Spectral Gradient Descent Mitigates Anisotropy-Driven Misalignment: A Case Study in Phase Retrieval
Abstract: Spectral gradient methods, such as the Muon optimizer, modify gradient updates by preserving directional information while discarding scale, and have shown strong empirical performance in deep learning. We investigate the mechanisms underlying these gains through a dynamical analysis of a nonlinear phase retrieval model with anisotropic Gaussian inputs, equivalent to training a two-layer neural network with the quadratic activation and fixed second-layer weights. Focusing on a spiked covariance setting where the dominant variance direction is orthogonal to the signal, we show that gradient descent (GD) suffers from a variance-induced misalignment: during the early escaping stage, the high-variance but uninformative spike direction is multiplicatively amplified, degrading alignment with the true signal under strong anisotropy. In contrast, spectral gradient descent (SpecGD) removes this spike amplification effect, leading to stable alignment and accelerated noise contraction. Numerical experiments confirm the theory and show that these phenomena persist under broader anisotropic covariances.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
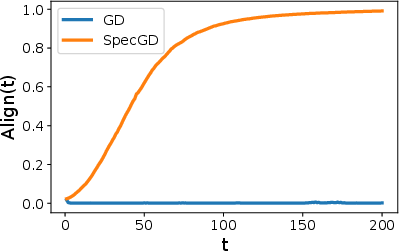
This paper asks: why does a newer way of training neural networks, called spectral gradient descent (used by the “Muon” optimizer), often work better than ordinary gradient descent? The authors study a simple, carefully chosen problem—phase retrieval—that behaves like training a tiny neural network with a quadratic (squaring) activation. They show that when the data are uneven in different directions (anisotropic), ordinary gradient descent gets pulled in the wrong direction, while spectral gradient descent resists that pull and finds the true signal faster and more reliably.
The main questions the paper tries to answer
- When your data have one “loud” direction that isn’t actually helpful (high variance but no information), does ordinary gradient descent get distracted?
- Can spectral gradient descent avoid being distracted by this “loud but unhelpful” direction?
- How do the two methods behave over time, and which one lines up with the true signal sooner?
How they studied it (methods in simple terms)
- The task: phase retrieval. Imagine you want to find a hidden vector (the “signal”), but you only get to see measurements after they’ve been squared. Squaring removes the sign (like taking brightness without color), which makes recovery harder.
- The data setup: most of the variation (think “loudness”) is along one direction that’s completely unrelated to the true signal. This is called a “spiked covariance” with the spike orthogonal to the signal. In everyday terms, the data shout loudly in a useless direction, and whisper in the direction you actually care about.
- Two training rules:
- Gradient Descent (GD): walk downhill in the direction of the slope, and step more where the slope is steepest. If some directions look much steeper because data vary a lot there (even if they’re unhelpful), GD tends to rush that way.
- Spectral Gradient Descent (SpecGD, like Muon): keep the directions of the gradient but throw away its magnitudes (sizes). Analogy: you follow the compass directions of the slope but ignore how steep the slope is. This prevents big, misleading steps in “loud” directions that aren’t useful.
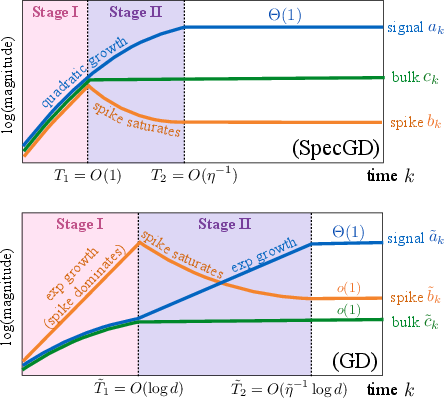
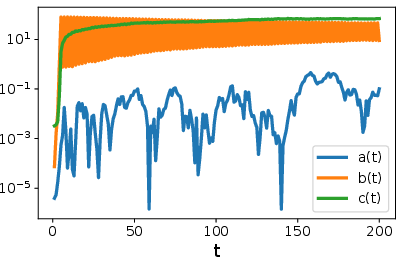
- A simple 3-number view: The authors show the whole training process can be tracked by just three numbers:
- a = how much the model aligns with the true signal
- b = how much it aligns with the loud-but-wrong “spike” direction
- c = how much it spreads into all other “regular” directions (the “bulk”)
- This reduction lets them clearly compare how GD and SpecGD evolve over time.
What they found (and why it matters)
The training naturally has two stages:
- Stage I: growth
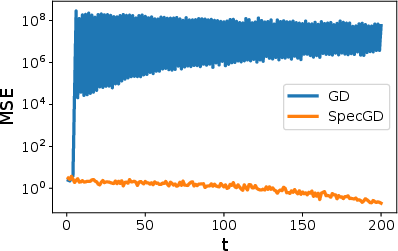
- GD: because the spike direction looks very “steep” (it has huge variance), GD multiplies the spike component b quickly. The model grows most in the wrong direction. This misalignment can get worse before it gets better. To avoid instability, GD needs a smaller learning rate, which slows everything down.
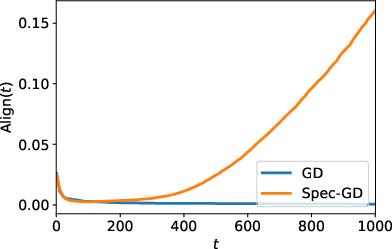
- SpecGD: because it ignores magnitude (steepness) and keeps only direction, it does not amplify the spike more than the others. The a, b, and c components all grow at similar rates. This keeps alignment with the true signal stable and moves the model steadily forward.
- Stage II: alignment
- GD: after a while, the growth along the spike saturates (stops increasing). Only then does the signal component a start to catch up and grow. This delay means it takes longer for GD to align with the true signal.
- SpecGD: the spike and bulk components hit natural limits earlier and stop dominating. The signal component keeps growing until it becomes clearly largest. Alignment improves sooner, and the time to move between stages does not blow up with problem size.
Key takeaways:
- GD suffers from “anisotropy-driven misalignment”: big variance in an unhelpful direction tricks it into growing the wrong way first.
- SpecGD removes this “variance amplification” by normalizing away scale, so it stays on track and reaches strong alignment faster.
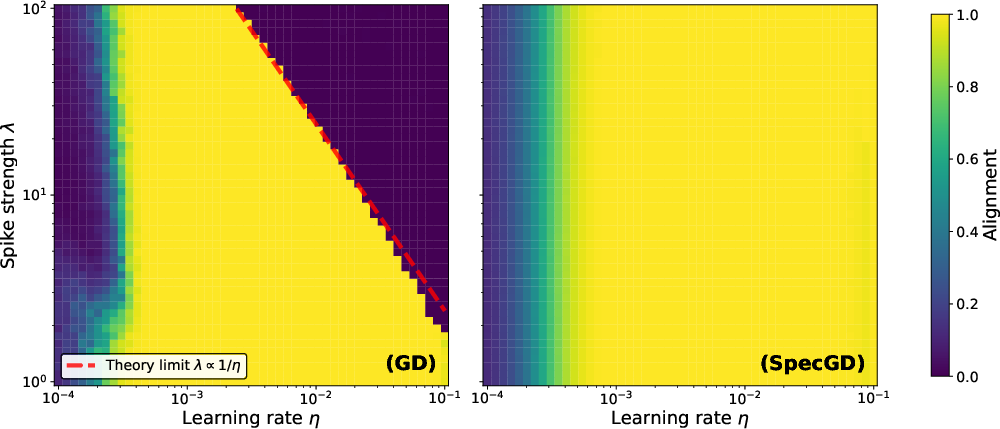
- Experiments confirm the theory and show the advantage persists in more realistic cases (e.g., when data variances follow a power law or when there are finite samples).
Why this is important
- Practical training: Many real datasets have imbalanced or heavy-tailed variation (some directions are much “louder” than others). GD can over-focus on these loud directions and get delayed. Spectral methods like Muon avoid this trap and can train faster and more stably.
- Design insight: It’s not just how big your gradient is—it’s also which directions you choose to trust. Treating parameter updates as matrices and preserving directional structure (while discarding scale) can change learning dynamics in a good way.
- Broader impact: This helps explain why Muon has shown strong results in deep learning. It suggests new optimizers should pay more attention to direction and geometry, not only to rescaling gradients.
In short: when the data shout in the wrong direction, ordinary gradient descent listens too much. Spectral gradient descent listens to the tune, not the volume—so it stays oriented toward the true signal and gets there faster.
Knowledge Gaps
Certainly! Below is a concise list of knowledge gaps, limitations, and open questions that the provided paper leaves unresolved:
Knowledge Gaps and Limitations
- Empirical vs. Theoretical Discrepancy: The paper suggests that the Muon optimizer exhibits superior empirical performance; however, the theoretical understanding of why it outperforms traditional optimizers like Adam in large-scale neural network training remains incomplete.
- Generality of Anisotropy Effects: The analysis is conducted under a spiked covariance model. It's unclear how well the results extrapolate to more general covariance structures, such as those with multiple spikes or broader spectral distributions.
- Robustness Across Architectures: The findings focus on phase retrieval in a two-layer neural network. The extent to which the benefits of spectral gradient descent (SpecGD) apply to deeper architectures or different types of neural networks remains unexplored.
- Online and Noisy Settings: The study is conducted at the population level without consideration of finite-sample effects or stochastic noise. The behavior of SpecGD under online conditions with noise warrants further study.
Open Questions
- Broader Impact of Non-linear Transformations: The effect of non-linear transformations, akin to those seen in Muon, on convergence and generalization across diverse neural network models and dataset scales remains an open question.
- Parameter Sensitivity: The paper presents a specific choice for learning rate parameters under certain assumptions. How sensitive are the results to these choices, and what methods could optimize these parameters dynamically during training?
- Extensions to Other Optimizers: Could insights gleaned from the role of anisotropy in the behavior of SpecGD be leveraged to improve other optimizers, including those that do not utilize spectral information directly?
These gaps highlight potential areas for future exploration to enhance understanding and broaden the applicability of the paper's conclusions.
Practical Applications
Immediate Applications
The following items can be deployed with existing tools and modest engineering effort; each entry links a specific use case to sectors and notes key dependencies.
- Sector: Software/AI infrastructure (DL training)
- Use case: Replace or augment Adam/SGD with Muon-like spectral gradient updates in models trained on anisotropic or heavy-tailed data (e.g., long-tailed vision datasets, language modeling with skewed token frequencies, recommender systems with popularity skew).
- Why it helps: SpecGD suppresses variance-induced misalignment and avoids spike amplification in early training, enabling faster and more stable alignment, larger usable learning rates, and fewer steps to target loss.
- Tools/workflow: Layerwise spectral update (polar factor) library; Newton–Schulz approximation as in Muon; “early-stage spectral, later-stage Adam” hybrid schedule; anisotropy-aware LR presets; PyTorch/JAX/TF optimizer plugin.
- Assumptions/dependencies: Matrix-shaped parameters per layer (standard in DL); acceptable per-step cost for polar/approximate polar; benefits largest when input/feature or gradient covariances are anisotropic; tuning for batch size and momentum interactions.
- Sector: Large-scale LLM and Transformer training
- Use case: Improve step-efficiency and stability under large batch sizes and heavy-tailed gradient statistics by adopting spectral gradient updates for attention/MLP weight matrices.
- Why it helps: Stage-I spike dominance under GD delays useful feature learning; spectral updates keep principal directions while discarding scale, shortening the escape phase.
- Tools/workflow: Distributed Muon-style kernels with mixed-precision Newton–Schulz; per-layer toggles to apply spectral updates only in early epochs; LR scaling rules η≈κ/√(d+λ) as safe default.
- Assumptions/dependencies: Extra FLOPs for spectral steps; need fused kernels to minimize overhead; compatibility with optimizer states (momentum/weight decay) and normalization layers.
- Sector: Scientific/medical imaging (phase retrieval, ptychography, X-ray diffraction, astronomy)
- Use case: Swap Euclidean GD steps in phase retrieval solvers with spectral steps to reduce artifacts from uninformative high-variance directions and speed convergence to the true phase.
- Why it helps: The paper’s model is a phase retrieval case study; spectral updates neutralize spurious spike growth caused by anisotropic measurement covariance.
- Tools/workflow: Integrate spectral descent into existing solvers (e.g., TomoPy, PtyLab) as an optimizer option; early-stage spectral then switch to classical updates; minibatch-compatible variants.
- Assumptions/dependencies: Measurement operator’s anisotropy resembles spiked/power-law covariances; computational budget for matrix polar per iteration; finite-sample noise robustness verified.
- Sector: Applied ML for imbalanced domains (ads/fraud, cybersecurity, healthcare triage)
- Use case: Improve minority-class learning and prevent early bias amplification by adopting spectral updates that learn principal components at comparable rates.
- Why it helps: SpecGD does not multiplicatively prefer the dominant (high-variance) directions in Stage I, mitigating misalignment under class/feature imbalance.
- Tools/workflow: Optimizer choice policy that defaults to spectral updates on skewed datasets; hybrid training schedule; monitoring minority-class metrics in early epochs.
- Assumptions/dependencies: Empirical alignment with the paper’s anisotropy mechanism; class imbalance manifests as feature covariance anisotropy; moderate overhead acceptable.
- Sector: MLOps/Observability
- Use case: Early-stage anisotropy diagnostics and guardrails that detect spike amplification and automatically switch optimizers or adjust LR.
- Why it helps: The theory identifies the failure mode (variance-induced misalignment) and its signature (exploding spike component).
- Tools/workflow: Periodic estimation of top eigenvalues of input/feature or gradient covariance (e.g., randomized power iterations); trigger rules: if λ̂/trace exceeds threshold, enable spectral steps and relax LR.
- Assumptions/dependencies: Overhead to estimate spectra; need logging hooks for gradient statistics; relies on sufficient batch size to estimate anisotropy reliably.
- Sector: Training efficiency and sustainability (cross-industry)
- Use case: Reduce wall-clock time and energy by exiting the escape phase faster and allowing larger stable learning rates with spectral updates.
- Why it helps: SpecGD shortens Stage I (O(1) steps in theory) and maintains alignment without tuning to anisotropy.
- Tools/workflow: Optimizer selection guidelines in compute procurement; energy dashboards attribute savings to optimizer choice.
- Assumptions/dependencies: Gains depend on anisotropy level and implementation efficiency of spectral kernels.
- Sector: Academia/education
- Use case: Curriculum and benchmark design that stress-test optimizers under anisotropy (spiked/power-law spectra) to study representation learning dynamics.
- Why it helps: Paper provides a reduced 3D manifold analysis and stage decomposition that can guide controlled experiments.
- Tools/workflow: Open-source synthetic datasets with controllable λ and spectral decay; teaching modules on anisotropy-driven misalignment and spectral methods.
- Assumptions/dependencies: Need reproducible estimators for anisotropy; extend from population to finite-sample/batch regimes in assignments.
Long-Term Applications
The following items require further research, scaling, or engineering (e.g., theory beyond stylized models, hardware kernels, robust automation).
- Sector: Optimizer R&D and libraries
- Use case: Generalized spectral optimizers that adaptively orthogonalize gradients in arbitrary architectures (CNNs, GNNs) and tensors (beyond matrices), with provable stability under broader covariances.
- Path to product: Library support for blockwise/low-rank spectral updates; dynamic basis adaptation; interpolations between Euclidean and spectral steps.
- Dependencies: Efficient approximate polar factorizations; theory beyond spiked models (power-law, non-Gaussian, nonstationary data); interactions with momentum/regularization.
- Sector: Hardware/Systems (accelerators, compilers)
- Use case: Fused, high-throughput polar decomposition kernels (e.g., Newton–Schulz with mixed precision) for GPUs/TPUs to make spectral updates cost-competitive at scale.
- Path to product: Vendor kernels and compiler passes that recognize layerwise gradient matrices and apply fast spectral primitives.
- Dependencies: Numerical stability in BF16/FP8; distributed consistency; memory bandwidth constraints.
- Sector: Automated MLOps
- Use case: Anisotropy-aware optimizer controllers that measure gradient/input spectra online and choose/update optimizer (spectral vs Adam/K-FAC), LR, and schedules automatically.
- Path to product: AIOps agent integrating spectral estimators, early-stage detectors of spike dominance, and policy rules.
- Dependencies: Reliable low-cost spectral diagnostics; guardrails against oscillations near sign-change thresholds; integration with existing training stacks.
- Sector: Scientific and medical imaging
- Use case: Real-time, bedside or in-situ phase retrieval with spectral descent in next-gen microscopes/beamlines; improved reconstructions under anisotropic noise and sampling.
- Path to product: Embedded spectral solvers in instrument pipelines; accelerated inference for ptychography/X-ray CDI; clinician-facing tools with faster convergence.
- Dependencies: Clinical validation; robustness to model mismatch and shot noise; streaming/online variants of spectral updates.
- Sector: Robust ML under distribution shift and heavy tails
- Use case: Training pipelines that remain stable and align features under covariate shifts introducing anisotropy (e.g., long-tailed deployments, open-world recognition).
- Path to product: Domain-adaptive spectral schedules; anisotropy-aware fine-tuning for model updates.
- Dependencies: Empirical validation across tasks; coupling with uncertainty estimation and calibration.
- Sector: Fairness and governance
- Use case: Mitigate early-stage dominance of majority groups in imbalanced data by using spectral updates to equalize learning rates across principal components.
- Path to policy: Optimizer choice as a documented control in ML governance; reporting anisotropy metrics and optimizer rationale in model cards.
- Dependencies: Causal links between anisotropy mitigation and fairness metrics; standardized audits; sector-specific regulation alignment.
- Sector: Robotics and autonomous systems
- Use case: Learning from anisotropic sensor logs (e.g., dominant ego-motion or background dynamics) where Euclidean GD can misalign features; spectral updates for representation learning and control.
- Path to product: Spectral optimizers in self-supervised pretraining stacks for perception/control.
- Dependencies: Real-time constraints; sample efficiency in on-policy regimes; robustness to non-Gaussian noise.
- Sector: Finance and energy/industrial IoT
- Use case: Training risk/failure detection models on heavy-tailed, imbalanced logs without early misalignment; faster convergence in large-batch pipelines.
- Path to product: Drop-in spectral optimizers in time-series/tabular training stacks; early-stage spectral warm starts.
- Dependencies: Validation on proprietary datasets; latency and throughput requirements; explainability/controls.
- Sector: Theoretical ML and methodology
- Use case: Stage-aware training controllers derived from reduced-order dynamics (signal–spike–bulk tracking) that generalize to multi-index and deep nonlinear models.
- Path to product: Lightweight estimators of “mass” terms and stage boundaries; controllers that allocate compute to stages adaptively.
- Dependencies: Extending manifold reductions beyond quadratic models; reliable online estimation in stochastic settings.
Cross-cutting assumptions and feasibility notes
- The paper’s guarantees are for population dynamics in a quadratic (phase-retrieval) model with Gaussian anisotropy (spiked covariance, sometimes power-law) and small isotropic initialization; strongest benefits occur when anisotropy is significant and uninformative directions dominate early gradients.
- Finite-sample and minibatch regimes: empirical evidence supports transfer, but stability and gains depend on batch size, noise, and approximation quality of the polar factor.
- Computational overhead: practical deployment often uses approximate polar decomposition (e.g., Newton–Schulz); performance hinges on high-quality implementations and system integration.
- Interactions: Momentum, normalization layers, and weight decay may alter dynamics; hybrid schedules (early spectral, later adaptive) mitigate risks.
- Measurements: Real-time anisotropy/gradient-spectrum monitoring introduces overhead but enables automated control and safer LR choices.
Glossary
- Anisotropic Gaussian inputs: Gaussian data whose covariance has direction-dependent variance (not proportional to the identity), causing some directions to dominate. "anisotropic Gaussian inputs"
- Barrier argument: A proof technique that constructs bounds that trajectories cannot cross, ensuring quantities remain within safe regions. "By using a barrier argument, we can show that these quantities remain bounded."
- Bulk (isotropic bulk): The high-dimensional subspace orthogonal to both the signal and spike directions, typically with uniform variance and many degrees of freedom. "isotropic bulk components"
- Frobenius cosine: A cosine similarity between matrices defined using the Frobenius inner product, used here to quantify signal alignment. "the Frobenius cosine"
- Frobenius inner product: The inner product on matrices defined as Tr(A⊤B), inducing the Frobenius norm. "the Frobenius inner product"
- Gradient flow (GF): The continuous-time limit of gradient descent expressed as an ordinary differential equation governing parameter dynamics. "the corresponding continuous-time gradient flows (GFs):"
- Gradient orthogonalization: A transformation that removes the scaling of gradient directions, focusing updates on directions rather than magnitudes. "gradient orthogonalization is advantageous"
- Invariant manifold: A subset of parameter space that is preserved by the dynamics, allowing reduction to lower-dimensional evolution. "three-dimensional invariant manifold"
- K-FAC: Kronecker-Factored Approximate Curvature, an optimizer that uses Kronecker-factored curvature approximations for efficient preconditioning. "K-FAC"
- KKT conditions: Karush–Kuhn–Tucker optimality conditions characterizing solutions to constrained optimization problems. "characterized through KKT conditions"
- Kronecker-factored preconditioners: Curvature-based rescaling methods that approximate second-order information using Kronecker products to reduce computation. "Kronecker-factored preconditioners"
- Moore–Penrose pseudoinverse: A generalized matrix inverse used to define matrix inverse square roots when matrices are singular or rectangular. "Moore--Penrose sense"
- Muon optimizer: A spectral optimizer that replaces raw gradients with orthogonalized directions derived from the polar decomposition. "The recently introduced optimizer Muon"
- Newton–Schulz approximation: An iterative method for computing matrix inverse square roots used to approximate the polar factor efficiently. "the Newton--Schulz approximation"
- Phase retrieval: The problem of recovering a signal from squared (phaseless) linear measurements, modeled here as quadratic observations. "phase retrieval model"
- Polar decomposition: A matrix factorization A = UH where U is orthogonal and H is positive semidefinite, used to extract an orthogonal update direction. "polar decomposition"
- Positive semidefinite (PSD) matrix: A symmetric matrix with nonnegative eigenvalues, often representing covariance or quadratic forms. "positive semidefinite matrix"
- Power-law spectra: Eigenvalue distributions that decay as a power law, leading to heavy-tailed variance across directions. "power-law spectra"
- Preconditioning: Modifying gradient updates using curvature or second-moment information to improve optimization efficiency. "preconditioning mechanisms"
- Scale-invariant update: An update rule whose effect does not depend on the magnitude of the gradient, only on its direction. "scale-invariant"
- Shampoo optimizer: An optimization method that uses factored second-moment estimates to form efficient matrix preconditioners. "Shampoo"
- Sign-based update: An update that uses only the signs of gradient components (or of reduced coefficients), discarding their magnitudes. "sign-based (scale-invariant) gradient update"
- Spectral gradient descent (SpecGD): An update rule that applies the polar factor of the gradient matrix, preserving singular subspaces while discarding singular values. "Spectral gradient descent (SpecGD) updates the gradient by its polar factor"
- Spectral norm: The largest singular value of a matrix (operator norm), used to analyze margin and implicit bias in learning. "spectral norm"
- Spiked covariance model: A covariance of the form Q = I + λ vv⊤ with a dominant “spike” direction, inducing strong anisotropy. "spiked covariance model"
- Stable rank: A scale-sensitive notion of matrix rank defined by the ratio of squared Frobenius norm to squared spectral norm. "stable-rank"
- Stiefel manifold: The set of matrices with orthonormal columns, used for orthonormal initialization of weights. "Stiefel manifold"
- Variance-induced misalignment: The phenomenon where high-variance but uninformative directions dominate early learning, reducing alignment with the true signal. "variance-induced misalignment"
Collections
Sign up for free to add this paper to one or more collections.