DeepSeek-OCR 2: Visual Causal Flow
Abstract: We present DeepSeek-OCR 2 to investigate the feasibility of a novel encoder-DeepEncoder V2-capable of dynamically reordering visual tokens upon image semantics. Conventional vision-LLMs (VLMs) invariably process visual tokens in a rigid raster-scan order (top-left to bottom-right) with fixed positional encoding when fed into LLMs. However, this contradicts human visual perception, which follows flexible yet semantically coherent scanning patterns driven by inherent logical structures. Particularly for images with complex layouts, human vision exhibits causally-informed sequential processing. Inspired by this cognitive mechanism, DeepEncoder V2 is designed to endow the encoder with causal reasoning capabilities, enabling it to intelligently reorder visual tokens prior to LLM-based content interpretation. This work explores a novel paradigm: whether 2D image understanding can be effectively achieved through two-cascaded 1D causal reasoning structures, thereby offering a new architectural approach with the potential to achieve genuine 2D reasoning. Codes and model weights are publicly accessible at http://github.com/deepseek-ai/DeepSeek-OCR-2.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “DeepSeek-OCR 2: Visual Causal Flow” in Simple Terms
Overview: What is this paper about?
This paper introduces DeepSeek-OCR 2, a new way to help computers “read” images of documents (like PDFs, textbooks, or forms) more like humans do. Instead of scanning an image from top-left to bottom-right in a fixed order, the model learns to look at parts of the image in a smarter, meaning-driven sequence—similar to how your eyes jump to titles, then figures, then captions when you read a busy page.
Key goals of the research
The authors set out to explore three main ideas:
- Can an image encoder learn to reorder what it “looks at” based on meaning, not just position?
- Can a 2D image be understood well by using two 1D steps in a row: first reorder the image parts sensibly, then read them like a sentence?
- Can we keep the model efficient (processing fewer pieces) while still improving accuracy on complex documents?
How it works (in everyday language)
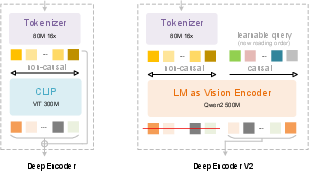
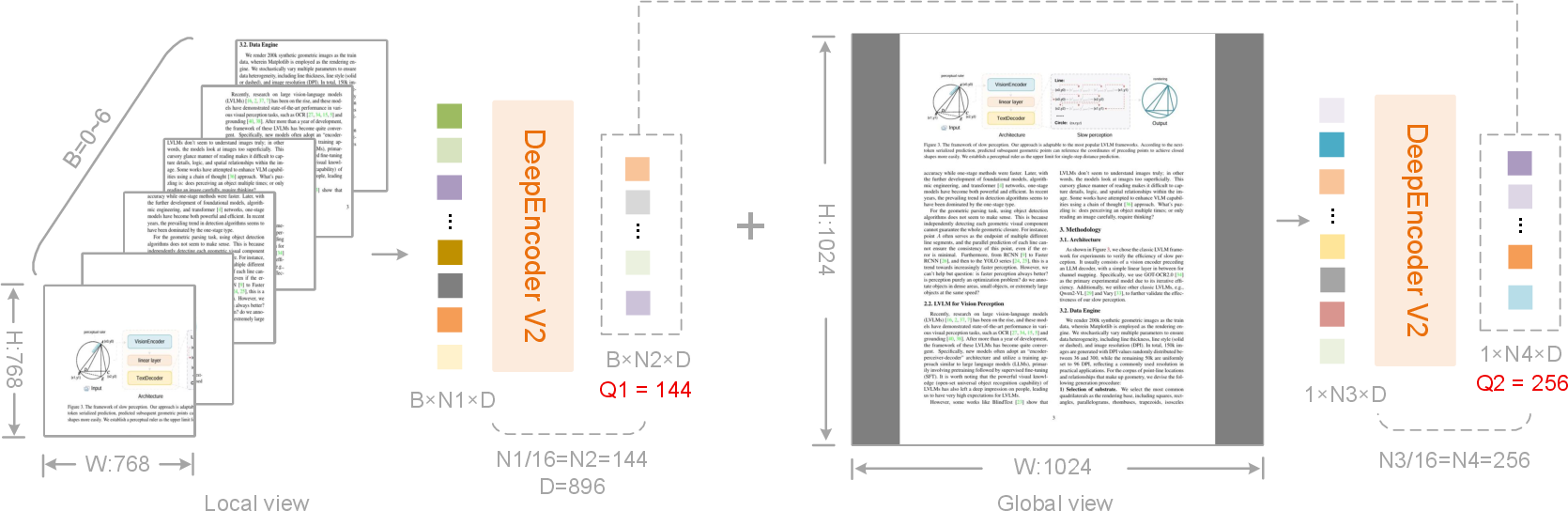
Think of a document image as being cut into many small tiles—like tiny sticky notes. Each sticky note is a “visual token.” Most models read all the sticky notes in a fixed order. DeepSeek-OCR 2 changes that by adding a smart “guide” that picks a better order to read them.
Here’s the basic idea:
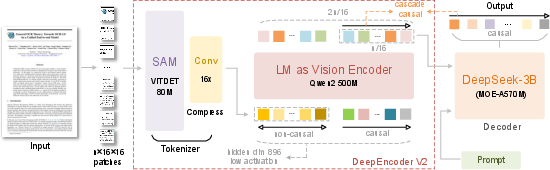
- The image is first compressed into fewer, richer tokens (imagine grouping nearby sticky notes into meaningful clusters). This keeps the model fast.
- The model then adds a set of “learnable queries.” You can think of these as smart pointers that decide which tokens to pay attention to next. These queries learn the best order to read the image based on meaning—like scanning a page from the title to the subtitle, then to the main text, then to figures.
- Two attention rules are used:
- Visual tokens have “everyone-can-see-everyone” attention. This lets the model understand the whole image at once.
- Query tokens have “look-back-only” attention (causal attention), like reading a sentence where each word depends on the ones before it. This helps the model build a step-by-step reading order.
- Only the reordered query outputs are then sent to the LLM to generate the final text or structure (like reading order, tables, or formulas).
- The model uses both a global view (the whole page) and up to six local close-ups (for tricky sections), producing between 256 and 1120 tokens per image—small enough to be efficient but large enough for detail.
Training happens in three simple stages:
- Teach the encoder to extract and compress visual features and learn reordering.
- Strengthen the queries so they reorder even better and compress knowledge more effectively.
- Freeze the encoder and fine-tune the LLM part for speed and stability.
Main findings: What did they achieve?
The team tested DeepSeek-OCR 2 on a well-known benchmark called OmniDocBench v1.5, which includes many types of documents in different languages. They also measured real-world performance in production.
Key results at a glance:
- Higher accuracy: Overall score improved to 91.09%, up by 3.73% from their previous model (DeepSeek-OCR).
- Better reading order: The model made fewer mistakes in the order of content (Edit Distance dropped from 0.085 to 0.057), meaning it’s better at reading documents the way humans do.
- Efficiency maintained: It uses at most 1120 visual tokens—fewer than many other systems—and still performs strongly.
- Real-world reliability: In production logs, repeated or duplicated outputs decreased (e.g., from 6.25% to 4.17% on user images), showing cleaner, more consistent results.
- Competitive under similar limits: With a similar token budget, it showed better document parsing consistency than some large commercial systems on certain metrics.
Why this matters:
- Smarter reading order means fewer jumbled outputs and more accurate extraction of text, tables, and formulas.
- Efficient token use means faster, cheaper processing without sacrificing quality.
Why is this approach important?
- It makes image understanding more human-like: What the model looks at next depends on what it just saw (cause-and-effect), not just where things are on the page.
- It bridges 2D images and 1D language: By reordering image parts into a meaningful sequence, the LLM can “read” images more naturally.
- It keeps models practical: Fewer tokens and smart compression mean less compute and memory, which helps in real-world systems.
What could this lead to next?
- Better document tools: More accurate OCR for homework, forms, textbooks, and scientific papers—especially those with complex layouts, formulas, and tables.
- Unified multi-skill models: The same “learnable query” idea could be applied to other data types (like audio and text), moving toward a single encoder that handles many kinds of input.
- Stronger 2D reasoning: The authors suggest that two 1D reasoning steps (reordering, then reading) could be a path toward deeper visual understanding. Future improvements might include more local views for very dense pages and longer query sequences for multiple passes over the same content.
In short, DeepSeek-OCR 2 shows that teaching a model to choose a smart reading order—before turning images into text—can make document understanding both more accurate and more efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of what remains missing, uncertain, or unexplored in the paper, phrased so that future researchers can act on it:
- Lack of rigorous evidence for “causal reordering”: no quantitative metric is provided to measure how much the learned order deviates from raster order or aligns with ground-truth reading order (e.g., Kendall’s τ, normalized edit distance between learned sequence and annotated reading sequences, or a formalized LCP-based metric).
- Missing interpretability analyses of causal flow tokens: no layer-wise visualizations, attention rollout, or token-trace audits showing stable, semantically coherent scanpaths across pages, seeds, and perturbations.
- No ablation on the custom attention mask: the paper does not isolate the contribution of the block mask design versus standard bidirectional or decoder-only masks, or test partial variants (e.g., allowing limited feedback from queries to visual tokens).
- Query count design is unvalidated: equal cardinality between queries and visual tokens is assumed; there is no sweep over query-to-vision ratios (fewer, equal, more) to establish scaling laws or to validate the “re-fixation” rationale.
- Unexplored multi-hop reordering: authors hypothesize needing longer query sequences for multiple re-examinations but do not test increased query length, multi-round query passes, or iterative refinement schedules.
- Cross-attention (mBART-style) “failure to converge” is only hypothesized: no systematic investigation of training instabilities, hyperparameter sweeps, architectural tweaks, or optimization remedies is presented.
- Token budget limitations are unresolved: newspapers and text-dense pages degrade under the 1120-token cap; adaptive token budgets, learned crop policies, or token-pruning/gating strategies are not explored.
- Limited domain coverage: evaluation is almost exclusively on OmniDocBench; generalization to natural images, DocVQA/ChartQA/TextVQA, scene text, charts, diagrams, and complex layouts beyond documents is untested.
- Multilingual and script diversity are insufficiently assessed: performance on non-Latin scripts, right-to-left languages (e.g., Arabic), vertical text (e.g., Japanese), and mixed-script pages is not reported; reading-order conventions across scripts are not studied.
- Robustness to real-world artifacts is unquantified: skew, rotation, occlusion, low resolution, handwriting/marginalia, stamps, and noisy scans are not stress-tested.
- No fine-grained error analysis: failure modes for formulas (e.g., structure, spacing, baseline alignment), tables (cell segmentation, spanning, nested headers), and inline math within text are not dissected.
- Contribution disentanglement is missing: improvements could come from data mix changes, tokenizer choice (SAM-based), multi-crop strategy, or the LLM-style encoder itself; controlled ablations are not provided.
- Training objective may be suboptimal for ordering: next-token prediction is used without auxiliary supervision (e.g., explicit reading-order labels, permutation prediction losses, contrastive ordering, or RL based on order metrics); the impact of such objectives remains unknown.
- Sensitivity to LLM initialization is unexplored: only Qwen2-0.5B is used as the encoder; effects of different pretrained LLMs, freezing strategies, and catastrophic forgetting of language capabilities are not analyzed.
- Encoder–decoder interaction is one-way: the mask forbids vision tokens attending to queries; the benefits of bidirectional exchange, alternating refinement layers, or iterative encoder–decoder loops are not evaluated.
- Spatial geometry fidelity is not validated: while semantics-driven ordering is emphasized, tasks requiring precise 2D geometry (e.g., table cell coordinates, layout graphs) are not benchmarked under strict geometric metrics.
- Compute and latency trade-offs are underreported: there is no detailed comparison of FLOPs, memory, throughput, and latency versus CLIP-ViT baselines or competing OCR/VLM systems under matched accuracy and token budgets.
- Generalization to multi-page context is unaddressed: cross-page references, consistent reading order across long documents, and global layout reasoning over document-length sequences are not studied.
- Crop policy is heuristic and static: there is no learned cropping/region proposal policy, content-adaptive windowing, or end-to-end optimization of crop placement and count.
- Alternative tokenizers are not compared: the SAM-based tokenizer is retained; the effects of simple patch embeddings, different compression ratios (e.g., 8× vs 16×), and tokenizer backbones on reordering quality and accuracy are untested.
- Head-to-head comparisons with query-based baselines are absent: no direct evaluation versus Q-former-style projectors, DETR-like query decoders, or learned 2D positional schemes at matched parameter counts and tokens.
- Stability and reproducibility are unclear: variance across random seeds, training runs, and data shuffles is not reported; convergence diagnostics and failure cases are not documented.
- Impact on LLM pretraining pipelines is unmeasured: although proposed as a data engine, there is no empirical study showing that OCR 2 outputs improve downstream LLM pretraining or instruction-tuning quality.
- Hallucination and factuality are not evaluated: beyond repetition rate, there is no assessment of hallucinated text/structure under constrained or ambiguous inputs, or under adversarial layouts.
- Readability–compression frontier is uncharted: systematic exploration of the accuracy–token trade-off (e.g., Pareto curves across token budgets, crops, query counts) is missing.
- Lack of open, detailed training recipes: precise data curation, filtering, annotation standards for reading order, and hyperparameter settings needed for faithful reproduction are not fully specified.
- Multimodal unification remains speculative: the claim that the same encoder can handle audio/text via modality-specific queries is not supported by experiments on speech or text-as-vision streams.
- Determinism and scanpath consistency are unknown: how stable the learned ordering is under minor visual perturbations, randomized augmentations, or different decoding temperatures is not quantified.
- Safety and privacy aspects of document OCR are not discussed: risks in processing sensitive documents (e.g., PII handling, watermarking, redaction robustness) are not addressed.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with the current DeepSeek-OCR 2 model and workflow, leveraging its causal visual flow encoder, 16× token compression, 256–1120-token budget, and demonstrated gains in reading order, tables, and formulas.
- Finance, Insurance, Legal — High-precision document conversion and data extraction
- What: Convert contracts, invoices, bank statements, claims, and regulatory filings into structured JSON/CSV with accurate reading order, tables, and formulas.
- Tools/workflows: “Flow-Order OCR SDK” or cloud API; batch PDF-to-structured pipelines; connectors to ERP/ETL.
- Assumptions/dependencies: Best on CN/EN; dense/newspaper-like layouts may need more local crops; PII/PHI governance and human-in-the-loop for compliance.
- Software/AI (RAG, LLMOps) — Layout-aware ingestion for retrieval and grounding
- What: Preprocess PDFs/images into semantically ordered text blocks, tables (CSV), and formulas (LaTeX) to reduce hallucinations and improve answer grounding in RAG.
- Tools/workflows: “Layout-aware RAG preprocessor”; embeddings per section/table; attach provenance spans.
- Assumptions/dependencies: Token budget of 1120 per page; content chunking strategy required for multi-page documents.
- Academia & Publishing — Scientific content digitization
- What: Extract LaTeX equations, figure/table metadata, and reading order from papers, dissertations, and reports; convert to Markdown/LaTeX/TEI.
- Tools/workflows: “Paper-to-LaTeX/Markdown” converter; publisher-side ingestion and copyediting assistants.
- Assumptions/dependencies: High-quality scans preferred; domain formatting variance may require minor post-processing rules.
- Public Sector & Policy — Records and forms processing
- What: Digitize and structure government forms, permits, and public records while preserving logical reading order for auditability and accessibility.
- Tools/workflows: “e-Records Pipeline” with PDF/UA tagging and section-level indexing.
- Assumptions/dependencies: Privacy controls, lineage tracking, and accessibility standards (e.g., PDF/UA) integration.
- Healthcare (admin side) — Claims and billing ingestion
- What: Extract structured data from HCFA/CMS forms, EOBs, and prior-authorization documents; normalize tables and reading order for downstream adjudication.
- Tools/workflows: Claims OCR microservice; rules engines/EDI translators downstream.
- Assumptions/dependencies: Restrict to administrative docs (not clinical imaging); HIPAA-compliant deployment; domain fine-tuning recommended.
- Education — Digitization of textbooks, exam papers, and worksheets
- What: Convert course materials to structured, reflowable formats with preserved order, tables, and equations for e-learning platforms.
- Tools/workflows: “Textbook-to-HTML/EPUB” pipeline; LMS ingestion plugins.
- Assumptions/dependencies: Multicolor/illustrated textbooks supported; complex multi-column layouts may benefit from increased crops.
- Accessibility (A11y) — Reading order and tagging for screen readers
- What: Generate logical reading order and semantic tags to improve screen reader navigation of complex PDFs.
- Tools/workflows: Auto-tagging to PDF/UA; ARIA role mapping in HTML exports.
- Assumptions/dependencies: QA recommended for critical documents; integration with existing A11y toolchains.
- Data Engineering — High-throughput pretraining data generation for LLMs
- What: Produce lower-duplication, higher-fidelity text from large PDF/image corpora for LLM pretraining (demonstrated lower repetition rate).
- Tools/workflows: Scalable PDF farms; dedup and quality scoring; versioned data lake writes.
- Assumptions/dependencies: GPU-backed inference; throughput tuning with crop strategy and batching.
- Cloud/SaaS — Cost-efficient OCR APIs with strict token budgets
- What: Offer OCR as a service delivering strong quality with ≤1120 visual tokens, reducing compute costs and latency.
- Tools/workflows: Stateless REST/gRPC APIs; autoscaling; usage-based billing.
- Assumptions/dependencies: GPU availability; SLAs for latency; robust monitoring for out-of-domain layouts.
- Energy & Utilities — Bill and meter-report ingestion
- What: Extract structured fields and tables from utility bills and consumption reports for analytics and customer portals.
- Tools/workflows: “Bill-to-CSV” ETL; anomaly detection on extracted values.
- Assumptions/dependencies: Template variance across providers may require light rules or few-shot tuning.
- Productivity Suites — PDF-to-Doc/Sheet plugins
- What: Convert PDFs to editable docs with accurate reading order; export tables to spreadsheets and equations to MathML/LaTeX.
- Tools/workflows: Office suite add-ins or desktop apps; “Export to Sheets/Markdown/LaTeX.”
- Assumptions/dependencies: UI polish and conflict resolution for ambiguous layout interpretations.
- Compliance/KYC/AML — Evidence ingestion and normalization
- What: Normalize documents for case management (IDs, statements, filings) with better ordering for case review and audit trails.
- Tools/workflows: Case ingestion pipelines; audit logs with source coordinates.
- Assumptions/dependencies: Human oversight for critical approvals; secure, on-prem deployment options.
Long-Term Applications
These concepts require additional research, scaling, or engineering—e.g., longer causal-flow sequences, broader modality coverage, domain adaptation, or edge deployment.
- Software/AI — Unified omni-modal encoder
- What: Extend the LLM-style encoder to native multimodality (images, audio, text) via modality-specific queries for unified token compression.
- Potential products/workflows: “Omni-Encoder SDK” for cross-modal retrieval, summarization, and streaming.
- Assumptions/dependencies: Training on multi-domain multimodal corpora; scheduler and memory optimizations for mixed modalities.
- General 2D Reasoning — Multi-hop causal reading across pages
- What: Scale causal flow tokens and reasoning to multi-page documents with re-examination loops and cross-page linking (figures ↔ references ↔ appendices).
- Potential products/workflows: Document agents that plan reading strategies and build knowledge graphs from long reports.
- Assumptions/dependencies: Longer sequences, memory-augmented decoding, and benchmarks beyond single-page OCR.
- Edge/Mobile/AR — On-device causal-order reading assistants
- What: Real-time, privacy-preserving reading on phones or smart glasses with semantic ordering (e.g., navigation of forms or signage).
- Potential products/workflows: AR overlays; offline OCR for accessibility.
- Assumptions/dependencies: Model distillation/quantization; hardware accelerators (NPU); latency targets <100 ms per view.
- Healthcare (clinical) — Structured extraction from clinical reports and embedded tables
- What: Robust extraction from diverse report templates, including pathology and radiology text with tables/measurements.
- Potential products/workflows: EHR ingestion pipelines; cohort-building tools.
- Assumptions/dependencies: Domain adaptation with clinical corpora; strict privacy/security; clinical validation.
- Scientific QA & Data Science — Deep chart/table reasoning
- What: Couple the encoder with chart/table QA to support hypothesis extraction and program synthesis from tables (e.g., auto-generating analysis code).
- Potential products/workflows: “Doc-to-Notebook” assistants; BI connectors that convert tables to SQL-ready schemas.
- Assumptions/dependencies: Enhanced training on ChartQA/tabular reasoning; error analyses and safety checks for decision support.
- Robotics & Operations — Panel/manual understanding for procedure guidance
- What: Apply causal visual flow to read control panels, schematics, and manuals in sequence to guide maintenance or assembly.
- Potential products/workflows: “Procedure-following” copilots; AR checklists.
- Assumptions/dependencies: Robustness to lighting/occlusion; multimodal fusion with sensor data; safety certifications.
- Legal & Policy Analytics — Long-document compliance agents
- What: Agents that ingest regulations/contracts, maintain clause order and dependencies, and produce structured compliance maps.
- Potential products/workflows: Regulatory monitoring dashboards; clause trackers.
- Assumptions/dependencies: Verified traceability to source spans; jurisdictional variation handling; human review loops.
- Multilingual & Low-Resource Scripts — Expansion beyond CN/EN
- What: Extend reading-order and structure gains to scripts with complex layouts (e.g., Arabic, Devanagari).
- Potential products/workflows: Globalized OCR services; localization toolchains.
- Assumptions/dependencies: Training data coverage; script-specific layout priors and evaluation.
- Document Reflow & Authoring — Intelligent PDF/UA authoring and repair
- What: Automatic generation or repair of logical structure, tags, and alt texts during authoring to ensure accessibility and reflow.
- Potential products/workflows: “Smart PDF Author” plugins with structure validation.
- Assumptions/dependencies: Authoring-tool integration; standardized tagging policies and QA.
- Self-Improving Data Engines — Closed-loop labeling and curriculum
- What: Use the model to bootstrap higher-quality supervision (less duplication, better ordering) for continual pretraining of LLMs/VLMs.
- Potential products/workflows: Auto-curation platforms with feedback loops from downstream tasks.
- Assumptions/dependencies: Data governance and dedup pipelines; monitoring of model-induced biases.
Notes on feasibility and dependencies across applications:
- Compute/throughput: Benefits from 16× compression and ≤1120-token budget; GPU-backed inference likely required at scale.
- Quality bounds: Paper shows strong gains but notes weaknesses on extremely dense layouts (e.g., newspapers) that may require more local crops or domain tuning.
- Integration: Best results when paired with downstream LLMs/RAG systems that exploit preserved reading order and structure.
- Governance: Many sectors (finance, healthcare, public) need privacy, auditability, and human-in-the-loop validation.
Glossary
- AdamW: An optimizer for training neural networks that decouples weight decay from the Adam updates to improve generalization. "We use the AdamW~\cite{AdamW} optimizer with cosine learning rate decay from 1e-4 to 1e-6,"
- autoregressive reasoning: A generation process where each step depends only on previously generated elements in sequence order. "the LLM decoder performs autoregressive reasoning over the ordered sequence."
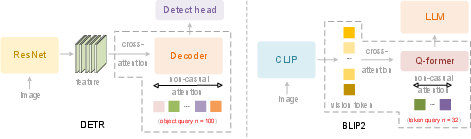
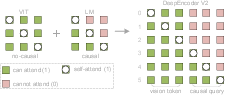
- bidirectional attention: An attention pattern where tokens can attend to both earlier and later tokens in the sequence. "The left region applies bidirectional attention (similar to ViT) to original visual tokens, allowing full token-to-token visibility."
- block causal attention mask: A structured attention mask combining a fully visible block and a causal (triangular) block to control information flow. "M \in {0,1}{2n \times 2n} is the block causal attention mask defined in Equation~\ref{enq1},"
- causal attention: A unidirectional attention mask where each token can only attend to previous tokens to preserve causal ordering. "learnable queries adopt causal attention."
- causal query tokens: Learnable tokens appended to the sequence that impose and learn a causal ordering over visual features. "the number of causal query tokens equals the number of visual tokens,"
- causal reasoning: Inferring cause-effect or logical progression to guide the order in which information is processed. "endow the encoder with causal reasoning capabilities, enabling it to intelligently reorder visual tokens"
- cross-attention: An attention mechanism where a query sequence attends to a different key/value sequence to fuse information across streams. "via cross-attention mechanisms,"
- decoder-only architecture: A Transformer setup that uses only a (causally masked) decoder stack without a separate encoder. "The decoder-only architecture with prefix-concatenation of visual tokens proves crucial:"
- document OCR: End-to-end extraction of textual and structural content from document images. "that make document OCR an ideal platform for validating our approach."
- Edit Distance (ED): A metric measuring how many insertions, deletions, or substitutions are needed to transform one string into another. "the Edit Distance (ED) for reading order (R-order) has also significantly decreased"
- encoder-projector-LLM paradigm: A VLM pipeline where an encoder produces visual tokens, a projector maps them into the LLM space, and the LLM performs reasoning. "with architectures converging toward the encoder-projector-LLM paradigm."
- foveal fixations: High-acuity gaze points in human vision, analogous to focused tokens in models. "foveal fixations function as visual tokens, locally sharp yet globally aware."
- FLOPs: Floating point operations; a hardware-agnostic measure of computational cost. "enabling higher data throughput under the same FLOPs."
- global receptive fields: The ability of tokens to aggregate information from the entire image rather than local regions only. "visual tokens maintain global receptive fields,"
- inductive bias: Built-in assumptions of a model that shape how it interprets input data. "Directly flattening image patches in a predefined raster-scan order introduces unwarranted inductive bias that ignores semantic relationships."
- learnable queries: Trainable vectors that query feature maps via attention to extract or reorganize information. "we introduce learnable queries~\cite{carion2020end}, termed causal flow tokens,"
- lower triangular matrix: A matrix with nonzero entries on and below the main diagonal used to enforce causal masking. "and denotes a lower triangular matrix (with ones on and below the diagonal, zeros above)."
- mBART-style encoder-decoder: A sequence-to-sequence architecture with a distinct encoder and decoder, as in mBART. "extra experiments with cross-attention in an mBART-style~\cite{liu2020multilingual} encoder-decoder structure fail to converge."
- Mixture-of-Experts (MoE): An architecture that routes inputs to a subset of specialized expert networks to increase capacity efficiently. "including Mixture-of-Experts (MoE) architectures,"
- multi-crop strategy: Processing multiple image crops at predefined resolutions to control token counts and capture local details. "we adopt a multi-crop strategy with fixed query configurations at predefined resolutions."
- omni-modal encoding: A unified encoding framework that handles multiple modalities (images, audio, text) within one architecture. "a promising pathway toward unified omni-modal encoding."
- pipeline parallelism: Distributing consecutive model stages across different devices to scale training. "We adopt 4-stage pipeline parallelism:"
- positional encodings: Additive or multiplicative signals that provide token position information to Transformers. "positional encodings (e.g., RoPE~\cite{su2021roformer})."
- prefix-concatenation: Concatenating one sequence in front of another so they are processed jointly within a single transformer stack. "prefix-concatenation of visual tokens proves crucial:"
- projector (VLM): A module that maps visual features into the LLM’s embedding space for multimodal alignment. "The projector aligns visual tokens with the LLM's embedding space,"
- Q-former: A query-driven transformer used to compress visual tokens before feeding them to an LLM. "Q-former utilizes 32 learnable queries"
- raster-scan order: Processing image patches in fixed top-left to bottom-right sequence regardless of semantics. "process visual tokens in a rigid raster-scan order (top-left to bottom-right)"
- Rotary Position Embedding (RoPE): A positional encoding technique that rotates query/key vectors to encode relative positions. "positional encodings (e.g., RoPE~\cite{su2021roformer})."
- self-attention: An attention mechanism where tokens attend to other tokens within the same sequence to aggregate context. "Both employ bidirectional self-attention among queries."
- sequence packing: Concatenating multiple sequences to utilize long context windows efficiently during training. "with sequence packing at 8K length,"
- token compression: Reducing the number of tokens while preserving salient information to lower computation. "it achieves 16 token compression"
- two-stage cascade causal reasoning: Using causal ordering in the encoder followed by causal decoding to decompose complex reasoning. "two-stage cascade causal reasoning"
- ViT (Vision Transformer): A transformer architecture for images that treats patches as tokens. "similar to ViT"
- vision tokenizer: A front-end module that converts images into discrete visual tokens for transformer processing. "The first component of DeepEncoder V2 is a vision tokenizer."
- vision-LLMs (VLMs): Models that jointly process visual and textual inputs for multimodal understanding. "architectural design of vision-LLMs (VLMs),"
- visual causal flow: The causally guided sequence in which visual information should be processed for coherent understanding. "to achieve visual causal flow;"
- visual token budget: The maximum number of visual tokens allowed for an image in a model or benchmark. "matches Gemini-3 pro's maximum visual token budget."
- visual tokens: Discrete representations of image patches used as the basic units for transformer processing. "The encoder discretizes images into visual tokens,"
- window attention: An attention scheme restricted to local windows to reduce complexity while capturing local structure. "through window attention with minimal parameters,"
Collections
Sign up for free to add this paper to one or more collections.