PaddleOCR-VL-1.5: Towards a Multi-Task 0.9B VLM for Robust In-the-Wild Document Parsing
Abstract: We introduce PaddleOCR-VL-1.5, an upgraded model achieving a new state-of-the-art (SOTA) accuracy of 94.5% on OmniDocBench v1.5. To rigorously evaluate robustness against real-world physical distortions, including scanning, skew, warping, screen-photography, and illumination, we propose the Real5-OmniDocBench benchmark. Experimental results demonstrate that this enhanced model attains SOTA performance on the newly curated benchmark. Furthermore, we extend the model's capabilities by incorporating seal recognition and text spotting tasks, while remaining a 0.9B ultra-compact VLM with high efficiency. Code: https://github.com/PaddlePaddle/PaddleOCR
Summary
- The paper presents a compact 0.9B VLM integrating PP-DocLayoutV3 and a NaViT-style encoder for robust document parsing under diverse distortions.
- It achieves high accuracy (94.5% on OmniDocBench and 92.05% on Real5-OmniDocBench) through joint optimization and a distortion-aware augmentation pipeline.
- The method notably improves segmentation and reading order prediction, demonstrating superior performance against traditional, larger-scale models.
Multi-Task Vision-Language Modeling for Robust Document Parsing: PaddleOCR-VL-1.5
Introduction
PaddleOCR-VL-1.5 advances ultra-compact document-centric vision-language modeling by simultaneously delivering high accuracy, robust generalization under unconstrained real-world scenarios, and expanded multi-task capabilities. Existing document parsing models have often been constrained by their optimization for clean, "digital-born" documents while exhibiting marked brittleness against physical distortions such as warping, illumination variation, skew, and screen-capture artifacts. This paper addresses these limitations by proposing architectural, algorithmic, and data-centric enhancements within a streamlined 0.9B parameter framework, culminating in clear state-of-the-art results across synthetic and real-world benchmarks (2601.21957).
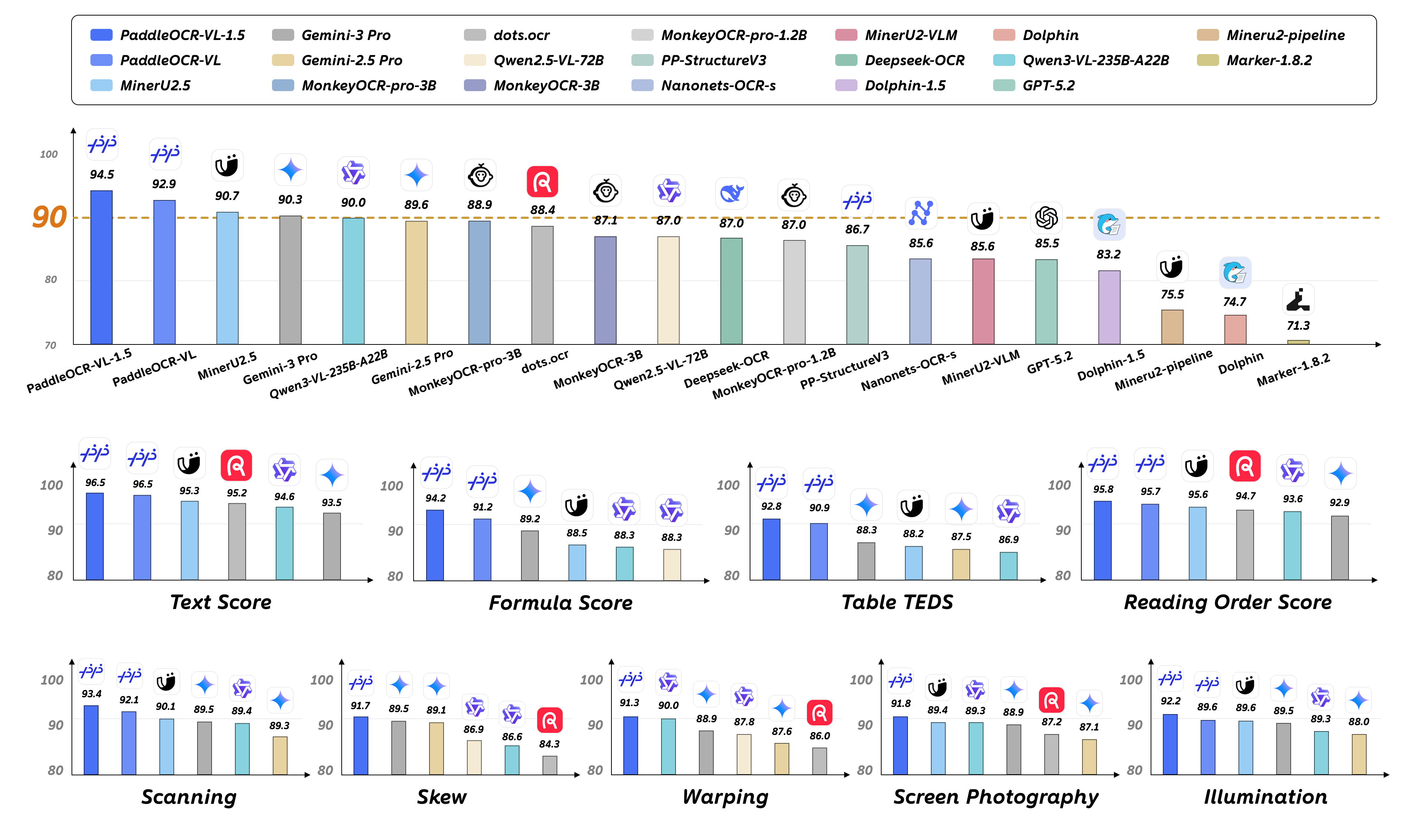
Figure 1: PaddleOCR-VL-1.5 sets new SOTA on both OmniDocBench v1.5 and the physically distorted Real5-OmniDocBench.
Model Architecture and Algorithmic Enhancements
PaddleOCR-VL-1.5 integrates two core modules: PP-DocLayoutV3 for layout analysis and a dynamic NaViT-style visual encoder coupled with ERNIE-4.5-0.3B for multimodal element recognition and text spotting.
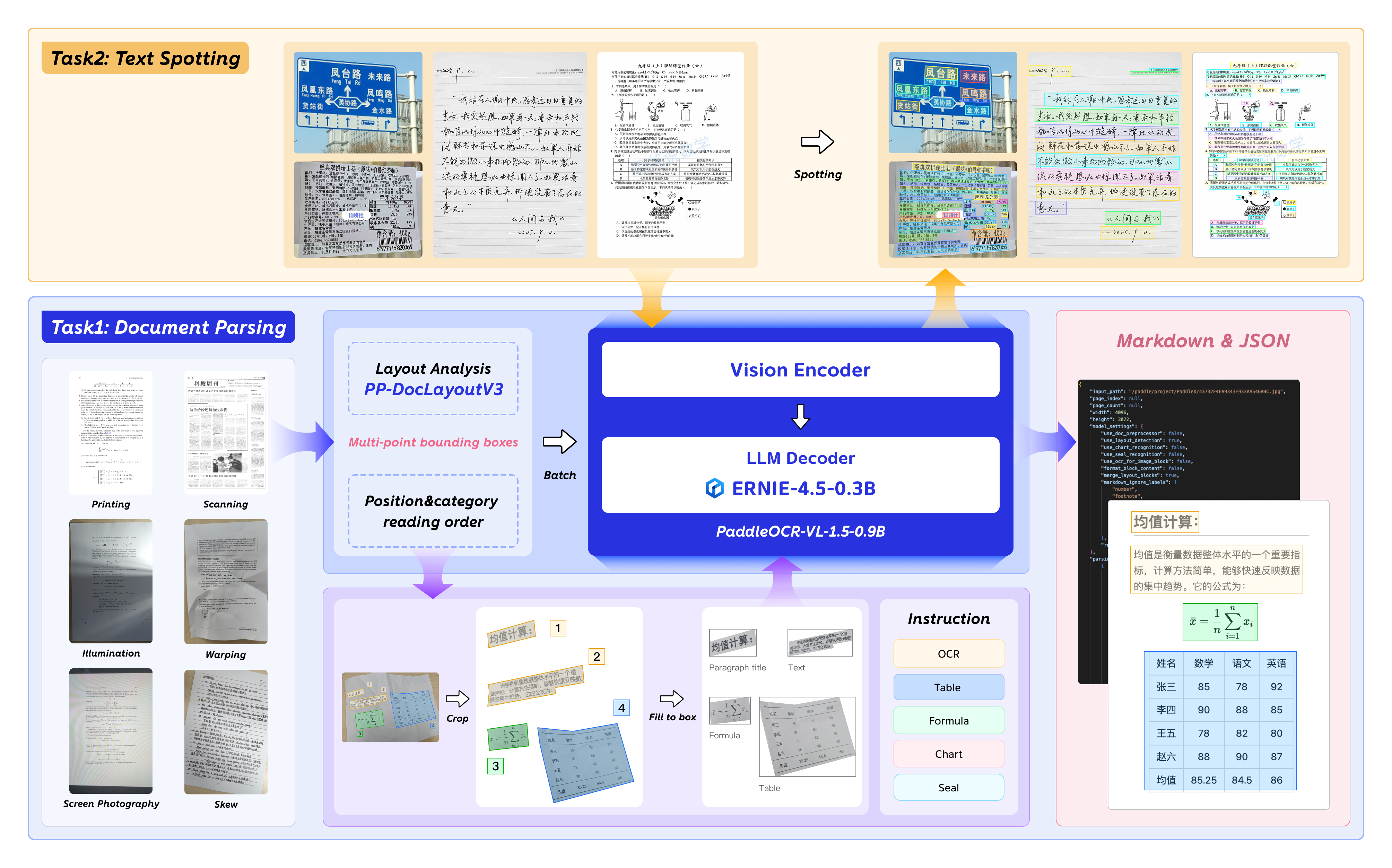
Figure 2: Schematic of the multi-task vision-language architecture of PaddleOCR-VL-1.5.
PP-DocLayoutV3
PP-DocLayoutV3 is a unified instance segmentation and reading order prediction module, specifically engineered to overcome non-planar and non-axis-aligned deformations. Unlike traditional box-based detection, PP-DocLayoutV3 outputs pixel-accurate element masks and computes sequence relations in a Transformer query space using an anti-symmetric pairwise scoring function. The final reading order is derived via vote-based ranking on sigmoid-activated scores, ensuring global logical consistency even in severely warped or skewed layouts.
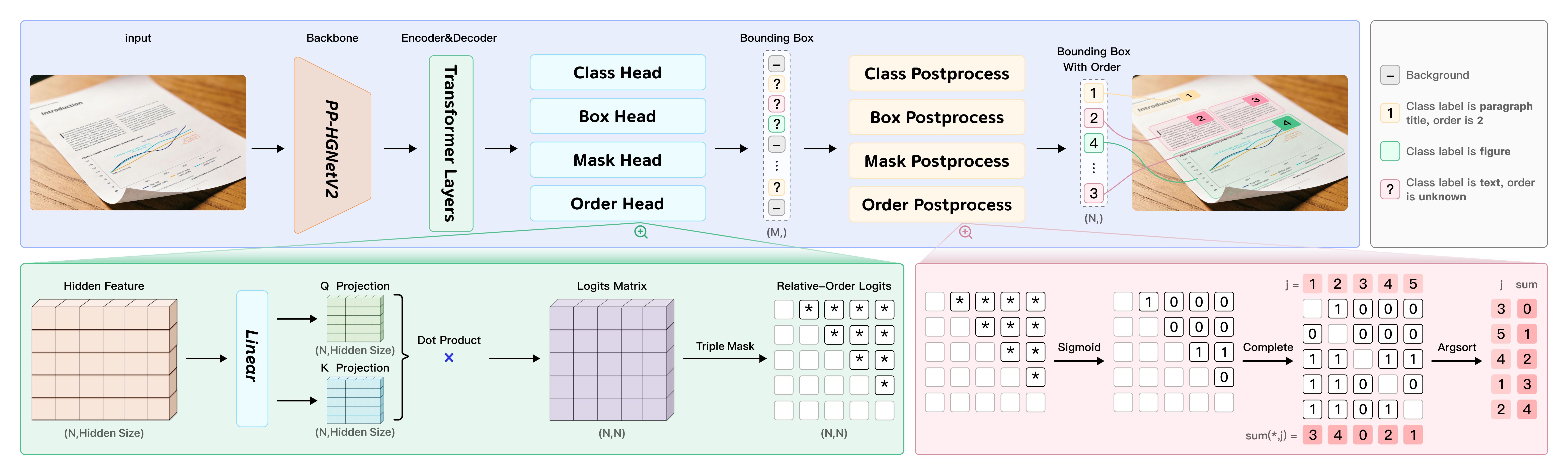
Figure 3: The unified architecture of PP-DocLayoutV3, with integrated instance segmentation and reading order prediction.
This end-to-end architecture fuses detection, segmentation, and ordering into a single forward pass, dramatically reducing error cascades and latency compared to multi-stage or autoregressive VLMs.
PaddleOCR-VL-1.5-0.9B Visual LLM
The vision-language module specializes in OCR, formula, table, chart, seal recognition, and text spotting. The spotting task employs a 4-point quadrilateral annotation schema embedded in the token vocabulary, allowing direct generation of both textual and spatial labels. This facilitates fine-grained localization required in highly variable document types, including ancient manuscripts and scene text.
Training Methodology
The PP-DocLayoutV3 module is trained via joint optimization on detection, segmentation, and order prediction, leveraging over 38k meticulously annotated samples spanning 25 granular element types and diverse document domains. A distortion-aware augmentation pipeline ensures exposure to simulated real-world deformations.
The LLM component utilizes 46M image-text pairs (a substantial expansion over prior iterations), with explicit inclusion of hard mining and uncertainty-aware cluster sampling. Reinforcement learning via GRPO is adopted to maximize instruction diversity and robustness, focusing adaptation effort on visually or semantically difficult instances.
Dataset Construction
Layout Analysis
The custom layout dataset is characterized by extensive manual curation, strategic unsupervised clustering, and hard-case mining for non-conventional structures. This data-centric approach targets rare scenarios—comics, CAD diagrams, high-aspect-ratio screenshots—not typically well represented in public corpora.
VLM Instructional Data
Instructional fine-tuning data are selected via Uncertainty-Aware Cluster Sampling (UACS), balancing visual coverage with explicit up-sampling for high-entropy clusters. Specialized annotation tools and semi-automatic multi-model cross-filtering raise label quality for new capability domains such as seal and spotting.
Benchmarking and Empirical Results
Synthetic and Real-World Benchmarks
The OmniDocBench v1.5 suite, including its realistic Real5-OmniDocBench subset, rigorously evaluates both clean and physically distorted documents with fine-grained metrics.

Figure 4: Real5-OmniDocBench samples illustrate physical distortions targeted by the model.
PaddleOCR-VL-1.5 achieves an overall accuracy of 94.5% on OmniDocBench v1.5 and 92.05% on Real5-OmniDocBench, significantly surpassing all pipeline-based, generalist, and specialist VLMs—even those exceeding 200B parameters. In the most challenging "Skew" scenario, it realizes a 14.19% improvement over its predecessor, reflecting dramatic gains in geometric robustness.
Figures 5–9 systematically document markdown outputs under various physical perturbations.

Figure 5: Markdown output for documents exhibiting strong illumination variation.

Figure 6: Robust output under skewed document geometry.

Figure 7: Extraction accuracy with screen photography-induced artifacts.

Figure 8: Parsing for scanned documents with typical noise.

Figure 9: Warped pages reconstructed into structured digital form.
Layout Analysis and New Scenarios
Comparisons in Figures 10–14 demonstrate superior segmentation and logical ordering on highly non-planar input, with robust performance on specialized domains previously excluded from model scope.
Multi-Task Capabilities
PaddleOCR-VL-1.5 integrates seal recognition and text spotting as first-class tasks, demonstrating leading normalized edit distance for seals (0.138 vs. 0.382 for Qwen3-VL-235B). In text spotting, the model achieves 0.8621 average accuracy over 9 unconstrained domains, substantially above contemporary benchmarks.

Figure 10: Markdown comparison for text decorations.

Figure 11: Outputs for documents with special character usage.

Figure 12: Model behavior in long-tail scenarios with vertical, ambiguous, or rare text.
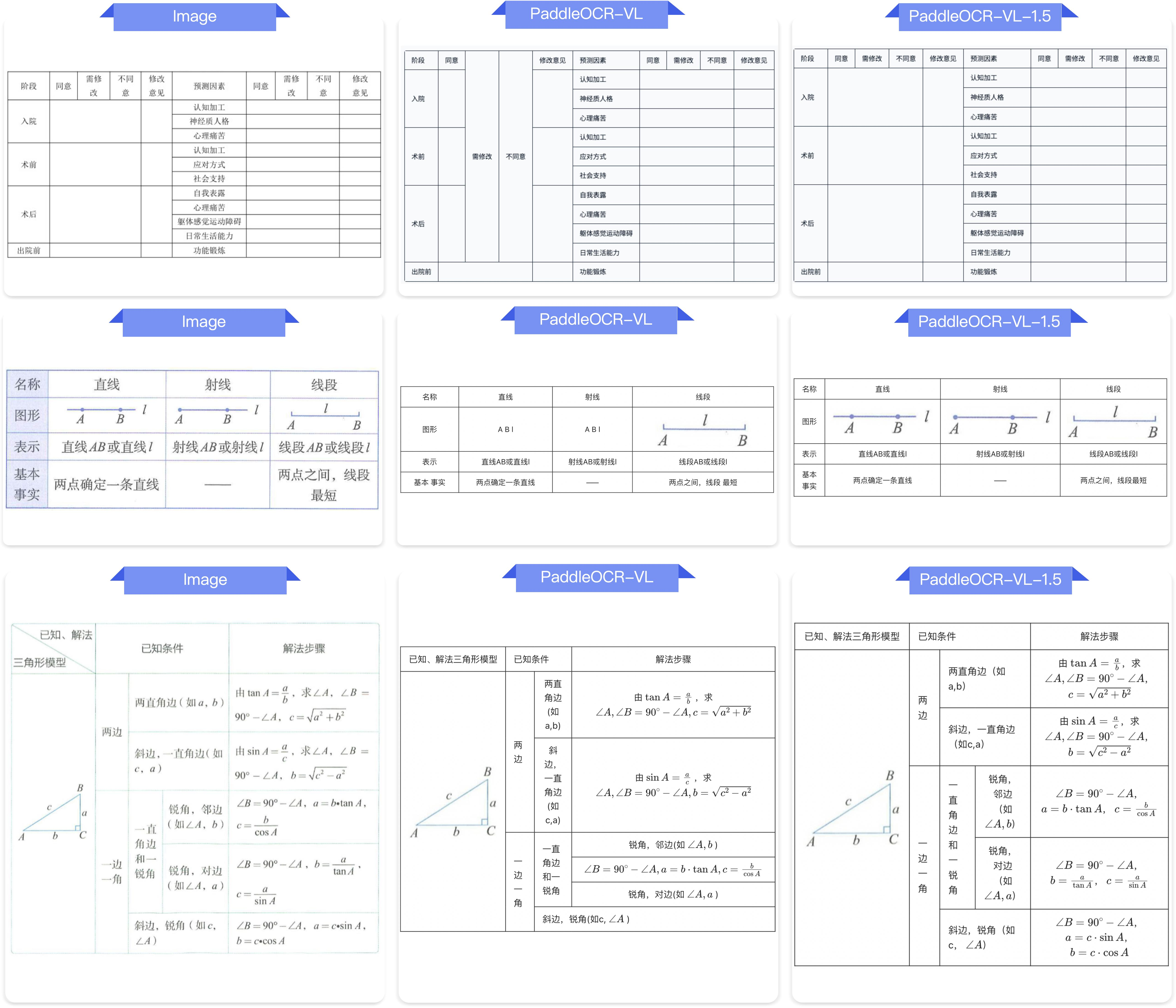
Figure 13: Extraction fidelity for general tables.

Figure 14: Robust parsing of multilingual table structures.

Figure 15: Accurate merging of cross-page tables.
Practical and Theoretical Implications
PaddleOCR-VL-1.5 demonstrates that carefully engineered ultra-compact models can not only match but exceed the document parsing performance of multimodal LLMs at drastically reduced parameter counts, with implications for deployment efficiency, cost, and accessibility. Its design—centered on targeted architectural specialization and adversarial data curation—presents a blueprint for domain-specific VLM construction.
High-fidelity structured output under unconstrained environmental conditions has direct impact on the reliability and precision of downstream systems, including RAG-based knowledge ingestion and enterprise-scale LLM deployments.
On the theoretical front, the model’s successful integration of end-to-end instance segmentation and logical order inference provides actionable insights into bridging vision-language abstraction gaps. Further, the explicit spatial tokenization approach for detection tasks may inform future VLMs targeting joint localization-generation problems.
Prospects for Future Development
The demonstrated success of PaddleOCR-VL-1.5 indicates strong returns from continued specialization and data-driven optimization, especially for domain adaptation in poorly represented or physically degraded contexts. Future research can extend this approach to additional document categories (e.g., historical scripts, blueprints), more language scripts, and enhanced support for layout-aware reasoning in legal and scientific documentation.
Integration with on-device deployment, privacy-preserving architectures, and streaming inference engines is warranted, given the model’s compact scale and high throughput. Exploration of self-supervised signal mining from enterprise data lakes and more advanced RL data screening techniques could further strengthen robustness and generality.
Conclusion
PaddleOCR-VL-1.5 establishes a new technical baseline for multi-task document parsing under unconstrained physical conditions, demonstrating state-of-the-art accuracy and superior parameter efficiency. Its architectural specializations and rigorous data-centric methodology convincingly address key limitations of prior approaches, providing a robust data foundation for downstream document intelligence systems and high-throughput enterprise workflows. The advances herein mark a significant leap in the practical integration of compact document-centric VLMs (2601.21957).
Paper to Video (Beta)
No one has generated a video about this paper yet.
Whiteboard
No one has generated a whiteboard explanation for this paper yet.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Open Problems
We found no open problems mentioned in this paper.
Continue Learning
- How does the PP-DocLayoutV3 module enhance instance segmentation and determine reading order in distorted documents?
- What specific architectural innovations allow PaddleOCR-VL-1.5 to outperform larger models despite its compact size?
- How does the distortion-aware augmentation pipeline contribute to the model's generalization in real-world scenarios?
- What are the implications of using PaddleOCR-VL-1.5 for enterprise-scale document processing and OCR applications?
- Find recent papers about robust multi-task document parsing.
Related Papers
- PP-OCR: A Practical Ultra Lightweight OCR System (2020)
- PP-OCRv2: Bag of Tricks for Ultra Lightweight OCR System (2021)
- mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding (2024)
- PaddleOCR 3.0 Technical Report (2025)
- MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing (2025)
- PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model (2025)
- MonkeyOCR v1.5 Technical Report: Unlocking Robust Document Parsing for Complex Patterns (2025)
- HunyuanOCR Technical Report (2025)
- DOCR-Inspector: Fine-Grained and Automated Evaluation of Document Parsing with VLM (2025)
- UniRec-0.1B: Unified Text and Formula Recognition with 0.1B Parameters (2025)
Collections
Sign up for free to add this paper to one or more collections.