- The paper proposes the PIR framework that transforms passive LLM solvers into proactive inquirers by identifying uncertainty and initiating targeted clarification.
- It employs a two-phase method—Interactive Capability Activation and User-Intent Alignment with reinforcement learning—to optimize reasoning and reduce unnecessary computation.
- Experimental results across benchmarks demonstrate significant accuracy gains and improved efficiency, reducing token usage and interaction turns compared to conventional models.
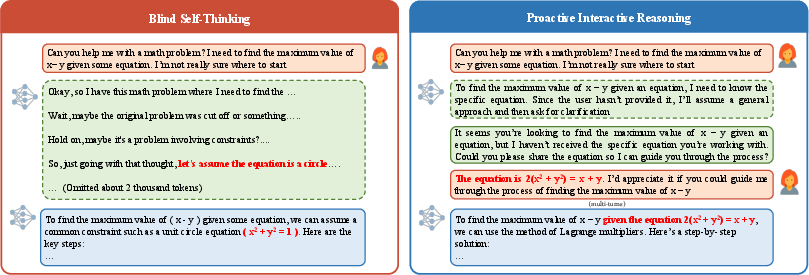
Motivation and Limitations of Blind Self-Thinking
Contemporary reasoning-oriented LLMs employing CoT prompting, such as GPT-o1 and DeepSeek-R1, exhibit significant progress in explicit stepwise reasoning but are critically impaired by blind self-thinking: they perform exhaustive internal reasoning without accounting for ambiguity or information gaps in user queries. This leads to phenomena such as overthinking, hallucinations, and misaligned conclusions, requiring users to provide iterative corrective feedback—reducing efficiency and user satisfaction.
The PIR paradigm introduced in this paper aims to resolve this deficiency by recasting reasoning LLMs as proactive inquirers, which strategically interleave reasoning with clarification, targeting premise- and intent-level uncertainty through interaction with user simulators rather than relying solely on external knowledge retrieval mechanisms.
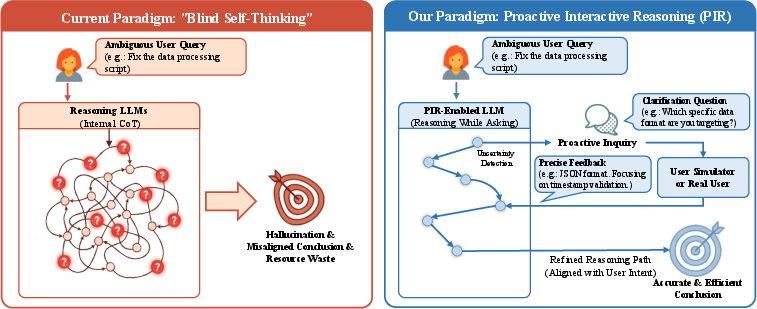
Figure 1: PIR paradigm schematic contrasting blind self-thinking (inefficient, uninformed reasoning) with the PIR approach, which incorporates proactive clarification leveraging uncertainty detection and targeted user simulator interaction.
PIR Framework: Architecture and Phases
The PIR framework consists of two main phases: Interactive Capability Activation and User-Intent Alignment.
Interactive Capability Activation: This stage leverages uncertainty-aware supervised fine-tuning. Reasoning trajectories from a frozen teacher model (e.g., DeepSeek-R1) are segmented and evaluated for prediction entropy (PE) at each reasoning step. High-entropy regions signify decision points with high uncertainty, at which the dataset is augmented with clarification questions and simulated user responses. Training on these "think-ask-respond" chains enables the model to learn when and how to initiate clarifications, activating proactive interaction capability.
User-Intent Alignment: To optimize interactive reasoning beyond cold-start, PIR integrates a reinforcement learning pipeline, US-GRPO (User Simulator-GRPO). A dynamic, instruction-following LLM user simulator is constructed for multi-turn rollouts. Composite rewards explicitly evaluate correctness (extrinsic) and reasoning trajectory (intrinsic: helpfulness, efficiency), guiding policy optimization towards strategies that actively resolve intent ambiguity with minimal unnecessary interaction.
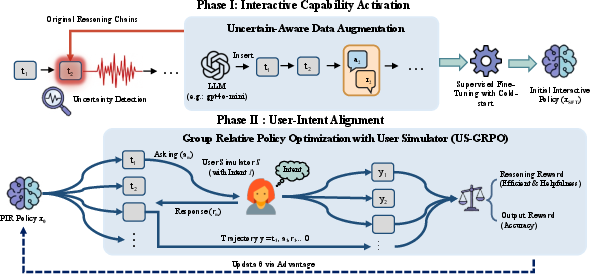
Figure 2: PIR framework operations: transition from passive solver to active inquirer using two-phase optimization and user simulator interaction.
Experimental Results: Efficiency and Accuracy
PIR models evaluated on Math-Chat, BigCodeBench-Chat, and DocEdit-Chat benchmarks decisively outperform baseline multi-turn LLMs (including instruction-tuned, proactive prompting, STaR-GATE, CollabLLM, and non-interactive reasoning LLMs).
| Dataset |
Metric |
Baseline Best |
PIR (US-GRPO) |
Relative Gain |
| MATH-Chat |
Accuracy |
21.30 |
32.70 |
+11.40 |
| BigCodeBench-Chat |
Pass Rate |
19.70 |
22.90 |
+3.20 |
| DocEdit-Chat |
BLEU |
28.00 |
41.36 |
+13.36 |
Notable findings:
Reliability, Robustness, and Generalization
PIR generalizes to non-interactive tasks such as factual knowledge (MMLU/MMLU-Pro), question answering (TriviaQA/SQuAD), and missing premise scenarios. On pure knowledge tasks, PIR abstains from unnecessary interaction but delivers decisive gains when ambiguity is present.
Mechanistic Insights: Uncertainty-Driven Interactivity
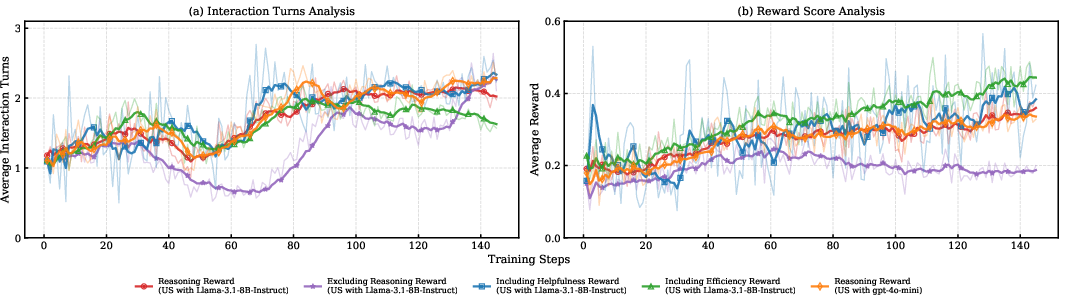
Analysis of PIR SFT reveals that the model’s querying behavior is tightly correlated with internal predictive entropy. As training scales, the distribution of PE for trigger sentences becomes elevated and stable, indicating refined capacity for precision-initiated clarification. Template accuracy for generating structured "think-ask-respond" chains converges rapidly as dataset size increases.
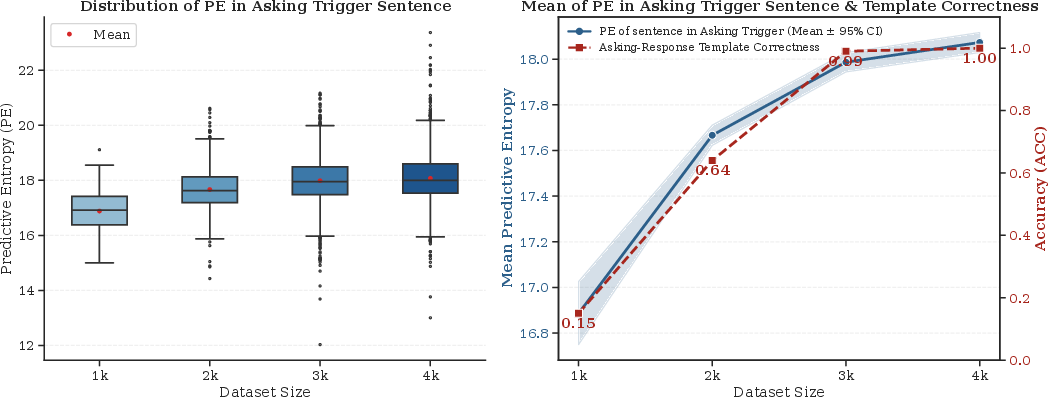
Figure 5: Uncertainty analysis: distribution and convergence of predictive entropy and template correctness at different dataset sizes.
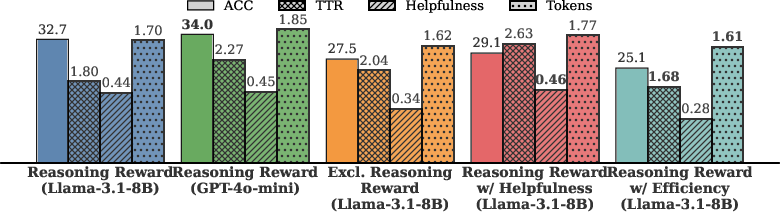
Reward Design and Ablation Analysis
Composite reward modeling proves essential. Ablations reveal the following:
Case Studies: Interactive Efficiency in Mathematical and Code Domains
Concrete cases demonstrate how PIR proactively clarifies intent prior to reasoning, preventing misaligned conclusions and unnecessary computation with minimal turns.

Figure 7: PIR vs. blind reasoning in math task—PIR queries for missing premise and produces a concise, correct solution.
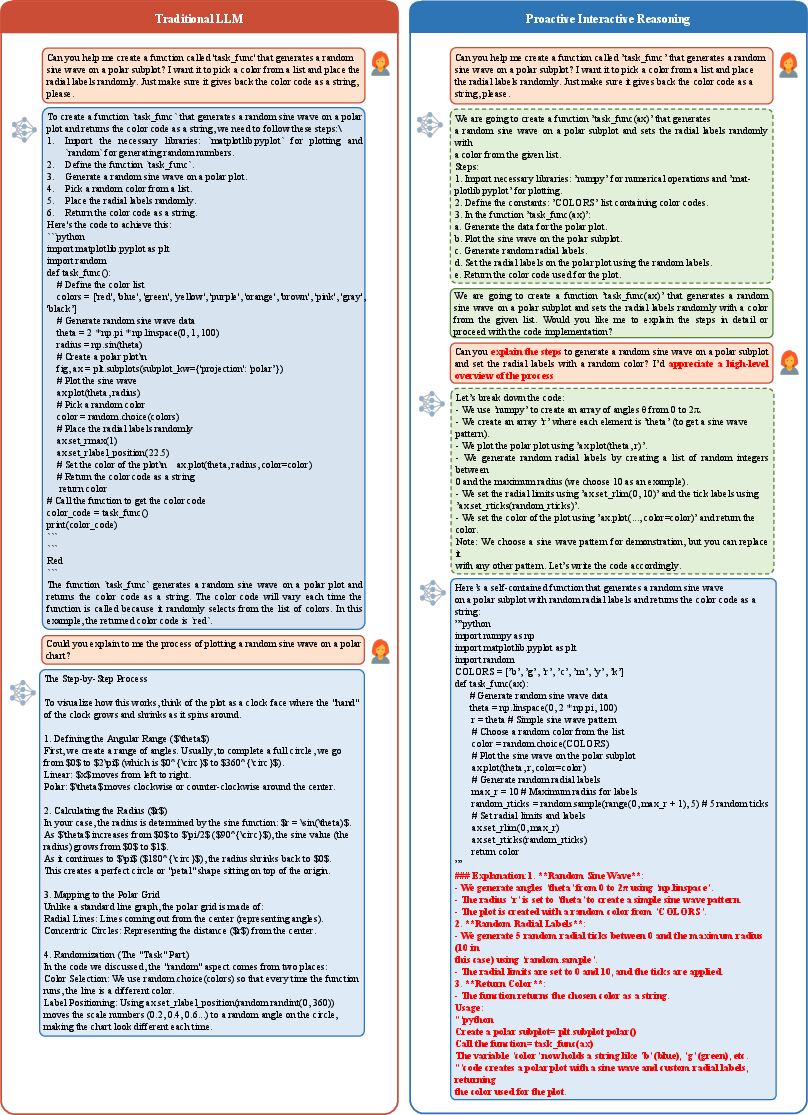
Figure 8: PIR handling code generation—proactively inquiring about user preferences, yielding modular, intent-aligned code and efficient interaction.
Practical and Theoretical Implications
The PIR approach establishes a robust mechanism for intent-aligned, ambiguity-aware reasoning in LLMs. By integrating policy optimization with user simulator-driven rewards and leveraging uncertainty-aware trajectory augmentation, models are endowed with strategic clarification capabilities, directly addressing the limitations of conventional CoT-based systems. This paradigm supports the development of next-generation LLMs capable of adaptive, efficient, and human-centric problem solving across open-ended domains.
Potential future directions include extending user simulation diversity, direct deployment in live settings, and incorporating explicit safety alignment for sensitive topics.
Conclusion
The PIR framework advances the state-of-the-art in reasoning LLMs by transforming passive solvers into proactive inquirers capable of interactive, uncertainty-resolving clarification. Through mechanism-driven reward modeling and rigorous evaluation, PIR models achieve strong gains in accuracy, compute efficiency, and generalization, establishing a scalable foundation for reliable, intent-aligned AI reasoning systems (2601.22139).