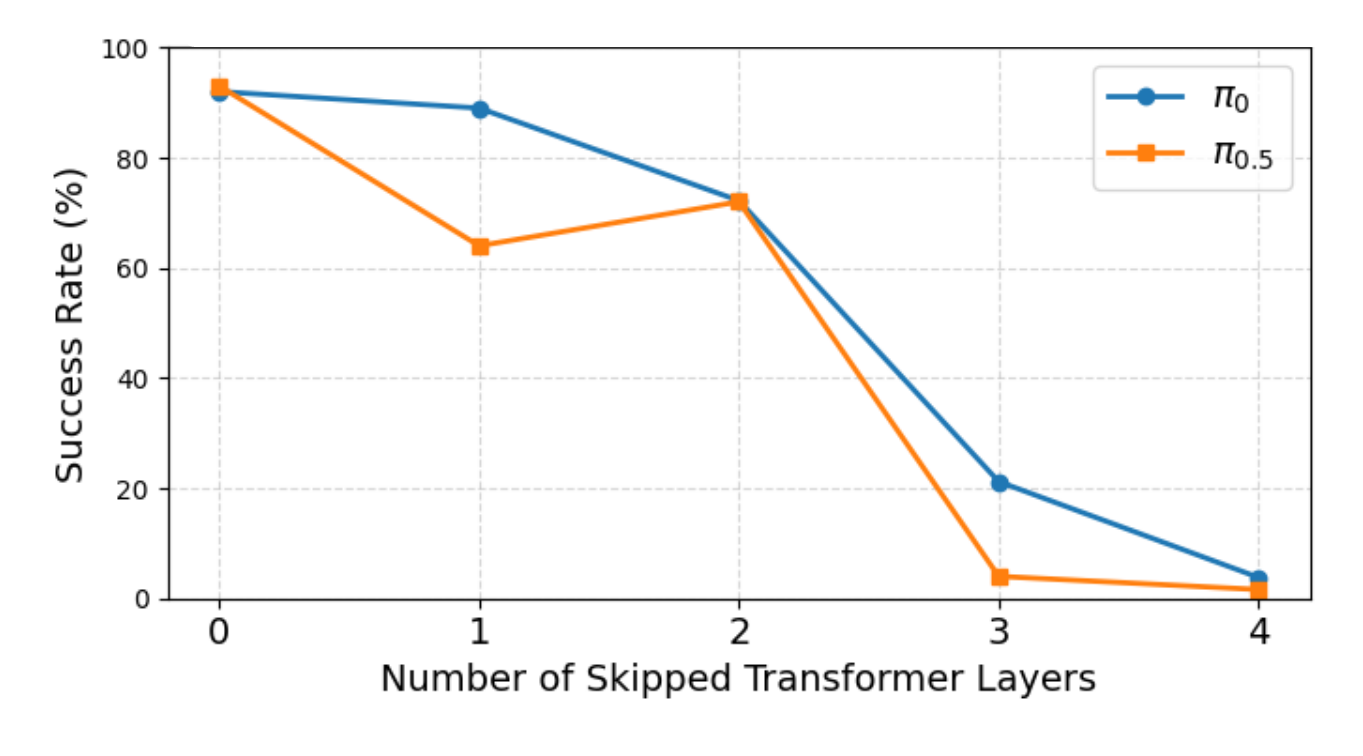
Figure 5: Success rates on LIBERO as a function of skipped transformer layers—substantial degradation observed with naive skipping, highlighting the advantage of structured distillation.
Real-world Edge Deployment
Robustness of Shallow-π is validated across demanding real-robot manipulation tasks on diverse platforms (ALOHA, RB-Y1), spanning dynamic scenes, fine dexterity, and coordinated multi-limb activities. Distilled models, up to 70% shallower than teachers, achieve 10 Hz operation on Jetson-Orin, outperforming both full-size teachers (due to reduction in open-loop control error) and small-from-scratch models (SmolVLA) on manipulation benchmarks. Crucially, open-loop control degradation in slow, large models is mitigated in Shallow-π due to rapid reactive inference.

Figure 6: Experimental task suite spanning complex manipulation and multi-DoF robot configurations, all evaluated on resource-constrained edge hardware.
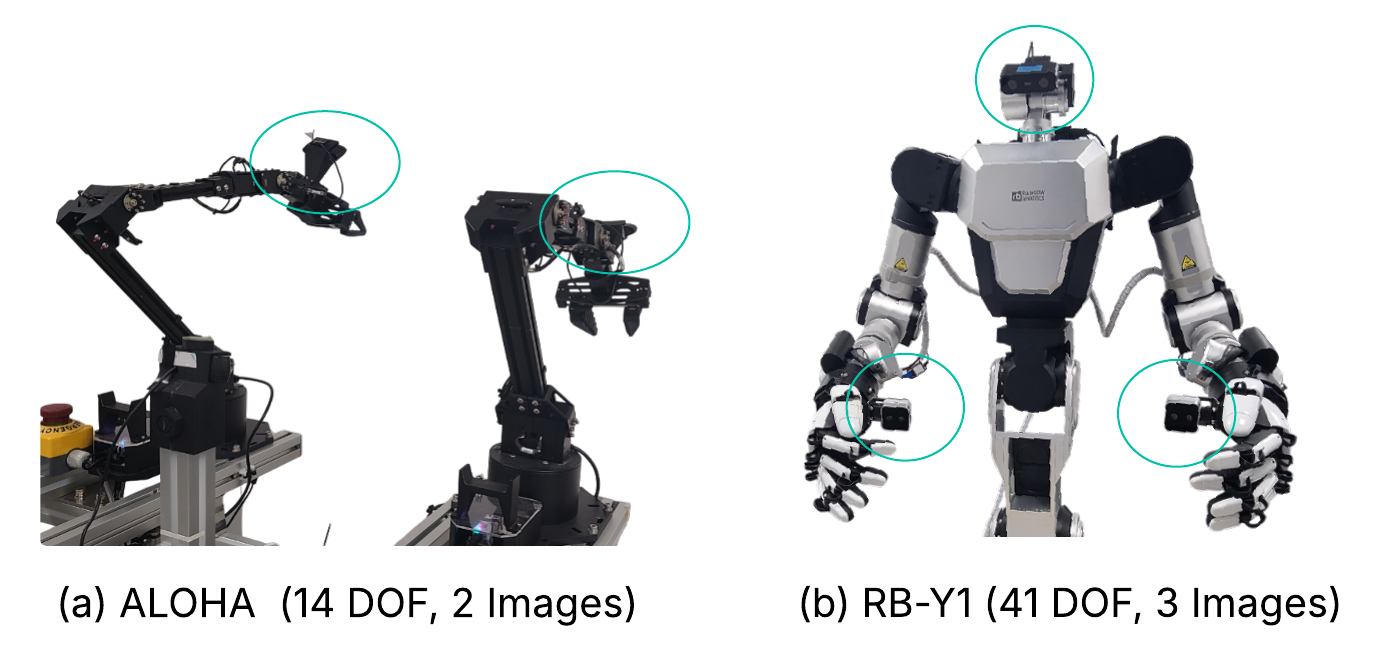
Figure 7: Robots' DoFs and onboard camera placements.
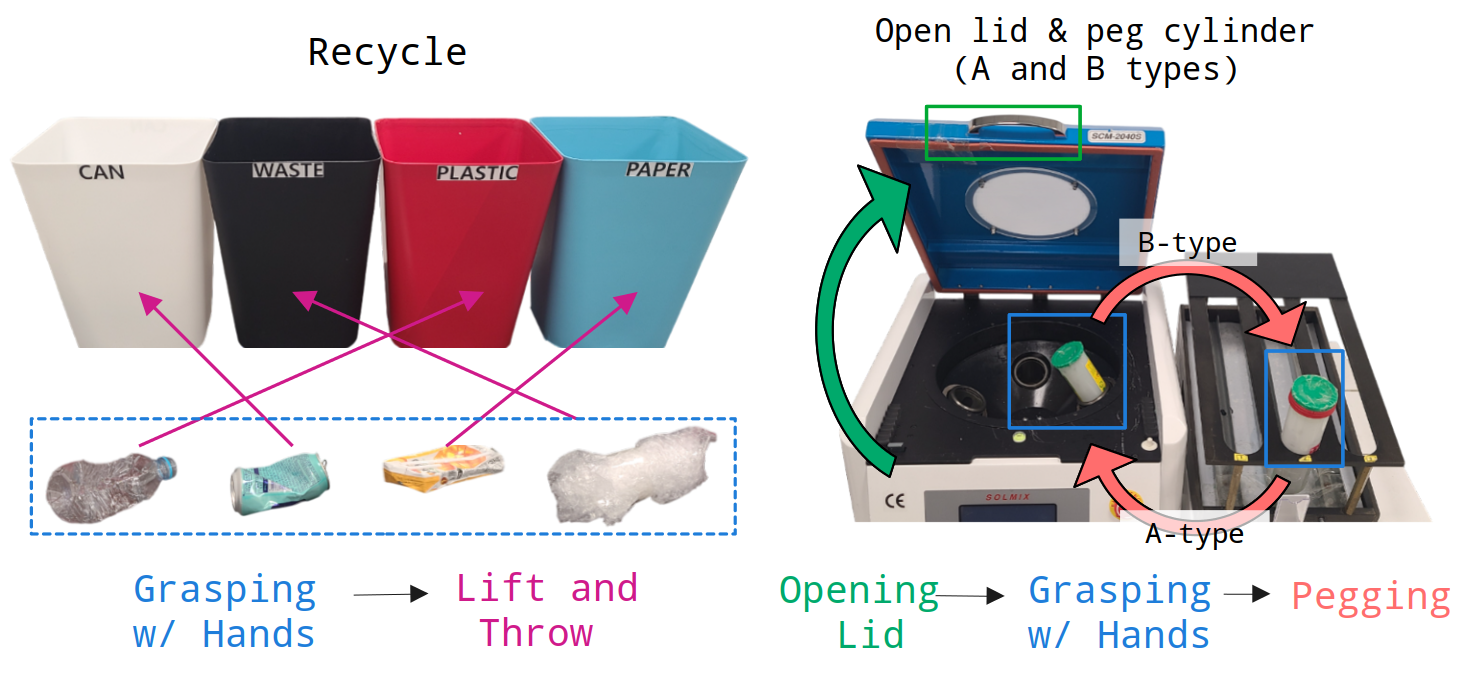
Figure 8: Compositional skill sequence for articulated hand tasks (RB-Y1).
Robustness and Generalization
Distillation in Shallow-π avoids overfitting to the teacher dataset, preserving generalization in unseen spatial configurations and perturbed environments. In contrast to teacher policies that increasingly fail in high-latency, non-reactive regimes, Shallow-π's rapid inference and exposure to diverse attention patterns enables successful adaptation and robust task execution.

Figure 9: Snapshots of open-loop failure in the teacher but robust correction in the student model due to reduced latency and up-to-date observations.
Theoretical and Practical Implications
By conclusively demonstrating that knowledge distillation can compress both backbone and action head in flow-based VLAs—with preservation of inter-layer multimodal conditioning—the work challenges the orthodoxy of backbone-only or dynamic routing-based acceleration, especially in architectures where action head mirrors VLM depth. These results advocate for distillation as the principle mechanism for structural efficiency in policy transformer models, with strong implications for scaling robotic foundation models to real-time, low-power deployment.
Further, the modular loss design (output, task, and targeted attention) sets a template for future distillation in layered, conditional generative architectures. The findings also guide the design of hardware-aware RL/robotic agents, underscoring the marginal value of token-level versus layer-level optimization.
Conclusion
Shallow-π establishes a principled, empirically validated blueprint for aggressive transformer layer reduction in flow-based VLAs through knowledge distillation, achieving substantial computational gains without significant accuracy compromise under real-world robotic constraints. This approach supersedes token pruning and layer-skipping in both practical efficiency and generalization.
Future extensions are anticipated to combine Shallow-π with token/diffusion step reduction, and to explore curriculum- or sample-aware distillation schemes that further minimize trivial data redundancy during compression. The paradigm sets a new operational baseline for deployable generalist robotic policies, advancing both the theoretical landscape and engineering of efficient action-oriented multimodal models.